技术分享-一致性哈希算法
背景来源
一致性哈希算法
数据倾斜问题
1、背景来源
1)分布式缓存使用HASH分配存在的问题: 服务器数量变动的时候,所有缓存的位置都要发生改变。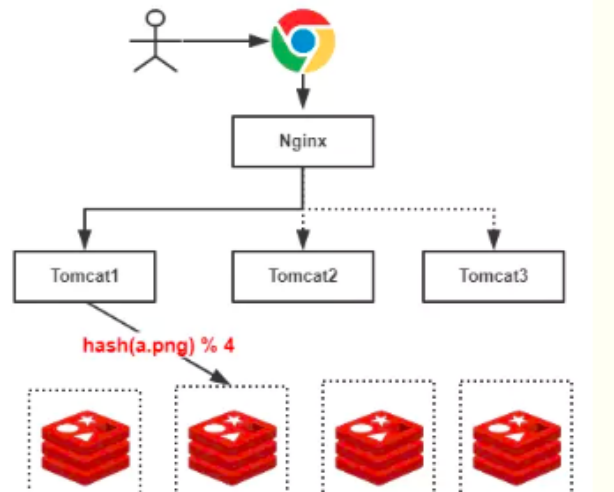
2、一致性哈希算法
1)全量的缓存空间当做一个环形存储结构,分成2^32个缓存区。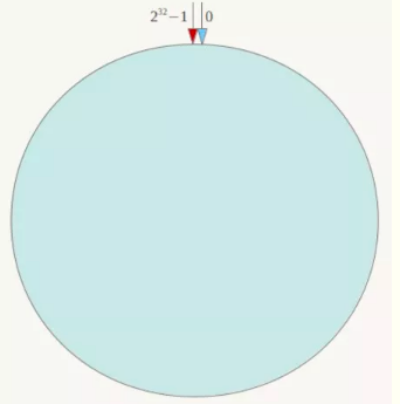
2)将服务器通过Hash算法映射到环形空间。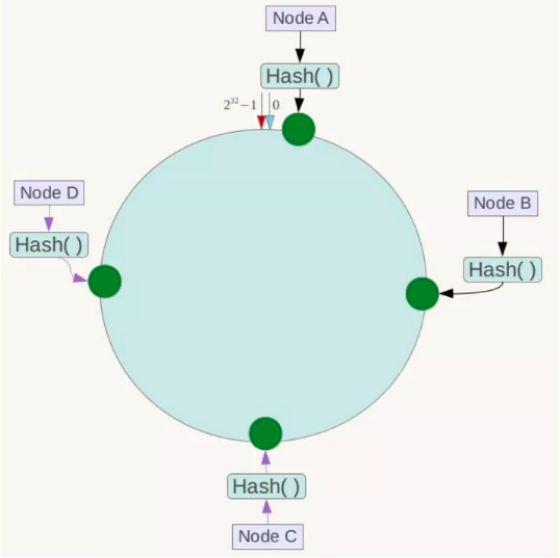
3)将缓存key通过同样的Hash算法映射到环形空间。再按照顺时针方向最近节点,就是key所归属的存储节点。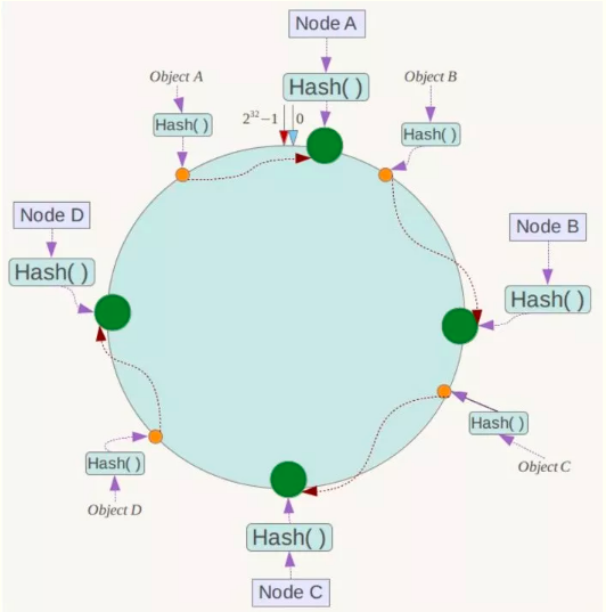
4)假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。在一致性Hash算法中,如果一台服务器不可用,受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据。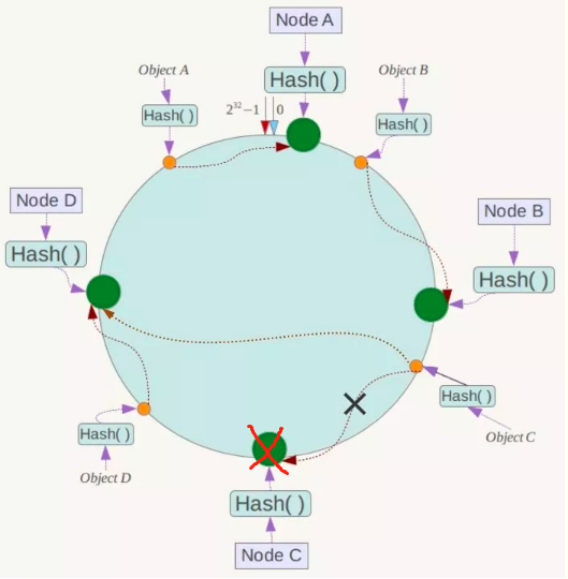
