
个人项目:论文查重
| 作业所属课程 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834 |
| ---- | ---- |
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11146 |
| 这个作业的目标 | 实现论文查重算法,熟练使用PSP表格,熟练使用单元测试,熟练使用代码质量检测工具,熟练使用性能分析工具 |
#[toc]
#一、GitHub
https://github.com/birdaaron/Cosine-Similarity
#二、PSP表格
|PSP2.1|Personal Software Process Stages| 预估耗时(分钟)|实际耗时(分钟)|
| ---- | ---- |---- |---- |
| Planning |计划|10|10|
|· Estimate|估计这个任务需要多少时间 |10|10|
| Development | 开发|290|470|
|· Analysis|需求分析 (包括学习新技术) |60|120|
|· Design Spec|生成设计文档 |0|0|
|· Design Review | 设计复审|0|0|
|· Coding Standard | 代码规范 (为目前的开发制定合适的规范)|0|0|
|· Design |具体设计 |20|20|
|· Coding |具体编码 |120|200|
|· Code Review |代码复审 |60|60|
|· Test |测试(自我测试,修改代码,提交修改) |30|70|
| Reporting | 报告|120|330|
| ·Test Report | 测试报告|90|300|
| ·Size Measurement | 计算工作量|0|0|
| ·Postmortem & Process Improvement Plan |事后总结, 并提出过程改进计划 |30|30|
| Total |合计 |420|810|
#三、接口的设计与实现过程
##1.算法原理
参考文章:https://www.cnblogs.com/airnew/p/9563703.html
简单起见,先从两个句子着手:
句子A:我喜欢分词!你喜欢吗?
句子B:我讨厌分词,你讨厌吗?
判断这两个句子的相似度的基本思路是:如果两句话的用词相似,它们的内容也就越相似。所以可以通过词频来计算两个句子的相似度。
既然要计算词频,就应该让计算机把所有用词都识别出来。
所以第一步就是分词。
分词A:我/喜欢/分词/!/你/喜欢/吗/?/
分词B:我/讨厌/分词/,/你/讨厌/吗/?/
第二部,将分词都放在一个集合里,方便统计
集合:我/你/喜欢/讨厌/吗/!/?/,/
第三步,计算词频
词频A:我(1)/你(1)/喜欢(2)/讨厌(0)/吗(1)/!(1)/?(1)/,(0)/
词频B:我(1)/你(1)/喜欢(0)/讨厌(2)/吗(1)/!(0)/?(1)/,(1)/
第四步,得出向量(词频数组)
句子A [1,1,2,0,1,1,1,0]
句子B [1,1,0,2,1,0,1,1]
得到词频后就可以开始计算相似度:如果把两个句子的向量看成是空间中的两条从原点[0,0,0,0,0,0,0,0]出发,指向[1,1,2,0,1,1,1,0]和[1,1,0,2,1,0,1,1]的线段,就可以通过计算线段夹角大小来判断两条线段是否重合/相似。
