Java IO总结
[Java IO Demo]
http://blog.csdn.net/pistolove/article/details/62210164
https://www.cnblogs.com/ylspace/p/8128112.html[总结的很好]
目录
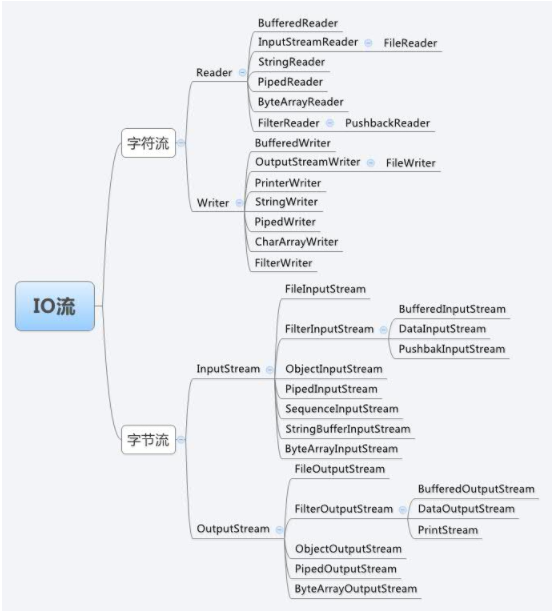
1. InputStream&&OutputStream体系结构
1.1 InputStream&&OutputStream API
1.2 FileInputStream&&FileOutputStream 文件字节流
1.3 while ((n = is.read(byteArray)) != -1) 中n的作用
1.4 PipedInputStream&&PipedOutputStream 管道字节流
1.5 FilterInputStream&&FilterOutputStream
1.5.1 BufferedInputStream&&BufferedOutputStream 缓冲字节流
1.5.2 BufferedInputStream的优势在于效率,减少了从硬盘读取的次数;使用时需使byte[]的长度小于缓存区数组的长度(默认8192)
1.6 ObjectInputStream&&ObjectOutputStream 对象字节流
2. Reader&&Writer 字符流
2.1 源码
2.2 字节流和字符流对比
2.3 BufferedReader&&BufferedWriter 缓冲字符流
2.4 InputStreamReader&&OutputStreamWriter 字节字符转换
2.5 FileReader是InputStreamReader的子类,FileWriter是OutputStreamWriter的子类
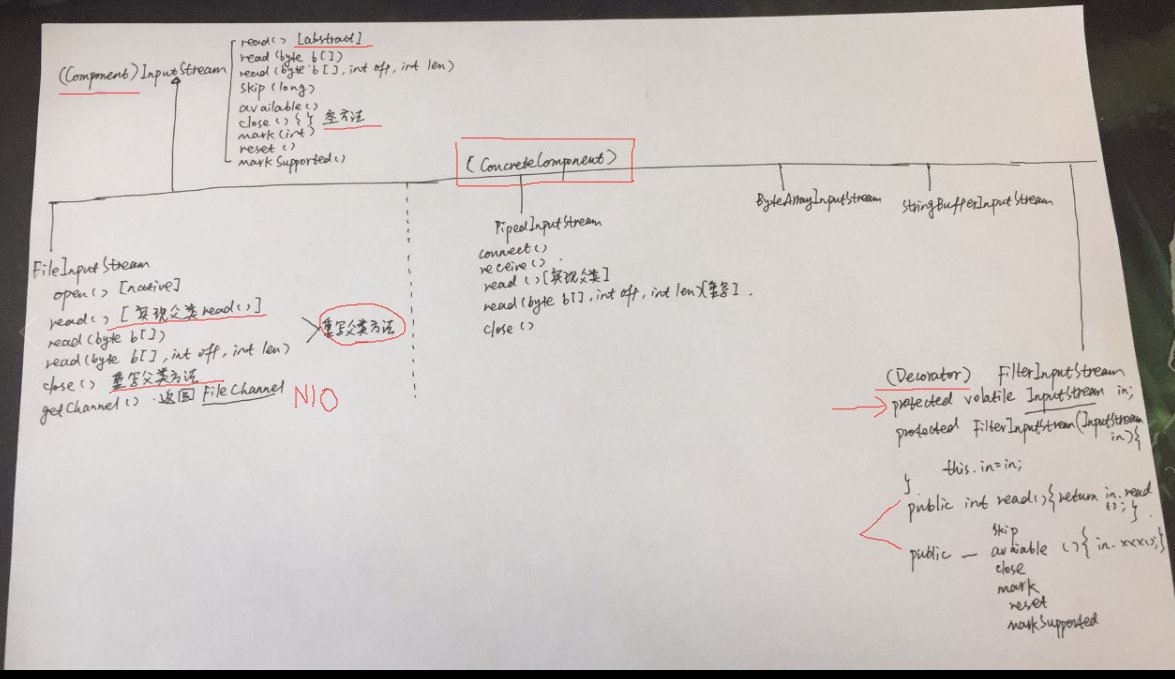
InputStream&&OutputStream体系结构
