
一、目标
分析“股东分析”模块用户行为
二、分析流程
- 在Kibana上导出2018/7/2-2019/6/30期间股东分析模块用户行为日志;
- 数据集清洗整理,并明确股东分析用户行为准则;
- 确定用户主体,分析用户使用分布;
- 分析用户使用留存率、流失率;
- 分析未签约用户使用情况。
三、用户行为分析过程
3.1 明确细则
中国结算发布《证券持有人名册业务实施细则》并自2018年7月2日开始实施。中国结算每个月向上市公司提供3次前200名大股东名册(包含股东人数),分别为每个月的10日、20日和月底最后一个交易日。此前为每月2次,且只提供前100大股东名册。
3.2 主要用户
股东分析主要用户为上市公司,该段日志期间该时间段范围内,证券结算机构拟提供36次股东名册,共1744家上市公司用户点击过股东分析模块,其中未签约用户436家。
3.3 用户行为次数筛选规则制定
一次点击视为一次登录;
0-10号、11-20号、21-月末期间多次行为视为一次有效行为;
四、用户行为分析
4.1、数据获取(获取2018/7/2-2019/6/30 时间段该模块用户点击量)
- 搜索数据:kibana → open → analyze-login 2019
- 下载数据:save → reporting → download
4.2、数据预处理
4.2.1 数据合并导入
import os import pandas as pd path = 'D:/0. data_analysis/11-19-6-3/2' #设置csv所在文件夹 files = os.listdir(path) #获取文件夹下所有文件名 df1 = pd.read_csv(path + '/' + files[0],encoding='utf-8',error_bad_lines=False)#读取首个csv文件,保存到df1中 for file in files[1:]: df2 = pd.read_csv(path +'/' + file,encoding='utf-8',error_bad_lines=False,converters = {u'companyCode':str} ) #打开csv文件,注意编码问题,保存到df2中 df1 = pd.concat([df1,df2],axis=0,ignore_index=True) #将df2数据与df1合并 df1 = df1.drop_duplicates() #去重 df1 = df1.reset_index(drop=True) #重新生成index df1.to_csv(path + '/' + 'total.csv') #将结果保存为新的csv文件
4.2.3、companyCode 处理
3.1 companyCode 处理:2885.0 → 002885
# 方法一:后期数据处理发现有5000多companyCode = 000000情况出现,故此方法不可取 import numpy as np df1['companyCode'] = df1['companyCode'].astype(np.str) # 转换数据列类型,去掉末尾.0 df1['companyCode'] = df1['companyCode'].str[0:8] df1['companyCode'] = df1['companyCode'].str.replace(".0", "") # 通过str.replace替除“.0” df1['companyCode']=df1['companyCode'].astype(str).str.zfill(6) # 补齐代码前面的0 # 方法二: import numpy as np df1.replace(np.nan, 0, inplace=True) df1.replace(np.inf, 0, inplace=True) df1['companyCode'] = df1['companyCode'].astype(np.int64) # 转换数据列类型,去掉末尾.0 df1['companyCode']=df1['companyCode'].astype(str).str.zfill(6) # 补齐代码前面的0
4.2..3 时间戳处理,将UTC时间改为东八区时间,并将date和time分隔
import datetime df1['date'] = pd.to_datetime(df1['@timestamp']) # 将@timestamp数据转化为datetime64类型保存到date中 df1['date'] = (df1['date'] + datetime.timedelta(hours=8)) # utc时间改为东八区时间+8h # 将时间和日期分隔 df1['time']= df1['date'] # 复制date 列数据到 time df1['date'] = df1.date.dt.date # 提取年月日 df1['time'] = df1.time.dt.time # 提取时间 # 将time列排序到第二列位置 df_time = df1.time df1 = df1.drop('time',axis = 1) df1.insert(1,'time',df_time) # 将date列数据排到第二列位置 df_date = df1.date df1 = df1.drop('date',axis = 1) df1.insert(1,'date',df_date) df1.loc[:'time' ] = df1.loc[:'time'].astype('str') # 将所有格式转化为object df1['time'] = df1['time'].str[0:8] #截取用户行为时间区域,去掉末尾秒后面微秒区域