也就是说,这个角的余弦值越大,就越相似。
##2.接口设计
· 我将实现的功能大体分为两个部分:
1.文件处理TextSimilarity.java:用于读取txt文件中的字符串和创造输出文件,是程序的入口
2.相似度计算Core.java:用于将读入的文章分词,记录词频和计算相似度
· 关系图
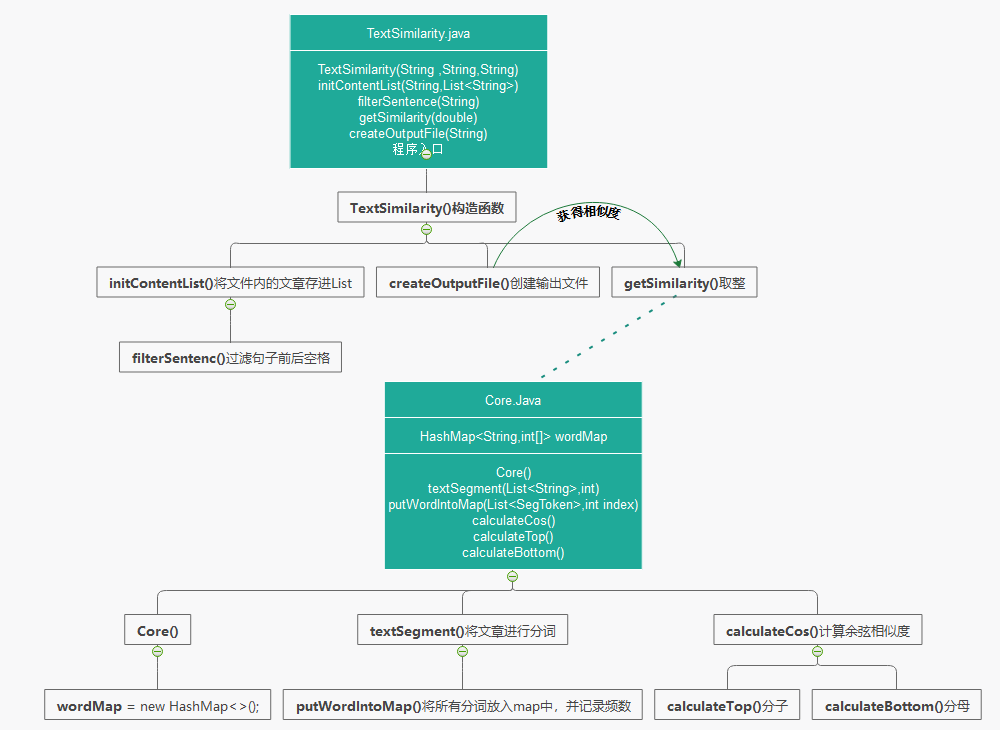
##3.关键算法
· 由于有了分词频数计算余弦值是非常简单的,那么关键就在于收集分词和统计分词频数
· 收集分词的集合是一个以分词字符串(String word)为Key,分词频数数组(int[2] count)为Value的HashMap(HashMap<String,int[]> wordMap),其中count[0]代表articleA的分词频数,count[1]则代表articleB的分词频数。

· 代码中用到的是分词器是jieba-analysis
#四、接口部分的性能改进
##1.使用SonarLint改进代码质量
· 已消除所有警告
##2.使用JProfier分析性能
###内存泄漏
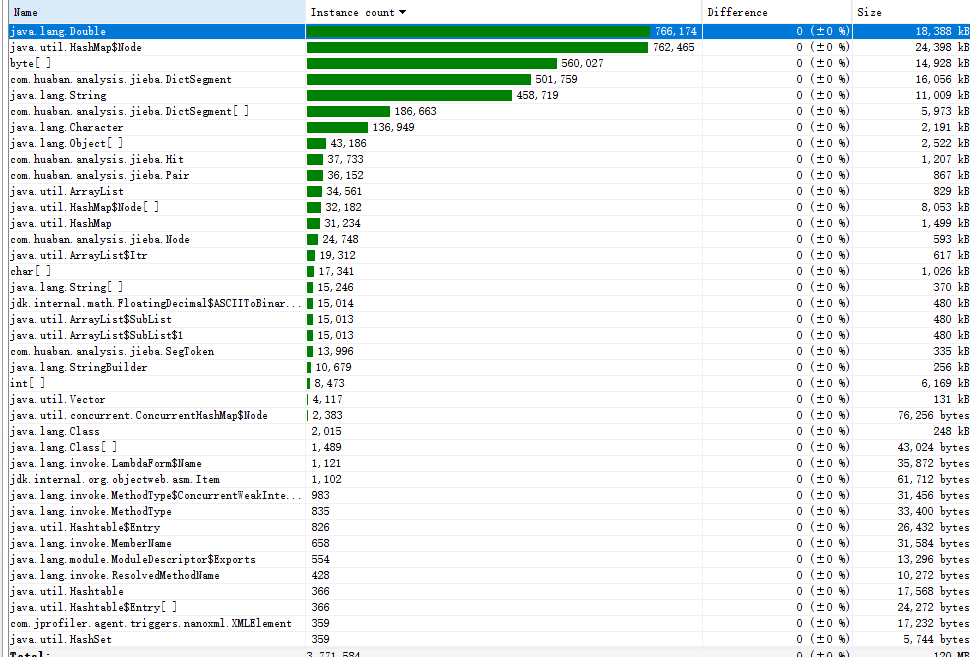
· Overview
Memory的下降代表垃圾回收

· Live memory
手动GC前,各对象占用内存
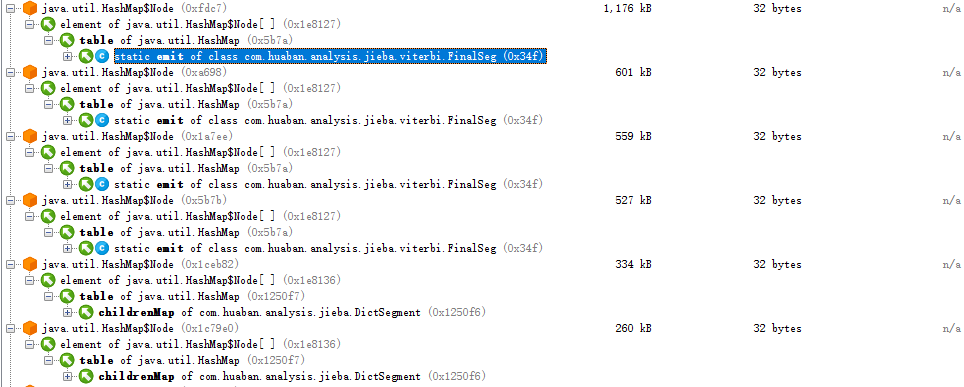
手动GC后,各对象占用内存,可见大部分HashMap被留在了内存里

· Heap walker