任何来自InputStream或Reader派生而来的类都包含read()基本方法,用于读取单个字节或字节数组; 任何来自OutputStream或Writer派生而来的类都包含write()基本方法,用于写入单个字节或字节数组;。但是,通常不会使用它们,它们之所以存在是因为其他类要使用它们,以提供更有用的接口。因此,很少使用单一的类来创建流对象,而是通过叠合多个对象来提供所期望的功能(装饰器模式)。Java流类库让人困惑的主要原因是:创建单一的接过来,却需要创建多个不同对象
字节序列的来源和目的地可以是: char[]、String、文件、管道(一端输入,一端输出)、网络。每一种数据源都有相对应的InputStream子类,另外,FilterInputStream也是一种InputStream[FilterOutputStream也是一种OutputStream],为"装饰器"类(具体Decorator)提供基类(下面讨论)
抽象类InputStream和OutputStream构成字节流类层次的基础
InputStream&&OutputStream API
1. public abstract int read() throws IOException;
读入一个来自文件/网络/内存的字节,并返回该字节,如遇到输入源的结尾,返回-1
2. InputStream抽象类中还有一些非抽象方法,例如read(byte b[]),读入1个字节数组,但该方法依然调用抽象的read(),因此,InputStream的各个子类只需要覆盖InputStream抽象类的抽象read()
read(byte b[]) 读入1个字节数组,返回实际读入的字节个数,如果遇到结尾,返回-1
public int read(byte b[]) throws IOException{
return read(b,0,b.length);
}
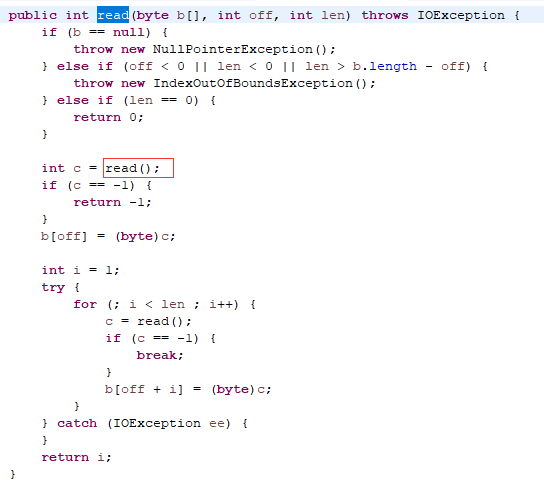
read(byte[] b,int off,int len)
off 第一个读入字节被放置在数组b中的位置
len 读入字节的最大数量
