python学习笔记
一、变量
python变量定义:
在使用标识符时,需要注意如下规则:
标识符可以由字母、数字、下画线(_)组成,其中数字不能打头。
标识符不能是 Python 关键字,但可以包含关键字。
标识符不能包含空格。
例如下面变量,有些是合法的,有些是不合法的:
abc_xyz:合法。
HelloWorld:合法。
abc:合法。
xyz#abc:不合法,标识符中不允许出现“#”号。
abc1:合法。
1abc:不合法,标识符不允许数字开头。
Python 还包含一系列关键字和内置函数,一般也不建议使用它们作为变量名:
如果开发者尝试使用关键字作为变量名,Python 解释器会报错。
如果开发者使用内置函数的名字作为变量名,Python 解释器倒不会报错,只是该内置函数就被这个变量覆盖了,该内置函数就不能使用了。
'False','None','True','and','as','assert','break','class','continue','def','del','elif','else','except',
'finally','for','from','global','if','import','in','is','lambda','nonlocal','not','or','pass','raise','return',
'try','while','With','yield'
驼峰命名法:(其他语言常用的命名法)
当变量名是由两个或多个单词组成,还可以利用驼峰命令法来命名
小驼峰命名法
第一个单词以小写字母开始,后续单词的首字母大写
firstName lastName
大驼峰命名法
每一个单词的首字母都采用大写字母
FirstName LastName
二、字符编码
编码/解码本质上是一种映射(对应关系),比如‘a’用ascii编码则是65,计算机中存储的就是00110101,但是显示的时候不能显示00110101,还是要显示'a',但计算机怎么知道00110101是'a'呢,这就需要解码,当选择用ascii解码时,当计算机读到00110101时就到对应的ascii表里一查发现是'a',就显示为'a'
编码:真实字符与二进制串的对应关系,真实字符→二进制串
解码:二进制串与真实字符的对应关系,二进制串→真实字符
要搞清楚字符编码,首先要解决的问题是:什么是字符编码?
我们都知道,计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字(010101).如果我们想保存数据,首先得将我们的数据进行一些处理,最终得转换成010101才能让计算机识别。
所以必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
那么问题就来了?作为一种编码方案,还得解决两个问题:
a.字节是怎么分组的,如8 bits或16 bits一组,这也被称作编码单元。
b.编码单元和字符之间的映射关系。例如,在ASCII码中,十进制65映射到字母A上。
ASCII码是上个世纪最流行的编码体系之一,至少在西方是这样。下图显示了ASCII码中编码单元是怎么映射到字符上的。
随着计算机越来越流行,厂商之间的竞争更加激烈,在不同的计算机体系间转换数据变得十分蛋疼,人们厌烦了这种自定义造成的混乱。最终,计算机制造商一起制定了一个标准的方法来描述字符。他们定义使用一个字节的低7位来表示字符,并且制作了如上图所示的对照表来映射七个比特的值到一个字符上。例如,字母A是65,c是99,~是126等等, ASCII码就这样诞生了。原始的ASCII标准定义了从0到127 的字符,这样正好能用七个比特表示。
为什么选择了7个比特而不是8个来表示一个字符呢?我并不关心。但是一个字节是8个比特,这意味着1个比特并没有被使用,也就是从128到255的编码并没有被制定ASCII标准的人所规定,这些美国人对世界的其它地方一无所知甚至完全不关心。其它国家的人趁这个机会开始使用128到255范围内的编码来表达自己语言中的字符。例如,144在阿拉伯人的ASCII码中是گ,而在俄罗斯的ASCII码中是ђ。ASCII码的问题在于尽管所有人都在0-127号字符的使用上达成了一致,但对于128-255号字符却有很多很多不同的解释。你必须告诉计算机使用哪种风格的ASCII码才能正确显示128-255号的字符。
总结:ASCII,一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符,ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符),后来为了将拉丁文也编码进了ASCII表,将最高位也占用了。
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符;为了满足其他国家,各个国家纷纷定制了自己的编码。日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
阶段三:万国码Unicode编码
后来,有人开始觉得太多编码导致世界变得过于复杂了,让人脑袋疼,于是大家坐在一起拍脑袋想出来一个方法:所有语言的字符都用同一种字符集来表示,这就是Unicode。
Unicode统一用2Bytes代表一个字符,2**16-1=65535,可代表6万多个字符,因而兼容万国语言.但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(英文字母只需要一个字节就足够,用两个字节来表示,无疑是浪费空间).于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes.UTF-8是一个非常惊艳的概念,它漂亮的实现了对ASCII码的向后兼容,以保证Unicode可以被大众接受。
在UTF-8中,0-127号的字符用1个字节来表示,使用和US-ASCII相同的编码。这意味着1980年代写的文档用UTF-8打开一点问题都没有。只有128号及以上的字符才用2个,3个或者4个字节来表示。因此,UTF-8被称作可变长度编码。于是下面字节流如下:
0100100001000101010011000100110001001111
这个字节流在ASCII和UTF-8中表示相同的字符:HELLO
至于其他的UTF-16,这里就不再叙述了。
总结一点:unicode:简单粗暴,所有字符都是2Bytes,优点是字符----->数字的转换速度快,缺点是占用空间大。
