
Kafka学习记录
Kafka学习记录
- 定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于 大数据实时处理领域。
- 为什么要用消息队列
1. 解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2. 可恢复性 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理 消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
3. 缓冲 有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
4. 灵活性与峰值处理能力 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理 这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的 访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5. 异步通信 很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入 队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
- 消息队列的两种模式
点对点模式
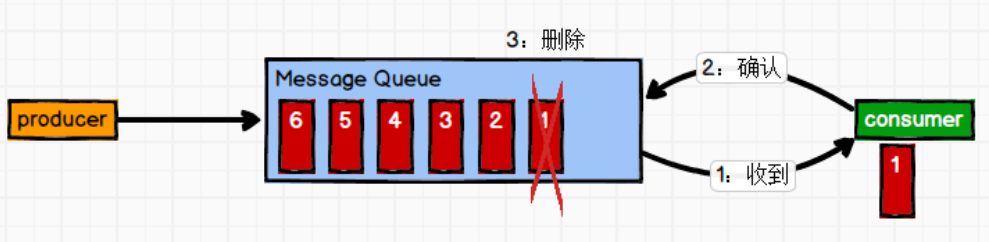
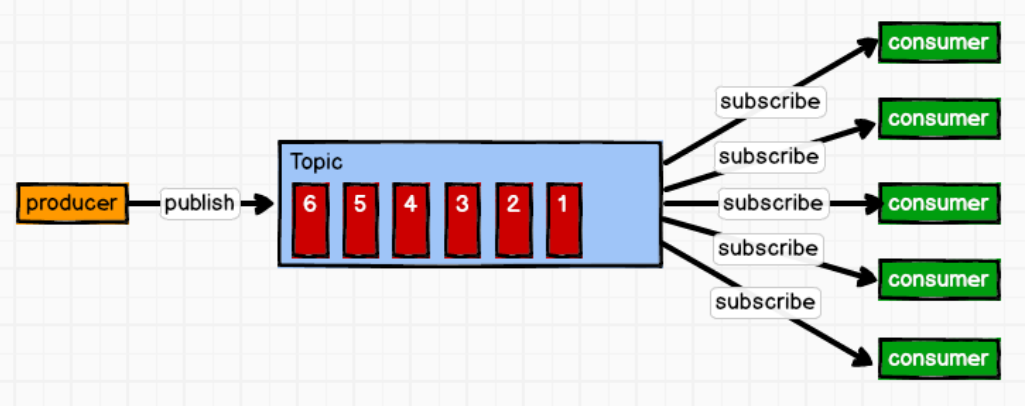
发布/订阅模式
- Kafka架构
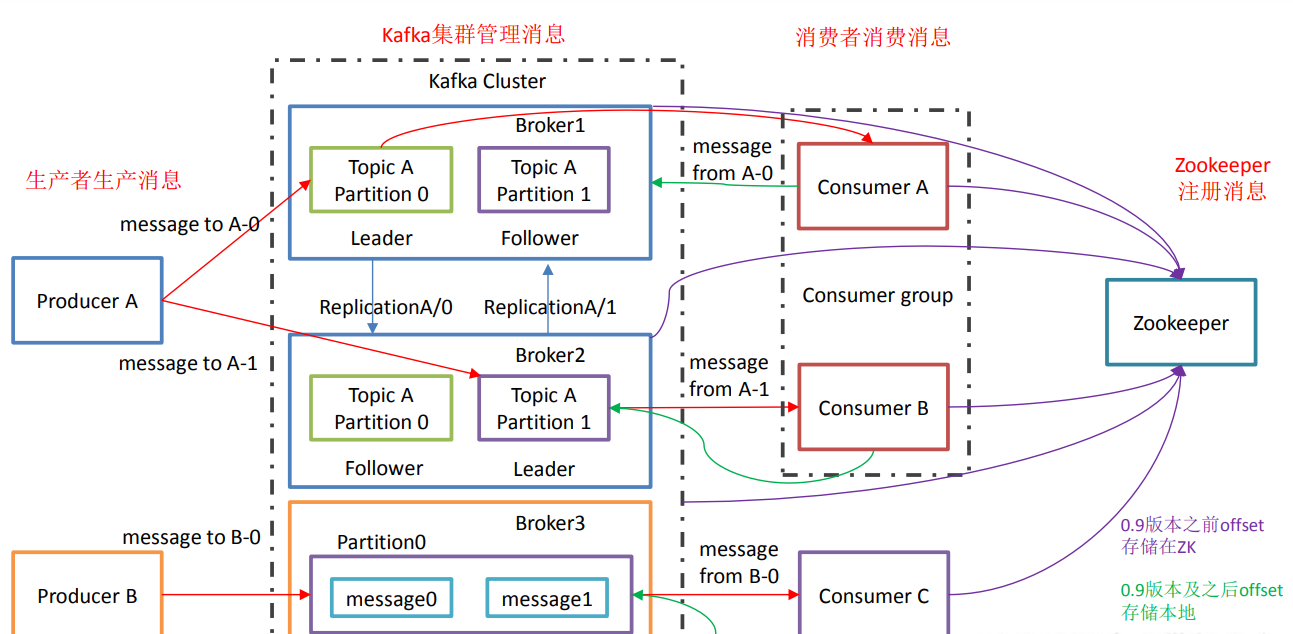
1)Producer :消息生产者,就是向 kafka broker 发消息的客户端;
2)Consumer :消息消费者,向 kafka broker 取消息的客户端;
3)Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负 责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所 有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic;
6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上, 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower。
8)leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对 象都是 leader。
9)follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据 的同步。leader 发生故障时,某个 follower 会成为新的 follower。
- 常用命令
1)查看当前服务器中的所有 topic
bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
2)创建 topic
bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 -- topic first
3)启动生产者Producer
bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
4)启动消费者Consumer
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
- kafka的数据可靠性怎么保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的 数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进 行下一轮的发送,否则重新发送数据。所以引出ack机制。
