游戏超高效网络/本地序列化,在C#/Unity中使用FlatBuffer,1万+小对象序列化仅140ms,0额外gc
笔者:心绪Source
未经许可,严禁转载
首先附上谷歌提供的序列化/反序列化对比图
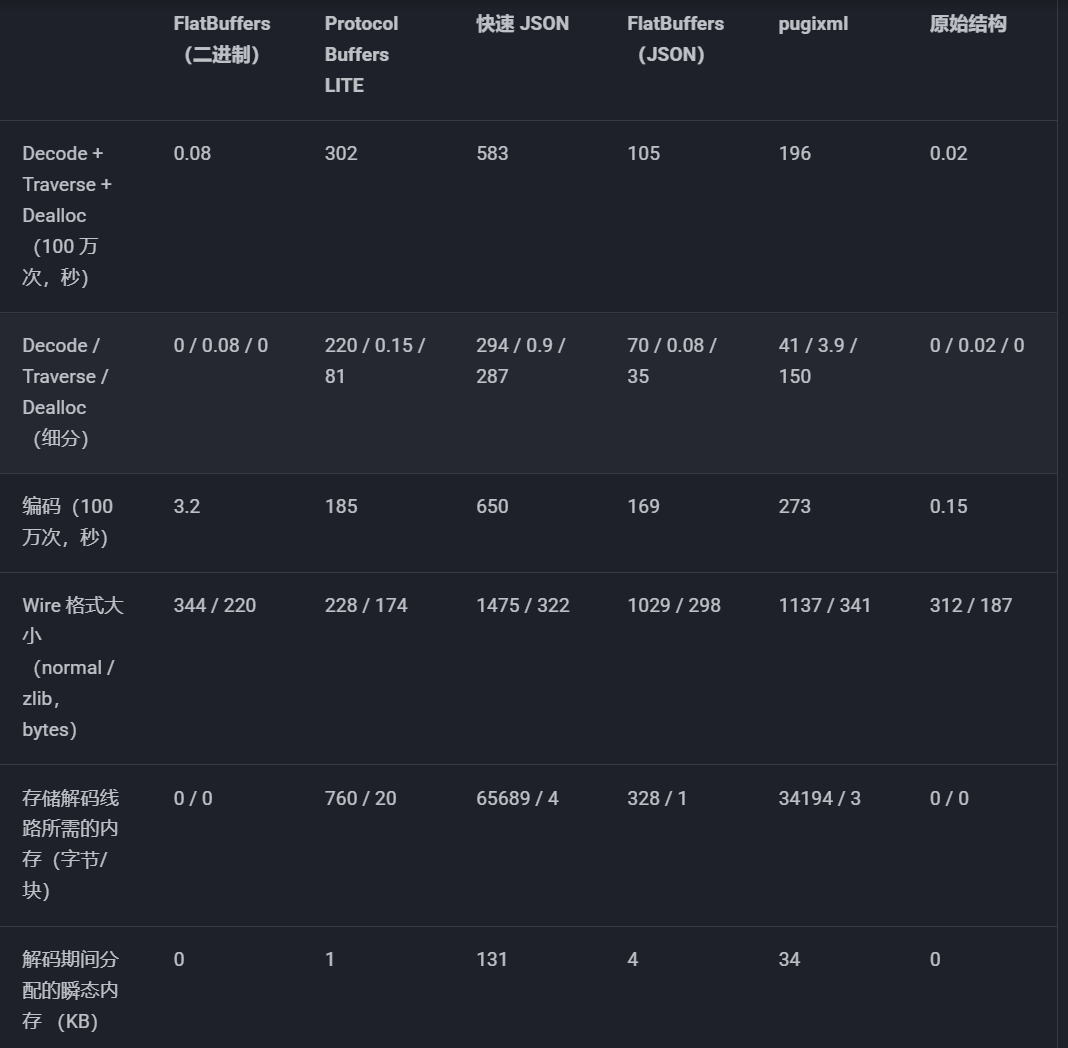
笔者在开始使用时踩到了不少坑,并对原项目支持了Span带来更高效率的序列化
首先我们要下载Flatc.exe,此程序用于将.fbs文件解析为我们.cs文件供C#项目使用
https://github.com/google/flatbuffers
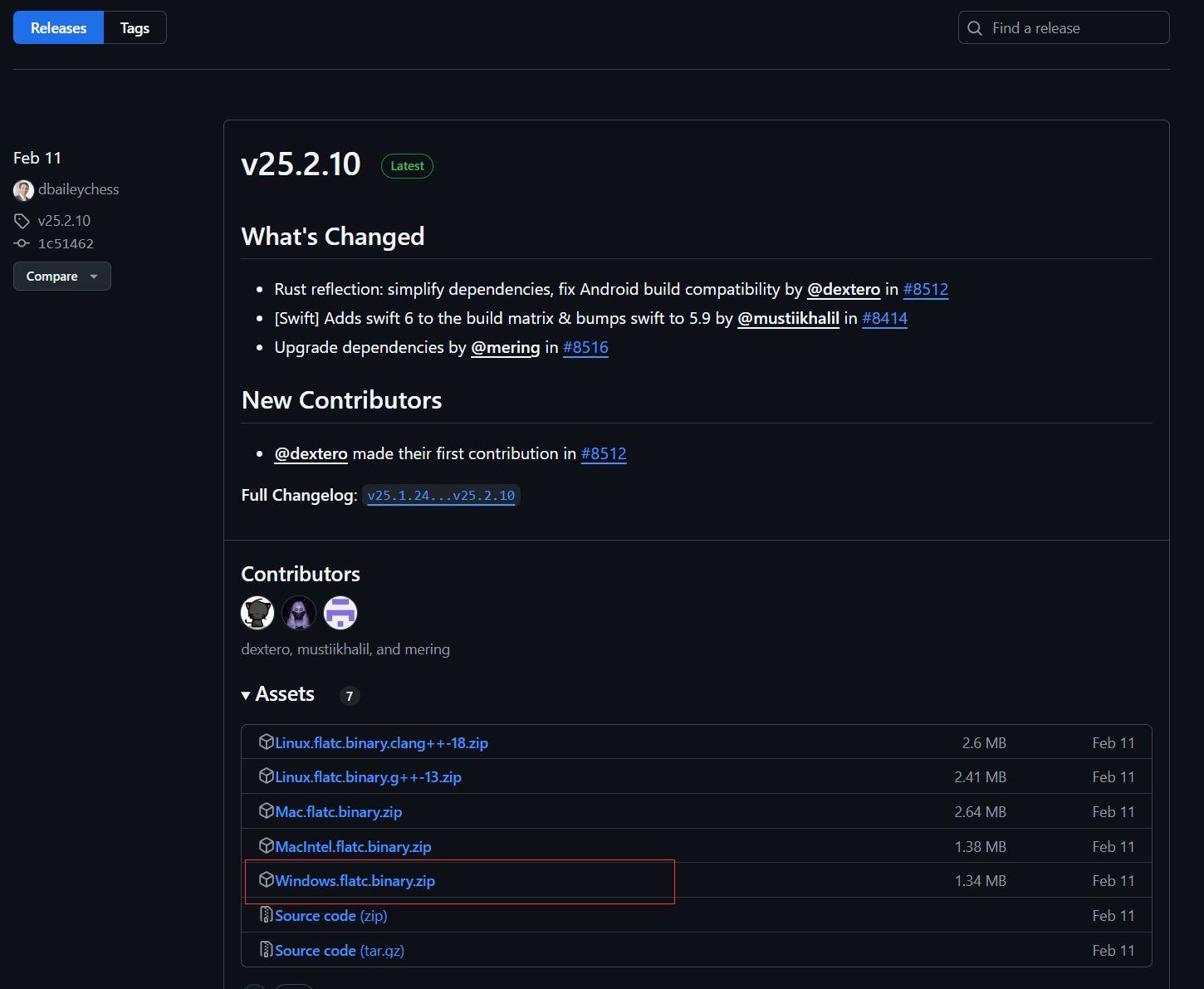
来到FlatBuffer在github中的开源界面
点击右下角releases,分发界面里下载25.2.10版本的
在Flatc.exe同级目录下写一个.bat命令
@echo off
chcp 65001 &
rem chcp 936 > nul
set "rootPath=E:\替换为项目根目录\"
for /r %rootPath% %%i in (*.fbs) do (
if not exist %%~dpiFlat_CS_Auto\ (mkdir %%~dpiFlat_CS_Auto\)
flatc --csharp --gen-onefile -I %rootPath% -I %%~dpi -o %%~dpiFlat_CS_Auto\ %%i
