
23 Scrapy爬虫第一个 实例
一、Scrapy爬虫的常用命令

二、建立第一个项目
https://docs.scrapy.org/en/latest/intro/tutorial.html
1、创建一个Scrapy爬虫工程
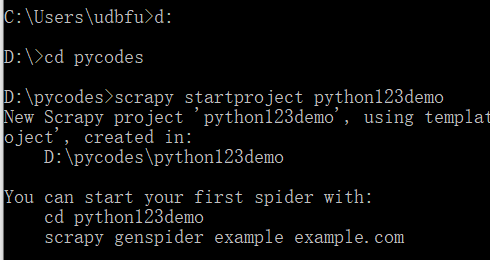
scrapy startproject python123demo 命令创建了一个python123demo新工程


2、在工程中产生一个Scrapy爬虫
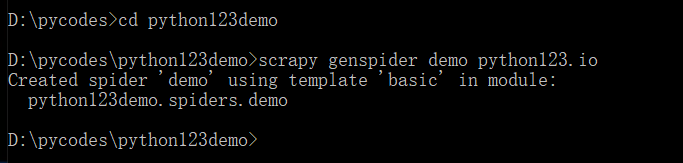
进入python123demo目录,输入命令:scrapy genspider demo python123.io
在D:\pycodes\python123demo\python123demo\spiders中生成了一个demo.py文件
生成的demo.py文件如下:
# -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider): name = 'demo' allowed_domains = ['python123.io'] start_urls = ['http://python123.io/'] def parse(self, response): pass
3、配置产生的spider
# -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider): name = 'demo' # allowed_domains = ['python123.io'] start_urls = ['http://python123.io/ws/demo.html'] def parse(self, response): fname = response.url.split('/')[-1] with open(fname, 'wb') as f: f.write(response.body) self.log('Saved file %s.' % name)
4、运行爬虫,获取网页

scrapy crawl demo 运行demo
5、结果
在python123demo项目目录中存储一个网页

6、代码分析


关键字yield有重要作用!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号