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示。
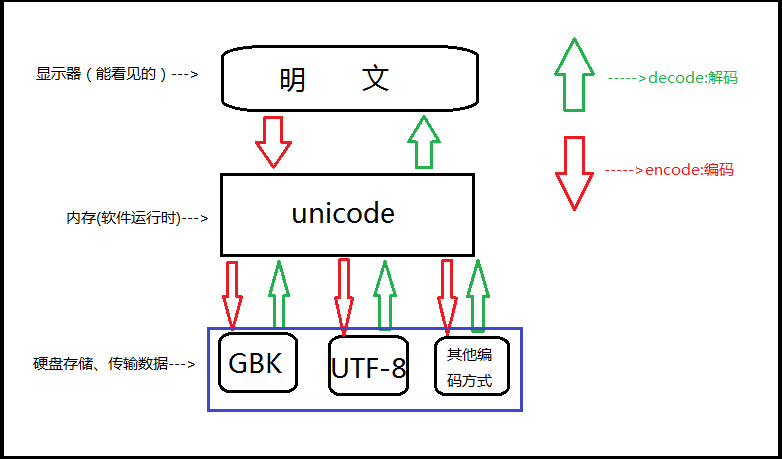
因此,内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快);硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode,这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8,因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成
utf-8格式的,而不是unicode。
三、用户交互与输出格式化
#用户交互
username = input("username:")
password = input("password: ")
print(name,password)
'''
执行结果:
username:alex
password: 233
alex 233
'''
#格式化输出1 字符串拼接
name = input("name:")
age = input("age: ")
job = input("job: ")
salary = input("salary: ")
info = '''
------- info of '''+ name + ''' -----------
Name:'''+ name + '''
Age:''' + age + '''
Job:''' + job + '''
Salary:''' + salary
print(info)
'''
执行结果:
name:alex
age: 22
job: IT
salary: 3000
------- info of alex -----------
Name:alex
Age:22
Job:IT
Salary:3000
'''
#格式化输出2 占位符 name = input("name:") age = input("age: ") job = input("job: ") salary = input("salary: ") info = ''' ------- info of %s ----------- Name: %s Age: %s Job:%s Salary:%s ''' %(name,name,age,job,salary) print(info) ''' 执行结果: name:alex age: 22 job: IT salary: 3000 ------- info of alex ----------- Name:alex Age:22 Job:IT Salary:3000 '''
# 格式化输出2 占位符
name = input("name:")
age = int(input("age: "))#input默认输入的是string类型,int()将string转换为数值
job = input("job: ")
salary = input("salary: ")
info = '''
------- info of %s -----------
Name: %s
Age: %d
Job:%s
Salary:%s
''' % (name, name, age, job, salary)
print(info)
'''
执行结果:
name:alex
age: 22
job: IT
salary: 3000
------- info of alex -----------
Name:alex
Age:22
Job:IT
Salary:3000
'''
# 格式化输出3 官方建议格式
name = input("name:")
age = int(input("age: "))#input默认输入的是string类型,int()将string转换为数值
job = input("job: ")
salary = input("salary: ")
info = '''
------- info of {_name}----------
Name: {_name}
Age: {_age}
Job:{_job}
Salary:{_salary}
'''.format(_name=name,
_age=age,
_job=job,
_salary=salary)
print(info)
'''
执行结果:
name:alex
age: 22
job: IT
salary: 3000
------- info of alex -----------
Name:alex
Age:22
Job:IT
Salary:3000
'''
四、判断与循环
#IF判断 变量赋值用一个等号,等号两边要有空格 , 判断两个变量是否相等用两个等号 _username = 'alex' _password = 'abc123' username = input("username:") password = input("password: ") if _username == username and _password == password: print("Welcome user {name} login in...".format(name=username)) else: print("Invalid username or password!") ''' 执行结果: username:alex password: abc123 Welcome user alex login in... username:alex password: 33 Invalid username or password! '''
# if 判断
age_of_oldby = 56
guess_age = int(input("guess age: "))
if guess_age == age_of_oldby:
print("yes,you got it.")
elif guess_age > age_of_oldby:
print("think smaller ...")
else:
print("think bigger!")
'''
执行结果
guess age: 99
think smaller ...
