
一、背景目的
分析用户日志量分布情况,对数据作出解释,研究用户使用使用行为,根据分析结果提出可行性建议。
二、分析流程
- 在Kibana上导出2018/7/2-2019/6/30期间股东分析模块用户行为日志;
- 数据集清洗整理,并明确股东分析用户行为准则;
- 确定用户主体,分析用户使用分布;
- 分析用户使用留存率、流失率;
- 分析未签约用户使用情况。
三、用户行为分析过程
3.1 明确细则
中国结算发布《证券持有人名册业务实施细则》并自2018年7月2日开始实施。中国结算每个月向上市公司提供3次前200名大股东名册(包含股东人数),分别为每个月的10日、20日和月底最后一个交易日。此前为每月2次,且只提供前100大股东名册。
3.2 主要用户
股东分析主要用户为上市公司,该段日志期间该时间段范围内,证券结算机构拟提供36次股东名册,共1744家上市公司用户点击过股东分析模块,其中未签约用户436家。
3.3 用户行为次数筛选规则制定
一次点击视为一次登录;
0-10号、11-20号、21-月末期间多次行为视为一次有效行为;
四、数据清洗
4.1、数据获取(获取2018/7/2-2019/6/30 时间段该模块用户点击量)
- 搜索数据:kibana → open → analyze-login 2019
- 下载数据:save → reporting → download
4.2、数据预处理
4.2.1 同一文件夹下多个格式相同的数据集合并
由于单个excel存储容量限制,总数居集需分为多个excel进行下载存储,分析时需将多个数据集合并
""" 1 同一文件夹下多个格式相同的数据集合并 path为文件夹所在位置,例如path = 'D:/3. shiyan/data' ,data = MergeData(path) 调用: path = 'D:/3. shiyan/data' data = MergeData(path) """ def MergeData(path): import os import pandas as pd # path = 'D:/3. shiyan/data' #设置csv所在文件夹 path = path files = os.listdir(path) #获取文件夹下所有文件名形成一个列表 df1 = pd.read_csv(path + '/' + files[0],encoding='utf-8',error_bad_lines=False)#读取首个csv文件,保存到df1中 for file in files[1:]: df2 = pd.read_csv(path +'/' + file,encoding='utf-8',error_bad_lines=False ) #打开csv文件,注意编码问题,保存到df2中 df1 = pd.concat([df1,df2],axis=0,ignore_index=True) #将df2数据与df1合并 df1 = df1.drop_duplicates() #去重 df1 = df1.reset_index(drop=True) #重新生成index df1.to_csv(path + '/' + 'total.csv') #将结果保存为新的csv文件 return df1
path = 'D:/3. shiyan/data' data = MergeData(path)
4.2.2 公司代码处理
公司代码首位为0的读取后被去除,且末尾带一位小数,需将公司代码改为6位数
""" 公司代码处理 需求数据需有公司代码列,例如data['companyCode'] = data['companyCode'] """ def companyCodeDeal(df3): import numpy as np df3=df3.dropna(subset=['companyCode']) # 去除companyCode列空值行 df3['companyCode'] = df3['companyCode'].astype(np.int64) # 转换数据列类型,去掉末尾.0 df3['companyCode']=df3['companyCode'].astype(str).str.zfill(6) # 补齐代码前面的0 return df3
data['companyCode'] = data['companyCode'] data1 =companyCodeDeal(data) data1.head(1)
4.2.3 干扰项去除
去除公司内部测试产生的无效数据,股东分析模块测试数据较少。
def removeInterference(data1): data1 = data1[~data1['companyCode'].str.startswith('99')] data1 = data1[~data1['companyCode'].str.contains('600036')] data1 = data1[~data1['companyCode'].str.contains('589618')] data1 = data1[~data1['companyCode'].isin(['188027'])] data1 = data1[~data1['companyCode'].isin(['188026'])] data1 = data1[~data1['companyCode'].isin(['825000'])] data1 = data1[~data1['companyCode'].isin(['826000'])] return data1
df = removeInterference(data1)
df.shape
4.2.4 时间戳处理
将UTC时间改为东八区时间,把时间戳拆分为date,time两列
""" 时间戳处理,将UTC时间改为东八区时间 被处理数据需有@timestamp列 """ def timestampDeal(df3): # 时间处理,将UTC时间改为东八区时间,并将date和time分隔 import datetime import pandas as pd import numpy as np df3['date'] = pd.to_datetime(df3['@timestamp']) # 将@timestamp数据转化为datetime64类型保存到date中 df3['date'] = (df3['date'] + datetime.timedelta(hours=8)) # utc时间改为东八区时间+8h # 将时间和日期分隔 df3['time']= df3['date'] # 复制date 列数据到 time df3['date'] = df3.date.dt.date # 提取年月日 df3['time'] = df3.time.dt.time # 提取时间 # 将time列排序到第二列位置 df_time = df3.time df3 = df3.drop('time',axis = 1) df3.insert(1,'time',df_time) # 将date列数据排到第二列位置 df_date = df3.date df3 = df3.drop('date',axis = 1) df3.insert(1,'date',df_date) # df3.loc[:'time' ] = df3.loc[:'time'].astype('str') # 将所有格式转化为object df3['time'] = df3['time'].astype(np.str) df3['time'] = df3['time'].str[0:8] #截取用户行为时间区域,去掉末尾秒后面微秒区域 return df3
df = timestampDeal(df) df = df.sort_values("date",ascending = False) # 从大到小排序 df.tail(1)

4.2.5 其他处理
df['clickButtonName']= df['clickButtonName'].str.strip() # 去除字符串元素中左右空格 df1 = df.drop_duplicates() # 删除数据记录中所有列值相同的记录 df1.rename(columns = {'@timestamp':'timestamp','companyShortName':'companyName'},inplace = True)#列名重命名