3. [OutputStream] abstract void write(int n) 写出1个字节的数据
4. [OutputStream] void write(byte[] b)
void write(byte[] b,int off,int len)
b 数据写出的数组
off 第一个写出字节被放置在数组b中的位置
len 写出字节的最大数量
5. [OutputStream] void close() 冲刷并关闭输出流
6. [OutputStream] void flush() 冲刷输出流,将所有缓冲的数据发送到目的地
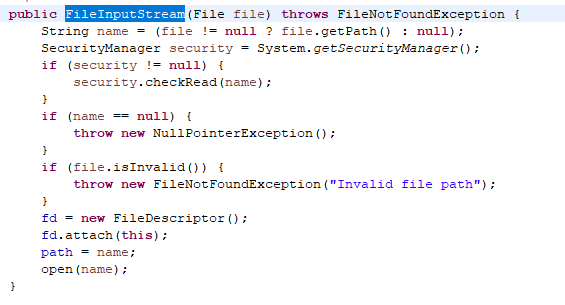
FileInputStream&&FileOutputStream 文件字节流
提供附着在一个磁盘文件上的输入输出流,只需要向其构造器提供文件名或文件的完整路径名
[Note]所有java.io包中的类都将相对路径名解释为以用户工作目录开始,可以调用System.getProperty("user.dir")获取
例如,A工程调用System.getProperty("user.dir")输出: E:\Eclipse WorkSpace路径\A [Windows系统,注意空格等的转义]
而在使用相对路径时,从System.getProperty("user.dir")输出的值,后开始写,例如
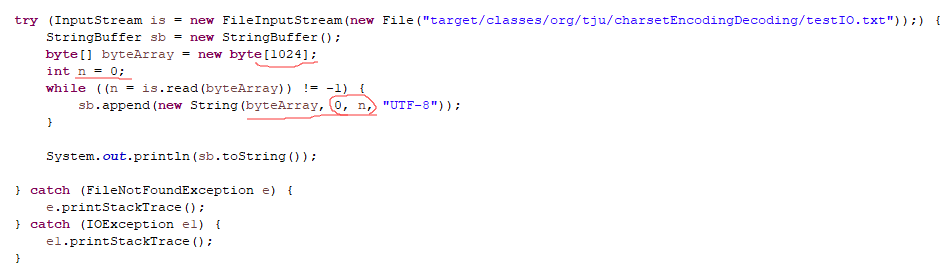
InputStream is = new FileInputStream(new File("target/classes/org/tju/charsetEncodingDecoding/testIO.txt"));

while ((n = is.read(byteArray)) != -1) 中n的作用
防止最后一次读取的字节小于buffer长度
1.
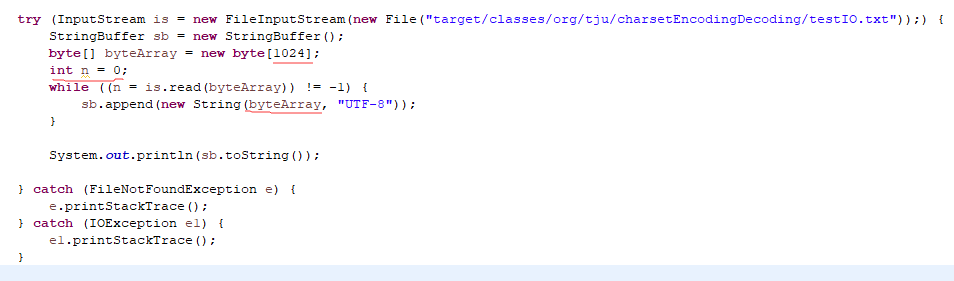
输出: 最后1次读取,实际读取的字节数小于数组长度1024,因此出现多个方块,如下

2.
