微服务集成Spring Cloud Zipkin实现链路追踪并集成Dubbo
1、什么是ZipKin
Zipkin是一个开源的分布式跟踪系统,可以帮助我们解决微服务架构下复杂服务调用链路的监控和分析问题。在传统的单体应用中,调试和监控是相对简单的因为所有组件都在同一个进程中。但随着微服务架构的兴起,应用程序被分解为多个小型服务,它们可能部署在不同的服务器上,甚至位于不同的数据中心或云平台上。这样一来,追踪和监控服务之间的调用链路就变得非常困难,特别是在出现性能问题或错误时。ZipKin的出现正是为了解决这个问题。它源自于Google的Dapper论文,该论文描述了Google内部的分布式追踪系统,用于监视其庞大的分布式系统的性能。Dapper发表后,Twitter通过这一思想实现了ZipKin,并于2012年开源,为开发者提供了一个简单而强大的工具来监视分布式系统的调用链路。Zipkin目前也成为了一个Apache软件基金会的顶级项目,吸引了全球范围内的开发者共同贡献和维护。
官网地址: https://zipkin.io/
Github地址:https://github.com/openzipkin/zipkin
2、安装Zipkin
在 SpringBoot 2.x 版本后就不推荐自定义 zipkin server 了,推荐使用官网下载的 jar 包方式也就是说我们不需要编写一个zipkin服务了,而改成直接启动jar包即可。
老版本jar下载地址:
https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec
老版本查看其他版本信息下载
https://central.sonatype.com/artifact/io.zipkin.java/zipkin-server/versions
最新版本的服务jar下载地址:
https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
最新版本查看其他版本信息下载
https://central.sonatype.com/artifact/io.zipkin/zipkin-server/versions
下载快速启动脚本:
https://zipkin.io/quickstart.sh
这里使用ZipKin老版本:zipkin-server-2.12.9-exec.jar
运行:
java -jar zipkin-server-2.12.9-exec.jar
