SQL Server数据归档的解决方案
最近新接到的一项工作是把SQL Server中保存了四五年的陈年数据(合同,付款,报销等等单据)进行归档,原因是每天的数据增量很大,而历史数据又不经常使用,影响生产环境的数据查询等操作。要求是:
1 归档的数据与生产环境数据分开保存,以便提高查询效率和服务器性能。
2 前端用户能够查询已归档的数据,即系统提供的功能不能发生改变
看起来要求不是很高,我自然会联想到两种方法,第一种新建一个与生产环境一样的数据库,把归档数据保存到这个数据库中;第二种在生产环境为每个表创建一个后缀为_Archive的表,例如Invoice, 那么就要创建一个Invoice_Archive表示存放归档的数据表。这两种方法可以用跨数据库访问或视图的方式,解决数据查询等需求。仔细分析后,弊端是需要对现行系统进行改造,即需要修改代码,以便适应对归档数据的访问,实际也把数据访问和业务操作给藕荷了,是一个费力又不讨好的解决方法。
有没有一种方法可以不修改系统能够透明的访问生产数据和归档数据呢?当然是有的,就是SQL Server提供的分区表。
在这里就不累赘复述分区表的定义和作用了,要想精通就要认真读微软官方文档:SQL Server 2005 中的分区表和索引。我浓缩的作用就是,通过使用分区表可以将数据表分割到不用的磁盘文件中,不同的磁盘就意味着性能的提升,因为两个磁头读取数据当然要比一个磁头读取数据快了,然后用户可以透明地根据不同的访问方式选取数据。举个例子:一个合同表,有个字段Archived标识是否归档(0代表未归档,1代表已归档),我们可以用分区表的方式,将合同表分成两个表分别保存在不同的磁盘,例如c和d, 当我们将一个合同设置为已归档,这条记录就会从c盘转到d盘,平时我们只查询未归档的记录,如果要查已归档的记录,也只需要select * from Contracts where Archived = 1这么简单,即透明的查询,具体的实现我们不用关心。
好了,不能光说不练,就验证一下。创建两个文件目录
创建一个测试数据库

USE Master; GO IF EXISTS ( SELECT name FROM sys.databases WHERE name = N'TestDB') DROP DATABASE TestDB; GO CREATE DATABASE TestDB ON PRIMARY (NAME='TestDB_Part1', FILENAME= 'D:\TestData\Primary\TestDB_Part1.mdf', SIZE=10, MAXSIZE=100, FILEGROWTH=1 ), FILEGROUP TestDB_Part2 (NAME = 'TestDB_Part2', FILENAME = 'D:\TestData\Secondary\TestDB_Part2.ndf', SIZE = 10, MAXSIZE=100, FILEGROWTH=1 ); GO
查看数据属性,有点不一样
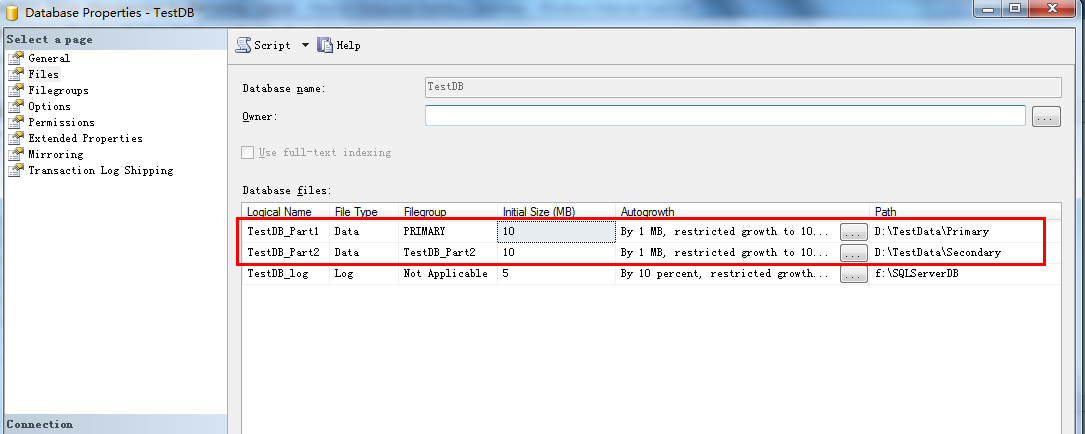
打开数据:
新建分区函数,参数类型是bit,即已归档的数据
新建一个分区方案,即已经归档的数据保存到TestDB_Part2分区文件上
创建一个测试数据表,绑定一个分区方案
插入一些新的数据,已供测试
先来一个普通查询

看看每个分区表存放数据的情况,分区一有3条记录,分区2没有记录,即没有归档数据

好了,我们归档一条记录看看

结果就是我们想要的。
总结:利用分区表不仅能大幅提升数据访问性能,而且可以根据需要分别存储数据到不同的文件,方便我们有效地利用数据,简化系统开发的复杂性。
https://www.cnblogs.com/qq260250932/p/5479037.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号