PipedInputStream&&PipedOutputStream 管道字节流
管道输入流PipedInputStream与管道输出流PipedOutputStream实现了类似管道的功能,用于不同线程之间的相互通信。不要在一个线程中同时使用PipeInpuStream和PipeOutputStream,这会造成死锁
使用一个循环缓冲数组来实现,这个数组默认大小为1024字节。输入流PipedInputStream从这个循环缓冲数组中读数据,输出流PipedOutputStream往这个循环缓冲数组中写入数据。当这个缓冲数组已满的时候,输出流PipedOutputStream所在的线程将阻塞;当这个缓冲数组首次为空的时候,输入流PipedInputStream所在的线程将阻塞
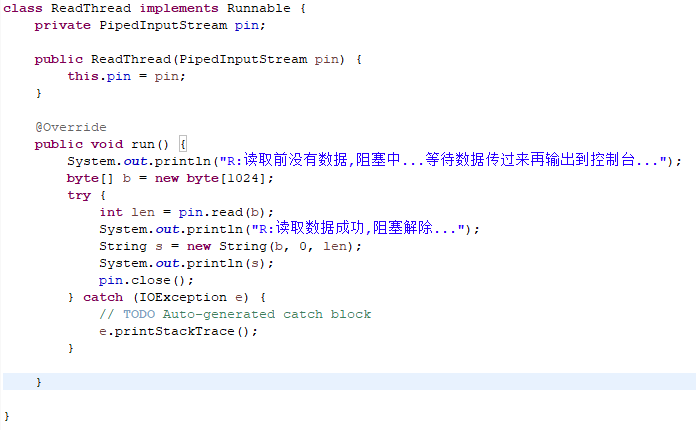

输出为:
R:读取前没有数据,阻塞中...等待数据传过来再输出到控制台...
W:开始将数据写入:但等个2秒让我们观察...
W:写入数据结束
R:读取数据成功,阻塞解除...
writePiped 数据...
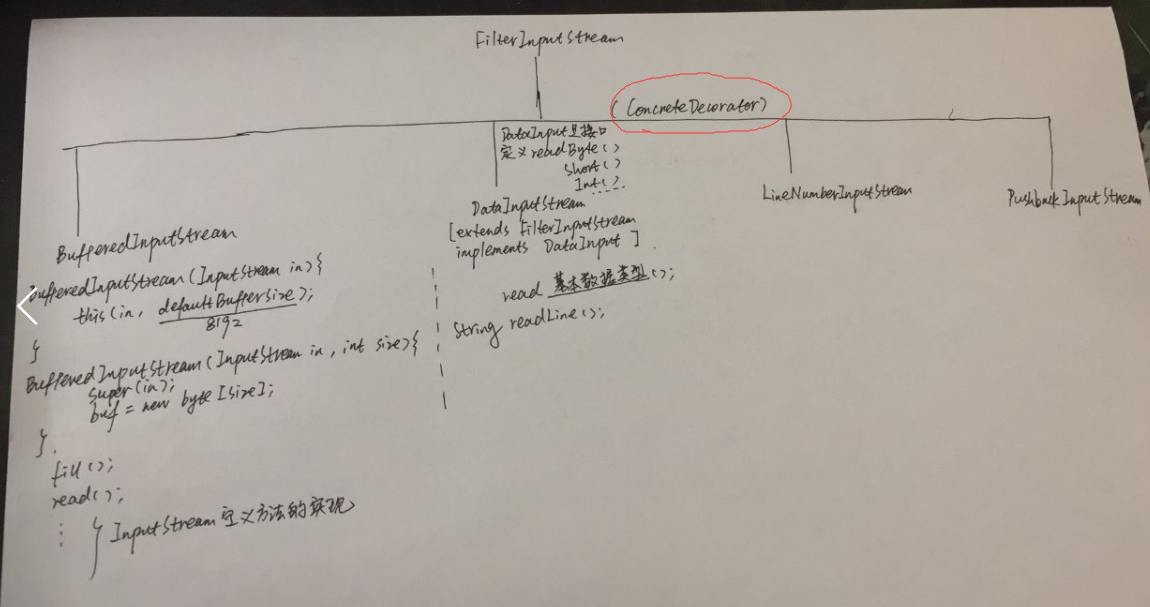
FilterInputStream&&FilterOutputStream
用来提供装饰器类接口以控制特定输入流和输出流的两个类,它们的名字并不是很直观。分别由I/O类库的基类InputStream和OutputStream派生而来
FilterInputStream类可以完成两件完全不同的事。其中,DataInputStream允许我们读取不同的基本数据类型和String(所有方法都以read开头,例如readByte()、readFloat()),搭配对应的DataOutputStream(),可以通过数据流将基本类型的数据从一个地方迁移到另一个地方;其他FilterInputStream则在内部修改InputStream的行为:是否缓冲,是否保留它所读过的行(允许查询行数/设置行数),是否把单一字符推回输入流等
BufferedInputStream&&BufferedOutputStream 缓冲字节流
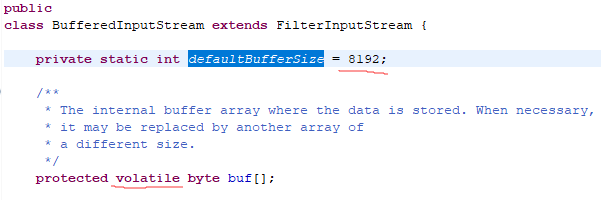
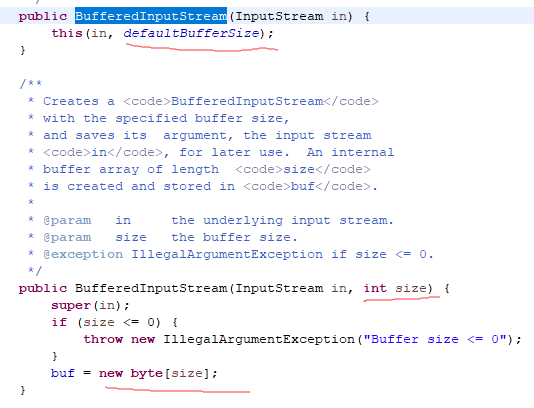
