1 目标
- 计算用户使用率及使用概率分布
![]()
-
1.2 程序顺序
- df1: 三会终端用户登陆数据
- df2: 用户信息数据
- df3: 公告数据
- df4: df1+df2
- df5: 用户首次登陆时间
- df: 用户登录时间与公告时间左连接,并去除登陆前公告时间
- df6: 统计公告数S,df用户与公告时间去重后groupby用户
- df7: 统计使用次数T,df用户公告时间与登录时间之差小于等于7 days
- df8: 用户使用率,df7/df6
- df9: 有效公告时间,df用户公告时间与登录时间之差小于等于7 days
- df10: 总体公告时间df, 并根据公告时间用户代码排序(例如用户公告数S=5,根据时间前后关系排序1、2、3、4、5
- df11: df10,df9左连接,新增列判断有效公告时间对应总体公告时间位置
- df12: 归一化分子计算
- df13: 归一化分母计算
- df14: df12,df13连接
- df15: 归一化计算
- df16:整合用户信息,使用率,用户使用时间轴分布(归一化)
- data: 输出结果
-
2 数据清洗
》下载三会终端数据用户登录数据:
- 登录kibana:https://kibana.
import pandas as pd df1 = pd.read_csv("D:/0. data_analysis/2. data_analysis/sanhuizhongduan/data/table.csv",names = ["companyCode","date","loginTimes"]) df1 = df1.drop(index=0) # 去除首行自带标题 # df.columns = ["companyCode","date","loginTimes"] df1['companyCode']=df1['companyCode'].str[0:6] # 清洗用户代码 """ 提取上市公司信息,去除干扰项 """ def listedCompanyExtract(df3): # 上市公司 import pandas as pd d1 = df3[df3.companyCode.str.startswith('00')] # 中小板和深主板 d2 = df3[df3.companyCode.str.startswith('30')] # 创业板 d3 = df3[df3.companyCode.str.startswith('43')] # 新三板 d4 = df3[df3.companyCode.str.startswith('60')] # 沪主板 d5 = df3[df3.companyCode.str.startswith('83')] # 新三板 d6 = df3[df3.companyCode.str.startswith('20')] # 深B d7 = df3[df3.companyCode.str.startswith('90')] # 沪B df9 = pd.concat([d1,d2,d3,d4,d5,d6,d7]).reset_index(drop=True) df6 = df3[df3.companyCode.str.startswith('58')] # 提取以companyCode以58开头的行 监管部门 df4 = df3[df3.companyCode.str.startswith('1')] # 提取以companyCode以1开头的行 中介机构 df7 = df3[df3.companyCode.str.startswith('78')] # 提取以companyCode以78开头的行 拟上市 df8 = df3.append([df9,df7,df6,df4]) df8.drop_duplicates(keep = False,inplace = True) # 提取剩余其他数据 return df9,df7,df6,df4,df8 d = listedCompanyExtract(df1) df1 = d[0] df1.shape
2.2 处理用户信息数据
》下载用户数据:
- 登录内部管理系统:http://cms.easy-
df2 = pd.read_excel("D:/0. data_analysis/2. data_analysis/sanhuizhongduan/data/客户管理_191030165630.xls") df2 = df2[["公司代码","公司简称","所在省市","所属区域","签约状态"]] # 提取所需特征 df2.rename(columns={"公司代码":"companyCode","公司简称":"companyName", "所在省市":"provinceOrcity","所属区域":"region","签约状态":"contractStatus"}, inplace = True) """处理所在省市""" provinceOrcity1 = df2["provinceOrcity"].tolist() provinceOrcity = [] for i in provinceOrcity1: provinceOrcity.append(i.split("-")[0]) df2["provinceOrcity"] = provinceOrcity """公司代码处理""" def companyCodeDeal(df3): import numpy as np df3=df3.dropna(subset=['companyCode']) # 去除companyCode列空值行 df3['companyCode'] = df3['companyCode'].astype(np.int64) # 转换数据列类型,去掉末尾.0 df3['companyCode']=df3['companyCode'].astype(str).str.zfill(6) # 补齐代码前面的0 return df3 df2 = companyCodeDeal(df2) df2.shape
2.3 处理用户公告数
》下载用户公告数据:
- 登录易董平台:https://9990
