🍖drf 过滤、排序、分页、异常处理
一.过滤组件 Filter
- 过滤是对多条数据进行筛选, 所以, 它只针对于 list(获取所有)
- 在请求路径中携带过滤条件, 对查询的结果进行过滤
1.drf 内置的过滤组件 SearchFilter
- models.py
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.IntegerField()
- serializer.py
from rest_framework import serializers
from drf_test import models
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = "__all__"
- views.py
class BookView2(ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = BookModelSerializer
# 导入SearchFilter组件
from rest_framework.filters import SearchFilter
# 指定组件
filter_backends = [SearchFilter]
# 指定搜索字段
search_fields = ['title', 'price']
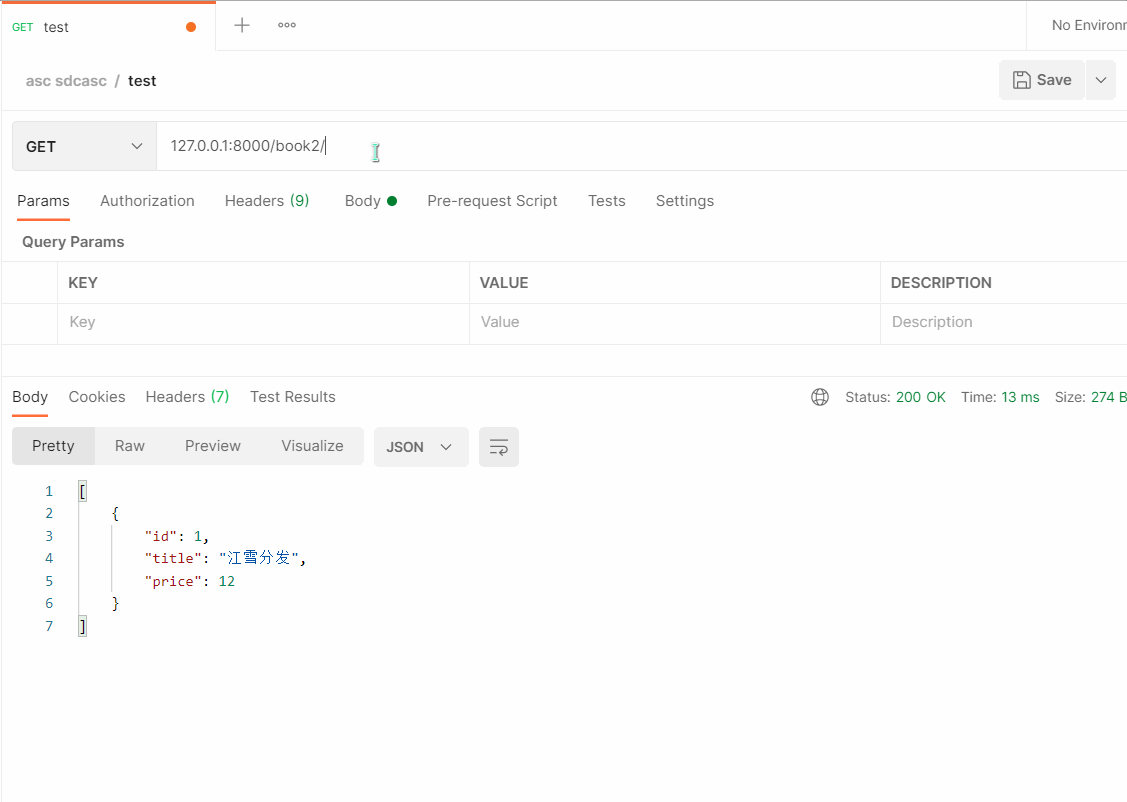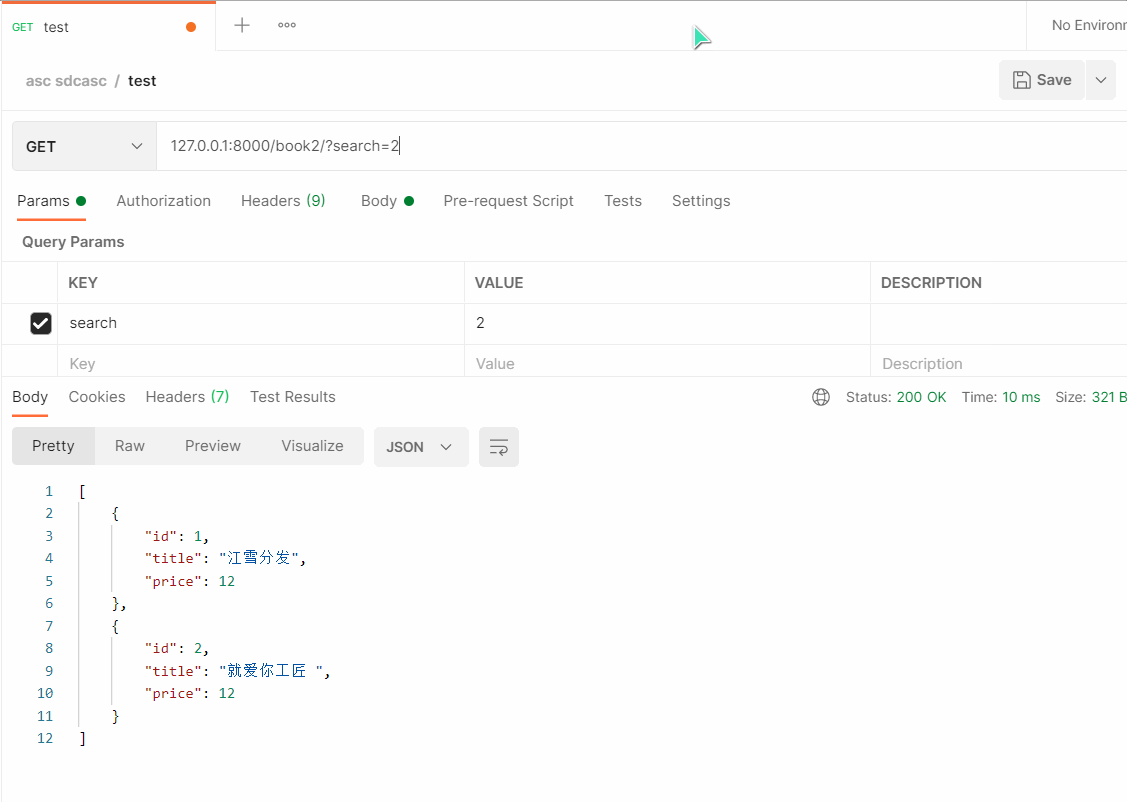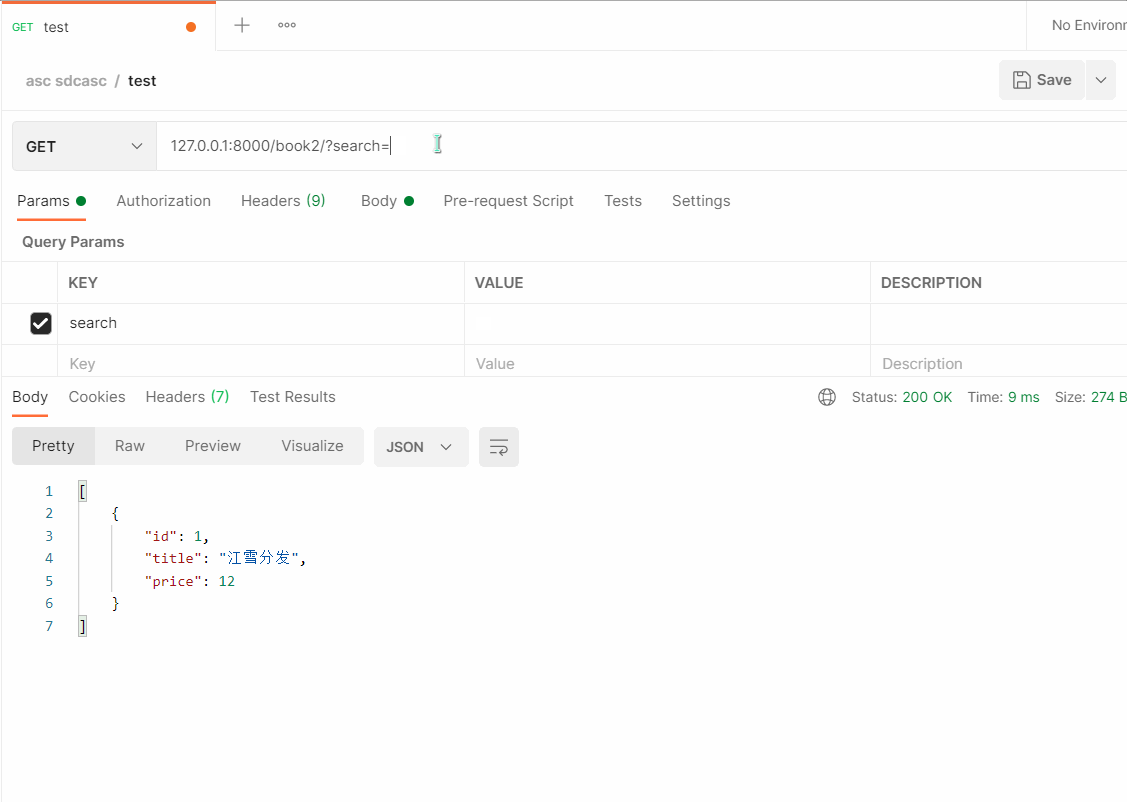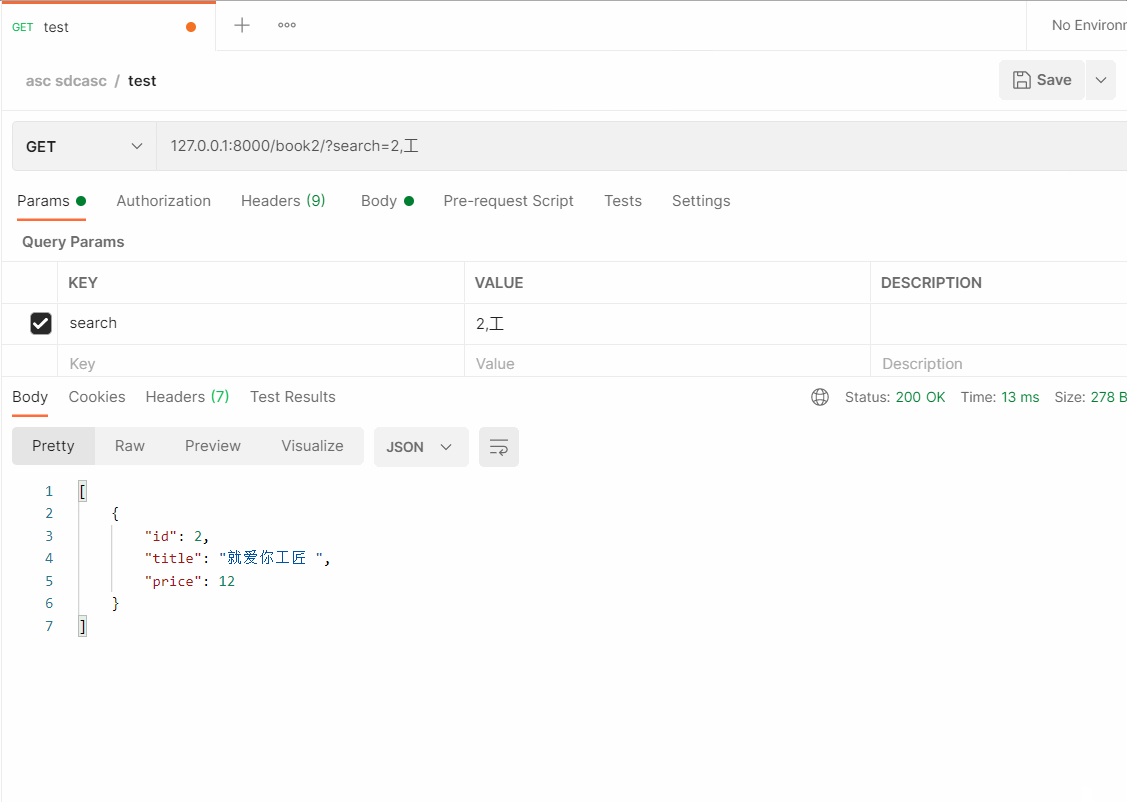
- 使用Postman来测试
# 127.0.0.1:8000/book2/?search=12
# 127.0.0.1:8000/book2/?search=2 (模糊查询)
# 127.0.0.1:8000/book2/?title=雪 (模糊查询)
- 总结
# 支持模糊查询
# 只能使用 search 来进行条件指定
# 可以使用 "," 来隔离多个条件来进行查询
# 不能查询外键字段,报错 : Related Field got invalid lookup: icontains
2.第三方过滤组件 Django-filter
- 安装 :
pip3 install django-filter - 注册 : 在
setting.py文件中注册app
INSTALLED_APPS = [
...