可见这些HashMap都是由我使用的分词器所带来的,不方便优化
###时间花费
· CallTree,可见大部分时间花费在分词上,很小部分时间花费在文件的读写
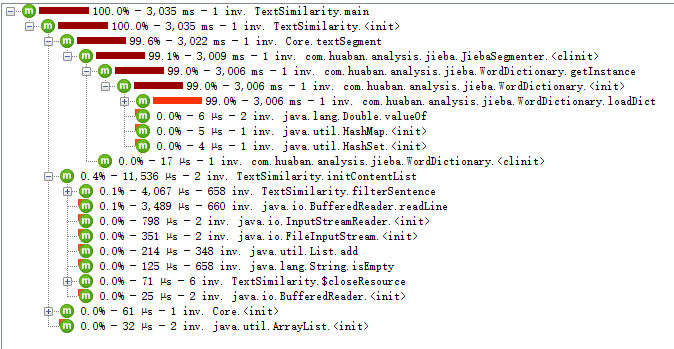
· 花费时间最多的函数
#五、单元测试展示
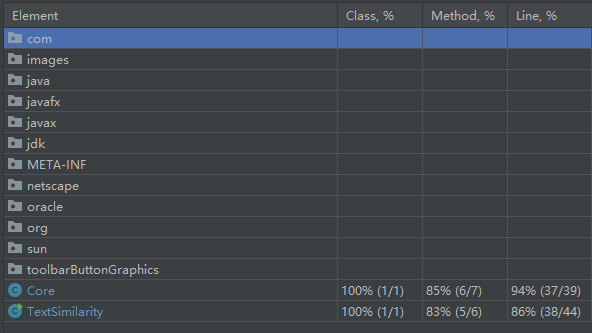
##1.测试覆盖率
##2.单元测试
###· TextSimilarityTest.java
该类主要是用于处理文件,所以主要测试是否成功从文件中读取文章和是否成功创建输出文件
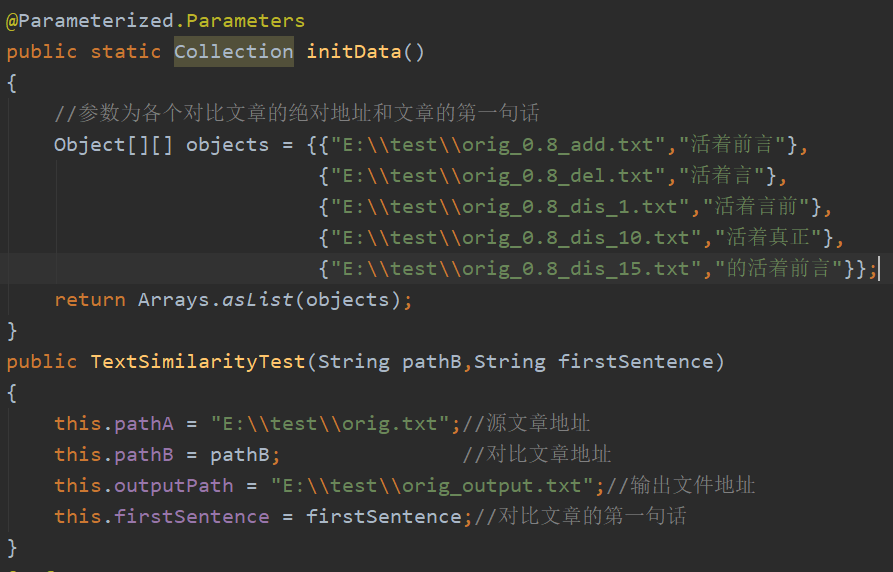
· 参数化测试
JUnit4允许开发人员使用不同的值反复运行相同的测试,initData()函数中objects包含5组数据,它们会在构造函数中被接收,相当于进行5次不同数据的测试,每组数据的第一个元素是对比文章的绝对地址,第二个元素是对比文章的第一句话(由于每篇文章的第一句话都是“活着前言”的不同变句,由此用来测试对应文章是否成功被读取到List中)
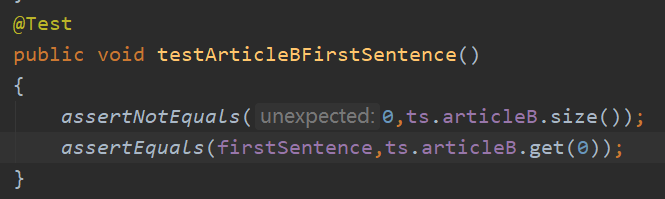
· void testArticleBFirstSentence() 测试对比文章是否被成功读取到List中
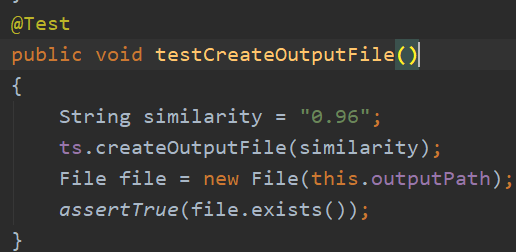
· void testCreateOutputFile() 测试输出文件是否成功创建
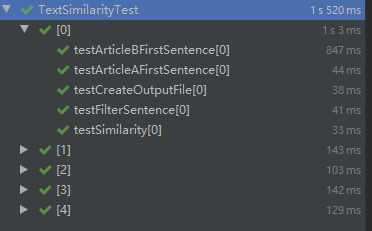
· 测试结果