五、数据分析
5.1 用户群体分析
股东分析用户群体为上市公司,以下代码主要用作其他模块用户群体分析
""" 用户群体划分 """ def listedCompanyExtract(df3): # 上市公司 import pandas as pd d1 = df3[df3.companyCode.str.startswith('00')] # 中小板和深主板 d2 = df3[df3.companyCode.str.startswith('30')] # 创业板 d3 = df3[df3.companyCode.str.startswith('43')] # 新三板 d4 = df3[df3.companyCode.str.startswith('60')] # 沪主板 d5 = df3[df3.companyCode.str.startswith('83')] # 新三板 d6 = df3[df3.companyCode.str.startswith('20')] # 深B d7 = df3[df3.companyCode.str.startswith('90')] # 沪B df9 = pd.concat([d1,d2,d3,d4,d5,d6,d7]).reset_index(drop=True) df6 = df3[df3.companyCode.str.startswith('58')] # 提取以companyCode以58开头的行 监管部门 df4 = df3[df3.companyCode.str.startswith('1')] # 提取以companyCode以1开头的行 中介机构 df7 = df3[df3.companyCode.str.startswith('78')] # 提取以companyCode以78开头的行 拟上市 df8 = df3.append([df9,df7,df6,df4]) df8.drop_duplicates(keep = False,inplace = True) # 提取剩余其他数据 return df9,df7,df6,df4,df8
d1 = listedCompanyExtract(df1) data999 = d1[0] # 提取上市公司数据集 data999.shape
5.2 用户签约时间段内有效行为数据
根据用户合同开始时间和结束时间,确定用户行为是否在合同期间
# 导入用户签约数据集 import pandas as pd import numpy as np data1 = pd.read_excel('D:/3. shiyan/data/签约列表_20190808.xls') data1.shape
# 两个数据集根据companyCode合并 data1 = data1[['服务公司代码','合同开始时间','合同结束时间']] data1.rename(columns={'服务公司代码':'companyCode'}, inplace = True) data999.rename(columns = {'clickButtonName':'login'},inplace = True)#列名重命名 df9 = data999[['companyName','companyCode','date','userName','login']] data2 = df9[['companyName','companyCode','date','userName','login']] loan_outer=pd.merge(data1,data2,how='outer')
# 挑选出在合同期间内的数据 dd = loan_outer dd['a1'] = pd.to_datetime(dd['date'])-pd.to_datetime(dd['合同开始时间']) dd['a2'] = pd.to_datetime(dd['合同结束时间'])-pd.to_datetime(dd['date']) dd['a1'] = dd['a1'].astype(np.str) # 数据结构转换,不然后面loc挑选时匹配不准 dd['a2'] = dd['a2'].astype(np.str) dd1 = dd.loc[dd['a1'] >"0 days"] data = dd1.loc[dd1['a2'] >"0 days"]
data = data.dropna(subset=['date']) # 去除date下空白行,无效数据
5.2 提取注册用户,新用户,老用户,新用户活跃,老用户活跃,计算新用户活跃率,老用户活跃率,总活跃率
# 用户合同期 data = data.dropna(subset=['date']) # 去除date下空白行 df0 = data.groupby(["companyCode","合同开始时间","合同结束时间"],sort = False).count() # df0['companyCode']= df0.index.get_level_values(0) # df0 = pd.Series(df0['Value'].values, index=df['Date']) df0 = df0.reset_index() # (all)index 改为 column df0 = df0.drop(df0.columns[[3,4,5,6,7,8]], axis=1) df0.shape # 用户首次行为时间 data = data.dropna(subset=['合同开始时间']) # 去除date下空白行 d1 = data.sort_values(["companyCode","date"],ascending = False) d1.drop_duplicates(subset=['companyCode'],keep = 'last',inplace = True) d1.shape lo1=pd.merge(df0,d1,how='outer',on = "companyCode") lo1 = lo1.drop(lo1.columns[[3,4,7,8,9,10]], axis=1) # 去除干扰列
"""提取单个用户首次行为时间,判断是否为新增用户""" lo1.drop_duplicates(subset=['companyCode','date'],keep='first',inplace=True) # 去除该列重复值 ,保留单个用户首次行为时间 lo1['date'] = pd.to_datetime(lo1['date']) lo1.set_index('date', inplace=True)
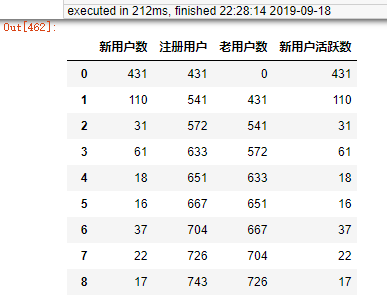
""" 按每月三次时间段划分""" df3 = lo1.groupby(["date"],sort = False).count() # 单个日期用户数统计 df3 = df3.sort_values("date",ascending = True) # 排序 df3["count"] = 1 df4 = df3['2018-7-2':'2018-7-10'] df5 = df3['2018-7-11':'2018-7-20'] df6 = df3['2018-7-21':'2018-7-31'] df7 = df3['2018-8-1':'2018-8-10'] df8 = df3['2018-8-11':'2018-8-20'] df9 = df3['2018-8-21':'2018-8-31'] df10 = df3['2018-9-1':'2018-9-10'] df11 = df3['2018-9-11':'2018-9-20'] df12 = df3['2018-9-21':'2018-9-30'] df13 = df3['2018-10-1':'2018-10-10'] df14 = df3['2018-10-11':'2018-10-20'] df15 = df3['2018-10-21':'2018-10-31'] df16 = df3['2018-11-1':'2018-11-10'] df17 = df3['2018-11-11':'2018-11-20'] df18 = df3['2018-11-21':'2018-11-30'] df19 = df3['2018-12-1':'2018-12-10'] df20 = df3['2018-12-11':'2018-12-20'] df21 = df3['2018-12-21':'2018-12-31'] df22 = df3['2019-1-1':'2019-1-10'] df23 = df3['2019-1-11':'2019-1-20'] df24 = df3['2019-1-21':'2019-1-31'] df25 = df3['2019-2-1':'2019-2-10'] df26 = df3['2019-2-11':'2019-2-20'] df27 = df3['2019-2-21':'2019-2-28'] df28 = df3['2019-3-1':'2019-3-10'] df29 = df3['2019-3-11':'2019-3-20'] df30 = df3['2019-3-21':'2019-3-31'] df31 = df3['2019-4-1':'2019-4-10'] df32 = df3['2019-4-11':'2019-4-20'] df33 = df3['2019-4-21':'2019-4-30'] df34 = df3['2019-5-1':'2019-5-10'] df35 = df3['2019-5-11':'2019-5-20'] df36 = df3['2019-5-21':'2019-5-31'] df37 = df3['2019-6-1':'2019-6-10'] df38 = df3['2019-6-11':'2019-6-20'] df39 = df3['2019-6-21':'2019-6-30'] c1 = df4.groupby("count",sort = False).sum() # 统计时间段内用户数 c2 = df5.groupby("count",sort = False).sum() # 统计时间段内用户数 c3 = df6.groupby("count",sort = False).sum() # 统计时间段内用户数 c4 = df7.groupby("count",sort = False).sum() # 统计时间段内用户数 c5 = df8.groupby("count",sort = False).sum() # 统计时间段内用户数 c6 = df9.groupby("count",sort = False).sum() # 统计时间段内用户数 c7 = df10.groupby("count",sort = False).sum() # 统计时间段内用户数 c8 = df11.groupby("count",sort = False).sum() # 统计时间段内用户数 c9 = df12.groupby("count",sort = False).sum() # 统计时间段内用户数 c10 = df13.groupby("count",sort = False).sum() # 统计时间段内用户数 c11 = df14.groupby("count",sort = False).sum() # 统计时间段内用户数 c12 = df15.groupby("count",sort = False).sum() # 统计时间段内用户数 c13 = df16.groupby("count",sort = False).sum() # 统计时间段内用户数 c14 = df17.groupby("count",sort = False).sum() # 统计时间段内用户数 c15 = df18.groupby("count",sort = False).sum() # 统计时间段内用户数 c16 = df19.groupby("count",sort = False).sum() # 统计时间段内用户数 c17 = df20.groupby("count",sort = False).sum() # 统计时间段内用户数 c18 = df21.groupby("count",sort = False).sum() # 统计时间段内用户数 c19 = df22.groupby("count",sort = False).sum() # 统计时间段内用户数 c20 = df23.groupby("count",sort = False).sum() # 统计时间段内用户数 c21 = df24.groupby("count",sort = False).sum() # 统计时间段内用户数 c22 = df25.groupby("count",sort = False).sum() # 统计时间段内用户数 c23 = df26.groupby("count",sort = False).sum() # 统计时间段内用户数 c24 = df27.groupby("count",sort = False).sum() # 统计时间段内用户数 c25 = df28.groupby("count",sort = False).sum() # 统计时间段内用户数 c26 = df29.groupby("count",sort = False).sum() # 统计时间段内用户数 c27 = df30.groupby("count",sort = False).sum() # 统计时间段内用户数 c28 = df31.groupby("count",sort = False).sum() # 统计时间段内用户数 c29 = df32.groupby("count",sort = False).sum() # 统计时间段内用户数 c30 = df33.groupby("count",sort = False).sum() # 统计时间段内用户数 c31 = df34.groupby("count",sort = False).sum() # 统计时间段内用户数 c32 = df35.groupby("count",sort = False).sum() # 统计时间段内用户数 c33 = df36.groupby("count",sort = False).sum() # 统计时间段内用户数 c34 = df37.groupby("count",sort = False).sum() # 统计时间段内用户数 c35 = df38.groupby("count",sort = False).sum() # 统计时间段内用户数 c36 = df39.groupby("count",sort = False).sum() # 统计时间段内用户数 activityRate = pd.concat([c1,c2,c3,c4,c5,c6,c7,c8,c9,c10,c11,c12,c13,c14,c15,c16,c17,c18,c19,c20,c21, c22,c23,c24,c25,c26,c27,c28,c29,c30,c31,c32,c33,c34,c35,c36]) activityRate = activityRate.reset_index(drop=True) activityRate.rename(index=str,columns={"companyCode":"新用户数","合同开始时间_x":"注册用户"}, inplace = True) activityRate = activityRate.drop(lo1.columns[[2,3]], axis=1) # 去除干扰列 list1 = activityRate['注册用户'].tolist() # 取出表格某一列组成列表 # list2 = list(range(0,len(list1))) # list2[0] = list1[0] """ 计算注册用户""" for i in range(1,len(list1)): list1[i] = list1[i-1]+list1[i] activityRate["注册用户"] = list1 """ 计算老用户""" activityRate["老用户数"] = activityRate["注册用户"] - activityRate["新用户数"] activityRate["新用户活跃数"] = activityRate["新用户数"] activityRate