# 或集成RabbitMQ
java -jar zipkin-server-2.12.9-exec.jar --zipkin.collector.rabbitmq.addresses=127.0.0.1
3、信息持久化启动
链路信息默认是存在内存中,下一次ZipKin重启后信息就会消失,所以需要信息持久化。官方提供了Elasticsearch方式与Mysql两种存储方式。本篇使用Mysql进行持久化,在正式环境推荐使用Elasticsearch进行持久化。首先创建一个zipkin数据库,然后下载数据库脚本: https://github.com/openzipkin/zipkin/blob/2.12.9/zipkin-storage/mysql-v1/src/main/resources/mysql.sql 或者复制以下sql语句在zipkin数据库中执行。
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',
PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT,
PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
启动命令:
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=1234qwer
启动成功访问服务:http://127.0.0.1:9411/zipkin/

4、微服务集成Zipkin
4.1、 引入Maven依赖
<!--依赖包含了sleuth,所以不需要再单独引入sleuth-->
<!-- sleuth :链路追踪器 zipkin :链路分析器-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<!--如果上面依赖飘红引不进来,那么原因可能是你使用的cloud版本已经移除了spring-cloud-starter-zipkin 则需要引入以下依赖-->
<!-- <dependency>-->
<!-- <groupId>org.springframework.cloud</groupId>-->
<!-- <artifactId>spring-cloud-starter-sleuth</artifactId>-->
<!-- </dependency>-->
<!-- <dependency>-->
<!-- <groupId>org.springframework.cloud</groupId>-->