4.2.4 去除重复项以及干扰项
# 去除重复项 df1.duplicated() # 查找重复行,重复返回True df2 = df1.drop_duplicates() # 去除重复行,保留唯一真值 # df2 = df1.drop_duplicates('companyCode') # 根据某个字段去重,此处无需使用 # 去除干扰项,99开头内部测试代码以及600036 df3 = df2[df2.companyCode.str.startswith('99')] # 提取comgpnayCode以99开头的数据,提取结果为5,公司代码999000 df3 = df2[~df2['companyCode'].isin(['600036'])] df3 = df2[~df2['companyCode'].isin(['999000'])] df3 = df2[~df2['companyCode'].isin(['000000'])] df3 = df3.reset_index(drop=True) # 去除行后重新赋予索引值,按0、1、2、3...排序 df3['@version']= df3['@version'].str.strip() # 去除字符串元素中左右空格 df3['authority']= df3['authority'].str.strip() # 去除字符串元素中左右空格 df3['clickButtonName']= df3['clickButtonName'].str.strip() # 去除字符串元素中左右空格 df3['userName']= df3['userName'].str.strip() # 去除字符串元素中左右空格 df3['companyShortName']= df3['companyShortName'].str.strip() # 去除字符串元素中左右空格 df3.shape
列名重命名,索引重新排序
df3.rename(columns = {'@timestamp':'timestamp','companyShortName':'companyName','clickButtonName':'login'},inplace = True)
df3 = df3.reset_index(drop = True)
4.2.5 观察数据,提取用户登录行为数据(关键数据,基于此进行分析)
# 观察数据特征排序 df4 = df3.groupby('login',sort = True).count() df4.sort_values('timestamp',ascending = False) df4 = df3.loc[df3['login'] == '0'] df4.shape
4.3 用户群体分类(主要用户为上市公司。占比99.9%)
%config ZMQInteractiveShell.ast_node_interactivity="all" df3 = df2 # 中介机构金融机构 df4 = df3[df3.companyCode.str.startswith('1')] # 提取以companyCode以18开头的行 # 新三板督导系统 df5 = df3[df3.companyCode.str.startswith('28')] # 提取以companyCode以28开头的行 # 监管部门及合作单位 df6 = df3[df3.companyCode.str.startswith('58')] # 提取以companyCode以58开头的行 # 拟上市 df7 = df3[df3.companyCode.str.startswith('78')] # 提取以companyCode以78开头的行 # 公司自用 df8 = df3[df3.companyCode.str.startswith('99')] # 提取以companyCode以99开头的行 # 上市公司 d1 = df3[df3.companyCode.str.startswith('00')] # 中小板和深主板 d2 = df3[df3.companyCode.str.startswith('30')] # 创业板 d3 = df3[df3.companyCode.str.startswith('43')] # 新三板 d4 = df3[df3.companyCode.str.startswith('60')] # 沪主板 d5 = df3[df3.companyCode.str.startswith('83')] # 新三板 d6 = df3[df3.companyCode.str.startswith('20')] # 深B d7 = df3[df3.companyCode.str.startswith('90')] # 沪B df9 = pd.concat([d1,d2,d3,d4,d5,d6,d7]) # 其它 df10 = df3[df3.companyCode.str.startswith('88')] # 提取以companyCode以88开头的行 df4.shape df5.shape df6.shape df7.shape df8.shape df9.shape df10.shape