5)在系统中增加一台服务器Node X,对象Object A、B、D不受影响,只有对象C的部分数据需要重定位到新的Node X。在一致性Hash算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。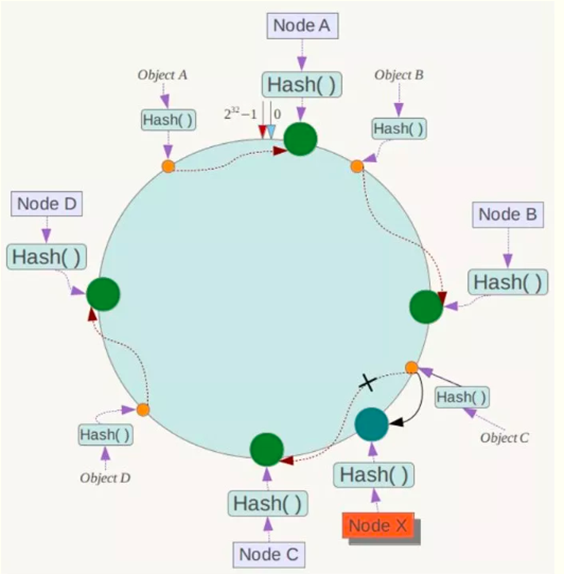
3、数据倾斜问题
1)一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题。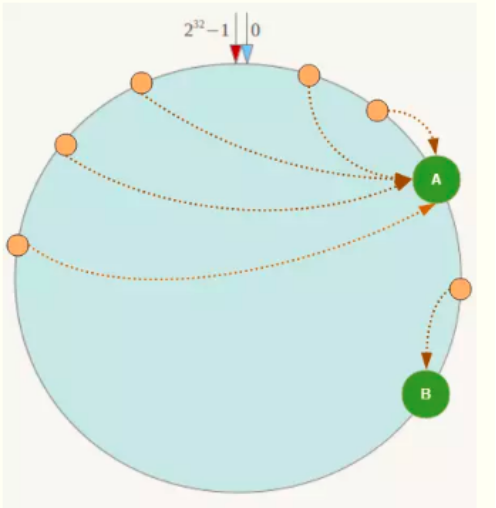
2)为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。具体做法可以在服务器IP或主机名的后面增加编号来实现。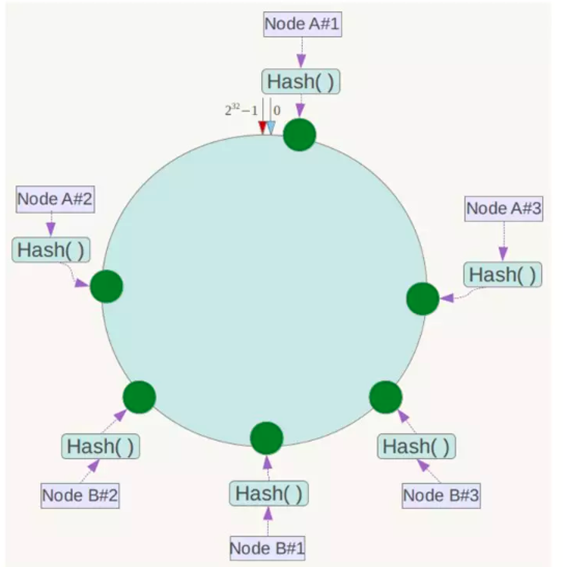
独乐乐不如众乐乐!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号