<!-- <artifactId>spring-cloud-sleuth-zipkin</artifactId>-->
<!-- </dependency>-->
4.2、 配置ZipKin信息
用户模块配置:
spring:
profiles:
active: dev
application:
# 服务名称
name: user-service-model
zipkin:
enabled: true #是否启用
#zipkin服务所在地址
base-url: http://127.0.0.1:9411/
sender:
type: web #使用http的方式传输数据到, Zipkin请求量比较大,可以通过消息中间件来发送,比如 RabbitMQ
#配置采样百分比
sleuth:
sampler:
probability: 1 # 将采样比例设置为 1.0,也就是全部都需要。默认是0.1也就是10%,一般情况下,10%就够用了
订单模块配置:
spring:
profiles:
active: dev
application:
# 服务名称
name: order-service-model
zipkin:
enabled: true
#zipkin服务所在地址
base-url: http://localhost:9411/
sender:
type: web #使用http的方式传输数据到, Zipkin请求量比较大,可以通过消息中间件来发送,比如 RabbitMQ
#配置采样百分比
sleuth:
sampler:
probability: 1 # 将采样比例设置为 1.0,也就是全部都需要。默认是0.1也就是10%,一般情况下,10%就够用了
配置成功后,启动gateway-module、user-module、order-module模块相关服务。启动成功访问后台服务接口,可以看到在zipkin中已经加载了相关请求信息。
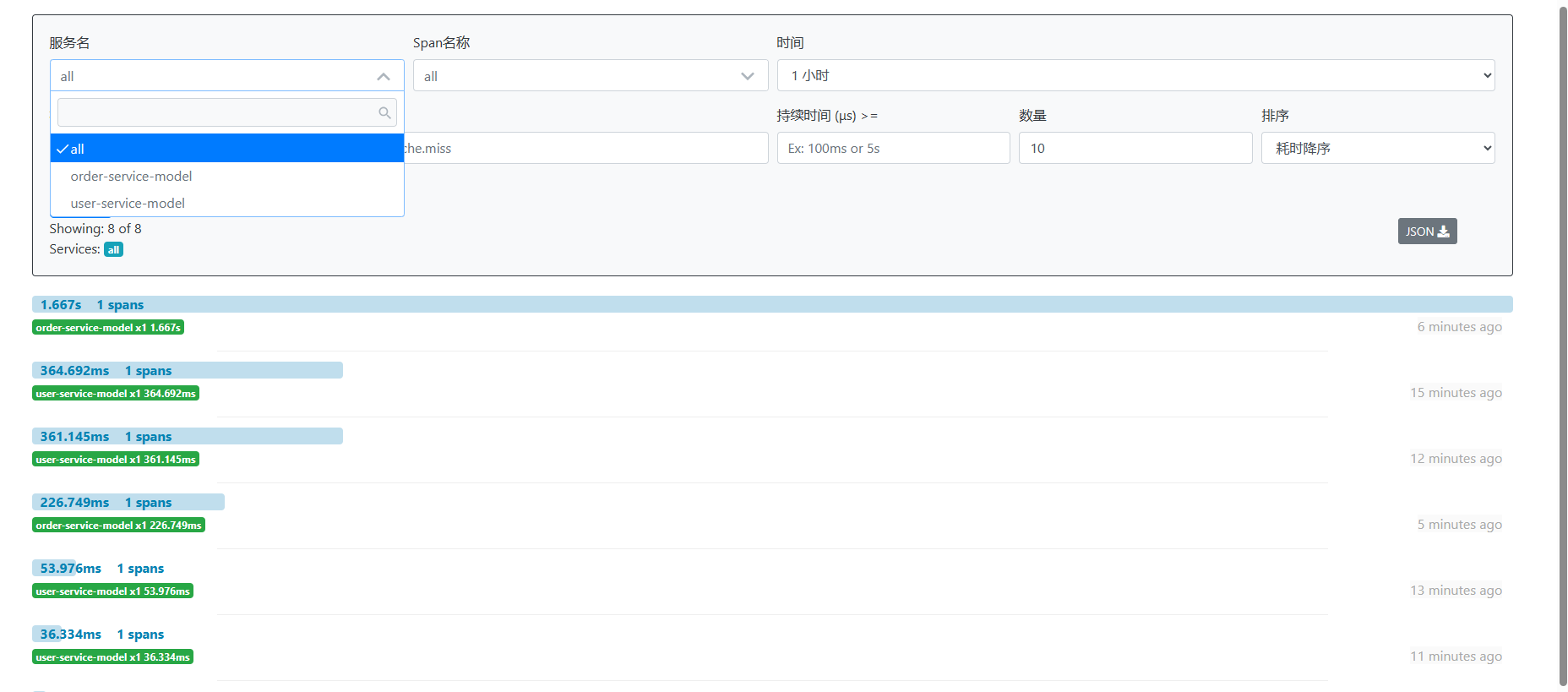
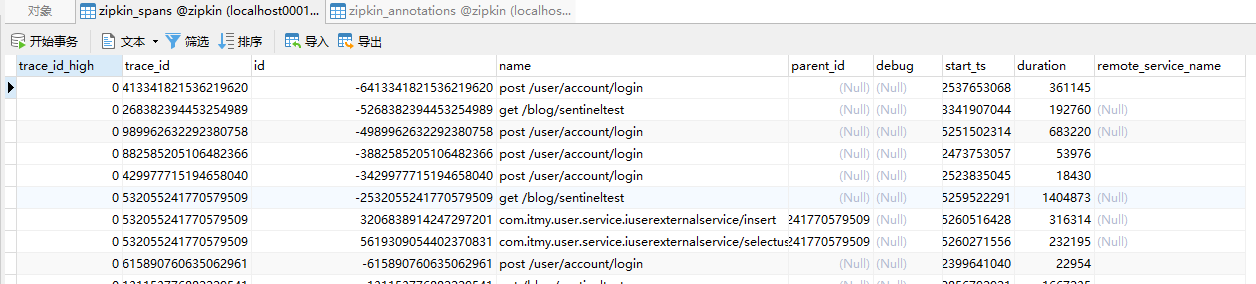
然后我们可以在看看数据库,检查下zipkin在数据库中信息是否持久化成功。查看下图可以发现数据也已经持久化成功了,这样不管zipkin重启多少次都不影响数据的展示。
5、ZipKin集成Dubbo