4.4 分析用户留存率
4.4.1 提取上市公司总数据集,确定用户及行为时间并从小到大,从早到晚排序
data1 = df9 # 导入上市公司数据 data1 = data1.groupby(['companyCode','date'],sort = False).count() # 数据按companyCode,date计数 data1['companyCode1'] = data1.index.get_level_values(0).values # 重新给数据列赋值companyCode data1['date1'] = data1.index.get_level_values(1).values # 重新给数据列赋值date data1 = data1.sort_values(['companyCode1','date1'],ascending = True) # 数据按companyCode和date由小到大排序 data3 = data1[['companyCode1','date1','timestamp']] # 选择特征列 data3['timestamp'] = 1 # 重新定义新列 # 为方便下面操作,将companyCode 由 000001 → 1 data3.to_csv('D:/0. data_analysis/2. data_analysis/Log module analysis/financial analysis/2018.11.19-2019.6.9易董日志分析/1. 治理/4. 桌面应用工具/股东分析/2.csv',encoding = 'utf-8-sig') data3 = pd.read_csv('D:/0. data_analysis/2. data_analysis/Log module analysis/financial analysis/2018.11.19-2019.6.9易董日志分析/1. 治理/4. 桌面应用工具/股东分析/2.csv', converters={'companyCode1': str}) # 读取项目名称列,不要列名
4.4.2 数据处理,提取仅使用一天用户companyCode列表,并在总数据集中删除仅使用一天用户
data2 = data1.groupby('companyCode1',sort =False).count() data2 = data2.sort_values('timestamp',ascending = False) data2['time'] = data2['time'].astype(np.str) df1 = data2.loc[data2['time'] == '1'] df1['companyCode1'] = df1.index.get_level_values(0).values df1.shape
df1['companyCode'] = df1['companyCode1'] # df1['date'] = df1['date1'] df1 = df1.groupby(['companyCode'],sort = True).count() del df1['companyCode1'] # 删除companyCode1列 df1['companyCode1'] = df1.index.get_level_values(0).values df1 = df1.sort_values(['companyCode1','date1'],ascending = True) df1 = df1[['companyCode1','date1','timestamp']] df1.to_csv('D:/0. data_analysis/2. data_analysis/Log module analysis/financial analysis/2018.11.19-2019.6.9易董日志分析/1. 治理/4. 桌面应用工具/股东分析/1.csv',encoding = 'utf-8-sig')
# 获取累计使用一天的用户名单列表
import pandas as pd def excel_one_line_to_list(): df1 = pd.read_csv('D:/0. data_analysis/2. data_analysis/Log module analysis/financial analysis/2018.11.19-2019.6.9易董日志分析/1. 治理/4. 桌面应用工具/股东分析/1.csv',usecols=[1], names=None,converters={'companyCode1': str}) # 读取项目名称列,不要列名 df_li = df1.values.tolist() result = [] for s_li in df_li: result.append(s_li[0]) print(result) if __name__ == '__main__': excel_one_line_to_list()