""" 1 同一文件夹下多个格式相同的数据集合并 path为文件夹所在位置,例如path = 'D:/3. shiyan/data' ,data = MergeData(path) 调用: path = 'D:/3. shiyan/data' data = MergeData(path) """ def MergeData(path): import os import pandas as pd # path = 'D:/3. shiyan/data' #设置csv所在文件夹 path = path files = os.listdir(path) #获取文件夹下所有文件名形成一个列表 df1 = pd.read_excel(path + '/' + files[0],encoding='utf-8',error_bad_lines=False)#读取首个csv文件,保存到df1中 for file in files[1:]: df2 = pd.read_excel(path +'/' + file,encoding='utf-8',error_bad_lines=False ) #打开csv文件,注意编码问题,保存到df2中 df1 = pd.concat([df1,df2],axis=0,ignore_index=True) #将df2数据与df1合并 df1 = df1.drop_duplicates() #去重 df1 = df1.reset_index(drop=True) #重新生成index # df1.to_csv(path + '/' + 'total.csv') #将结果保存为新的csv文件 return df1 path = 'D:/0. data_analysis/2. data_analysis/sanhuizhongduan/data/sanhui' df3 = MergeData(path) # df4 = df3.drop(columns=["Unnamed: 10", "Unnamed: 9","企业性质","公告类型","公告类型/业务分类"]) # 删除列 df3 = df3[["公司代码","公告日期"]] """ 处理同时存在两个代码的情况""" l1 = df3["公司代码"].tolist() l23 = [] for i in l1: companyCode = i.split(",") if len(companyCode) == 2: companyCode = [i for i in companyCode if not i.startswith("2") ] companyCode = [i for i in companyCode if not i.startswith("9") ] companyCode = str(companyCode).replace("['","").replace("']","") # print(companyCode) l23.append(str(companyCode)) df3["公司代码"] = l23 df3.rename(columns={"公司代码":"companyCode","公告日期":"bulletinData",}, inplace = True) df3.drop_duplicates(subset=["companyCode","bulletinData"],inplace = True) # 去除同一天的重复值
3 数据整合与计算
3.1 整合用户信息并选择时间范围内用户数据
- 数据时间范围选择
"""用户登录信息与用户信息合并""" df4 = pd.merge(df1, df2, on = "companyCode", how="left") df4 = df4[["date","companyCode","companyName","provinceOrcity","region","contractStatus","loginTimes"]] # df4["loginTimes"] = 1 df4 = df4.dropna(subset=['companyCode', 'companyName']) """选取时间范围内有效数据""" import time df4 = df4.sort_values(['companyCode','date'],ascending = True) df4['date'] = pd.to_datetime(df4['date']) df4 = df4.set_index('date') df4 = df4['2019-10-14':'2019-10-20'] df4['date']= df4.index.get_level_values(0).values df4 = df4.reset_index(drop=True)
3.2 时间范围内用户首次登录时间
df5 = df4.sort_values(['companyCode','date'],ascending = True) df5 = df5.drop_duplicates(subset = ["companyCode"], keep='first') df5.shape
3.3 整合用户登录时间与发布公告时间
df = pd.merge(df4, df3, on = "companyCode",how = "left") # 基于登录用户进行连接 df.shape """去除用户首次登陆前发布的公告时间""" import numpy as np df["bulletinData"] = pd.to_datetime(df["bulletinData"]) df["minus"] = df["bulletinData"] - df["date"] # df["minus1"] = df["minus"] df['minus'] = df['minus'].astype(np.int64) # 转换数据列类型 df = df.loc[df["minus"] >=0] df['minus'] = df['minus'].astype(np.str) # 转换数据列类型 df['minus'] = df['minus'].str[0:-9] # df['minus'] = df['minus'].astype(np.int64) # 转换数据列类型 """ 将时间差由秒改为天数""" listd = df["minus"].tolist() for i in listd: if i =="": listd[listd.index(i)] = 0 listd1= [] for i in listd: i = int(i) listd1.append(i/60/60/24) df['minus'] = listd1 df.shape
3.4 用户登陆后发布公告次数 (开会次数S)
df6 = df.sort_values(['companyCode','bulletinData'],ascending = True) df6 = df6.drop_duplicates(subset = ["companyCode","bulletinData"], keep='first') # 同一天多次公告视为一次 df6 = df6.groupby(["companyCode"],sort = False).count() df6.shape
3.5 用户发布公告前登录使用次数 T (发布公告前7天内使用过算1次)
df7 = df.loc[df["minus"] <=7] df7 = df7.sort_values(['companyCode','bulletinData'],ascending = True) df7 = df7.drop_duplicates(subset = ["companyCode","bulletinData"], keep='first') # df7 = df7.drop_duplicates(subset = ["companyCode","date"], keep='first') df7 = df7.groupby(["companyCode"],sort = False).count() df7.shape
3.6 用户使用率(T/S)