为InputStream,OutputStream类增加缓冲区功能。FileInputStream和FileOutputStream 在使用时,可以用byte数组作为数据读入的缓存区,以读文件为例,读取硬盘的速度远远低于读取内存的数据,为了减少对硬盘的读取,通常从文件中一次读取一定长度的数据,把数据存入缓存中,在写入的时候也是一次写入一定长度的数据,这样可以增加文件的读取效率
FileInputStream用byte数组来做了缓存,而BufferedInputStream和BufferedOutputStream已经为我们增加了这个缓存功能。构建BufferedInputStream实例时,需要给定一个InputStream类型的实例,实现BufferedInputStream时,实际上最后是实现InputStream实例。同样,构建BufferedOutputStream时,也需要给定一个OutputStream实例,实现BufferedOutputStream时,实际上最后是实现OutputStream实例。BufferedInputStream的数据成员buf是一个数组,默认为8192字节。当读取数据来源时,例如文件,BufferedInputStream会尽量将buf填满。当使用read()方法时,实际上是先读取buf中的数据,而不是直接对数据来源作读取。当buf中的数据不足时,BufferedInputStream才会再调用给定的InputStream对象的read()方法,从指定的装置中提取数据。BufferedOutputStream的数据成员buf也是一个数组,默认为8192字节。当使用write()方法写入数据时实际上会先将数据写到buf中,当buf已满时才会调用给定的OutputStream对象的write()方法,将buf数据写到目的地,而不是每次都对目的地作写入的动作

输出: 文件大小为4.3G
17353
28452
BufferedInputStream的优势在于效率,减少了从硬盘读取的次数;使用时需使byte[]的长度小于缓存区数组的长度(默认8192)
BufferedInputStream每次读取都是从缓冲区里拷贝数据,读完缓冲区数据再读,缓冲区没东西了就调IO从数据源读到缓冲区,然后程序再从缓冲区读
