个人项目 论文查重
|这个作业属于哪个课程|计科国际班|
| ---- | ---- | ---- |
|这个作业要求在哪里|作业要求|
|这个作业的目标| 实现论文查重算法|
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 360 | 390 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 20 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 120 | 150 |
| · Coding | · 具体编码 | 300 | 360 |
| · Code Review | · 代码复审 | 30 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 40 |
| Reporting | 报告 | 120 | 120 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 1280 | 1440 |
github地址
模块接口
jieba.lcut()
中文文本需要通过分词获得单个的词语
利用一个中文词库,确定汉字之间的关联概率
汉字间概率大的组成词组,形成分词结果
用例
import jieba
whatever = jieba.lcut("今天的天气真好", cut_all=False) #全模式
print("Full Mode: " + "/ ".join(whatever))
结果
Full Mode: 今天/ 的/ 天气/ 真/ 好
re.compline()
使用正则表达式过滤掉标点符号和转义字符
用例
import re
re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
A = re_telephone.match('010-12345').groups()
print(A)
结果
('010', '12345')
gensim.similarities.Similarity()
用来计算余弦相似度
gensim.corpora.Dictionary()
用来生成词典
os.path.exists()
用于判断文件是否存在
实现过程
1.输入两个文件,并判断文件是否存在
2.若存在,则对其文本内容进行过滤处理,仅保留汉字,数字和字母,若不存在,则输出相应内容(文件不存在)
#将文本的标点符号和转义字符过滤掉
def filter(string):
rule = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]") #仅保留字母,数字和汉字
string = rule.sub("", string)
return string
3.对过滤后的文本内容结巴分词
#对过滤后的文本进行jieba分词
def divide(string):
result = jieba.lcut(string)
return result
4.对两份处理后的文本内容合体,然后建立词典
5.对两份处理后的文本进行余弦相似度计算,得到文本相似度
#对jieba分词后的文本进行余弦相似度计算,从而得到文本相似度
def calc_sim(text1, text2):
texts = [text1, text2] #建立【分词列表集】
dictionary = gensim.corpora.Dictionary(texts) #基于【分词列表集】建立【词典】
corpus = [dictionary.doc2bow(text) for text in texts] #基于【词典】,将【分词列表集】转换为【稀疏向量集】,即【语料库】
feature_count = len(dictionary) #提取词典特征数
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, feature_count)
test_corpus1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus1][1]
return cosine_sim
6.将文本相似度写入txt文件
性能改进
各函数时间占用
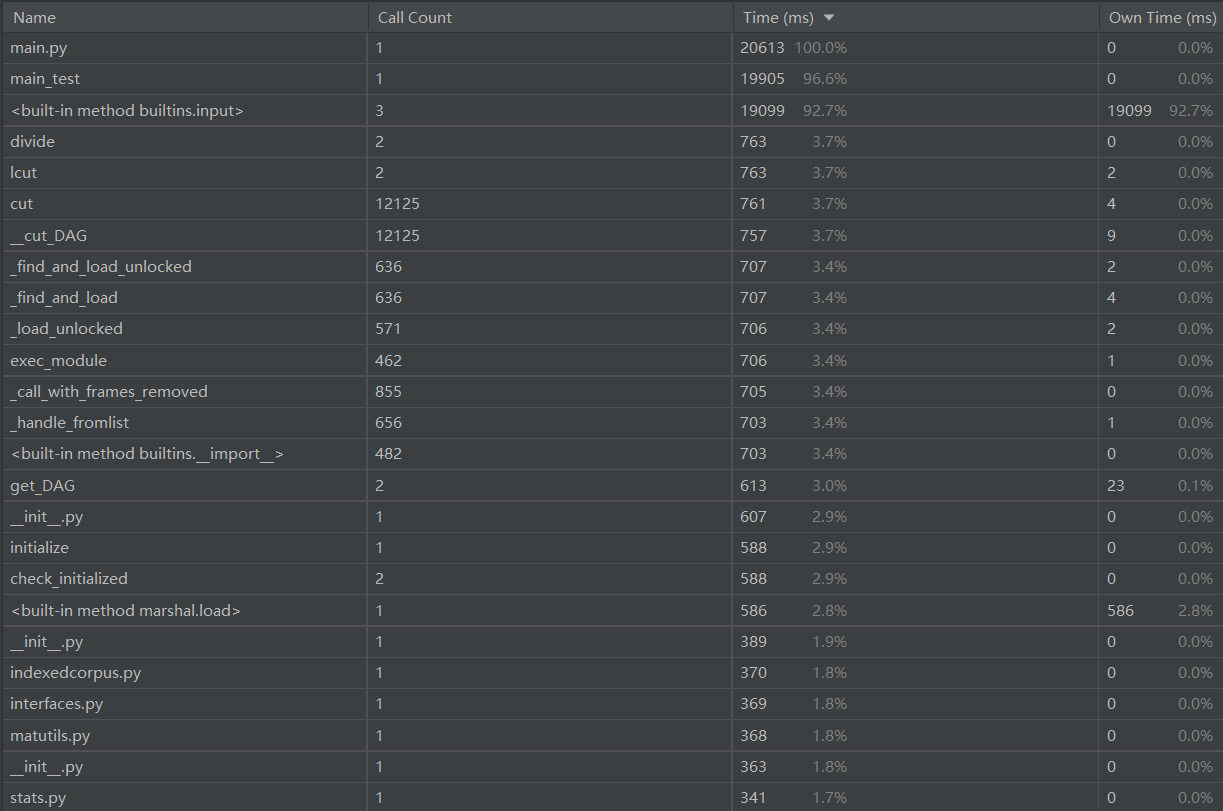
流程图

单元测试
import unittest
from main import main_test
class MyTestCase(unittest.TestCase):
def test_something(self):
self.assertEqual(0.99, main_test())
if __name__ == '__main__':
unittest.main()
测试1
orig.txt和orig_0.8_add.txt比较,预测相似度为0.99

测试成功
测试2
orig.txt和orig_0.8_del.txt比较,预测相似度为0.99
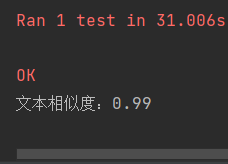
测试成功
测试3
orig.txt和orig_0.8_dis_1.txt比较,预测相似度为0.99
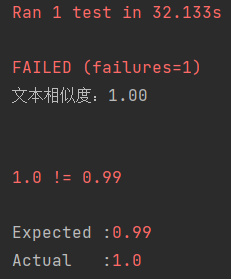
测试失败,预测失败
异常处理
若输入的文件为空或不存在,则会输出“xx文件不存在”
if not os.path.exists(path1):
print("论文原文文件不存在")
exit()
if not os.path.exists(path2):
print("抄袭版论文文件不存在")
exit()
用例,论文原文文件不存在
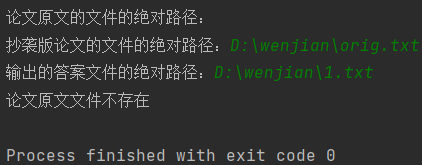
用例,抄袭版论文文件不存在
代码覆盖度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号