由于项目使用的是dubbo做为各服务模块之间的通信调用,要想zipkin采集到各服务模块的调用信息,所以需要自己去集成。操作也很方便zipkin为我们提供了集成dubbo相关依赖。首先在dubbo提供者和消费者模块中引入maven依赖:
<!--适用于 Dubbo 2.7.X 版本-->
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-dubbo</artifactId>
</dependency>
<!--适用于 Dubbo 2.6.x-->
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-dubbo-rpc</artifactId>
</dependency>
然后在dubbo配置中添加filter属性设置tracing参数,调用方:
dubbo:
application:
name: order-service-model-consumer
consumer:
group: DEFAULT_GROUP
version: 2.0
check: false
filter: tracing #tracingfilter过滤器对dubbo进行追踪
provider:
filter: tracing #tracingfilter过滤器对dubbo进行追踪
提供方:
dubbo:
application:
name: user-service-model-provider
protocol:
name: dubbo
port: -1
consumer:
check: false
filter: tracing #tracingfilter过滤器对dubbo进行追踪
provider:
filter: tracing #tracingfilter过滤器对dubbo进行追踪
group: DEFAULT_GROUP
version: 2.0
配置成功后,重新启动项目服务接口可以看出zipkin实现了对dubbo的链路追踪。查看下图可以发现该接口调用了订单和用户两个服务模块。
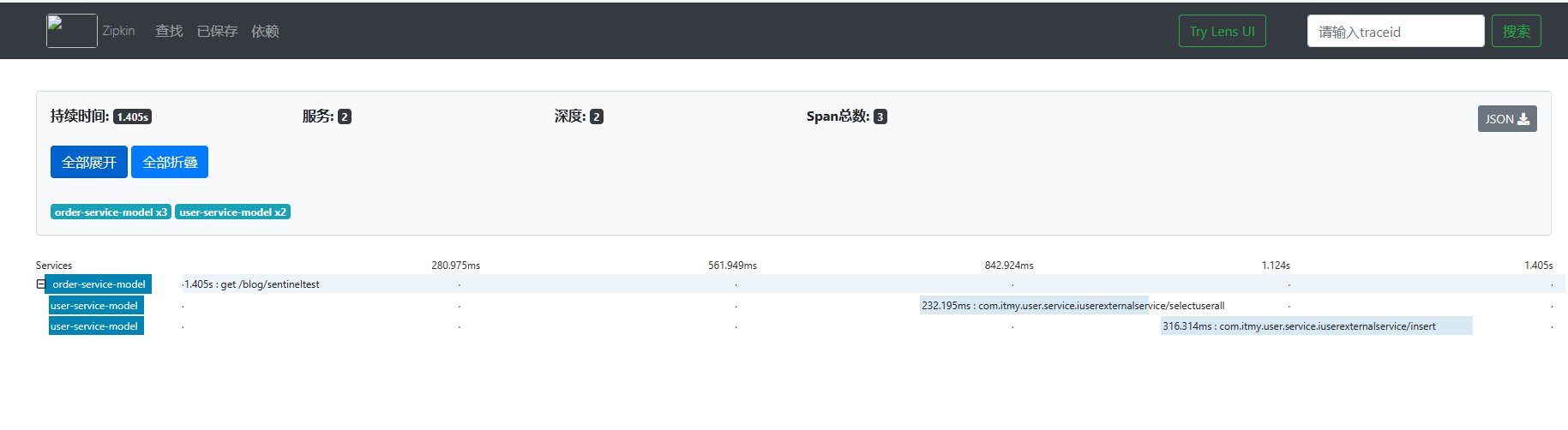
点击user-service-model可以查看出采集信息详情。
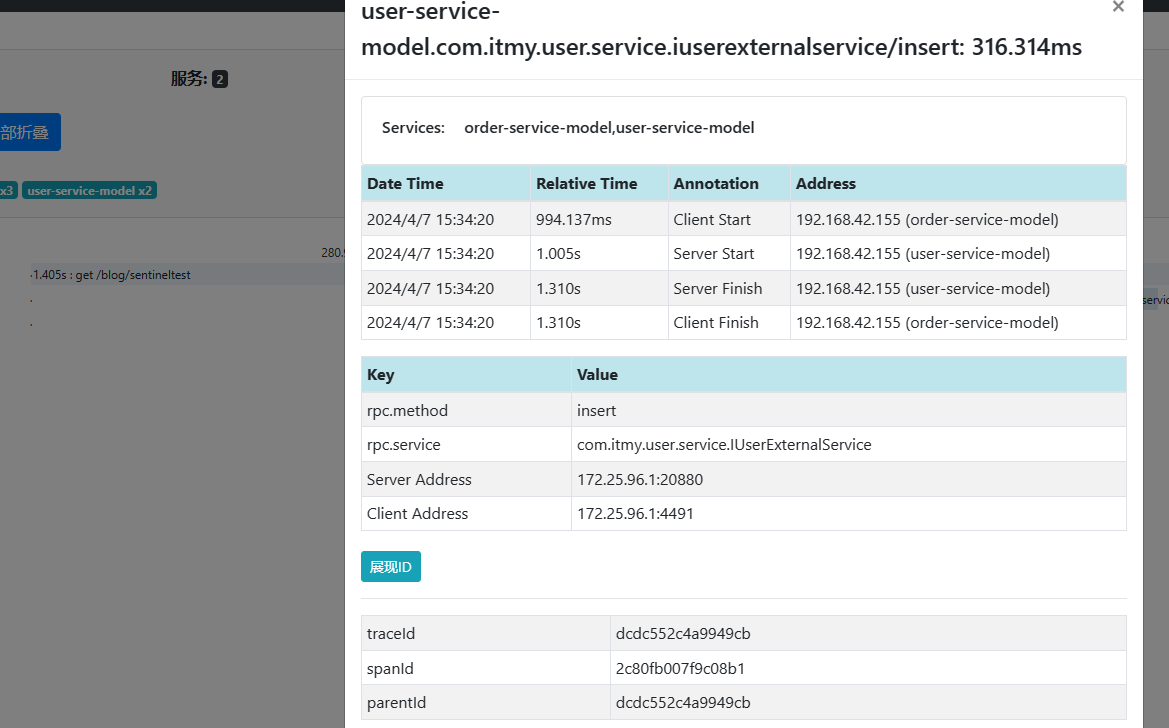
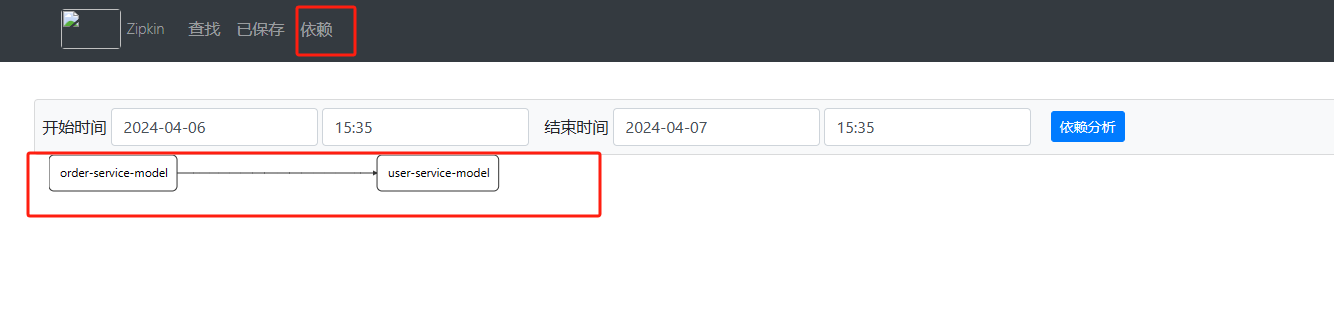
在zipkin导航菜单中,点击依赖可以查看每个服务模块的依赖信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号