
scrapy中间件
scrapy中间件主要由2个,1个是下载中间件,1个是爬虫中间件。
一、下载中间件
下载中间件主要用到的方法有三个:
process_request(self, request, spider):用来处理正常的请求对象的数据,每个request请求通过下载中间件时,该方法被调用,可以用来设置headers,proxy等。
process_response(self, request, response, spider):用来处理响应对象的数据
process_exception(self, request, exception, spider):用来处理抛异常的请求对象的数据
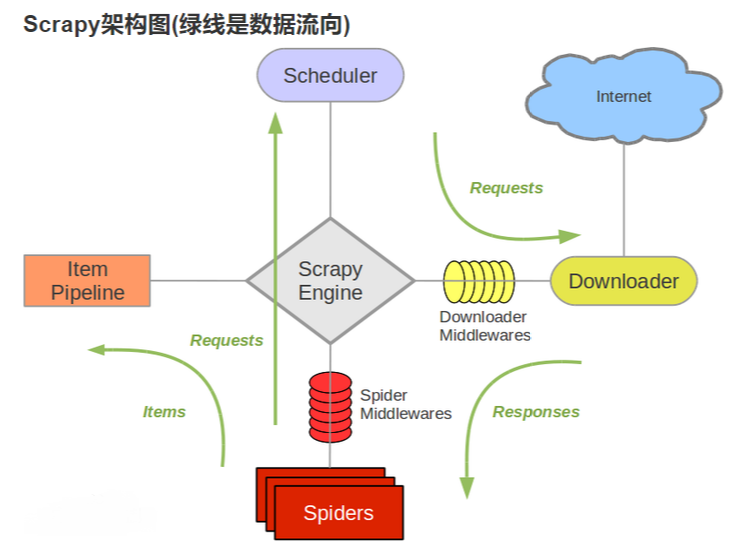
引擎engine将request对象交给下载器之前,会经过下载器中间件;中间件提供了一个方法 process_request,可以对 request对象设置headers,proxy、Cookie等;
当下载器完成下载,获得到 response对象,将它交给引擎engine的时,又会经过 下载器中间件;此时,中间件提供了另一个方法 process_response,可以判断 response对象的状态码,来决定是否将 response提交给引擎。
(1)process_request(self,request,spider)
- request:发送请求的 request 对象
- spider:发送请求的 spider 对象
返回值有可能会返回下面的任何一种:
- 返回 None:如果返回 None,Scrapy 将继续处理该 request,执行其他中间件中的相应方法,直到合适的下载器处理函数被调用
- 返回 Response 对象:Scrapy 将不会调用任何其他的 process_request 方法,将直接返回这个 response 对象,已经激活的中间件的 process_response() 方法则会在每个 response 返回时被调用
- 返回 Request 对象:Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用
- 如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。
def process_request(self, request, spider): # 设置headers request.headers["User-Agent"] = random.choice(self.user_agent_list)
同理,还可以设置proxy、cookies等。
(2)process_response(self,request,response,spider)
下载器下载的数据到引擎中间会执行的方法。
- request:request 对象
- response:被处理的
- response 对象
- spider:spider 对象
返回值可能会返回如下几种:
- 返回 Response 对象,会将这个新的 response 对象传给其他中间件,最终传给爬虫
- 返回 Request 对象:下载器链被切断,返回的 request 会重新被下载器调度下载。
- 如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
(3)process_exception(self, request, exception, spider)
返回值返回以下几种:
- 返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
- 返回Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
- 返回 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。
二、爬虫中间件
(使用不多,有一定了解后再续)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号