"""按时间段进行筛选去除,保留期间用户唯一活跃数""" df2 = data df2['date'] = pd.to_datetime(df2['date']) df3 = df2.set_index('date') df4 = df3['2018-7-2':'2018-7-10'] df5 = df3['2018-7-11':'2018-7-20'] df6 = df3['2018-7-21':'2018-7-31'] df7 = df3['2018-8-1':'2018-8-10'] df8 = df3['2018-8-11':'2018-8-20'] df9 = df3['2018-8-21':'2018-8-31'] df10 = df3['2018-9-1':'2018-9-10'] df11 = df3['2018-9-11':'2018-9-20'] df12 = df3['2018-9-21':'2018-9-30'] df13 = df3['2018-10-1':'2018-10-10'] df14 = df3['2018-10-11':'2018-10-20'] df15 = df3['2018-10-21':'2018-10-31'] df16 = df3['2018-11-1':'2018-11-10'] df17 = df3['2018-11-11':'2018-11-20'] df18 = df3['2018-11-21':'2018-11-30'] df19 = df3['2018-12-1':'2018-12-10'] df20 = df3['2018-12-11':'2018-12-20'] df21 = df3['2018-12-21':'2018-12-31'] df22 = df3['2019-1-1':'2019-1-10'] df23 = df3['2019-1-11':'2019-1-20'] df24 = df3['2019-1-21':'2019-1-31'] df25 = df3['2019-2-1':'2019-2-10'] df26 = df3['2019-2-11':'2019-2-20'] df27 = df3['2019-2-21':'2019-2-28'] df28 = df3['2019-3-1':'2019-3-10'] df29 = df3['2019-3-11':'2019-3-20'] df30 = df3['2019-3-21':'2019-3-31'] df31 = df3['2019-4-1':'2019-4-10'] df32 = df3['2019-4-11':'2019-4-20'] df33 = df3['2019-4-21':'2019-4-30'] df34 = df3['2019-5-1':'2019-5-10'] df35 = df3['2019-5-11':'2019-5-20'] df36 = df3['2019-5-21':'2019-5-31'] df37 = df3['2019-6-1':'2019-6-10'] df38 = df3['2019-6-11':'2019-6-20'] df39 = df3['2019-6-21':'2019-6-30'] df4.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df5.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df6.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df7.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df8.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df9.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df10.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df11.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df12.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df13.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df14.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df15.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df16.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df17.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df18.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df19.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df20.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df21.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df22.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df23.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df24.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df25.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df26.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df27.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df28.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df29.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df30.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df31.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df32.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df33.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df34.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df35.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df36.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df37.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df38.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df39.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 data2 = pd.concat([df4,df5,df6,df7,df8,df9,df10,df11,df12, df13,df14,df15,df16,df17,df18,df19,df20,df21,df22,df23,df24,df25, df26,df27,df28,df29,df30,df31,df32,df33,df34,df35,df36,df37,df38,df39]) data2
