Hive练习
一、基础DDL练习
SHOW DATABASES; CREATE DATABASE IF NOT EXISTS db1 COMMENT 'Our database db1'; SHOW DATABASES; DESCRIBE DATABASE db1; CREATE TABLE db1.table1 (word STRING, count INT); SHOW TABLES in db1; DESCRIBE db1.table1; USE db1; SHOW TABLES; SELECT * FROM db1.table1; DROP TABLE table1; DROP DATABASE db1; USE default;
二、基础DML语句
创建表 create table if not exists user_dimension ( uid STRING, name STRING, gender STRING, birth DATE, province STRING )ROW FORMAT DELIMITED //按行切分的意思 FIELDS TERMINATED BY ',' //按逗号分隔的 查看表信息 describe user_dimension; show create table user_dimension; 查看所有表 show tables; 载入本地数据 load data local inpath '/home/orco/tempdata/user.data' overwrite into table user_dimension; 载入HDFS上的数据 load data inpath '/user/orco/practice_1/user.data' overwrite into table user_dimension; 验证 select * from user_dimension; 查看hive在hdfs上的存储目录 hadoop fs -ls /warehouse/ hadoop fs -ls /warehouse/user_dimension
三、复杂数据类型
示例2: CREATE TABLE IF NOT EXISTS employees ( name STRING, salary FLOAT, subordinates ARRAY<STRING>, deductions MAP<STRING, FLOAT>, address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' COLLECTION ITEMS TERMINATED BY '\002' MAP KEYS TERMINATED BY '\003' LINES TERMINATED BY '\n' STORED AS TEXTFILE; //最后这一行,是默认,可以不写 载入数据 load data local inpath ' /home/orco/tempdata/data/employees.txt' overwrite into table employees ; 查询数据 SELECT name, deductions['Federal Taxes'] FROM employees WHERE deductions['Federal Taxes'] > 0.2; SELECT name, deductions['Federal Taxes'] FROM employees WHERE deductions['Federal Taxes'] > cast( 0.2 as float); SELECT name FROM employees WHERE subordinates[1] = 'Todd Jones'; SELECT name, address FROM employees WHERE address.street RLIKE '^.*(Ontario|Chicago).*$';
四、数据模型-分区
为减少不必要的暴力数据扫描,可以对表进行分区,为避免产生过多小文件,建议只对离散字段进行分区