'django_filters',
]
- 全局配置
REST_FRAMEWORK = {
'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',),
}
- 局部配置
# 导入过滤器组件
from django_filters.rest_framework import DjangoFilterBackend
# 视图类中书写指定
filter_backends = [DjangoFilterBackend,]
filter_fields = '__all__' # 所有字段
filter_fields = ['title',..] # 指定某几个字段
- views.py 中使用
from django_filters.rest_framework import DjangoFilterBackend
class BookView2(ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = BookModelSerializer
# 指定第三方组件
filter_backends = [DjangoFilterBackend,]
# 指定字段,注意是 filter_fields,不是 search_fields
filter_fields = ['title', 'price']
- Postman 测试
# 127.0.0.1:8000/book2/?title=萨嘎达
# 127.0.0.1:8000/book2/?price=2 (不支持模糊查询)
# 127.0.0.1:8000/book2/?price=34&title=阿嘎达
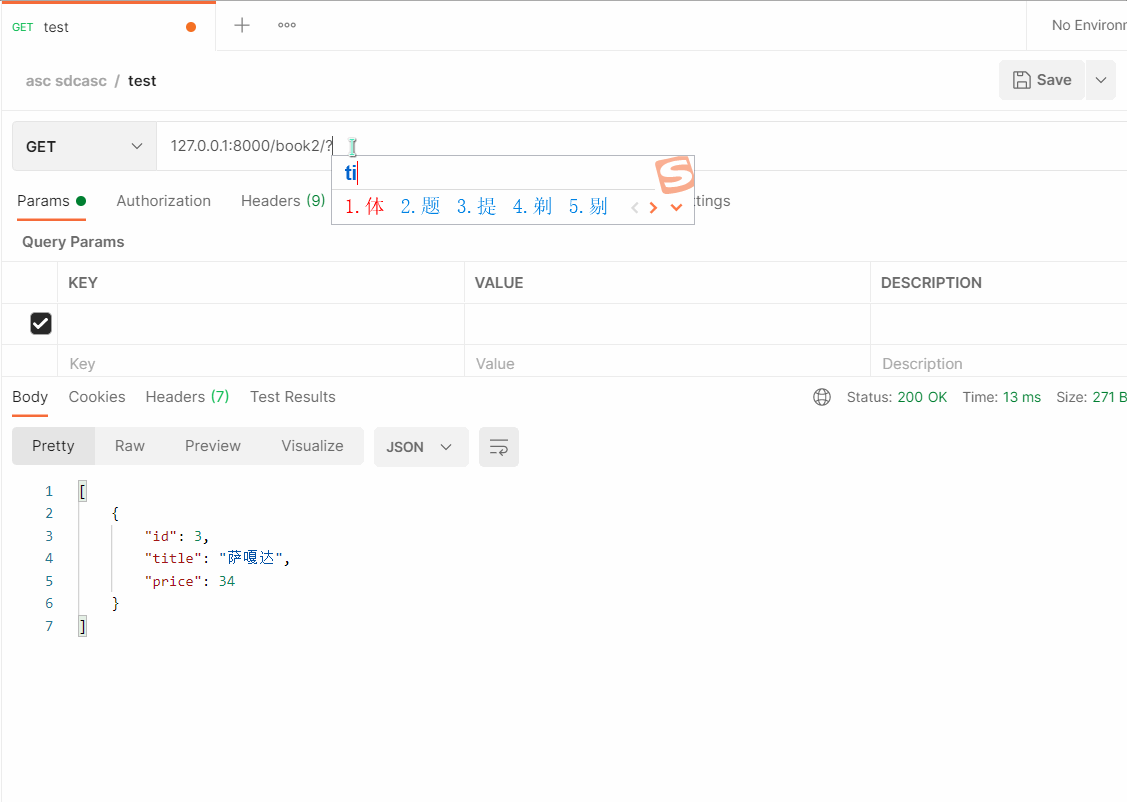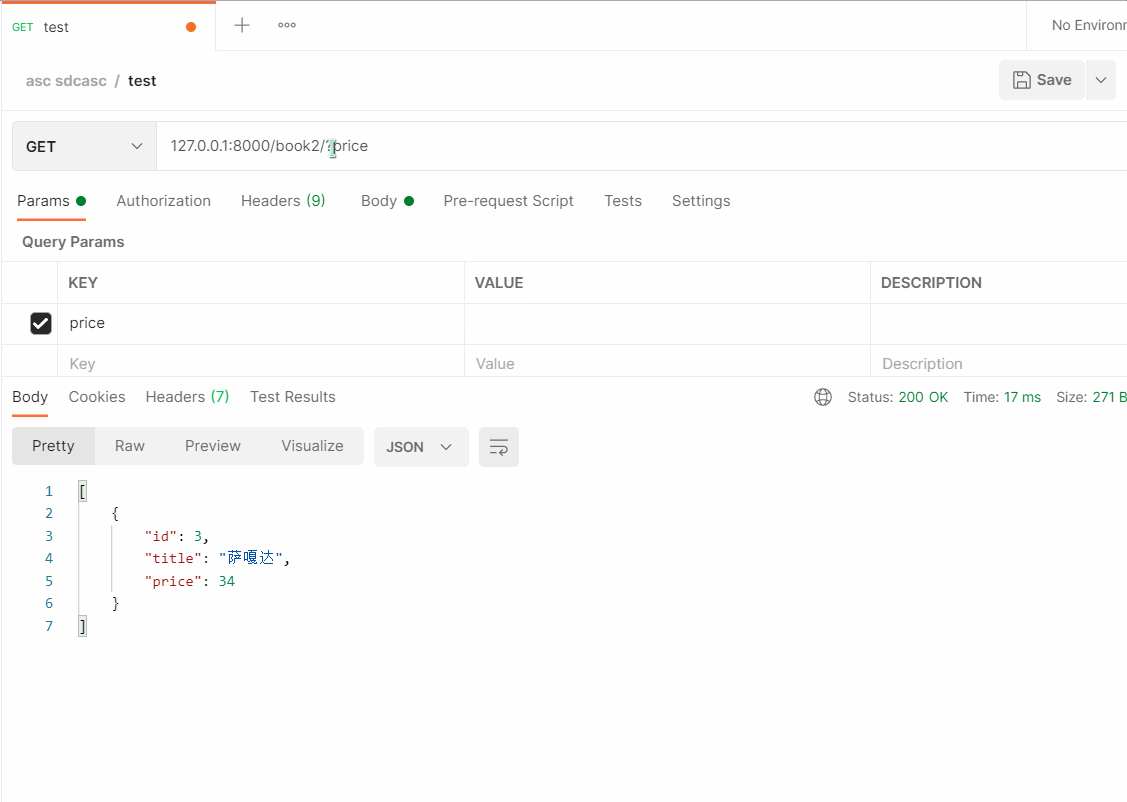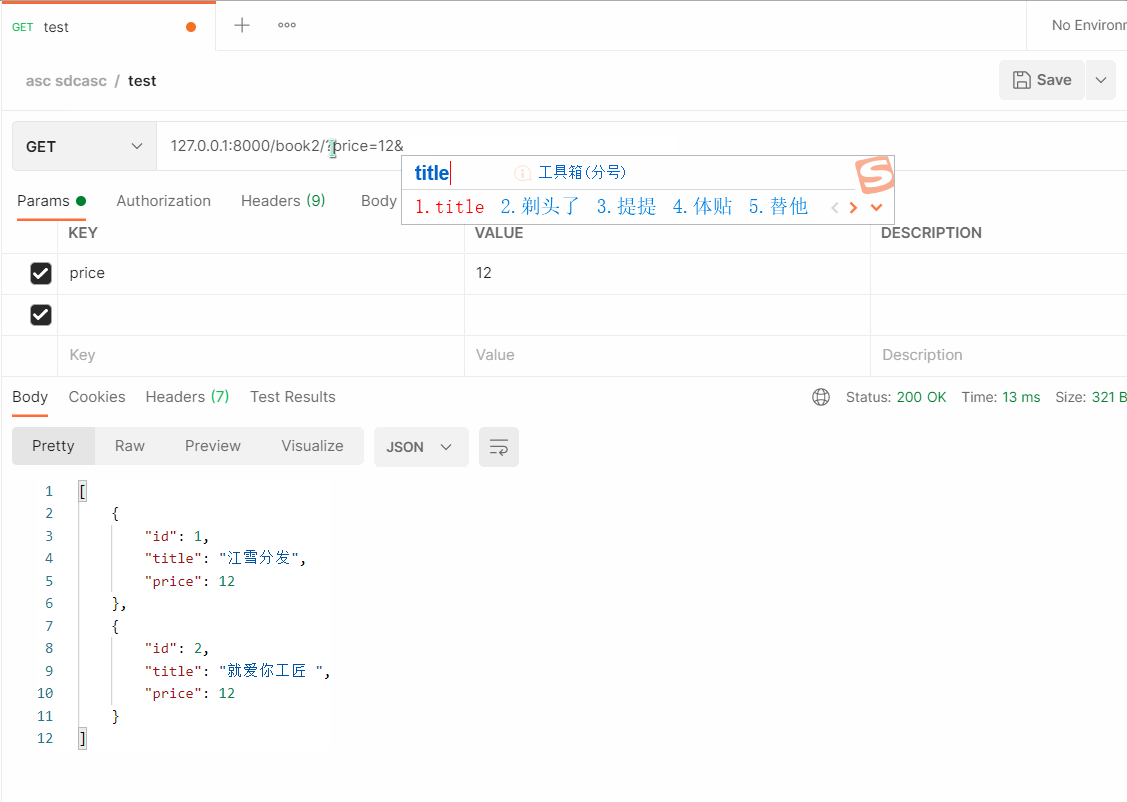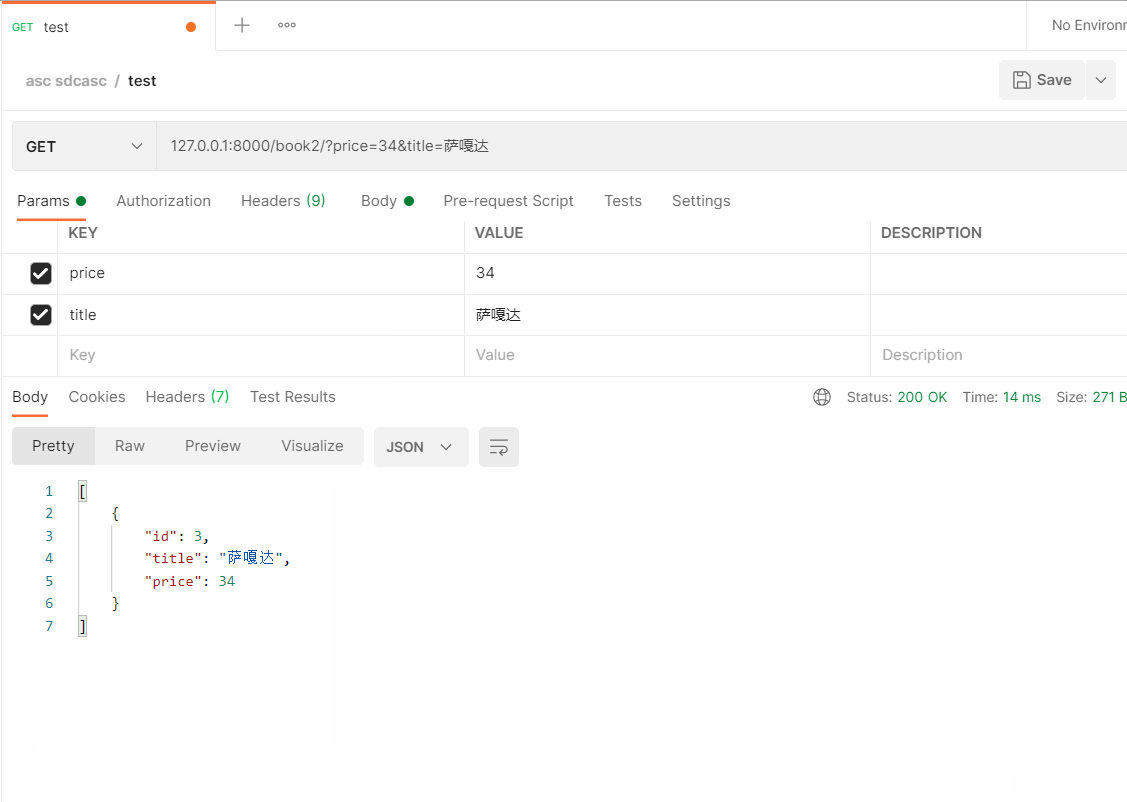
- 总结
# 可以指定字段名进行查询 (还有一些其他强大功能,如:通过时间过滤,(后边介绍))
# 不支持模糊查询
# 针对django内置搜索组件的拓展, 在django内置的基础之上还拓展了外键字段的过滤功能
3.自定义过滤类
