
一、背景
互联网时代,数据分析与检索可对公司运营起决策性作用,而大部分数据需要从网上获取,且该类数据多为非结构化数据,本次实战目的是通过python爬虫爬取非结构化数据转换为结构化数据存储到数据库中。
非结构化数据需经过ETL(Extract, Transformation, loading)工具将数据转换为结构化数据才能取用
数据抽取、转换、储存(data ETL):原始资料(Raw Data)→ ETL脚本(ETL Script)→ 结构化数据(Tidy Data)
环境配置:开始→anaconda3→acaconda prompt 输入:pip install requests
pip install BeautifulSoup4
二、网络爬虫架构
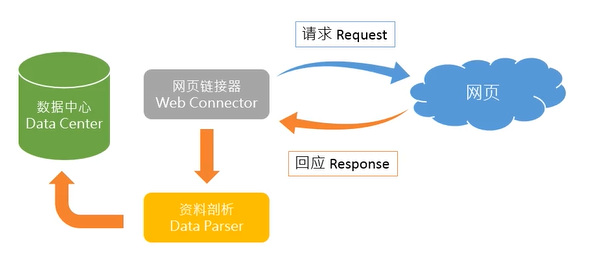
1. 单击鼠标右键 → 检查 → 网络(Network)→ 右上角红色点打开 → 刷新页面 → 内容类型选择文档(Doc)→ 查看Reponse请求找到对应页面
2. 点击headers → 使用get存储:Request URL
备注:Doc下第一个链接包含90%媒体资讯,剩下10%在XHR等其他部分
观察元素抓取位置
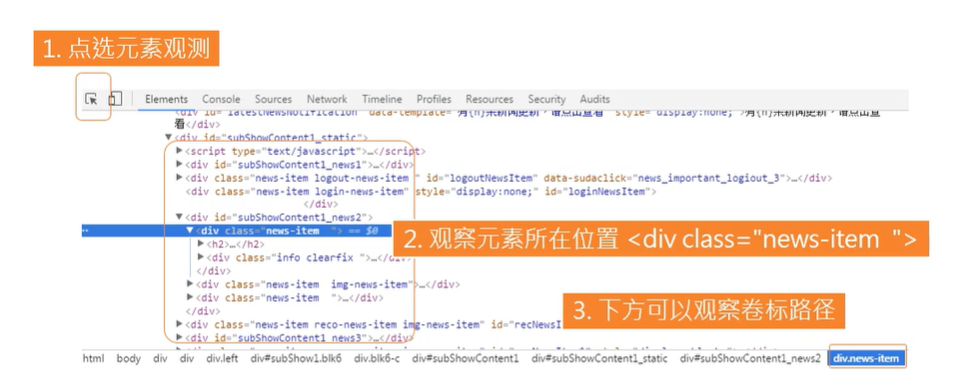

三、撰写新浪新闻网络爬虫(爬取新浪微博国际性新闻)