建表 CREATE TABLE IF NOT EXISTS stocks ( ymd DATE, price_open FLOAT, price_high FLOAT, price_low FLOAT, price_close FLOAT, volume INT, price_adj_close FLOAT ) PARTITIONED BY (exchanger STRING, symbol STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; 载入数据 load data local inpath '/home/orco/resources/apache-hive-2.1.1-bin/hivedata/stocks/NASDAQ/AAPL/stocks.csv' overwrite into table stocks partition(exchanger="NASDAQ", symbol="AAPL"); show partitions stocks; load data local inpath '/home/orco/resources/apache-hive-2.1.1-bin/hivedata/stocks/NASDAQ/INTC/stocks.csv' overwrite into table stocks partition(exchanger="NASDAQ", symbol="INTC"); load data local inpath '/home/orco/resources/apache-hive-2.1.1-bin/hivedata/stocks/NYSE/GE/stocks.csv' overwrite into table stocks partition(exchanger="NYSE", symbol="GE"); show partitions stocks; 查询 SELECT * FROM stocks WHERE exchanger = 'NASDAQ' AND symbol = 'AAPL' LIMIT 10; SELECT ymd, price_close FROM stocks WHERE exchanger = 'NASDAQ' AND symbol = 'AAPL' LIMIT 10; 查看HDFS文件目录 hadoop fs -ls /warehouse/stocks/ hadoop fs -ls /warehouse/stocks/exchanger=NASDAQ hadoop fs -ls /warehouse/stocks/exchanger=NASDAQ/symbol=AAPL
六、外部表
external关键字,删除表时,外部表只删除元数据,不删除数据,更加安全
数据 hadoop fs -put stocks /user/orco/ 创建外部表 CREATE EXTERNAL TABLE IF NOT EXISTS stocks_external ( ymd DATE, price_open FLOAT, price_high FLOAT, price_low FLOAT, price_close FLOAT, volume INT, price_adj_close FLOAT ) PARTITIONED BY (exchanger STRING, symbol STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/user/orco/stocks'; select * from stocks_external; 载入数据 alter table stocks_external add partition(exchanger="NASDAQ", symbol="AAPL") location '/user/orco/stocks/NASDAQ/AAPL/' show partitions stocks_external; select * from stocks_external limit 10; alter table stocks_external add partition(exchanger="NASDAQ", symbol="INTC") location '/user/orco/stocks/NASDAQ/INTC/'; alter table stocks_external add partition(exchanger="NYSE", symbol="IBM") location '/user/orco/stocks/NYSE/IBM/'; alter table stocks_external add partition(exchanger="NYSE", symbol="GE") location '/user/orco/stocks/NYSE/GE/'; show partitions stocks_external; 查询 SELECT * FROM stocks_external WHERE exchanger = 'NASDAQ' AND symbol = 'AAPL' LIMIT 10; SELECT ymd, price_close FROM stocks_external WHERE exchanger = 'NASDAQ' AND symbol = 'AAPL' LIMIT 10; select exchanger, symbol,count(*) from stocks_external group by exchanger, symbol; select exchanger, symbol, max(price_high) from stocks_external group by exchanger, symbol; 删除表 删除内部表stocks drop table stocks; 查看HDFS上文件目录 hadoop fs -ls /warehouse/ 删除外部表stocks_external drop table stocks_external; 查看HDFS上文件目录 hadoop fs -ls /user/orco hadoop fs -ls /user/stocks
七、列式存储
在Create/Alter表的时候,可以为表以及分区的文件指定不同的格式
• Storage Formats
• Row Formats
• SerDe
STORED AS file_format
– STORED AS PARQUET
– STORED AS ORC
– STORED AS SEQUENCEFILE
– STORED AS AVRO
– STORED AS TEXTFILE
列式存储格式ORC与Parquet:存储空间

列式存储格式ORC与Parquet:性能
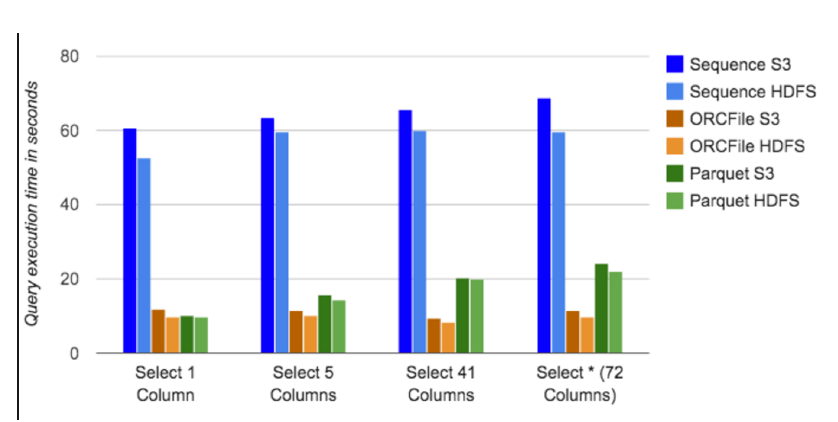
如何创建ORC表

create table if not exists record_orc ( rid STRING, uid STRING, bid STRING, price INT, source_province STRING, target_province STRING, site STRING, express_number STRING, express_company STRING, trancation_date DATE ) stored as orc; show create table record_orc; 载入数据 select * from record_orc limit 10; insert into table record_orc select * from record; select * from record_orc limit 10;
八、Lateral View,行转多列

CREATE TABLE IF NOT EXISTS employees ( name STRING, salary FLOAT, subordinates ARRAY<STRING>, deductions MAP<STRING, FLOAT>, address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' COLLECTION ITEMS TERMINATED BY '\002' MAP KEYS TERMINATED BY '\003' LINES TERMINATED BY '\n' STORED AS TEXTFILE; 查询 select name,subordinate from employees LATERAL VIEW explode(subordinates) subordinates_table AS subordinate;
九、explain

 浙公网安备 33010602011771号
浙公网安备 33010602011771号