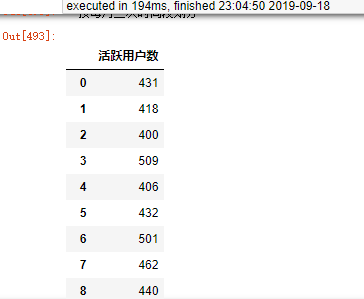
""" 按每月三次时间段划分""" df3 = data2.groupby(["date"],sort = False).count() # 单个日期用户数统计 df3 = df3.sort_values("date",ascending = True) # 排序 df3["count"] = 1 df4 = df3['2018-7-2':'2018-7-10'] df5 = df3['2018-7-11':'2018-7-20'] df6 = df3['2018-7-21':'2018-7-31'] df7 = df3['2018-8-1':'2018-8-10'] df8 = df3['2018-8-11':'2018-8-20'] df9 = df3['2018-8-21':'2018-8-31'] df10 = df3['2018-9-1':'2018-9-10'] df11 = df3['2018-9-11':'2018-9-20'] df12 = df3['2018-9-21':'2018-9-30'] df13 = df3['2018-10-1':'2018-10-10'] df14 = df3['2018-10-11':'2018-10-20'] df15 = df3['2018-10-21':'2018-10-31'] df16 = df3['2018-11-1':'2018-11-10'] df17 = df3['2018-11-11':'2018-11-20'] df18 = df3['2018-11-21':'2018-11-30'] df19 = df3['2018-12-1':'2018-12-10'] df20 = df3['2018-12-11':'2018-12-20'] df21 = df3['2018-12-21':'2018-12-31'] df22 = df3['2019-1-1':'2019-1-10'] df23 = df3['2019-1-11':'2019-1-20'] df24 = df3['2019-1-21':'2019-1-31'] df25 = df3['2019-2-1':'2019-2-10'] df26 = df3['2019-2-11':'2019-2-20'] df27 = df3['2019-2-21':'2019-2-28'] df28 = df3['2019-3-1':'2019-3-10'] df29 = df3['2019-3-11':'2019-3-20'] df30 = df3['2019-3-21':'2019-3-31'] df31 = df3['2019-4-1':'2019-4-10'] df32 = df3['2019-4-11':'2019-4-20'] df33 = df3['2019-4-21':'2019-4-30'] df34 = df3['2019-5-1':'2019-5-10'] df35 = df3['2019-5-11':'2019-5-20'] df36 = df3['2019-5-21':'2019-5-31'] df37 = df3['2019-6-1':'2019-6-10'] df38 = df3['2019-6-11':'2019-6-20'] df39 = df3['2019-6-21':'2019-6-30'] c1 = df4.groupby("count",sort = False).sum() # 统计时间段内用户数 c2 = df5.groupby("count",sort = False).sum() # 统计时间段内用户数 c3 = df6.groupby("count",sort = False).sum() # 统计时间段内用户数 c4 = df7.groupby("count",sort = False).sum() # 统计时间段内用户数 c5 = df8.groupby("count",sort = False).sum() # 统计时间段内用户数 c6 = df9.groupby("count",sort = False).sum() # 统计时间段内用户数 c7 = df10.groupby("count",sort = False).sum() # 统计时间段内用户数 c8 = df11.groupby("count",sort = False).sum() # 统计时间段内用户数 c9 = df12.groupby("count",sort = False).sum() # 统计时间段内用户数 c10 = df13.groupby("count",sort = False).sum() # 统计时间段内用户数 c11 = df14.groupby("count",sort = False).sum() # 统计时间段内用户数 c12 = df15.groupby("count",sort = False).sum() # 统计时间段内用户数 c13 = df16.groupby("count",sort = False).sum() # 统计时间段内用户数 c14 = df17.groupby("count",sort = False).sum() # 统计时间段内用户数 c15 = df18.groupby("count",sort = False).sum() # 统计时间段内用户数 c16 = df19.groupby("count",sort = False).sum() # 统计时间段内用户数 c17 = df20.groupby("count",sort = False).sum() # 统计时间段内用户数 c18 = df21.groupby("count",sort = False).sum() # 统计时间段内用户数 c19 = df22.groupby("count",sort = False).sum() # 统计时间段内用户数 c20 = df23.groupby("count",sort = False).sum() # 统计时间段内用户数 c21 = df24.groupby("count",sort = False).sum() # 统计时间段内用户数 c22 = df25.groupby("count",sort = False).sum() # 统计时间段内用户数 c23 = df26.groupby("count",sort = False).sum() # 统计时间段内用户数 c24 = df27.groupby("count",sort = False).sum() # 统计时间段内用户数 c25 = df28.groupby("count",sort = False).sum() # 统计时间段内用户数 c26 = df29.groupby("count",sort = False).sum() # 统计时间段内用户数 c27 = df30.groupby("count",sort = False).sum() # 统计时间段内用户数 c28 = df31.groupby("count",sort = False).sum() # 统计时间段内用户数 c29 = df32.groupby("count",sort = False).sum() # 统计时间段内用户数 c30 = df33.groupby("count",sort = False).sum() # 统计时间段内用户数 c31 = df34.groupby("count",sort = False).sum() # 统计时间段内用户数 c32 = df35.groupby("count",sort = False).sum() # 统计时间段内用户数 c33 = df36.groupby("count",sort = False).sum() # 统计时间段内用户数 c34 = df37.groupby("count",sort = False).sum() # 统计时间段内用户数 c35 = df38.groupby("count",sort = False).sum() # 统计时间段内用户数 c36 = df39.groupby("count",sort = False).sum() # 统计时间段内用户数 activityRate1 = pd.concat([c1,c2,c3,c4,c5,c6,c7,c8,c9,c10,c11,c12,c13,c14,c15,c16,c17,c18,c19,c20,c21, c22,c23,c24,c25,c26,c27,c28,c29,c30,c31,c32,c33,c34,c35,c36]) activityRate1 = activityRate1.reset_index(drop=True) activityRate1.rename(index=str,columns={"companyCode":"活跃用户数"}, inplace = True) activityRate1 = activityRate1.drop(activityRate1.columns[[1,2,3,4,5,6,7]], axis=1) # 去除干扰列 activityRate1