当程序的数组小于缓冲区的大小的时候才会起到缓冲作用。比如是byte[] b=new byte[2048];,要读的数据是1G,那么要调512次IO,假设一次1s,就512s 但如果用BufferedInputStream,每从缓冲区读取4(8192/2048=4)次才调用一次IO(假设访问内存一次0.1s),总共要128次IO,就128s,加上从缓冲区拷贝数据的时间(512*0.1=51.2s),128+51.2=179.2
使用1s和0.1s来体现读IO相对于读内存很耗时
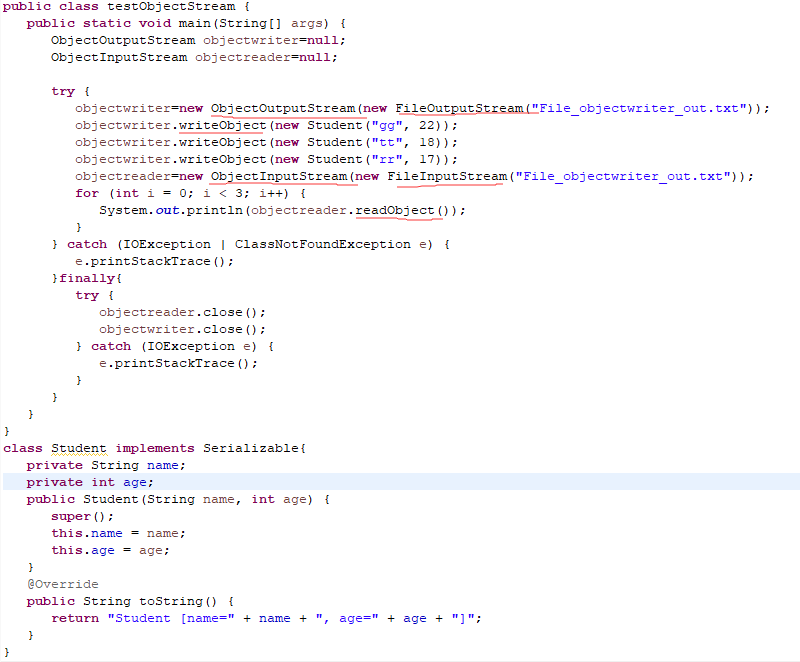
ObjectInputStream&&ObjectOutputStream 对象字节流
实体类Student必须实现Serializable接口,并重写toString()方法,否则objectwriter.writeObject(new Student("gg", 22)); 执行会报错
Reader&&Writer 字符流
Reader和Writer能够完成的操作,InputStream和OutputStream字节流也都能完成。反过来不成立
Reader和Writer只能操作文本文件,二进制文件只能使用字节流来操作
Reader是用于读取字符流的抽象类。子类必须实现的方法只有 read(char[], int, int) 和 close()。但是,多数子类将重写一些方法,以提供更高的效率和/或其他功能
Writer是用于写入字符流的抽象类。子类必须实现的方法仅有 write(char[], int, int)、flush() 和 close()。但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能
有时,我们必须把来自于"字节"层次结构的类和"字符"层次结构的类结合起来使用。为了实现这个目的,要用到"适配器"类:InputStreamReader(将InputStream转为Reader)和OutputStreamWriter(将OutputStream转为Writer)
Reader和Writer主要是为了国际化。InputStream和OutputStream只能支持8位字节流,不能处理Unicode字符。由于Unicode用于字符国际化(Java本身的char也是16位的Unicode),所有Reader和Writer是为了在所有IO中支持Unicode。