echo %%i 生成完成
)
pause
rem echo 完整路径: "%%i"
rem echo 驱动器: %%~di
rem echo 路径: %%~pi
rem echo 文件名(带扩展名): %%~nxi
rem echo 文件名(不带扩展名): %%~ni
rem echo 扩展名: %%~xi
rem echo 文件大小: %%~zi 字节
rem echo 最后修改时间: %%~ti
此.bat命令是从根目录开始找到所有.fbs文件,并在那个文件同级生成Flat_CS_Auto文件夹,将生成的.cs文件放入其中,
--gen-onefile 是为了如果一个.fbs定义了多个类型,那么我们只写到一个.cs文件里,而不是每个类型生成一个,
-I 代表输入文件所在的文件夹,我们-I命令传入了 项目根路径与.fbs路径,目的是.fbs如果引用了其他.fbs,我们只需要在引用文件里使用从根目录开始的相对路径就可以找到被引用文件
-o 代表生成.cs文件输出位置
最后空格后面的%%i是.fbs文件名,程序会从输入的-I路径依次寻找
接下来我们讲.fbs语法
// example IDL file
include "BasicData.fbs";
namespace MyGame;
enum Color : byte { Red = 1, Green, Blue }
struct Vec2 {
x : float;
y : float;
}
table Monster {