'''
#while 循环 count = 0 age_of_oldby = 56 while count < 3: guess_age = int(input("guess age: ")) if guess_age == age_of_oldby: print("yes,you got it.") break # 破坏,中断 elif guess_age > age_of_oldby: print("think smaller ...") else: print("think bigger!") count = count + 1 # count += 1 else: print("you have tried too many time..fuck off")
#while 循环 任意玩 count = 0 age_of_oldby = 56 while count < 3: guess_age = int(input("guess age: ")) if guess_age == age_of_oldby: print("yes,you got it.") break # 破坏,中断 elif guess_age > age_of_oldby: print("think smaller ...") else: print("think bigger!") count = count + 1 # count += 1 if count == 3: countine_confirm = input("do you want to keep guessing..?") if countine_confirm != 'n': count = 0 #else: # print("you have tried too many time..fuck off")
# for 循环 age_of_oldby = 56 #for i in range(0,3,2): for 循环从0开始,每次跳2个,例如 0、2 for i in range(3): guess_age = int(input("guess age: ")) if guess_age == age_of_oldby: print("yes,you got it.") break # 破坏,中断 elif guess_age > age_of_oldby: print("think smaller ...") else: print("think bigger!") else: print("you have tried too many time..fuck off")
#continue 遇到continue程序不会执行下面的语句,程序跳到循环开始继续执行 for i in range(0, 10): if i < 3: print("loop :", i) else: continue print("he he...")
#break break只会跳出内循环,外循环继续执行 for i in range(10): print("-------", i) for j in range(10): print(j) if j > 5: break
五、模块初识
python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的python库支持,以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学习2个简单的标准库。
sys
import sys print(sys.path) #打印环境变量 print(sys.argv) #打印当前程序的相对变量,但pycharm中是脚本程序的绝对路径,再pycharm中打印的是绝对路径 #pirnt(sys.argv[0]) 获取执行脚本时第一个变量值
OS
import os #cmd_res = os.system("dir")#只执行命令,不保存结果。 cmd_res = os.popen("dir").read() print('----',cmd_res) #cmd_res 打印的是命令执行是否成功,成功返回0, os.mkdir("newdir") #当前路径创建一个文件夹
六 .pyc是什么鬼?
1.Python是一门解释型语音?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释型语音,我就这样一直相信下去,知道发现了*.pyc文件的存在.如果是解释型语音,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并把一些基础概念给理清.
2.解释型语音和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个"翻译机"来从事把高级语言转变成计算机能读懂的机器语言的过程,这个过程分为两类,第一种是编译,第二种是解释.
编译型语言在程序执行前,先会通过编译器对程序执行一个编译过程,把程序转变成机器语言.运行时就不需要翻译,而直接执行就可以了.最经典的例子就是C语言.
解释型语音就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行做出翻译,然后直接运行,最经典的例子是Ruby,还有Python.
通过以上的例子,我们可以来总结一下解释型语音和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了"翻译",所以在运行时就少掉了"翻译的过程",所以效率比较高.但我们也不能一概而论.一些解释型语音也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在速度上和编译型语言比较接近.
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种.
用Java来举例,Java首先是通过编译器编译成字节码文件,然后运行时通过解释器给解释成机器文件.所以我们说Java是一种先编译后解释的语言.
3.Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧.
当我们在命令行中输入python hello.py时,其实是激活了Python的"解释器"告诉"解释器":你要开始工作了.可是在"解释"之前,其实执行的第一项工作和Java一样,是编译.
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融而成了一部而已.其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言
4.简述Python的运行过程
在说这个问题之前,我们现在说两个概念,PycodeObject和pyc文件.
我们在硬盘上看到的pyc自然不必多说,而其实PycodeObject则是Python编译器真正编译成的结果.我们先简单知道就可以了,继续向下看.
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,python解释器则将PycodeObject写回到pyc文件中.
当Python程序第二次运行时,首先程序会在硬盘中寻找pyc文件.如果找到,则直接载入,否则就重复上面的过程.
所以我们应该这样来定位PycodeObject写回到pyc文件,我们说pyc文件其实是PycodeObject的一种持久化保存方式.
七、基础数据类型初识
1、数字
2、是一个整数的例子。
长整数不过是大一些的整数。
3.23和5.23E-4是浮点数的例子。E标记表示10的冥。在这里,5.23E-4表示5.23*10-4.
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4位实数,j位虚数,数学中表示复数是什么?.
什么是数据类型?
我们人类可以很容易的分清数字与字符的区别,但是计算机并不能呀,计算机虽然很强大,但从某种角度上看又很傻,除非你明确的告诉它,1是数字,“汉”是文字,否则它是分不清1和‘汉’的区别的,因此,在每个编程语言里都会有一个叫数据类型的东东,其实就是对常用的各种数据类型进行了明确的划分,你想让计算机进行数值运算,你就传数字给它,你想让他处理文字,就传字符串类型给他。Python中常用的数据类型有多种,今天我们暂只讲3种, 数字、字符串、布尔类型
1、整数类型(int)
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
布尔值(True,False)
布尔类型很简单,就两个值 ,一个True(真),一个False(假), 主要用记逻辑判断
但其实你们并不明白对么? let me explain, 我现在有2个值 , a=3, b=5 , 我说a>b你说成立么? 我们当然知道不成立,但问题是计算机怎么去描述这成不成立呢?或者说a< b是成立,计算机怎么描述这是成立呢?
没错,答案就是,用布尔类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号