activityRate["总活跃用户数"] = activityRate1["活跃用户数"] activityRate["老用户活跃数"] = activityRate["总活跃用户数"] - activityRate["新用户活跃数"] order = ["注册总用户数","新用户数","老用户数","新用户活跃数","老用户活跃数","总活跃用户数"] # 排序 activityRate = activityRate[order] activityRate["新增活跃率"] = (activityRate["新用户活跃数"] / activityRate["新用户数"]) activityRate["新增活跃率"] = activityRate["新增活跃率"].apply(lambda x: format(x, '.2%')) activityRate["老用户活跃率"] = (activityRate["老用户活跃数"] / activityRate["老用户数"]) activityRate = activityRate.fillna(0) activityRate["老用户活跃率"] = activityRate["老用户活跃率"].apply(lambda x: format(x, '.2%')) activityRate["总活跃率"] = (activityRate["总活跃用户数"] / activityRate["注册总用户数"]) activityRate["总活跃率"] = activityRate["总活跃率"].apply(lambda x: format(x, '.2%')) # activityRate.T activityRate
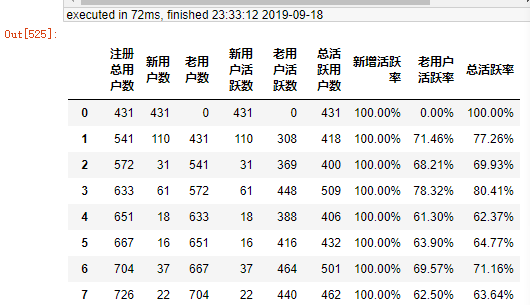
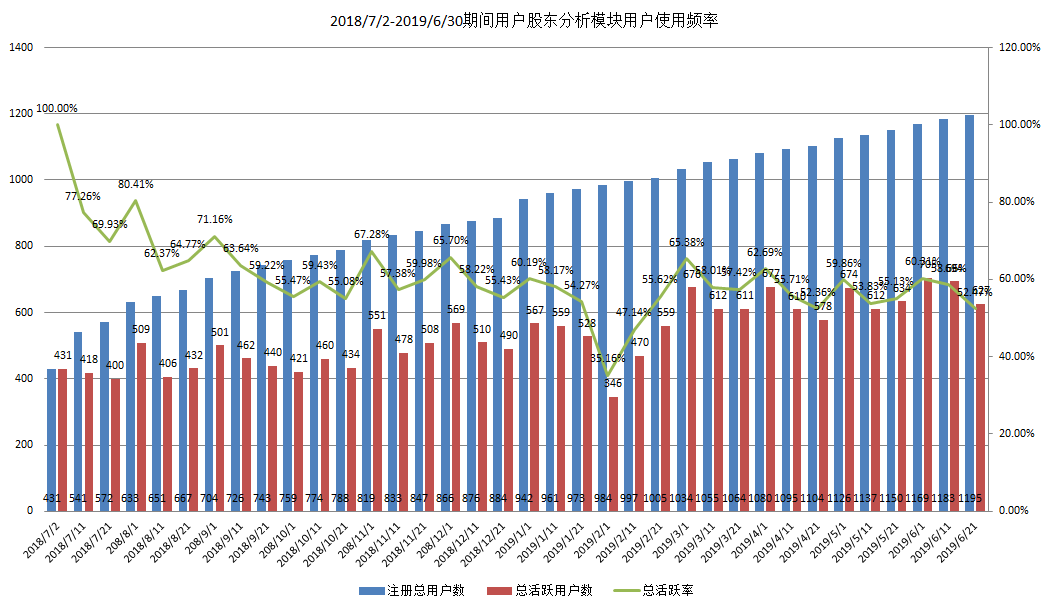
共1195家家公司使用过股东分析,整体用户使用频率先下降后期趋于平缓波动状态,平均每次约532家公司使用,平均每次公司使用率约为60.7%。
计算规则:
根据股东名册发放时间,0-10号、11-20号、21-月末期间多次行为视为同一次股东分析行为;
股东名册发放公司数从日志时间段内用户首次行为时间开始计算,每发放一次股东名册记为1,统计所有发放公司数;
公司使用频率 = 单次使用易董股东分析公司数/单次股东名册发放公司数。
5.3 公司使用导出数据内容模块分布
公司主要行为模式:观察股东持仓行为特征、监控公司最新股权结构情况、跟踪股东变化趋势、机构股东的关系管理、关注信用股东的变化情况、特别关注的股东分类及持股股东详情、维护股东数据、其他设置。公司重点关注公司最新股权结构情况以及股东变化趋势。
|
行为类别 |
用户行为 |
使用次数 |
公司数 |
公司占比 |
|
1. 观察股东持仓行为特征 |
股东行为特征分析-马上分析 |
366 |
236 |
19.7% |
|
2. 监控公司最新股权结构情况 |
最新股东概况 |
18335 |
1120 |
93.7% |
|
最新股东概况--导出报告 |
8037 |
792 |
66.3% |
|
|
股东性质分类统计--导出所选项 |
285 |
146 |
12.2% |
|
|
股东地域分类统计--导出所选项 |
170 |
69 |
5.8% |
|
|
3. 支持跟踪股东变化趋势 |
股东对比分析 |
13280 |
1100 |
92.1% |
|
股东对比分析--导出Excel |
1518 |
519 |
43.4% |
|
|
股东对比分析--一键对比 |
8930 |
874 |
73.1% |
|
|
股东对比分析--两期对比 |
7499 |
676 |
56.6% |
|
|
股东对比分析--两期对比--导出分析报告 |
5587 |
633 |
53.0% |
|
|
股东对比分析--两期对比--导出Excel |
4501 |
412 |
34.5% |
|
|
股东对比分析--多期对比 |
734 |
253 |
21.2% |
|
|
股东对比分析--多期对比--导出Excel |
727 |
247 |
20.7% |
|
|
股东对比分析--一键环比 |
1495 |
443 |
37.1% |
|
|
股东对比分析--多期环比 |
886 |
177 |
14.8% |
|
|
股东对比分析--多期环比--导出Excel |
883 |
175 |
14.6% |
|
|
户均持股分析 |
26 |
26 |
2.2% |
|
|
户均持股分析--导出Excel |
3 |
3 |
0.3% |
|
|
4. 做好机构股东的关系管理 |
机构股东分析 |
6929 |
1017 |
85.1% |
|
机构股东分析--导出全体机构 |
949 |
158 |
13.2% |
|
|
机构股东分析--导出所选机构 |
618 |
201 |
16.8% |
|
|
机构股东分析--导出Excel |
845 |
197 |
16.5% |
|
|
5. 关注信用股东的变化情况 |
信用分析 |
1130 |
275 |
23.0% |
|
信用分析--导出Excel |
156 |
36 |
3.0% |
|
|
6. 建立自己关注的股东分类查看持股股东详情 |
股东信息查询 |
5844 |
1003 |
83.9% |
|
股东信息查询--导出Excel |
672 |
264 |
22.1% |
|
|
新建分组 |
876 |
397 |
33.2% |
|
|
编辑分组 |
507 |
192 |
16.1% |
|
|
添加到分组 |
289 |
181 |
15.1% |
|
|
关注股东 |
355 |
247 |
20.7% |
|
|
发送问候短信 |
88 |
79 |
6.6% |
|
|
7. 维护股东数据 |
名册文件管理 |
435 |
305 |
25.5% |
|
个人中心 |
1870 |
665 |
55.6% |
|
|
个人中心--新建股东分组 |
438 |
192 |
16.1% |
|
|
个人中心--取消关注 |
51 |
46 |
3.8% |
|
|
个人中心--发送短信 |
30 |
28 |
2.3% |
|
|
个人中心--新增模版 |
16 |
15 |
1.3% |
|
|
数据备份管理 |
271 |
151 |
12.6% |
|
|
8. 其他设置 |
标签定义 |
220 |
174 |
14.6% |
|
系统设置 |
197 |
144 |
12.1% |
|
|
系统帮助 |
91 |
70 |
5.9% |
|
|
在线咨询 |
89 |
66 |
5.5% |
计算规则:
根据股东名册发放时间,每月0-10号、11-20号、21-月末期间多次行为视为同一次股东分析行为。
5.4 单个公司使用频率分布