pos : Vec2;
pos_array : [Vec2];
mana : short = 150;
name : string;
friendly : bool = false;
inventory : [float];
color : Color = Blue;
dic_key : [string];
dic_value : [int];
}
- 支持//代码注释
- 除注释外不可使用中文
- include 后面跟相对路径,相对于我们.bat命令里-I的后面的路径
- namespace 可以指定命名空间,生成的C#代码自动在此命名空间下
- struct 结构体,结构体里面只能有基本类型,结构体可以相互嵌套,结构体数据会被直接嵌入父数据,解码比表更快
- tabel 表,表内可以有任意类型对象,表数据不会被嵌入父数据,而是单独存在,父数据仅持有表指针,所以解码要先从父数据中获取指针然后再去找表数据
- 字段名 : 字段类型 ,字段名必须使用小写,单词之间可以使用_分割,[字段类型]代表数组,= 后面跟默认值;
- 如果字段类型是引用的其他文件中的,需要从 命名空间.类型 ,同命名空间可以省略
接下来我们调用.bat生成我们的.cs文件,并将.cs放入工程中,可能会报错先不管
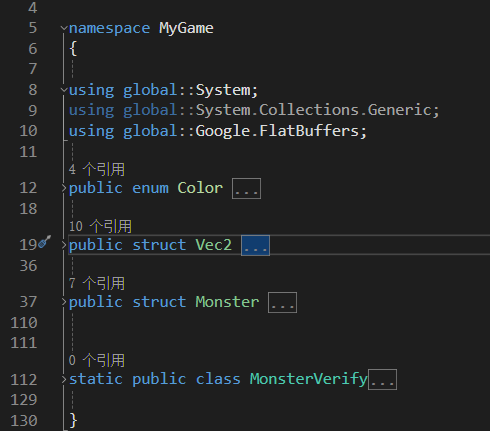
可以看到生成了我们需要的3个类,而Monster是表,所以还会额外生成他的检查器用于检查一段字节是否是Monster类型