###· CoreTest.java
该类主要用于分词、统计词频和计算相似度,其中计算相似度比较简单,重点在于测试前两个功能。
· 测试数据

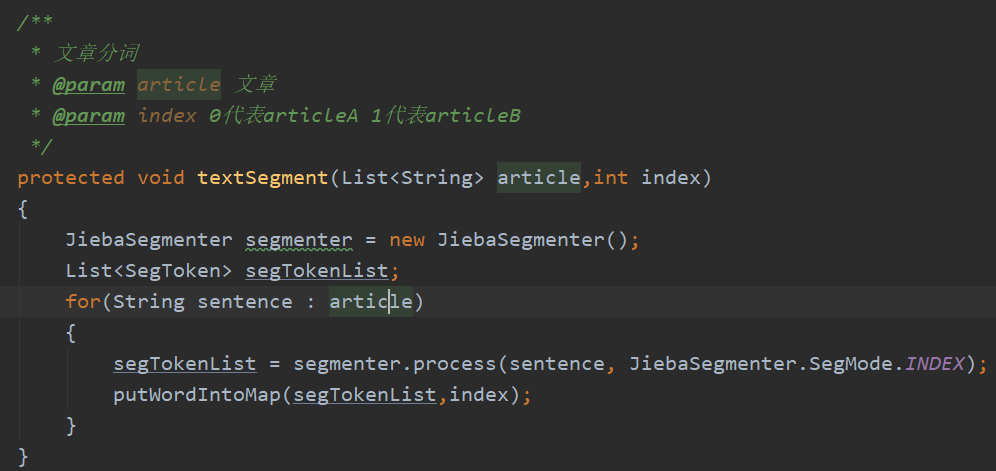
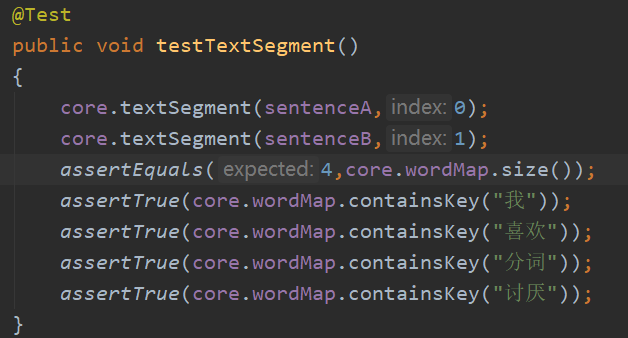
· void testTextSegment()测试分词结果和词频统计结果
· 测试结果
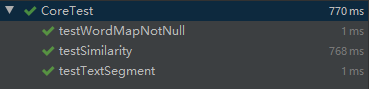
###· 文章相似度测试
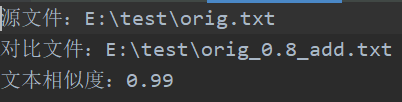
· orig.txt与orig_0.8_add.txt
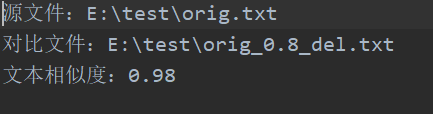
· orig.txt与orig_0.8_del.txt
· orig.txt与orig_0.8_dis_1.txt

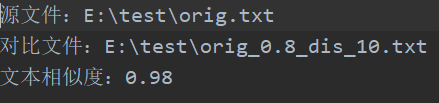
· orig.txt与orig_0.8_dis_10.txt
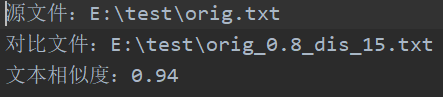
· orig.txt与orig_0.8_dis_15.txt
#六、异常处理
· FileNotFoundException
在从文件中读取字符串和创造输出文件时,如果给出的文件地址不正确,就会产生该异常
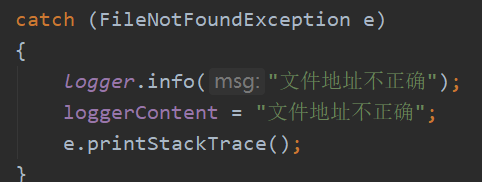
异常测试



 浙公网安备 33010602011771号
浙公网安备 33010602011771号