

数仓随记
表全量、增量选择
大表 变化大 ---全量
大表 变化小 ---增量
小表 变化大 ---全量
小表 变化小 ---全量
查看hdf以gzip压缩的文件
hadoop fs -cat /xxxx/xxx.gz | gzip -d
或
hadoop fs -cat /xxxx/xxx.gz | zcat
dataX动态传参
python bin/datax.py -p"-Ddt=2020-06-14" job/base_province.json
CREATE TABLE my_table(a string, b bigint, ...)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
STORED AS TEXTFILE;
UDF : 进一出一
UDAF :多进一出
UDTF :一进多出
复杂表字段定义
-
array
1.定义 array
2.取值 arr[0]
3.构造 array(val1, val2, ...), split("a,b,c,d" , ","), collect_set() -
map
1.定义 map<string, bigint>
2.取值 map[key]
3.构造 map(key1, value1, key2, value2, ...), str_to_map(text[, delimiter1, delimiter2]) -
struct
1.定义 structid:int,name:string
2.取值 struct.id
3.构造 struct(val1, val2, val3, ...), named_struct(name1, val1, name2, val2, ...)
拉链标
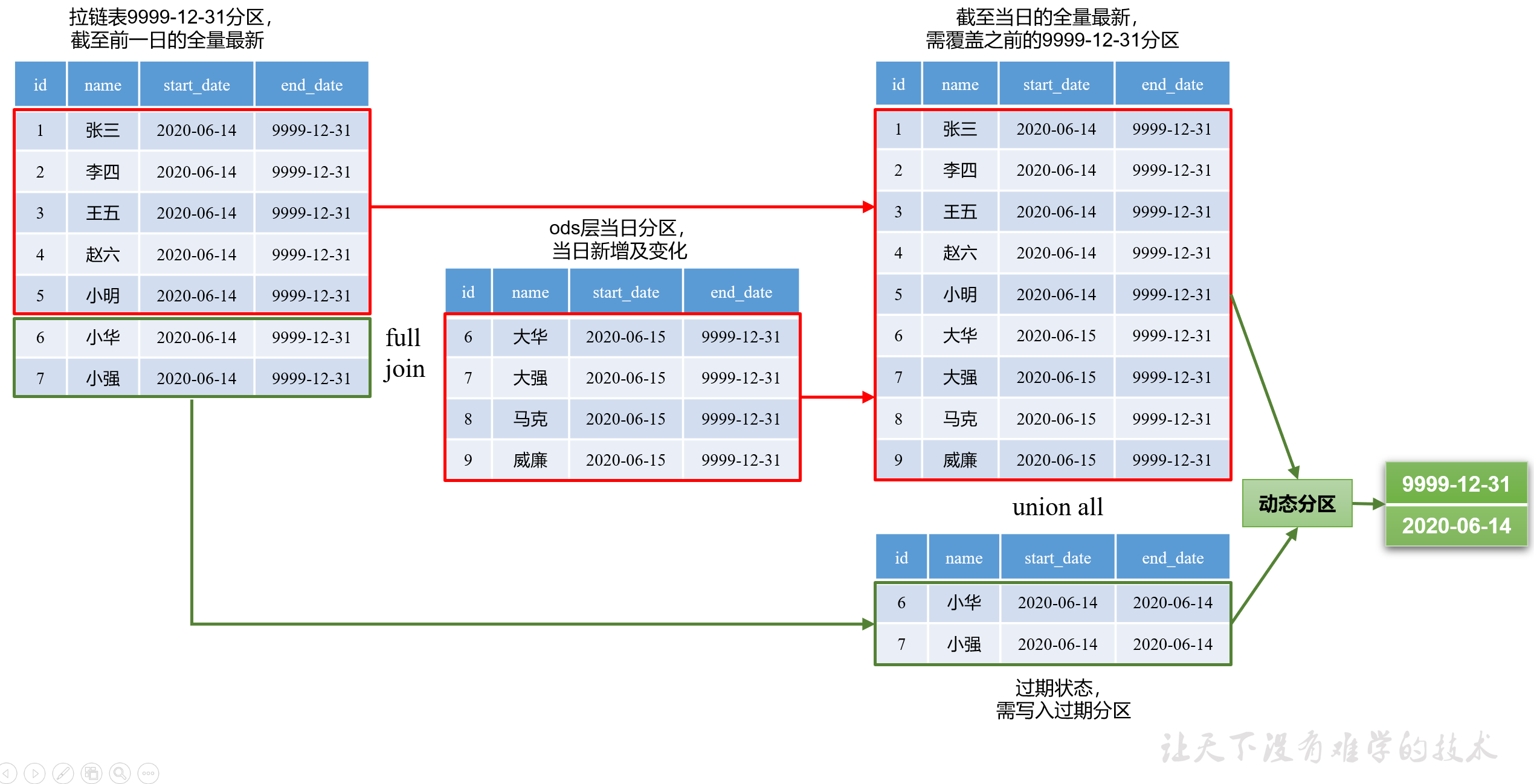
拉链表sql语句:方法一
set hive.exec.dynamic.partition.mode=nonstrict;
with a as
(
select
*
from t1
full join t2
on t1.xx=t2.xx
)
insert overwrite table t1 partition(dt)
select
新数据,
dt
from a
union all
select
旧数据,
dt
from a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号