接下来我们回到github中获取C#的源代码
下载相同版本的源代码
解压后找到
\flatbuffers-master\net\FlatBuffers
将整个FlatBuffers文件夹作为代码的一部分放入项目中,现在之前的报错应该都被修复了
我们还需要添加宏,如果是unity中
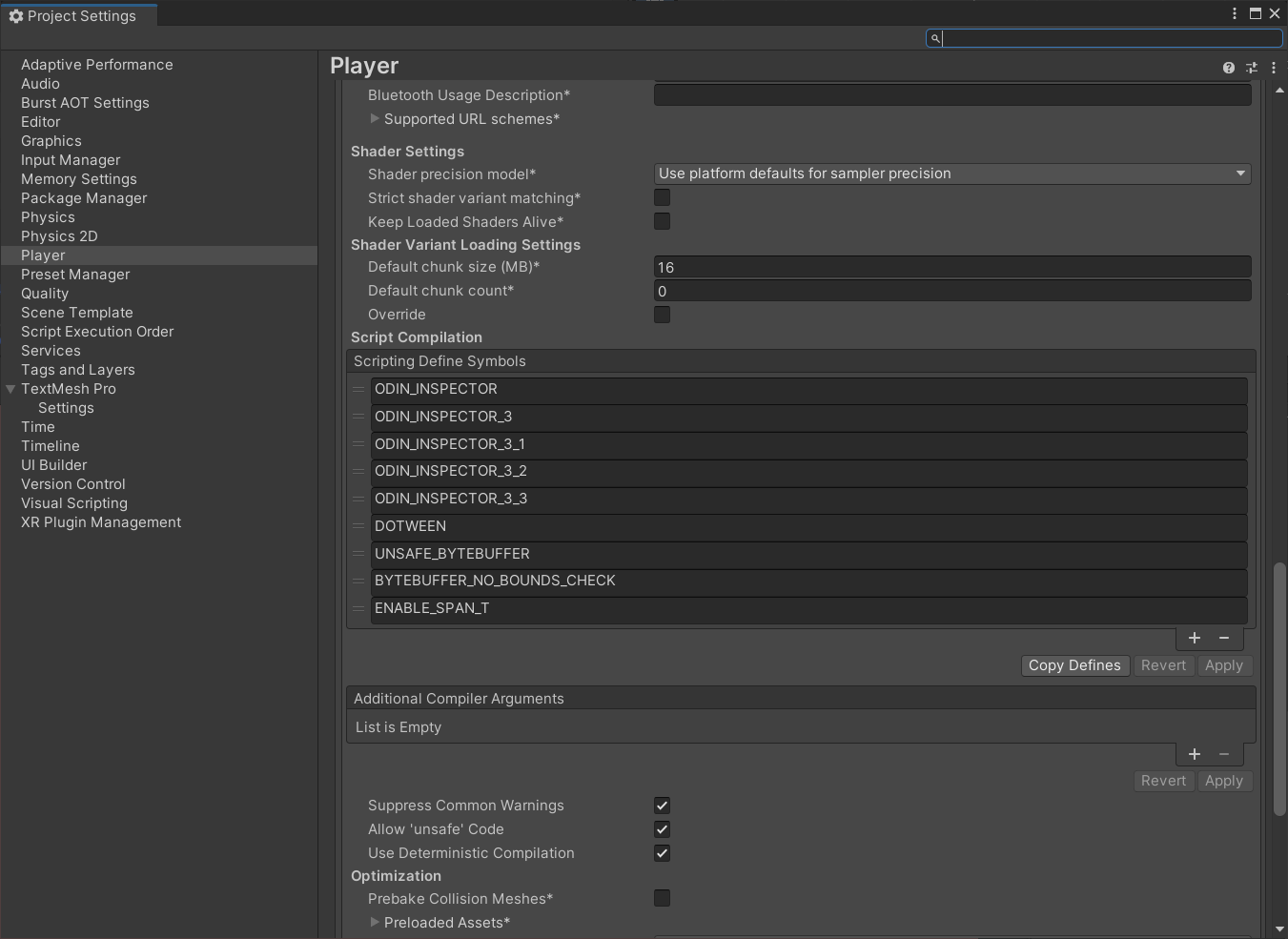
在Project Settings >> Player >> Other Settings >> Script Compliation 中
UNSAFE_BYTEBUFFER //这将使用不安全的代码来作底层字节数组。这可以产生合理的性能提升
BYTEBUFFER_NO_BOUNDS_CHECK //这将禁用对字节数组的边界检查断言。在普通代码中,这可能会产生较小的性能提升。
ENABLE_SPAN_T //这将启用使用 Span<T> 而不是 T[] 读取和写入内存块。您还可以通过提供 ByteBufferAllocator 的自定义实现来启用直接写入共享内存或其他类型的内存。 ENABLE_SPAN_T 还需要定义 UNSAFE_BYTEBUFFER 或 .NET Standard 2.1。
//对于某些操作,将 UNSAFE_BYTEBUFFER 和 BYTEBUFFER_NO_BOUNDS_CHECK 一起使用可以产生 ~15% 的性能提升,但这样做具有潜在危险。这样做的风险由您自己承担!