# a 列中待删除的元素 a_to_drop = [300255, 407, 603379, 300279, 300103, 603817, 2707, 603818, 669, 300096, 662, 4, 603367, 300264, 603773, 300119, 300265, 2863, 603387, 300269, 2687, 18, 2915, 2955, 300161, 2751, 300043, 2752, 200468, 2757, 603707, 2827, 300041, 547, 300195, 300071, 526, 29, 603655, 100, 2813, 31, 300177, 2800, 300023, 2828, 300220, 603589, 603867, 603516, 2708, 603960, 300056, 300132, 2906, 2725, 300180, 200168, 603725, 2739, 603933, 603920, 300135, 25, 300052, 300230, 603863, 300222, 603896, 2102, 678, 2236, 300698, 2005, 600721, 300706, 300708, 2219, 600702, 300715, 600681, 600668, 300720, 2017, 2205, 600618, 300727, 600734, 998, 600599, 600754, 300637, 2301, 600860, 300656, 600809, 989, 600797, 300670, 600783, 300671, 300674, 2266, 600769, 600763, 2238, 600603, 300738, 948, 600423, 600096, 2146, 600396, 2143, 600125, 600152, 600162, 600197, 2132, 2127, 600348, 600219, 600333, 2082, 600295, 600090, 2068, 300742, 600057, 300743, 600559, 600557, 600546, 2033, 300757, 2045, 300762, 300772, 2055, 600497, 2062, 600031, 2151, 600039, 600884, 600901, 603336, 759, 603161, 2540, 603136, 603127, 603118, 603116, 603106, 300414, 2524, 2520, 603086, 300428, 300431, 813, 2509, 2556, 737, 2504, 733, 2641, 603329, 300338, 603316, 300341, 603288, 300353, 717, 603259, 2599, 2583, 603218, 721, 2579, 2577, 603050, 833, 600928, 601500, 2397, 917, 918, 601139, 300565, 2369, 601069, 300591, 2355, 601003, 300597, 600982, 600936, 2337, 600929, 2399, 300536, 835, 601595, 300471, 2460, 2457, 603011, 2442, 856, 875, 2434, 883, 885, 601869, 898, 601800, 601618, 300531, 600169] # 找到待删除元素所在的位置,返回的是 true or false 序列 flag = data3['companyCode'].isin(a_to_drop) # 由于我们要取差集,因此对上述序列取反 diff_flag = [not f for f in flag] # res 为我们所需要的差集 res = data3[diff_flag] # 重置index res.index = [i for i in range(len(res))]
4.4.3 分析用户使用连续性,数据整理
- 根据用户行为时间,确定相邻时间之差;
- 重新定义单个用户末尾时间差,确保接下来筛选中保留数据(防止不同用户之间相邻时间差干扰)
- 将两个数据集合并,并保留重新定义后的数据,删除之前未定义数据
# 提取date列,后续进行加减 df9 = res['date'] df9 = pd.DataFrame(df9) df9.drop(index=0,inplace=True) df9.reset_index(drop=True,inplace=True) res['end_time'] = df9['date'] res['aa'] =pd.to_datetime(res['end_time'])-pd.to_datetime(res['date']) # 统计两次行为间隔时间
res.fillna('365 days')
