

MAPREDUCER学习笔记
MAPREDUCE基本原理
一,概念理解
1,Mapreduce是一个分布式运算程序的编程架构,相对于HDFS来说就是客户端。其核心功能就是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并运行在一个hadoop集群上。
2,基本整体架构:MEAppMaster,MapTask,ReduceTask。
二,MapReduce框架结构及核心运行机制
1,结构:MRAppMaster:负责整个程序的过程调度及状态协调;MapTask:负责map阶段的整个数据处理流程---》数据处理;ReduceTask:负责reduce阶段的整个数据处理流程---》数据运算。
2,MR程序运行的流程(以wordcount为例子)
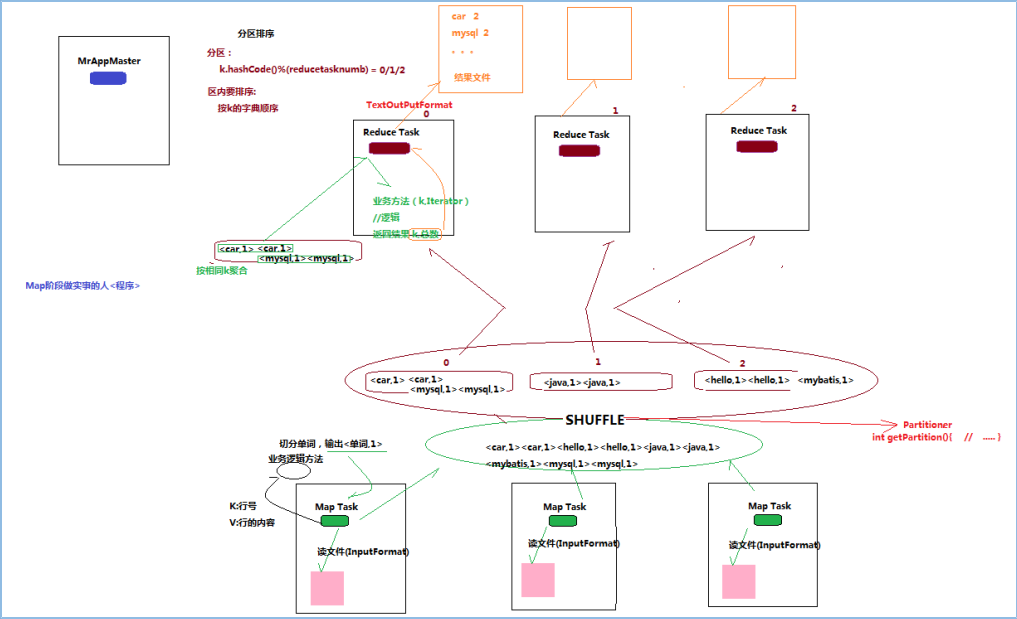
一个mr程序启动之后,首先执行的是MRAppMatser,启动之后,根据job的描述,计算出所需的MapTask的实例个数,然后向集群申请所需的MapTask的个数。
MapTask启动后根据给定的切片范围进行数据处理。
MRAppMatser监控到所有的MapTask执行完毕后,会根据客户指定的参数启动相应的数量的ReduceTask进程,并告知ReduceTask进程要处理的数据范围。
执行ReducerTask,将运算结果通过用户指定的outputformat将结果输出到外部存储。
三,MapReduce程序的运行模式
1,本地运行模式:而处理的数据及输出结果可以在本地文件系统。
2,集群运行模式:将mapreduce程序提交给yarn集群resourcemanager,分发到很多的节点上并发执行处理的数据和输出结果应该位于hdfs文件系统。
四,wordcount示例编写
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
1,定义一个mapper类
package com;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/*KEYIN指的是输入的Key
* VALUEUIN指的是输入的value
* KEYOUT输出的key值
* VALUEOUT输出的value值
*/
public class wordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//处理MRMapperMaster分配过来的数据,我们实现业务
/*LongWritable key 读取文件内容的偏移量
* Text value 文本neirong
* Context Context Mapperduce的上下文
*
* */
//从写map方法
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//每一行数据
String data =value.toString();
//获取每行单词
String[] split =data.split(" ");
//遍历数组
for (String string : split) {
//读取的每个单词都设置为key为单词,value为1
context.write(new Text(string), new IntWritable(1));
}
}
}
2,定义一个reducer类
package com; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /* * reduce的KEYIN指的是输入的key * Reduce的ValueIn 指的是输入的value * Redude的keyout指的是 输出的key * Reduce 的valueout 指的是 输出的value值 * * * */ public class wordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ //重写reduce方法 @Override protected void reduce(Text keyin, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { //统计出现单词的次数 int count =0; //循环一共出现的次数并累加 Iterator<IntWritable>iter =values.iterator(); while(iter.hasNext()){ IntWritable next =iter.next(); count+=next.get(); } context.write(keyin,new IntWritable(count)); } }
3,定义一个主类,用来描述job并提交job
package com; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.sun.jersey.core.impl.provider.entity.XMLJAXBElementProvider.Text; public class wordCountSubmit { public static void main(String[] args) throws Exception { Configuration conf=new JobConf(); conf.set("fs.defaultFS", "hdfs://192.168.184.134:9000"); Job wcj=Job.getInstance(conf); //设置jar包所需要执行的class类 wcj.setJarByClass(wordCountSubmit.class); //设置reduce所在的class类 wcj.setReducerClass(wordCountReducer.class); //设置mapper所在的class类 wcj.setMapperClass(wordCountMapper.class); //设置mapper的输出数据类型 wcj.setMapOutputKeyClass(Text.class); wcj.setMapOutputValueClass(IntWritable.class); //设置reduce的输出数据类型 wcj.setOutputKeyClass(Text.class); wcj.setOutputValueClass(IntWritable.class); //设置文件的输入输出位置 FileInputFormat.setInputPaths(wcj, "/sum"); FileOutputFormat.setOutputPath(wcj, new Path("/sum2"));//此路径下的sum2在hdfs中不能存在否则报错 //打包的jar包在虚拟机的home目录下就可以运行,不要在Hadoop的hdfs文件管理系统下运行 //提交 wcj.waitForCompletion(true); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号