找到FlatBufferBuilder脚本,并将类型设置为 public partial class FlatBufferBuilder
我们再写一个扩展脚本,将下面代码复制进去
using System;
using System.Collections.Generic;
using System.Linq;
using System.Runtime.InteropServices;
using System.Text;
namespace Google.FlatBuffers
{
public partial class FlatBufferBuilder
{
/// <summary>
/// 创建指针数组的指针
/// </summary>
/// <param name="offsets">全是指针的数组</param>
/// <returns></returns>
public VectorOffset CreateVector_Offset(Span<int> offsets)
{
NotNested();
int oneObjectSize = sizeof(int);
int allObjectSize = oneObjectSize * offsets.Length;
StartVector(oneObjectSize, offsets.Length, oneObjectSize);
Prep(oneObjectSize, allObjectSize);
for (int i = 0; i < offsets.Length; i++)
{
int off = offsets[i];
if (off != 0)
off = Offset - off + oneObjectSize;
PutInt(off);
}
return EndVector();
}
/// <summary>
/// 创建基本数据数组的指针
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="datas">全是基础类型的数组</param>
/// <returns></returns>
public unsafe VectorOffset CreateVector_Data<T>(Span<T> datas) where T : unmanaged
{
NotNested();
int oneObjectSize = sizeof(T);
int allObjectSize = oneObjectSize * datas.Length;
StartVector(oneObjectSize, datas.Length, oneObjectSize);
Prep(oneObjectSize, allObjectSize);
Span<T> copyDatas = stackalloc T[datas.Length];
fixed (T* src = datas, dest = copyDatas)
Buffer.MemoryCopy(src, dest, allObjectSize, allObjectSize);
copyDatas.Reverse();
ToLittleEndian(copyDatas, oneObjectSize);
_space -= allObjectSize;
fixed (T* prt = copyDatas)
{
Span<byte> datas_byte = new Span<byte>(prt, allObjectSize);
datas_byte.CopyTo(_bb.ToSpan(_space, allObjectSize));
}
return EndVector();
}
public VectorOffset CreateVector_Builder(FlatBufferBuilder datasForm) => CreateVector_Data(datasForm.ToSpan());
private static void ToLittleEndian<T>(Span<T> array, int oneObjectSize) where T : unmanaged
{
Span<byte> bytes = MemoryMarshal.AsBytes(array);
// 如果当前系统是大端序,则反转字节
if (oneObjectSize > 1 && !BitConverter.IsLittleEndian)
{
for (int i = 0; i < array.Length; i++)
{
var elementSpan = bytes.Slice(i * oneObjectSize, oneObjectSize);
elementSpan.Reverse(); // 反转当前元素的字节序
