爬虫之爬取抖音用户信息-字体加密-静态
破解字体加密
获取用户的url
找到目标用户
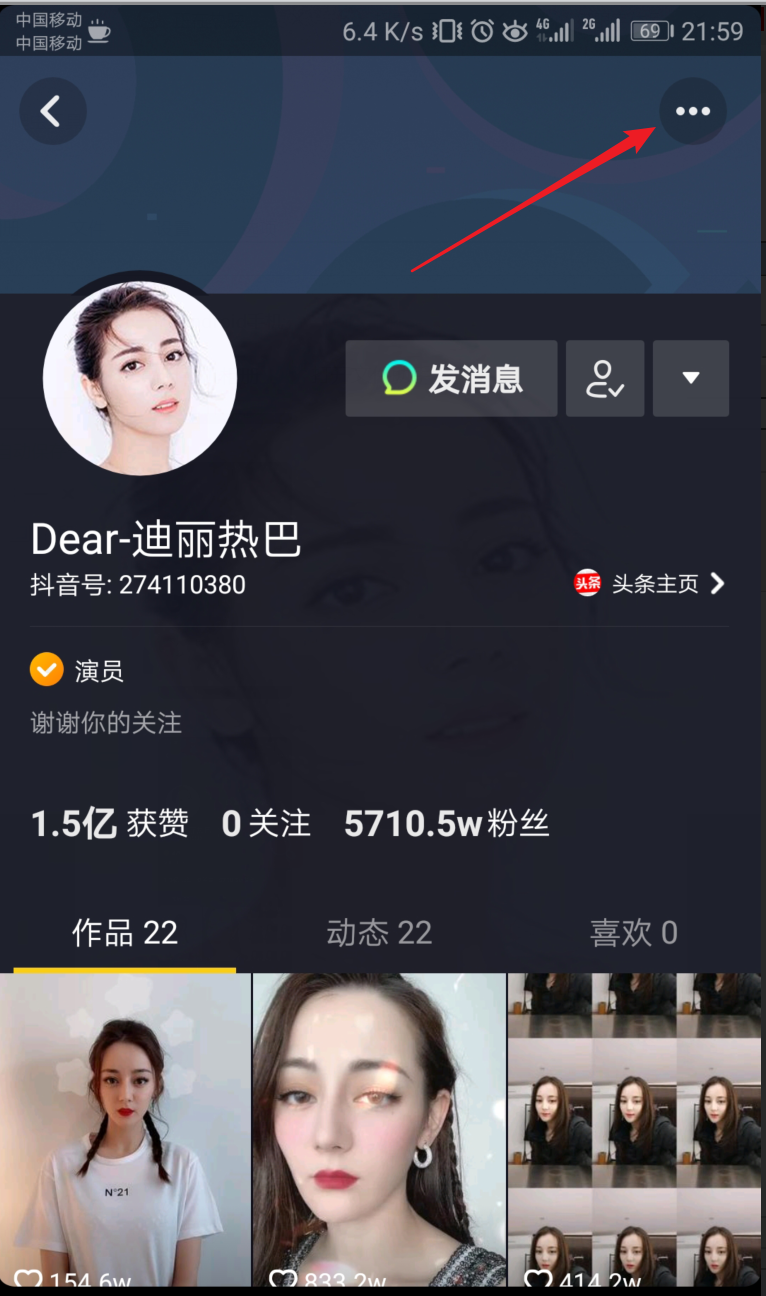
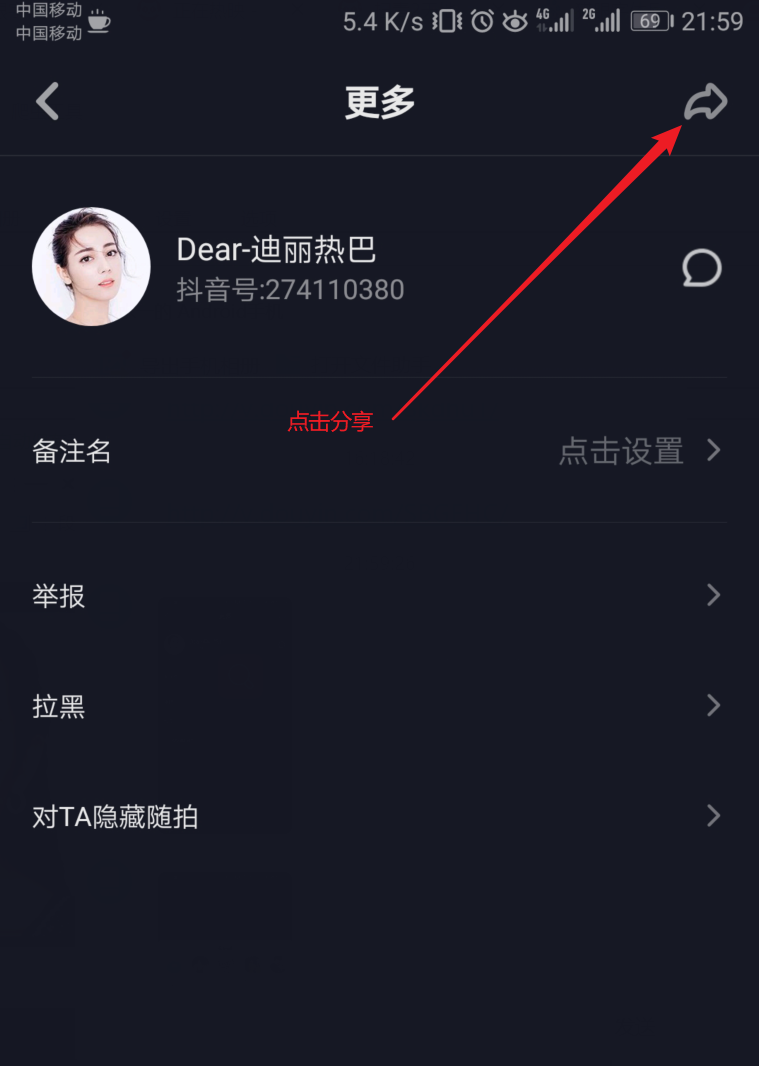

复制的链接:http://v.douyin.com/SBGFHC/
在浏览器请求后重定向的地址就是真实地址:
https://www.iesdouyin.com/share/user/88445518961?sec_uid=MS4wLjABAAAAWxLpO0Q437qGFpnEKBIIaU5-xOj2yAhH3MNJi-AUY04&u_code=g307keff×tamp=1563956307

查看我们要获取的信息
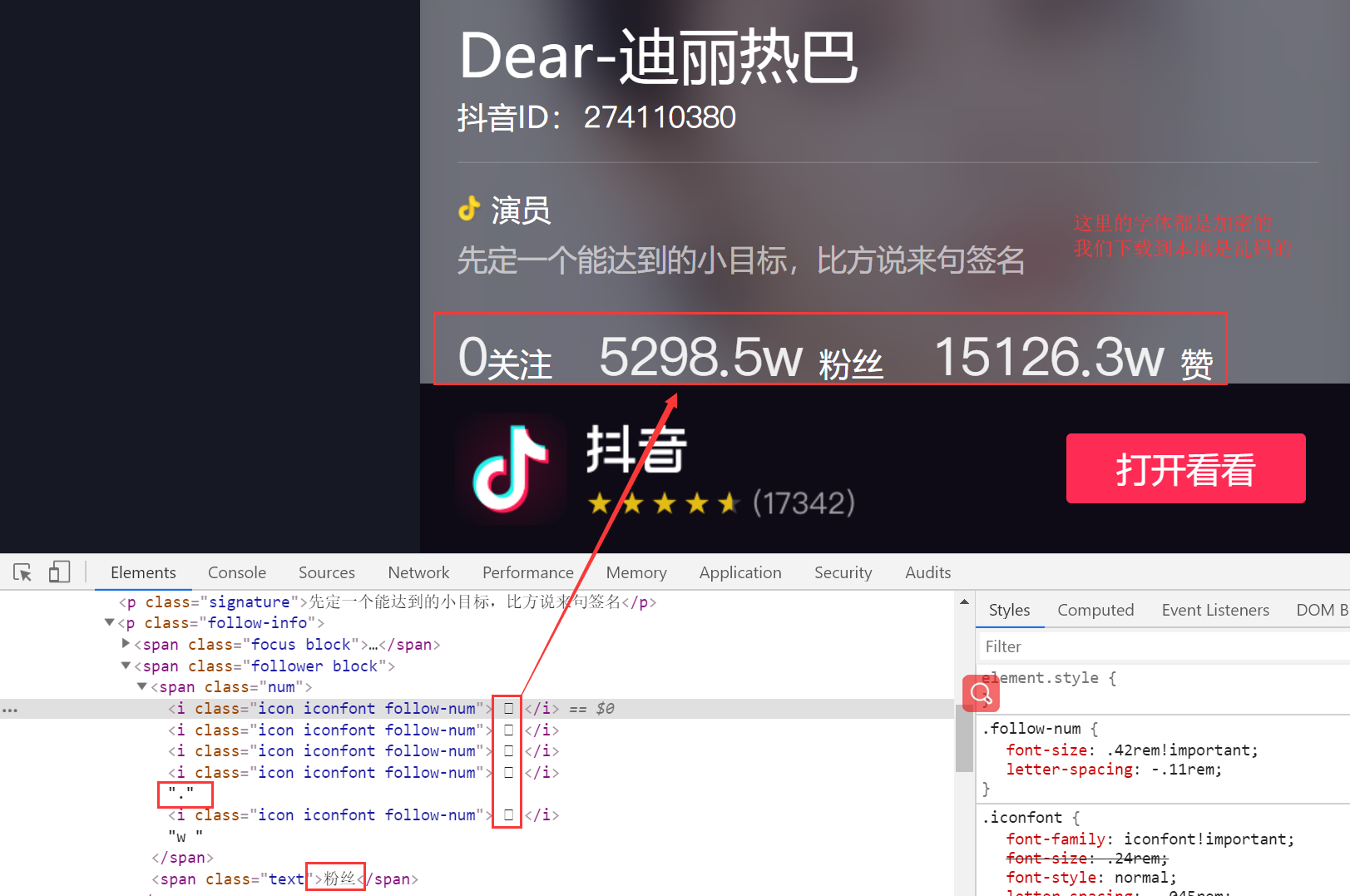
检查网页源代码
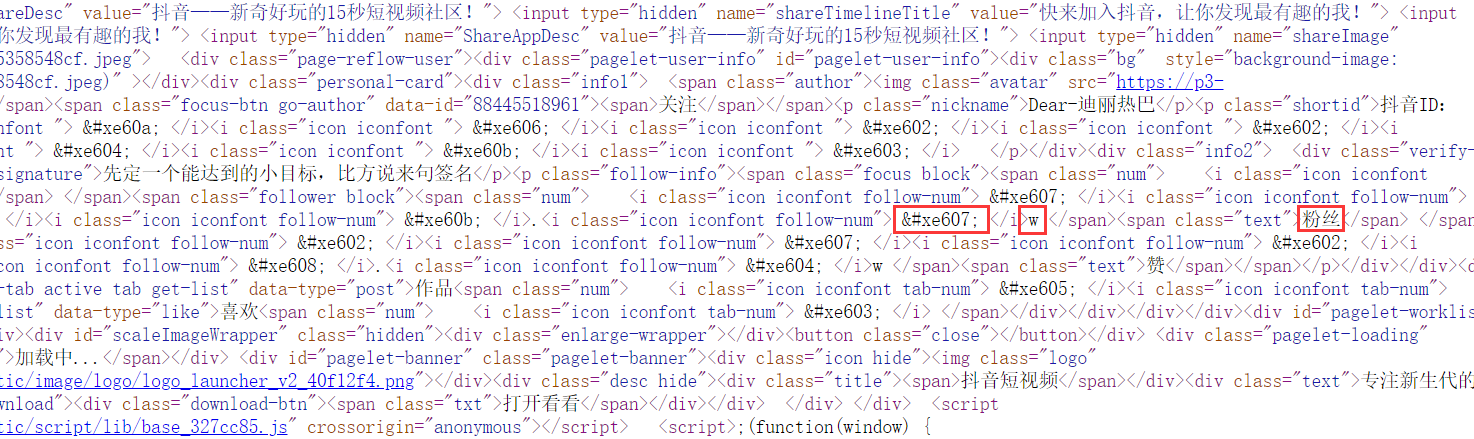
发现该网站的字体是自定义的,我们在爬取时需要获取它的字体文件,根据它的编码格式进行解码;
通过http://fontstore.baidu.com/static/editor/index.html查看下载的字体文件,每次请求获得的字体文件都一样,说明该网站自定义的字体文件只有这一个,字体映射关系不会发生改变

通过fontTools模块将文件转换成xml可读文件
from fontTools.ttLib import TTFont font = TTFont('iconfont_9eb9a50.woff') font.saveXML('iconfont_9eb9a50.xml')
具体实现代码