""" 累计使用天数 需求列表需三列以上,其中df1['date'] = df1['date1'],df1['companyCode'] = df1["companyCode"],df1['count'] = "1" """ def NumberofDaysUsed(h1): h1 = h1.groupby(['date','companyCode'],sort = False).count() # 去除一天中的重复值 h1 = h1.sort_values('count',ascending = False) h1["使用天数"] = h1.index.get_level_values(1).values #提取索引列(第二列)值添加为新的一列 h1 = h1['使用天数'].value_counts() # 统计该列所有元素重复次数 h1 = pd.DataFrame(h1) h1 = h1['使用天数'].value_counts() # 统计该列所有元素重复次数 h1.sort_index(inplace=True) # 按索引进行排序 h1 = pd.DataFrame(h1) a1 = h1 a1['AC'] = '1' a1 = a1.groupby('AC',sort = False).sum() print('使用公司数量:',a1) h1 = h1['使用天数'] h1 = pd.DataFrame(h1) return h1
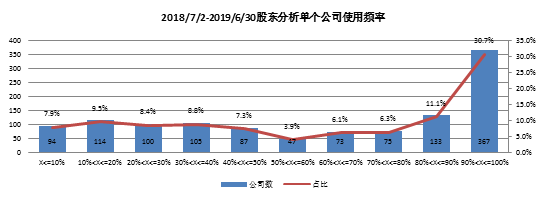
1195家公司使用频率呈翘尾趋势,公司平均使用频率60.8%,使用频率30%以下公司308家,占比25.8%,使用频率80%以上公司575家,占比48.1%。
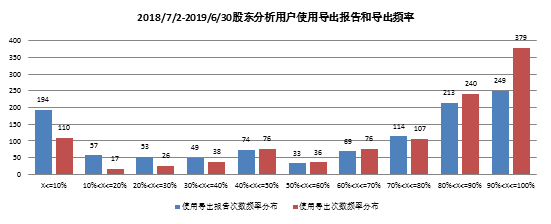
计算规则:
公司使用导出报告频率 = 单个公司使用易董股东分析导出报告次数/单个公司使用易董股东分析次数。
公司使用导出频率 = 单个公司使用易董股东分析进行导出次数/单个公司使用易董股东分析次数。
整体公司使用时,进行导出行为和导出报告行为频率呈先下降后上升趋势,导出频率80%以上用户619家,占比51.8%;0导出公司共137家,100%导出公司194家,其中100%导出报告公司133家。
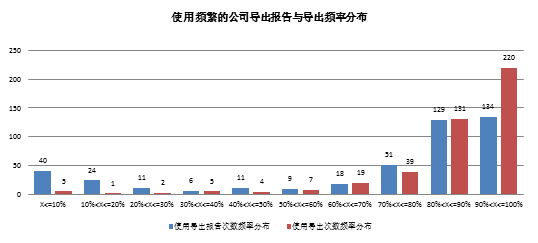
计算规则:
使用频繁的用户筛选:用户使用次数>=12,使用频率>=80%共433家。
用户使用次数和频率越高,导出行为频率越高。
5.5 公司留存率
给每一个时间段打上对应标签num列(2018-7-2:1,2019-6-21:36),然后每个公司多次有效行为进行排序sort_id列(例如000001四次有效行为即为1234),num列下单元格减去上单元格,若连续则数据为1
一次用户留存拟进行股东分析用户数=COUNTIF(D:D,2) D:D为sort_id列,一次用户留存使用模块用户数 =COUNTIFS(D:D,2,E:E,1)
一次留存率 =[ =COUNTIF(D:D,2)] / [COUNTIFS(D:D,2,E:E,1)]
二次留存率 = [ =COUNTIF(D:D,3)] / [COUNTIFS(D:D,3,E:E,1)]
df2 = df1 df2 = df2.sort_values(['companyCode','date'],ascending = True) df2['date'] = pd.to_datetime(df2['date']) df3 = df2.set_index('date') df4 = df3['2018-7-2':'2018-7-10'] df5 = df3['2018-7-11':'2018-7-20'] df6 = df3['2018-7-21':'2018-7-31'] df7 = df3['2018-8-1':'2018-8-10'] df8 = df3['2018-8-11':'2018-8-20'] df9 = df3['2018-8-21':'2018-8-31'] df10 = df3['2018-9-1':'2018-9-10'] df11 = df3['2018-9-11':'2018-9-20'] df12 = df3['2018-9-21':'2018-9-30'] df13 = df3['2018-10-1':'2018-10-10'] df14 = df3['2018-10-11':'2018-10-20'] df15 = df3['2018-10-21':'2018-10-31'] df16 = df3['2018-11-1':'2018-11-10'] df17 = df3['2018-11-11':'2018-11-20'] df18 = df3['2018-11-21':'2018-11-30'] df19 = df3['2018-12-1':'2018-12-10'] df20 = df3['2018-12-11':'2018-12-20'] df21 = df3['2018-12-21':'2018-12-31'] df22 = df3['2019-1-1':'2019-1-10'] df23 = df3['2019-1-11':'2019-1-20'] df24 = df3['2019-1-21':'2019-1-31'] df25 = df3['2019-2-1':'2019-2-10'] df26 = df3['2019-2-11':'2019-2-20'] df27 = df3['2019-2-21':'2019-2-28'] df28 = df3['2019-3-1':'2019-3-10'] df29 = df3['2019-3-11':'2019-3-20'] df30 = df3['2019-3-21':'2019-3-31'] df31 = df3['2019-4-1':'2019-4-10'] df32 = df3['2019-4-11':'2019-4-20'] df33 = df3['2019-4-21':'2019-4-30'] df34 = df3['2019-5-1':'2019-5-10'] df35 = df3['2019-5-11':'2019-5-20'] df36 = df3['2019-5-21':'2019-5-31'] df37 = df3['2019-6-1':'2019-6-10'] df38 = df3['2019-6-11':'2019-6-20'] df39 = df3['2019-6-21':'2019-6-30'] df4.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df5.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df6.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df7.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df8.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df9.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df10.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df11.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df12.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df13.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df14.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df15.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df16.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df17.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df18.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df19.