}
}
}
public override string ToString()
{
var span = ToSpan();
StringBuilder sb = new StringBuilder(span.Length);
for (int i = 0; i < span.Length; i++)
sb.Append(span[i]);
return sb.ToString();
}
private static List<FlatBufferBuilder> pool = new List<FlatBufferBuilder>(26);
public static FlatBufferBuilder TakeOut(int size)
{
if (size <= 0) size = 1024;
int minGap = int.MaxValue;
int minGapIndex = -1;
int maxSize = size;
int maxSizeIndex = -1;
lock (pool)
{
for (int i = pool.Count - 1; i >= 0; i--)
{
var builder = pool[i];
int gap = builder.DataBuffer.Length - size;
if (gap >= 0 && gap < minGap)
{
//差距在一个size以内,直接返回
if (gap < size)
{
minGapIndex = i;
break;
}
minGap = gap;
minGapIndex = i;
}
if (builder.DataBuffer.Length > maxSize)
{
maxSize = builder.DataBuffer.Length;
maxSizeIndex = i;
}
}
FlatBufferBuilder ret = null;
if (minGapIndex != -1)
{
ret = pool[minGapIndex];
pool.RemoveAt(minGapIndex);
}
else if (maxSizeIndex != -1)
{
ret = pool[maxSizeIndex];
pool.RemoveAt(maxSizeIndex);
}
else
{
ret = new FlatBufferBuilder(size * 2);
}
return ret;
}
}
public static void PutIn(FlatBufferBuilder builder)
{
builder.Clear();
lock (pool)
{
pool.Add(builder);
}
}
public Span<byte> ToSpan() => DataBuffer.ToSpan(DataBuffer.Position, Offset);
}
}
接下来我们来序列化一个Monster类型
System.Diagnostics.Stopwatch stopwatch = new System.Diagnostics.Stopwatch();
stopwatch.Start();
//生成序列化字节数组缓存,容量不够时大小会翻倍
FlatBufferBuilder builder = new FlatBufferBuilder(1024);
//假设这些是我们的程序数据
List<Vector2> posArray = new List<Vector2>() { new Vector2(1.3f, 4.2f), new Vector2(5.3f, 8.4f), new Vector2(10.11f, 31.24f) };
string name = "心绪Source 请勿转载";
Span<float> inventory = new float[] { 3.14f, 12.009f, 2025 };
Dictionary<string, int> dic = new Dictionary<string, int>() { { "你好", 1 }, { "世界", 2 }, { "!!", 3 } };
//在Flat中,非标量数据不能嵌套序列化,每一个必须单独序列化后获取指针,将指针数组传递给需要存储的父对象
//标量类型数组区分大小端后直接被复制到缓存,非标量数组存储时需要遍历数组重新计算相对于数组头的偏移(似乎是数组头,反正需要重新计算)
//开始创建结构体数组
Monster.StartPosArrayVector(builder, posArray.Count);
//创建的时候字节流正向添加,取出的时候字节流反向取出,所以我们取出的时候从索引高位到低位取出,最后仍然是正向的
for (int i = 0; i < posArray.Count; i++)