# -*- coding: utf-8 -*- # @Time : 2019/7/24 12:03 import re import requests from lxml import etree from fontTools.ttLib import TTFont # 从本地读取字体文件 ttfond = TTFont("iconfont_9eb9a50.woff") def get_cmap_dict(): """ :return: 关系映射表 """ # 从本地读取关系映射表【从网站下载的woff字体文件】 best_cmap = ttfond["cmap"].getBestCmap() # 循环关系映射表将数字替换成16进制 best_cmap_dict = {} for key,value in best_cmap.items(): best_cmap_dict[hex(key)] = value return best_cmap_dict # 'num_1', '0xe604': 'num_2', '0xe605': 'num_3' def get_num_cmap(): """ :return: 返回num和真正的数字映射关系 """ num_map = { "x":"", "num_":1, "num_1":0, "num_2":3, "num_3":2, "num_4":4, "num_5":5, "num_6":6, "num_7":9, "num_8":7, "num_9":8, } return num_map def map_cmap_num(get_cmap_dict,get_num_cmap): new_cmap = {} for key,value in get_cmap_dict().items(): key = re.sub("0","&#",key,count=1) + ";" # 源代码中的格式  new_cmap[key] = get_num_cmap()[value] # 替换后的格式 # '': 1, '': 0, '': 3, '': 2, return new_cmap # 获取网页源码 def get_html(url): headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' } response = requests.get(url,headers=headers).text return response def replace_num_and_cmap(result,response): """ 将网页源代码中的替换成数字 :param result: :param response: :return: """ for key,value in result.items(): if key in response: # print(777) response = re.sub(key, str(value), response) return response def manage(response): res = etree.HTML(response) douyin_name = res.xpath('//p[@class="nickname"]//text()')[0] douyin_id = 'ID:'+''.join(res.xpath('//p[@class="shortid"]/i//text()')).replace(' ','') guanzhu_num = ''.join(res.xpath('//span[@class="focus block"]//text()')).replace(' ','') fensi_num = ''.join(res.xpath('//span[@class="follower block"]//text()')).replace(' ','') dianzan = ''.join(res.xpath('//span[@class="liked-num block"]//text()')).replace(' ','') print(douyin_name,douyin_id,guanzhu_num,fensi_num,dianzan) # Dear-迪丽热巴 ID:274110380 0关注 5298.2w粉丝 15123.2w赞 if __name__ == '__main__': new_cmap = map_cmap_num(get_cmap_dict, get_num_cmap) response = get_html("https://www.iesdouyin.com/share/user/88445518961?sec_uid=MS4wLjABAAAAWxLpO0Q437qGFpnEKBIIaU5-xOj2yAhH3MNJi-AUY04&u_code=g307keff×tamp=1563956307") response = replace_num_and_cmap(new_cmap,response) manage(response)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号