- ISR(InSyncReplicaSet)
和Leader保持同步的follower集合(即速率和leader相差低于10秒的follower的集合)。
当ISR中的follower完成数据同步之后,Leader就会给follower发送ack,如果follower长时间未向Leader同步数据,则该follower将会被踢出ISR,该事件阙值由replica.lag.time.max.sx参数决定,Leader发生故障时,就会从ISR中选举新的Leader。
- ACK
0:producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还 没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
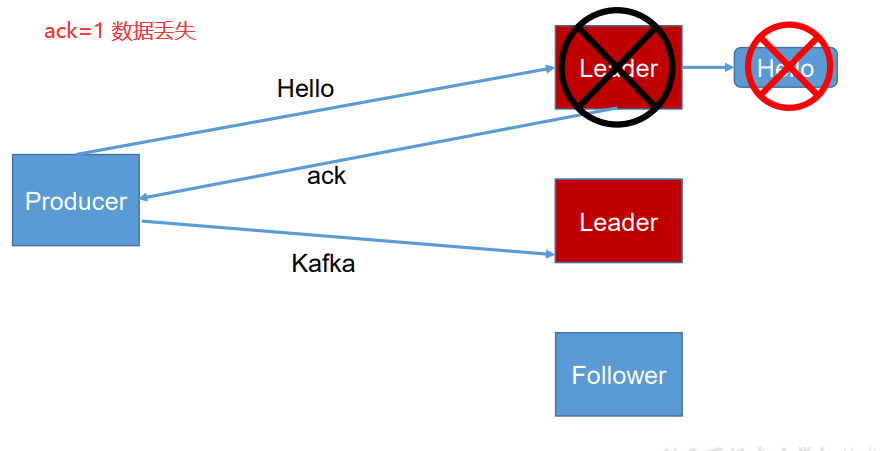
1:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower 同步成功之前 leader 故障,那么将会丢失数据;
-1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盘成功后才 返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会 造成数据重复。
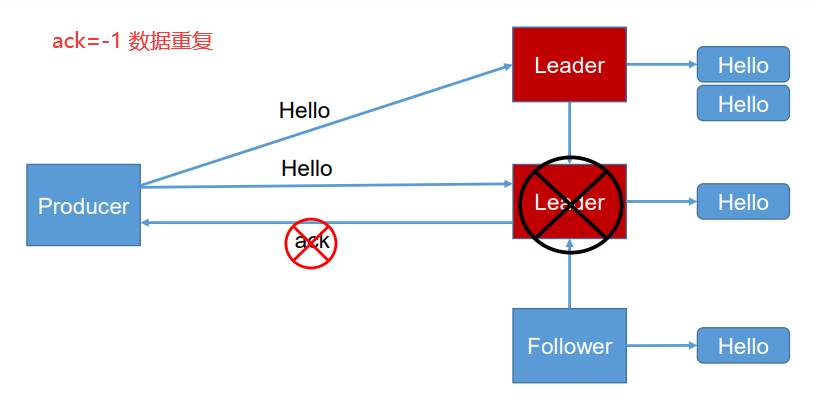
- kafka的数据一致性怎么保证(副本之间)
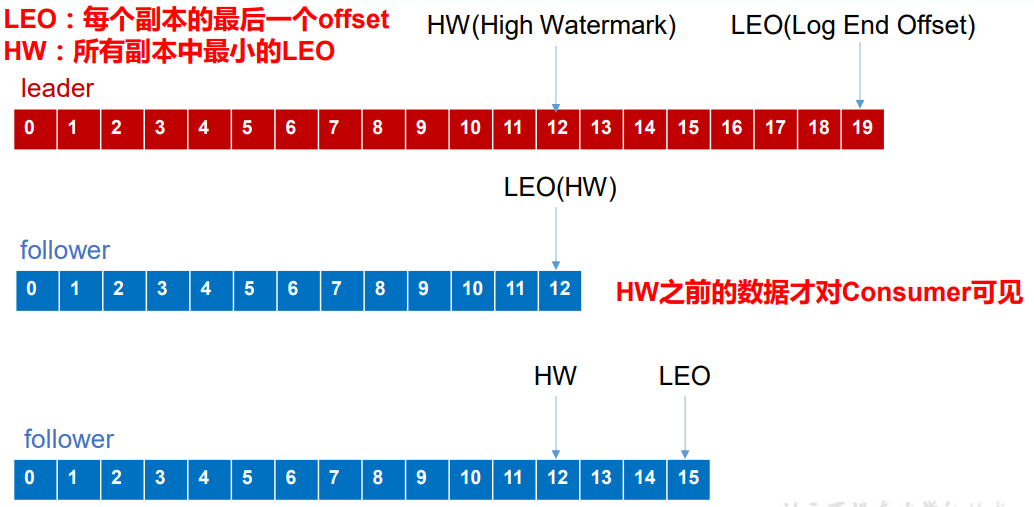
LEO:指的是每个副本最大的 offset;
HW:指的是消费者能见到的最大的 offset,ISR 队列中最小的 LEO。
- Exactly Once 语义
将服务器的 ACK 级别设置为-1,可以保证 Producer 到 Server 之间不会丢失数据,即 At Least Once 语义。相对的,将服务器 ACK 级别设置为 0,可以保证生产者每条消息只会被 发送一次,即 At Most Once 语义。
At Least Once 可以保证数据不丢失,但是不能保证数据不重复;相对的,At Least Once 可以保证数据不重复,但是不能保证数据不丢失。但是,对于一些非常重要的信息,比如说 交易数据,下游数据消费者要求数据既不重复也不丢失,即 Exactly Once 语义。在 0.11 版 本以前的 Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局 去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。
0.11 版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指 Producer 不论 向 Server 发送多少次重复数据,Server 端都只会持久化一条。幂等性结合 At Least Once 语 义,就构成了 Kafka 的 Exactly Once 语义。
即:
At Least Once + 幂等性 = Exactly Once
要启用幂等性,只需要将 Producer 的参数中 enable.idompotence 设置为 true 即可。Kafka 的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的 Producer 在 初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而 Broker 端会对<pid, partition,="" seqnumber="">做缓存,当具有相同主键的消息提交时,Broker 只 会持久化一条。
但是 PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨 分区跨会话的 Exactly Once。