//循环创建每一个结构体
Vec2.CreateVec2(builder, posArray[i].x, posArray[i].y);
//创建完数组后获取数组指针
VectorOffset posArrayOffset = builder.EndVector();
StringOffset nameOffset = builder.CreateString(name);
//往数组中添加基本数据时,我们使用Put方法而不是Add方法,因为StartVector方法已经将数据对齐,而每次调用Add方法都会尝试重新对齐
Monster.StartInventoryVector(builder, inventory.Length);
for (int i = 0; i < inventory.Length; i++)
builder.PutFloat(inventory[i]);
VectorOffset inventoryOffset = builder.EndVector();
//字符串的指针的数组,使用栈数组在堆开辟额外空间
Span<int> KeyOffsetArray = stackalloc int[dic.Count];
//int的值数组,为了防止字典遍历两次分别获取key和value,所以我们同时开辟两个数组存key和value
Span<int> ValueArray = stackalloc int[dic.Count];
int index = 0;
foreach (var kv in dic)
{
//循环创建每一个string并记录指针
KeyOffsetArray[index] = builder.CreateString(kv.Key).Value;
ValueArray[index] = kv.Value;
index++;
}
//使用扩展方法创建指针数组,之所以不使用StartVector方法,因为Flat中不能嵌套序列化非标量,无法在创建数组的同时创建string
VectorOffset dicOffset_Key = builder.CreateVector_Offset(KeyOffsetArray);
//基本类型使用此方法,此方法对比上方Inventory数组的创建方法更快
VectorOffset dicOffset_Value = builder.CreateVector_Data(ValueArray);
//开始生成Monster对象,完成之前不能创建非标量
Monster.StartMonster(builder);
Monster.AddPos(builder, Vec2.CreateVec2(builder, 1.2f, -2.4f));
Monster.AddPosArray(builder, posArrayOffset);
Monster.AddMana(builder, 10);
Monster.AddName(builder, nameOffset);
Monster.AddFriendly(builder, true);
Monster.AddInventory(builder, inventoryOffset);
Monster.AddColor(builder, MyGame.Color.Red);
Monster.AddDicKey(builder, dicOffset_Key);
Monster.AddDicValue(builder, dicOffset_Value);
//完成指针
int endOffset = Monster.EndMonster(builder).Value;
//将完成指针放入缓存,反序列化需要此指针
builder.Finish(endOffset);
Debug.Log("序列化一次时间" + stopwatch.ElapsedMilliseconds);
stopwatch.Restart();
using (var fileStream = new FileStream(@"D:\test.txt", FileMode.Create, FileAccess.Write))
{
fileStream.Write(builder.DataBuffer.ToSpan(builder.DataBuffer.Position, builder.Offset));
}
byte[] buffer = null;
using (var fileStream = new FileStream(@"D:\test.txt", FileMode.Open, FileAccess.Read))
{
buffer = ArrayPool<byte>.Shared.Rent((int)fileStream.Length);
fileStream.Read(buffer);