另外Reader和Writer比InputStream和OutputStream更快。几乎所有原始的Java IO流类都有相对应的Reader和Writer提供天然的Unicode操作,但是有些场合,面向字节的InputStream和OutputStream才是正确的解决方案,例如java.util.zip只能面向字节,而不面向字符。因此,最明智的做法是,尽量尝试使用Reader和Writer,一旦程序代码无法正常编译,使用字节流
| 来源/去处 Java 1.0类 字节类库 | 对应的 Java 1.1类 字符类库 |
| InputStream |
Reader 适配器:InputStreamReader |
| OutputStream | Writer 适配器:OutputStreamWriter |
| FileInputStream | FileReader |
| FileOutputStream | FileWriter |
| ByteArrayInputStream | CharArrayReader |
| ByteArrayOutputStream | CharArrayWriter |
| PipedInputStream | PipedReader |
| PipedOutputStream | PipedWriter |
对于InputStream和OutputStream来说,我们会使用FilterInputStream和FilterOutputStream的装饰器子类来修改"流"以满足特殊的需求。Reader和Writer的类继承层次继续沿用相同的思想-但并不完全相同
尽管BufferedOutputStream是FilterOutputStream的子类,但是BufferedWriter并不是FilterWriter的子类(尽管BufferedWriter是抽象类,没有任何子类,把它放在那里也只是作为一个占位符)
| 来源/去处 Java 1.0类 FilterXXX | 对应的 Java 1.1类 类库 |
| FilterInputStream |
FilterReader |
| FilterOutputStream | FilterWriter(抽象类,没有子类) |
| BufferedInputStream | BufferedReader(有readLine()) |