df8 = pd.merge(df6,df7,on = "companyCode",how = "left") df8 = df8[["companyName_x","companyName_y"]] df8 = df8.fillna(0) df8.rename(columns={"companyName_x":"S","companyName_y":"T",}, inplace = True) df8["usageRate"] = df8["T"]/df8["S"]
3.7 用户使用程度归一化比较
"""获取用户有效时间范内使用三会发布公告时间""" df9 = df.loc[df["minus"] <=7] df9 = df9.sort_values(['companyCode','bulletinData'],ascending = True) df9 = df9.drop_duplicates(subset = ["companyCode","bulletinData"], keep='first') df9 = df9[["companyCode","bulletinData"]]
"""获取用户有效时间内发布公告时间""" df10 = df.sort_values(['companyCode','bulletinData'],ascending = True) df10 = df10.drop_duplicates(subset = ["companyCode","bulletinData"], keep='first') df10 = df10[["companyCode","bulletinData"]] df10['sort_id'] = df10['bulletinData'].groupby(df10['companyCode']).rank() # 根据companyCode 单独排序
df11 = pd.merge(df10,df9,on = "companyCode",how = "left")
"""获取时间范围内发布时间与使用时间统一的位置""" df11['equl'] = df11[['bulletinData_x', 'bulletinData_y']].apply(lambda x: x['bulletinData_x'] == x['bulletinData_y'], axis=1) # 使用会议管理时间和发布公告时间是否相等 df11 = df11.loc[df11["equl"] == True] df11 = df11[["companyCode","sort_id"]]
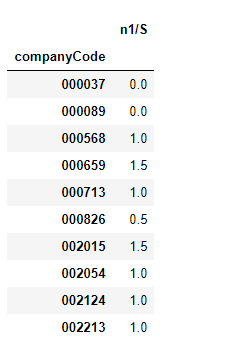
"""归一化分子,使用次数位置除以总体公告数之和""" df12 = pd.merge(df6,df11, on ="companyCode",how = "left") df12["n1/S"] = df12["sort_id"]/df12["minus"] df12 = df12.groupby("companyCode",sort =True).sum() df12 = df12[["n1/S"]] df12.head(10)
![]()
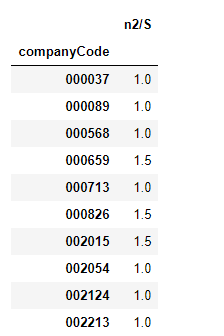
"""归一化分母,公告次数位置除以总体公告数之和""" df13 =df10 df13 = df13.drop_duplicates(subset = ["companyCode"], keep='last') df14 = pd.merge(df10,df13, on = "companyCode", how = "left") # df13["sort_id1"] = df13["sort_id"] df14["n2/S"] = df14["sort_id_x"]/df14["sort_id_y"] df14 = df14.groupby("companyCode",sort =True).sum() df14 = df14[["n2/S"]] df14.head(10)
![]()
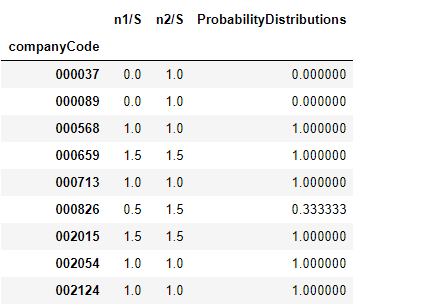
"""归一化,计算用户使用概率分布""" df15 = pd.merge(df12,df14,on = "companyCode") df15["ProbabilityDistributions"] = df15["n1/S"]/df15["n2/S"] df15.shape df15.head(10)
![]()
4 结果输出
df16 = pd.merge(df8,df15,on = "companyCode") df16 = df16[["S","T","usageRate","ProbabilityDistributions"]] data = pd.merge(df2,df16, on = "companyCode", how = "right") data.shape
data.rename(columns = {"S":"公告次数/S","T":"使用次数/T","usageRate":"使用率","ProbabilityDistributions":"连续性归一化处理"}, inplace = True) data["使用率"] = data["使用率"].apply(lambda x: format(x, '.2%')) data["连续性归一化处理"] = data["连续性归一化处理"].apply(lambda x: format(x, '.2%')) data.head(1)![]()
df5.rename(columns = {"date":"first_use_date",}, inplace = True)# 统计用户使用情况分布 list1 = data["companyCode"].tolist() list2 = df5["companyCode"].tolist() dd = data.loc[data["使用率"] != "0.00%"] dict1 = {"登录三会模块总用户数":len(list2), "登陆后有发布公告用户数":len(list1), "登陆后有使用用户数":dd.shape[0]} ddd = pd.DataFrame(dict1,index=["数量"]) # 文本表格 ddd = ddd.T
from datetime import datetime writer = pd.ExcelWriter("D:/0. data_analysis/2. data_analysis/sanhuizhongduan/三会终端数据分析%s.xls"%(datetime.now().strftime("%Y%m%d")),encoding = "sig-utf-8") data.to_excel(writer,sheet_name='登陆后发布公告用户数') df5.to_excel(writer,sheet_name='登陆总用户数') ddd.to_excel(writer,sheet_name='数据统计') writer.save() writer.close()