# 提取单个用户最末尾数据并重新赋值 mydf = res.drop_duplicates(subset='companyCode1',keep="last") # 观察单个用户与下一用户交接的时间差,<=0有1442,>=0有84,=0,有5 mydf.shape # mydf = mydf.loc[mydf['aa'] == '0 days'] # mydf.head(10) mydf['aa1'] =mydf['aa'] mydf.loc[mydf['aa'] <= '0 days','aa1'] = '365 days' mydf.loc[mydf['aa'] >= '0 days','aa1'] = '365 days' mydf= mydf.fillna('365 days') # 填补空缺值 del mydf['aa'] # 删除aa列 mydf.rename(columns = {'aa1':'aa'},inplace = True) # mydf = mydf.reset_index(drop = True)
# 将两个数据集合并,并保留修改后最大值 方法一:出现错误未知 sss = res.append(mydf) sss['aa'] = sss['aa'].astype(np.str) sss = sss.sort_values(['companyCode'], ascending=False).drop_duplicates(['companyCode1','date']).sort_index() # 根据companyCode,date列去重,保留最大值 sss['aa'] = sss['aa'].str.replace("00:00:00", "") # 通过str.replace替除“00:00:00” 方法二: sss = res.append(mydf) sss = sss[['companyCode','date','aa']] sss = sss.sort_values(['companyCode','date'],ascending = True) sss = sss.fillna('365 days') # 填补空缺值 sss['aa'] = sss['aa'].astype(np.str) sss['aa'] = sss['aa'].str.replace("00:00:00", "") # 通过str.replace替除“00:00:00” sss = sss.drop_duplicates(subset=['companyCode','date'], keep='last', inplace=False) 检查 mydf = sss.drop_duplicates(subset='companyCode',keep="last") #aa全部为365 days mydf.to_csv('D:/0. data_analysis/2. data_analysis/Log module analysis/financial analysis/2018.11.19-2019.6.9易董日志分析/1. 治理/4. 桌面应用工具/股东分析/999.csv',encoding = 'utf-8-sig')
4.4.4 不同时间间隔用户留存率分析 (待验证)
方法一:读入清洗后的数据,根据loc函数筛选时间差,['aa'] >= '4’时结果有误,原因未知,此方法失败 mydf = pd.read_excel('C:/Users/qiang.chen/Desktop/data2.xlsx') mydf = df1.loc[df1['aa'] >= '1'] data2 = mydf.groupby('companyCode',sort =False).count() # data2 = data2.sort_values('timestamp',ascending = True) data2['date'] = data2['date'].astype(np.str) a = list(range(140)) b = [str(i) for i in a] for i in range(0,140): d9 = data2.loc[data2['date'] == b[i]] d9.shape 方法二:通过excel表格筛选时间差,删除保存,读入统计 mydf = pd.read_excel('C:/Users/qiang.chen/Desktop/data2.xlsx') data2 = mydf.groupby('companyCode',sort =False).count() data2['date'] = data2['date'].astype(np.str) a = list(range(140)) b = [str(i) for i in a] for i in range(0,140): d9 = data2.loc[data2['date'] == b[i]] d9.shape
四、用户行为分析(上述时间分割因时间差区域跨度,有一定误差故未采用)
4.1 根据时间区域去重,分析每段时间区域用户使用次数
共1744家用户使用过股东分析,每月三次,平均每次约671家用户使用。
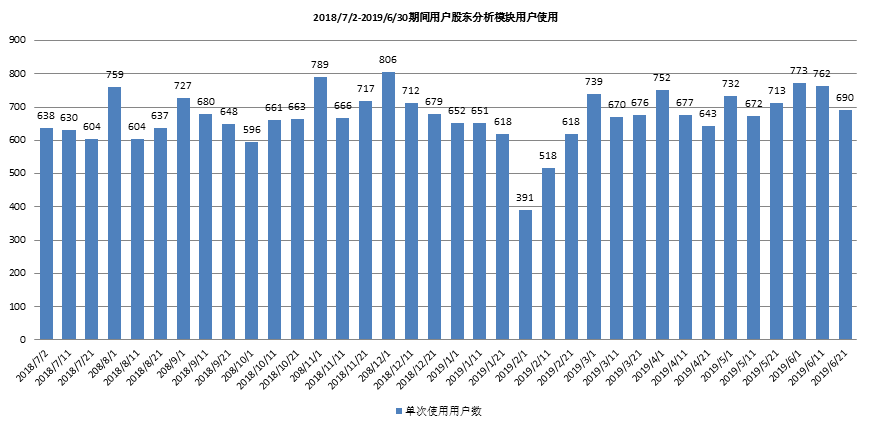
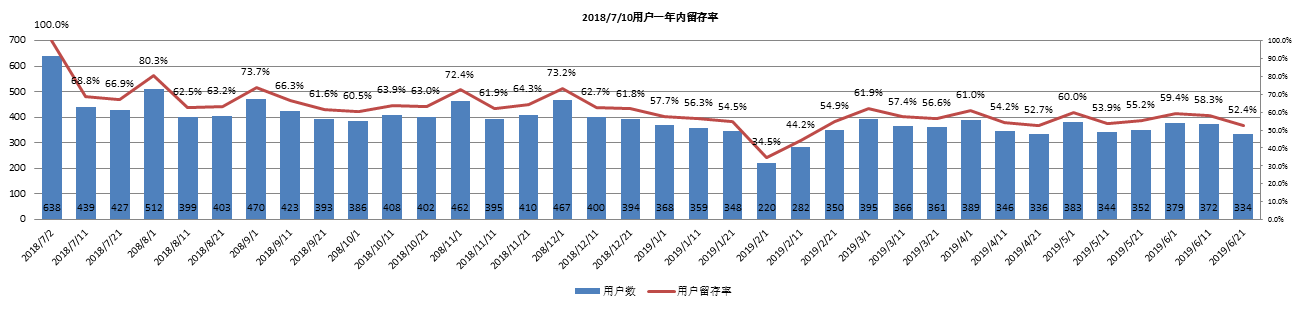
4.2 用户留存率
a. 以18年7月10号内638家用户为基准,分析此批用户2018/7/2-2019/6/30期间留存率;
该时间段范围内,证券结算机构拟提供36次股东名册;
用户平均留存率约为61%,随时间推移,用户留存率呈缓慢下降趋势。
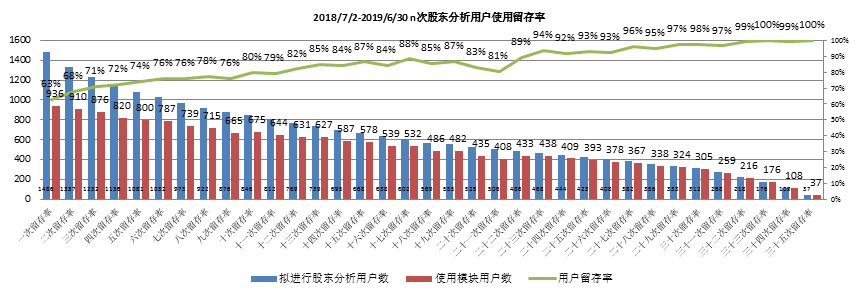
b.