| BufferedOutputStream | BufferedWriter |
| DataInputStream | DataInputStream(除了需要使用readLine()以外) |
| PrintStream | PrintWriter |
无论何时使用readLine(),都不应该使用DataInputStream,而是使用BufferedReader。除了readLine()以外,DataInputStream还是IO类库的首选
源码



//该抽象方法read(char cbuf[],int off,int len)是每个实现了Reader的输入流都要实现的方法,和字节流有所不同,字符流read()是抽象方法
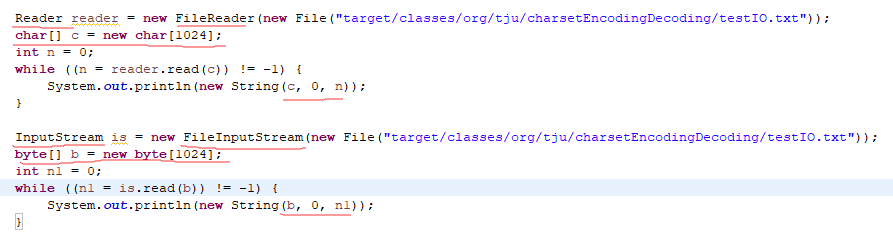
字节流和字符流对比
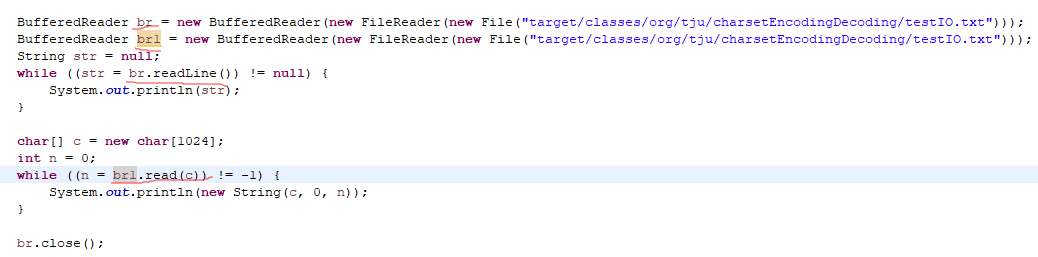
BufferedReader&&BufferedWriter 缓冲字符流
BufferedReader的readLine()方法一次读取一行,是阻塞式的, 如果到达流末尾, 就返回null[read()方法返回-1]
readLine()只有在数据流发生异常或者另一端被close()掉时,才会返回null值。如果不指定buffer大小,则readLine()使用的buffer有8192个字符。在达到buffer大小之前,只有遇到"/r"、"/n"、"/r/n"才会返回
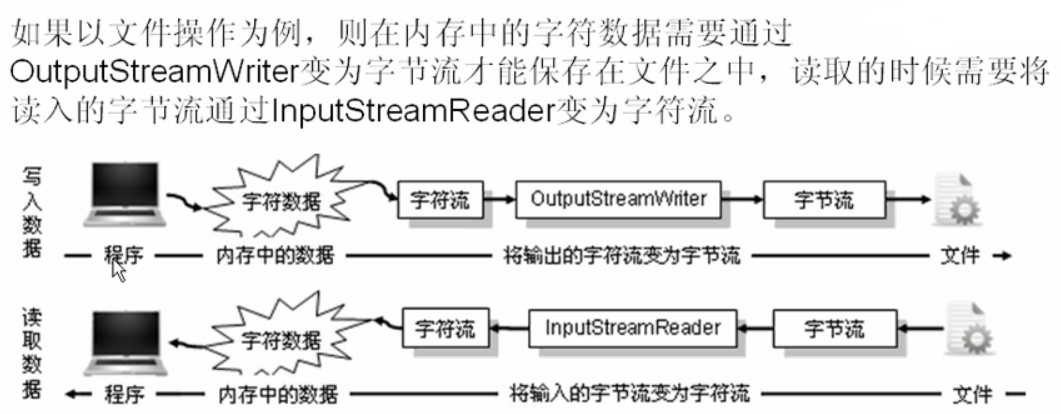
InputStreamReader&&OutputStreamWriter 字节字符转换
OutputStreamWriter:是Writer的子类,将字符流变成字节流
InputStreamReader:是Reader的子类,将字节流变成字符流

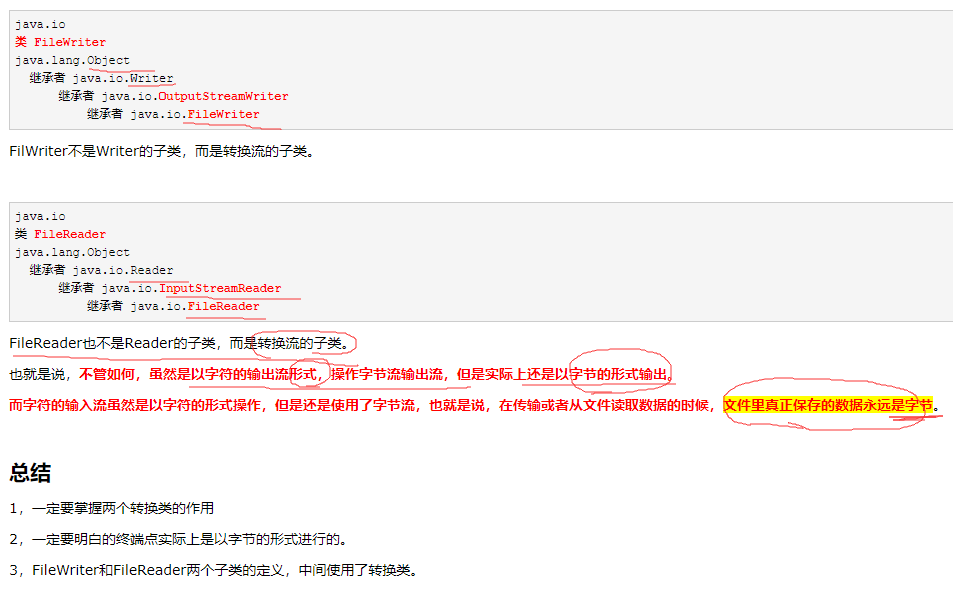
FileReader是InputStreamReader的子类,FileWriter是OutputStreamWriter的子类(FileInputStream和FileOutputStream是InputStream和OutputStream的子类,这点注意)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号