Spark和MapReduce的区别(计算模型角度)
本文主要从运行模式的角度分析Spark和MapReduce的计算模型的特点,更加深入这两个重要的大数据计算模型
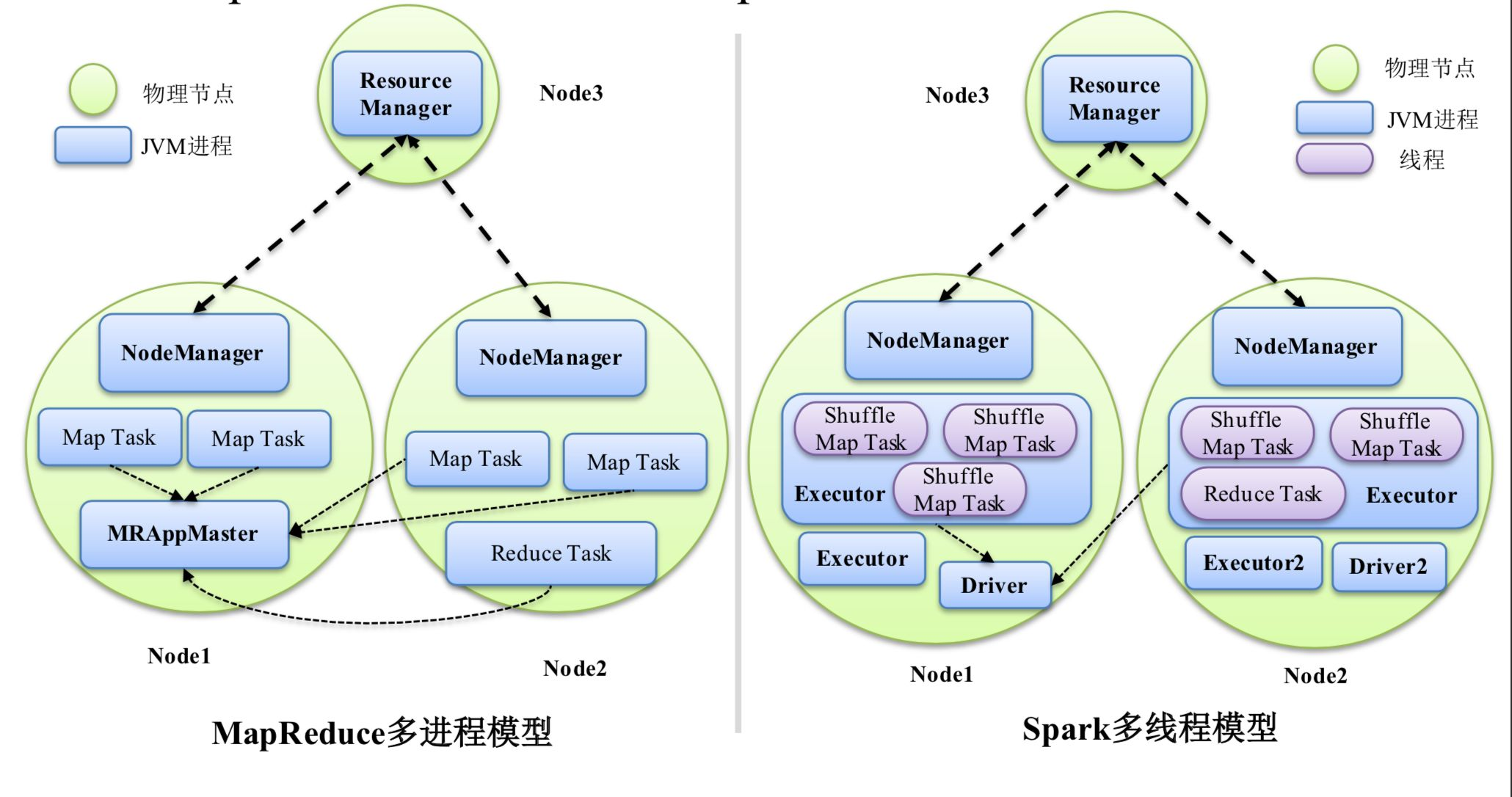
值得注意的是,如果从整体角度来看,其实Spark和MapReduce都是多进程模型,MapReduce应用程序是由多个独立的Task进程组成的,而Spark的运行环境也是由多个独立的Executor进程组成的临时资源池构成的。但从Task角度,MapReduce还是进程模式,而Spark就是多线程模式了。
MapReduce的多进程模型中每个Task都会运行在独立的JVM上,这样的好处就是资源可控,因为粒度为进程,可以很方便地为每个Task设置资源量(但目前只能设置CPU和内存两种资源),但是缺点也很多,首先就是如果一个Job包括很多Task,那么大量的JVM申请会很占用内存,甚至OOM,同时这个模型里,每个Task都要经历申请资源---->运行Task----->释放资源这样的过程,所占的资源不能被其他Task利用, 这样的特点就导致启动一个Task都是一个性能消耗很大的动作,因此MapReduce适合的是对时间要求不高也就是可以运行很长时间都不会不耐烦的作业,同时资源可控的特点也允许MR计算模型适用于需要平稳运行的大作业。
Spark的多线程模型中,运行在相同节点的Task以多线程的形式运行在同一个Executor进程中,这样运行一个Task就只需要对应启动一个线程即可,开销较小,同时多线程共享同一个Executor进程内的资源,可以节约很多非必要的内存占用,比如Spark中的广播变量就是这个道理,同一个Executor进程中可以共享变量,不用分发到每个线程中了,第三点就是Executor进程中Task结束后并不会立刻释放资源,可以为多批Task服务,这样也减少了部分性能开销。因此,Spark多线程模型可以运行一些对时间要求很快低延迟的任务,但由于粒度为线程级别,所以不好控制每个Task的资源量,所以对于大型作业不够友好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号