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df20.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df21.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df22.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df23.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df24.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df25.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df26.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df27.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df28.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df29.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df30.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df31.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df32.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df33.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df34.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df35.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df36.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df37.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df38.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df39.drop_duplicates(subset=['companyCode'],keep='first',inplace=True) # 去除该列重复值 df4['num'] = '1' df5['num'] = '2' df6['num'] = '3' df7['num'] = '4' df8['num'] = '5' df9['num'] = '6' df10['num'] = '7' df11['num'] = '8' df12['num'] = '9' df13['num'] = '10' df14['num'] = '11' df15['num'] = '12' df16['num'] = '13' df17['num'] = '14' df18['num'] = '15' df19['num'] = '16' df20['num'] = '17' df21['num'] = '18' df22['num'] = '19' df23['num'] = '20' df24['num'] = '21' df25['num'] = '22' df26['num'] = '23' df27['num'] = '24' df28['num'] = '25' df29['num'] = '26' df30['num'] = '27' df31['num'] = '28' df32['num'] = '29' df33['num'] = '30' df34['num'] = '31' df35['num'] = '32' df36['num'] = '33' df37['num'] = '34' df38['num'] = '35' df39['num'] = '36' data1 = pd.concat([df4,df5,df6,df7,df8,df9,df10,df11,df12, df13,df14,df15,df16,df17,df18,df19,df20,df21,df22,df23,df24,df25, df26,df27,df28,df29,df30,df31,df32,df33,df34,df35,df36,df37,df38,df39]) # data2 = data1.groupby(['companyCode','date'],sort = False).count() # data2 = data2.sort_values('companyCode',ascending = True) data1 = data1.sort_values('date',ascending = True) data1 = data1[['companyCode','num']] data1['num'] = data1['num'].astype(np.int) data1['sort_id'] = data1['num'].groupby(data1['companyCode']).rank() # 根据companyCode 单独排序 data1.to_csv('C:/Users/qiang.chen/Desktop/111111.csv',encoding = 'utf-8-sig')
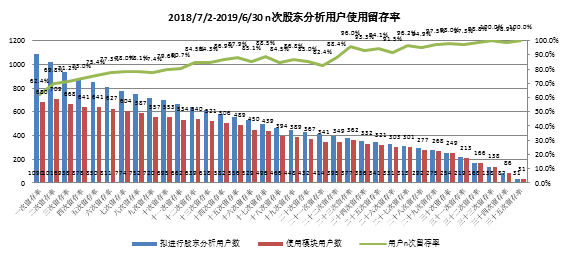
计算规则:
一次留存率等于使用易董进行第一次股东分析后有连续进行第二次股东分析的公司数(不一定使用易董)作为除数,使用易董进行第二次会议公司数作为被除数。
基于公司是否使用和使用连续性,公司留存率呈上升趋势,累计使用36次公司31家。
5.6 公司流失率
前九个月使用一次,后三个月不使用公司视为流失公司,共流失61家,流失率约为5.7%;
前七个月使用一次,后五个月不使用公司视为流失公司,共流失54家,流失率约为5.6%。
计算规则:
公司流失率=前九个月使用一次,后三个月不用的公司61家/前九个所有使用公司数1065家;
公司流失率=前七个月使用一次,后五个月不用的公司54家/前七个所有使用公司数971家。
六,结论
- 2018/7/2-2019/6/30期间使用股东分析签约用户共1195家,每十天使用一次,使用公司数量随时间推移逐渐上升,平均每次使用公司数532家(19138/36),单次使用频率随时间变化先下降后期趋于平缓波动,平均每次使用率约为60.7%,用户使用时导出报告公司占比67.6%,进行导出(含导出报告)公司占比81.1%;
- 公司行为模式有8种:观察股东持仓行为特征、监控公司最新股权结构情况、跟踪股东变化趋势、机构股东的关系管理、关注信用股东的变化情况、特别关注的股东分类及持股股东详情、维护股东数据、其他设置。用户重点关注公司最新股权结构情况以及股东变化趋势;
- 1195家公司使用频率变化呈翘尾趋势,每家公司平均使用频率60.8%,使用频率30%以下公司308家,占比25.8%,使用频率80%以上公司575家,占比48.1%;
- 1195家公司使用时,进行导出行为和导出报告行为频率呈先下降后上升趋势;使用同时进行导出报告平均频率为54.5%,导出平均频率为65.6%,0导出公司共137家,100%导出公司194家,其中100%导出报告公司133家,用户使用次数和频率越高,导出行为频率越高;
- 以公司使用连续性计算公司n次留存率,使用次数越多,公司留存率越高,平均留存率为86.4%,随使用次数增加,公司留存率呈上升趋势;
- 若前九个月使用一次,后三个月不使用公司视为流失公司,共流失61家,流失率约为5.7%(61/前九个月使用用户1065家),若前七个月使用一次,后五个月不使用公司视为流失公司,共流失54家,流失率约为5.6%(54/前七个月使用用户971家)。