Debug.Log("长度" + buffer.Length);
}
Monster monster = Monster.GetRootAsMonster(new ByteBuffer(buffer));
StringBuilder sb = new StringBuilder();
sb.Append("Position: ").Append(monster.Pos.Value.X).Append(' ').Append(monster.Pos.Value.Y).AppendLine();
sb.Append("Position Array:").AppendLine();
for (int i = monster.PosArrayLength - 1; i >=0 ; i--)
{
var pos = monster.PosArray(i);
sb.Append(" ").Append(pos.Value.X).Append(' ').Append(pos.Value.Y).AppendLine();
}
sb.Append("Mana: ").Append(monster.Mana).AppendLine();
sb.Append("Name: ").Append(monster.Name).AppendLine();
sb.Append("Friendly: ").Append(monster.Friendly).AppendLine();
sb.Append("Inventory:").AppendLine();
for (int i = monster.InventoryLength - 1; i > 0 ; i--)
{
sb.Append(" ").Append(monster.Inventory(i)).AppendLine();
}
sb.Append("Color: ").Append(monster.Color).AppendLine();
sb.Append("Dictionary:").AppendLine();
for (int i = monster.DicKeyLength-1; i >= 0; i--)
{
sb.Append(" Key: ").Append(monster.DicKey(i))
.Append(", Value: ").Append(monster.DicValue(i)).AppendLine();
}
Debug.Log(sb.ToString());
Debug.Log("反序列化一次时间" + stopwatch.ElapsedMilliseconds);
stopwatch.Restart();
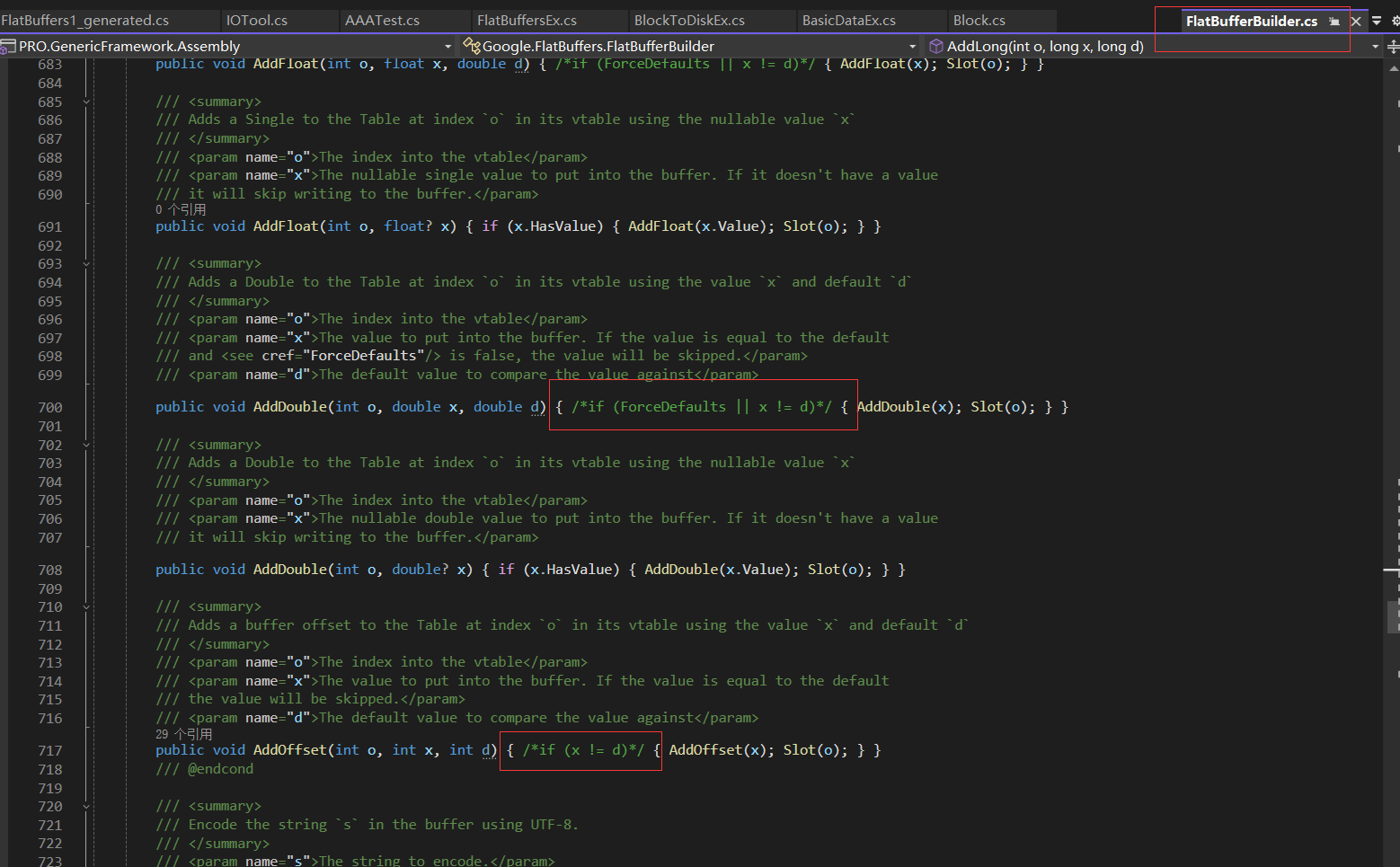
我们还应当在FlatBufferBuilder.cs文件中注释掉所有的
if (ForceDefaults || x != d)
if (x != d)
这两个判断在单独添加一个基础类型的时候判断值是否为默认值,如果是默认值就不添加,但是在工程上,我们如果有不想添加的值就根本不会调用添加方法,并且这个判断会比较两个浮点数是否相同,即不准确又性能浪费
最后我们来看序列化的效率
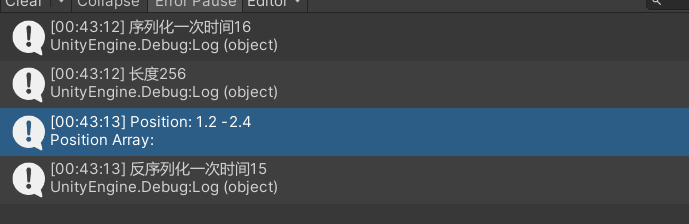
序列化时间为16ms,反序列化时间为15ms,字节流大小为256字节
FlatBufferBuilder对象可以复用,Clear指针置零,无需清理对象,我们初始FlatBUfferBuilder创建的过程中应当指定初始值,放置扩容时丢弃旧数组
结论:
序列化与反序列化非常之快,序列化与反序列化过程中基本无额外堆空间开辟,ProtoBUffer序列化与反序列化会生成辅助对象,辅助对象都是引用类型,使用大量小message会造成gc压力
代价是产生的字节流完全无压缩,对比ProtoBuffer产生的字节流大了一倍,比大部分库的API使用更复杂,对比Json人类完全不可读,序列化过程中非标量值不能更改,比如string,我们要先在缓存中创建string,然后获取string的指针,父对象再存指针,只能修改父对象的指向,缓存空间的原string也无法删除,最后序列化的字节流会产生额外垃圾数据
总体来说使用了较小的代价换来了巨大的性能提升
文献引用:
[https://halfrost.com/flatbuffers_encode/#toc-7](深入浅出 FlatBuffers 之 Encode)
[https://flatbuffers.dev/tutorial/#vectors](FlatBuffer Docs)
[https://github.com/google/flatbuffers]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号