基于用户是否使用和使用连续性,用户留存率呈上升趋势,持续使用用户37家。
根据时间段去重后,给每一次用户行为编号(不同时间段编不同序号),然后单个用户编号相减(若行为连续结果为1),给单个用户进行赋值索引;
统计用户行为次数,统计用户索引数1,2....n;例如1为1486
统计用户索引对应差值为1的数目,例如索引1对映编号差值为1的共936次,一次用户留存率 = 936/1486 = 63.0%,其它n次用户留存率依此计算。
p2['sort_id'] = p2['number'].groupby(p2['companyCode']).rank() # 给单个用户赋值索引
4.3 用户流失率
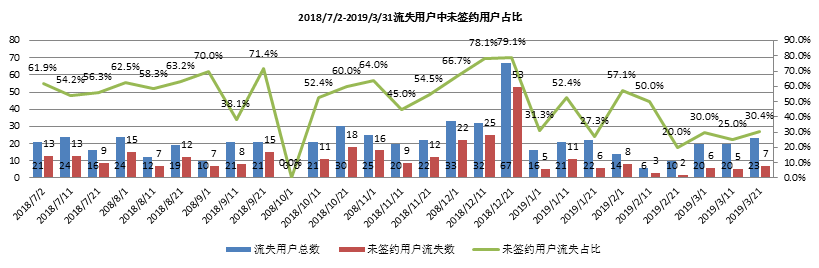
通过用户最后行为时间对用户进行划分;2019/4、2019/5、2019/6三个月未使用股东分析判定用户流失;
2018/12/21流失用户共67家,其中未签约用户53家;
流失用户共570家,其中未签约用户318家,用户平均每次使用后流失率约为3.2%;用户流失率受未签约用户影响较大;
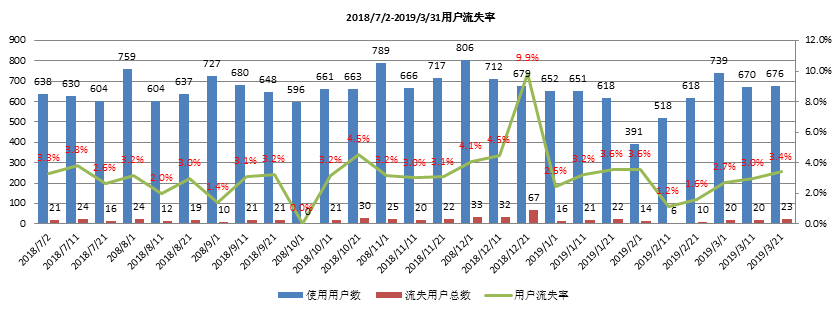
用户流失率受未签约用户影响,平均每次流失中未签约用户占比53.6%;
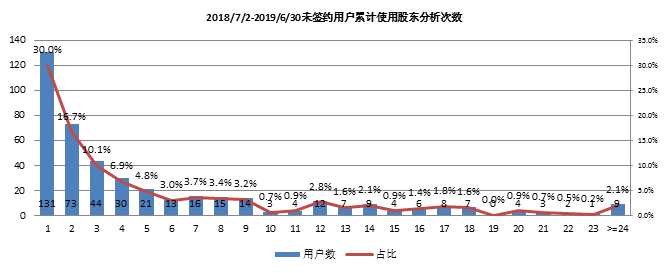
4.4 未签约用户使用次数分布
未签约用户累计使用次数大于等于24的9家用户如下表所示。
五、总结与建议
5.1 总结
- 2018/7/2-2019/6/30共提供股东名册36次,平均每次提供后有671家公司进行股东分析,共有用户1744家,其中累计使用30次以上用户333家;
- 以2018/7/10以内638家用户为基准,一年内用户平均留存率为61%,整体趋势呈缓慢下降趋势;
- 以用户使用连续性计算用户留存率,使用次数越多,用户留存率越高,平均留存率为83.4%,随使用次数增加,用户留存率呈上升趋势;
- 以2019年4、5、6月未登录判定用户流失,共流失570名用户,其中未签约用户318名,平均用户流失率约为3.2%;
- 未签约用户共436家,累计使用24天以上者9家。
5.2 建议
- 针对(未签约+近三个月仍在使用+累计使用次数达10次以上+近期未组织拜访)5家用户组织拜访,明确用户需求,优化服务,提高用户体验,达成签约。
|
序号 |
公司名 |
公司代码 |
所属区域 |
所在省市 |
是否签约 |
最近使用时间 |
最近拜访时间 |
使用次数 |
|
1 |
辰安科技 |
300523 |
田斯凯 |
北京 - 北京市 |
未签约 |
2019/6/11 |
2018/12/12 |
32 |
|
2 |
奥拓电子 |
002587 |
崔华宇 |
深圳 - 深圳市 |
未签约 |
2019/6/21 |
2018/9/12 |
28 |
|
3 |
承德露露 |
000848 |
崔巍 |
河北-承德市 |
未签约 |
2019/4/1 |
#N/A |
20 |
|
4 |
深圳华强 |
000062 |
崔华宇 |
深圳 - 深圳市 |
未签约 |
2019/6/25 |
2018/9/7 |
13 |
|
5 |
拓尔思 |
300229 |
田斯凯 |
北京 - 北京市 |
未签约 |
2019/6/11 |
2017/12/25 |
10 |
