Spark SQL概述
前言:一些逻辑用spark core 来写,会比较麻烦,如果用sql 来表达,那简直太方便了
一、Spark SQL 是什么
是专门处理结构化数据的 Spark 组件
Spark SQL 提供了两种操作数据的方法:
sql 查询
DataFrames/Datasets API
Spark SQL = Schema + RDD
二、Spark SQL引入的主要动机
更快地编写和运行Spark程序
编写更少的代码,读取更少的数据,让优化器自动优化程序,释放程序员的工作

三、Spark SQL总体架构
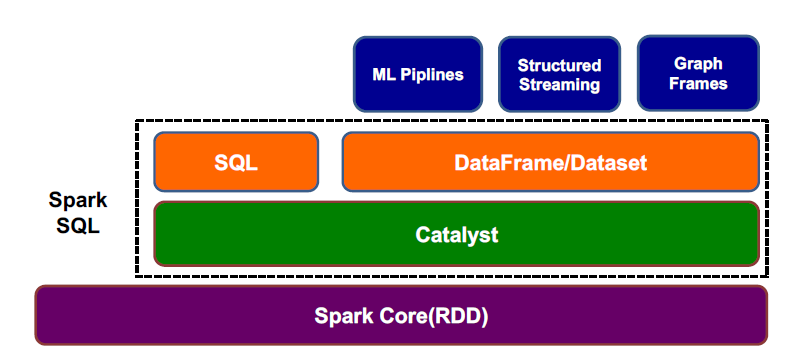
Spark SQL 最底层是 Spark Core,上面的 Catalyst 是一个执行计划的优化器,可以帮助优化查询
在 Catalyst 之上还有两个组件,SQL 和 DataFrame/Dataset ,这两个组件上层对应的接口不一样,SQL 对应的是纯粹的 sql 语句的输入,DataFrame/Dataset 对应的是他们的api产生的输入
SQL 和 DataFrame/Dataset 这两个组件最终的结果都会输入到 Catalyst 这个优化器,等优化后,最终结果会交给 Spark Core 来运行
下面三行是 Spark SQL 的套件,在之上还有一些更高级的 API ,比如机器学习等
四、SQL 与 DataFrame/Dataset
Spark 提供了两种编写 Spark SQL 程序的 API,使用 SQL 查询或者使用 DataFrame/Dataset
使用SQL
如果你非常熟悉SQL语法,则使用SQL
使用DataFrame/Dataset
DSL(Domain Specific Language):DSL是一个规范,比如上上个图中的 table,avg,groupby 就是,网上自行搜索 DSL
采用更通用的语言(Scala,Python)表达你的查询需求
使用DataFrame更快的捕获错误:SQL 是编译时不检查,运行时检查,而 DataFrame 则是在编译时就去检查,比如检查列是否存在,列类型是否正确
五、Spark SQL API演化
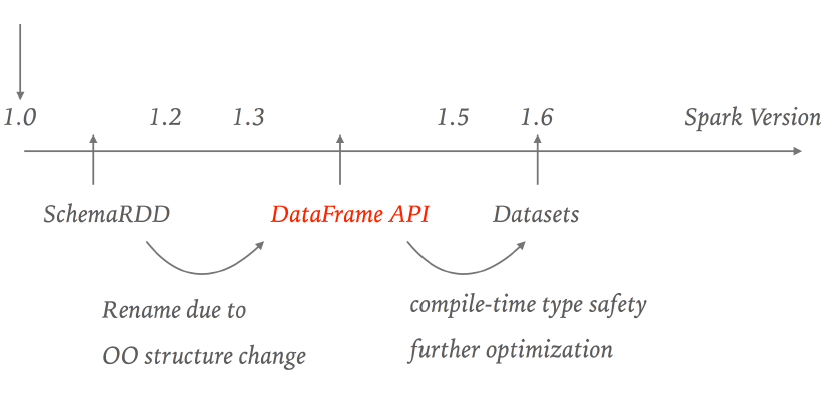
1.3后引入了 DataFrame,但之后发现有一些限制,又引入 Dataset,本来他们两个是不同的 API,后来版本中发现 DataFrame 和 Dataset 有互通的地方,于是2.0里面,DataFrame 成了 Dataset 的子集
1、RDD API(2011)
JVM对象组成的分布式数据集合
不可变且具有容错能力
可处理结构化与非结构化数据
函数式转换
2、RDD API的局限性
无Schema
用户自己优化程序
从不同的数据源读取数据非常困难
合并多个数据源中的数据也非常困难
3、DataFrame API(2013)
Row对象组成的分布式数据集合:一个数据集有很多个记录构成,每个记录都是一个 Row 的对象,Row 保存的信息有,包含哪些列,列名是什么,每一列是什么数据类型
不可变且具有容错能力
处理结构化数据
自带优化器Catalyst,可自动优化程序
Data source API: DataFrame 比 RDD API 更方便的一点是,有一个 Data source API,它可以让用户非常方便的去读取各种数据源的数据
所以 DataFrame 内部是无类型的,即 Row 是无类型的,但是 Row 这一行数据里面是有类型的
DataSet 内部是有类型的,java 对象,需要用户自己去定义
DataFrame 是一种特殊类型的 DataSet
4、DataFrame API的局限性
运行时类型检查
不能直接操作domain对象
函数式编程风格
举例:
val dataframe = sqlContext.read.json("people.json”) dataframe.filter("salary > 1000").show() //局限性 Throws Runtime exception org.apache.spark.sql.AnalysisException: cannot resolve 'salary' given input columns age, name; //Create RDD[Person] val personRDD = sc.makeRDD(Seq(Person("A",10), Person("B",20))) //Create dataframe from a RDD[Person] val personDF = sqlContext.createDataFrame(personRDD) //We get back RDD[Row] and not RDD[Person] personDF.rdd //局限性 RDD 转换为 DF , DF再转回 RDD 后,会丢失一些信息
注:Spark RDD、DataFrame和DataSet的区别自行网上搜索
5、Dataset
Dataset 扩展自 DataFrame API,提供了编译时类型安全,面向对象风格的 API


case class Person(name: String, age: Int) val dataframe = sqlContext.read.json("people.json") val ds : Dataset[Person] = dataframe.as[Person] // Compute histogram of age by name val hist = ds.groupBy(_.name).mapGroups({ case (name, people) => { val buckets = new Array[Int](10) people.map(_.age).foreach { a => buckets(a / 10) += 1 } (name, buckets) } })
Dataset API
类型安全:可直接作用在domain对象上
//Create RDD[Person] val personRDD = sc.makeRDD(Seq(Person("A",10), Person("B",20))) //Create Dataset from a RDD val personDS = sqlContext.createDataset(personRDD) personDS.rdd //We get back RDD[Person] and not RDD[Row] in Dataframe
高效:代码生成编解码器,序列化更高效
协作:Dataset与Dataframe可相互转换
编译时类型检查
case class Person(name: String, age: Long) val dataframe = sqlContext.read.json("people.json") val ds : Dataset[Person] = dataframe.as[Person]
ds.filter(p => p.age > 25) ds.filter(p => p.salary > 12500) //error: value salary is not a member of Person

 浙公网安备 33010602011771号
浙公网安备 33010602011771号