- 分区分配策略
- Range分区分配策略
Range是对每个Topic而言的(即一个Topic一个Topic分),首先对同一个Topic里面的分区按照序号进 行排序,并对消费者按照字母顺序进行排序。然后用Partitions分区的个数除以消费者线程的总数来决定 每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。假设n=分 区数/消费者数量,m=分区数%消费者数量,那么前m个消费者每个分配n+1个分区,后面的(消费者数 量-m)个消费者每个分配n个分区。假如有10个分区,3个消费者线程,把分区按照序号排列
0,1,2,3,4,5,6,7,8,9
消费者线程为
C1-0,C2-0,C2-1
那么用partition数除以消费者线程的总数来决定每个消费者线程消费几个partition,如果除不尽,前面 几个消费者将会多消费一个分区。在我们的例子里面,我们有10个分区,3个消费者线程,10/3 = 3,而 且除不尽,那么消费者线程C1-0将会多消费一个分区,所以最后分区分配的结果看起来是这样的:
C1-0:0,1,2,3
C2-0:4,5,6
C2-1:7,8,9
如果有11个分区将会是:
C1-0:0,1,2,3
C2-0:4,5,6,7
C2-1:8,9,10
假如我们有两个主题T1,T2,分别有10个分区,最后的分配结果将会是这样:
C1-0:T1(0,1,2,3)T2(0,1,2,3)
C2-0:T1(4,5,6)T2(4,5,6)
C2-1:T1(7,8,9) T2(7,8,9)
- RoundRobinAssignor分区分配策略
RoundRobinAssignor策略的原理是将消费组内所有消费者以及消费者所订阅的所有topic的partition按 照字典序排序,然后通过轮询方式逐个将分区以此分配给每个消费者. 使用RoundRobin策略有两个前提 条件必须满足:
同一个消费者组里面的所有消费者的num.streams(消费者消费线程数)必须相等; 每个消费者订阅的主题必须相同。 加入按照 hashCode 排序完的topic-partitions组依次为
T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4, T1-7, T1-6, T1-9
我们的消费者线程排序为
C1-0, C1-1, C2-0, C2-1
最后分区分配的结果为:
C1-0 将消费 T1-5, T1-2, T1-6 分区
C1-1 将消费 T1-3, T1-1, T1-9 分区
C2-0 将消费 T1-0, T1-4 分区
C2-1 将消费 T1-8, T1-7 分区
- Kafka中的事务是怎样实现的
Producer事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和 Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。 为了管理Transaction,Kafka引入了一个新的组件Transaction Coordinator。Producer就是通过和 Transaction Coordinator交互获得Transaction ID对应的任务状态。Transaction Coordinator还负责将 事务所有写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务 状态可以得到恢复,从而继续进行。
Consumer事务
对于Consumer而言,事务的保证就会相对较弱,尤其是无法保证Commit的信息被精确消费。这是由于 Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事务的消息可能 会出现重启后被删除的情况。
posted on 2022-02-22 15:08 SpringStrong 阅读(85) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号