- 创建一个存放过滤类的文件
- 在文件中书写自定义的过滤器类 : customfilter.py
- 继承
BaseFilterBackend, 必须重写filter_queryset方法
from rest_framework.filters import BaseFilterBackend
from django.db.models import F,Q
# 自定义过滤类(继承BaseFilterBackend)
class MyFilter(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
price = request.GET.get('price')
title = request.GET.get('title')
# 匹配的逻辑代码自己定制
if title and price:
# contains : 包含(模糊匹配)
queryset = queryset.filter(Q(title__contains=title)|Q(price__contains=price))
if title:
queryset = queryset.filter(title__contains=title)
if price:
queryset = queryset.filter(price__contains=price)
return queryset
- views.py
# 导入自定义过滤类
from drf_test.customfilter.customfilter import MyFilter
class BookView2(ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = BookModelSerializer
filter_backends = [MyFilter,]
- Postman 测试
# 127.0.0.1:8000/book2/?title=萨嘎达
# 127.0.0.1:8000/book2/?price=2 (模糊查询)
# 127.0.0.1:8000/book2/?price=2&title=雪 (多个条件模糊查询)
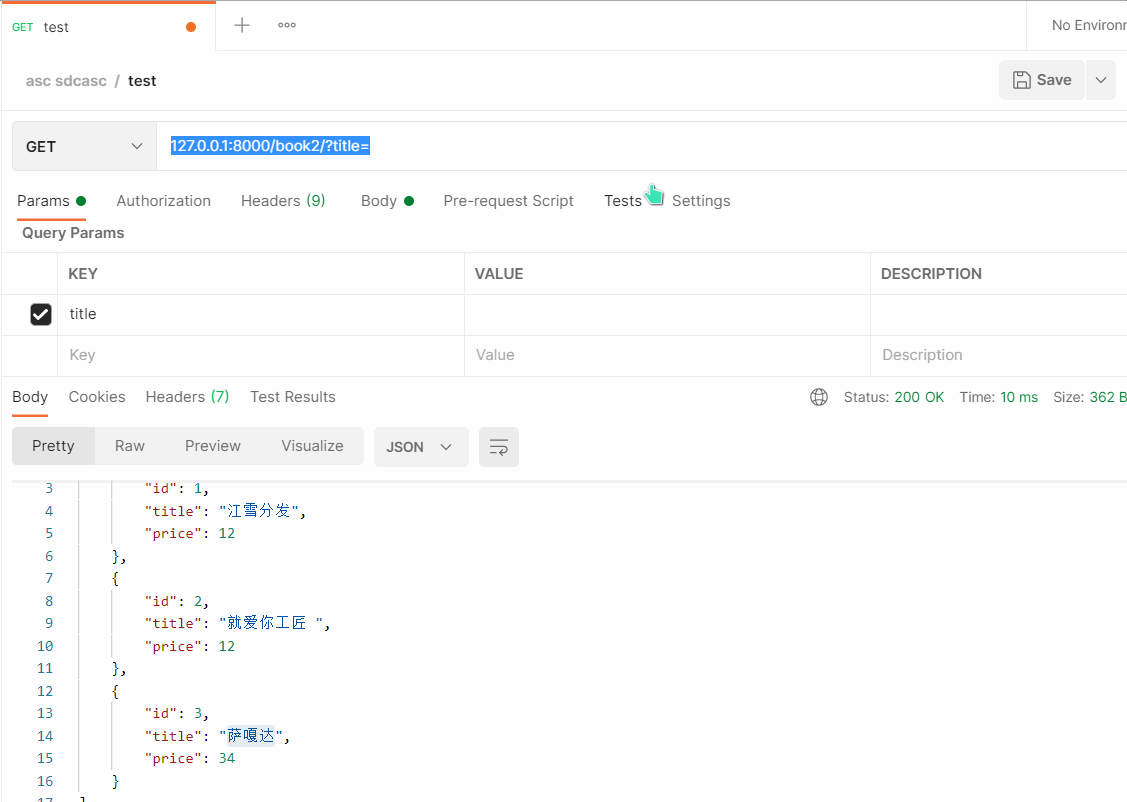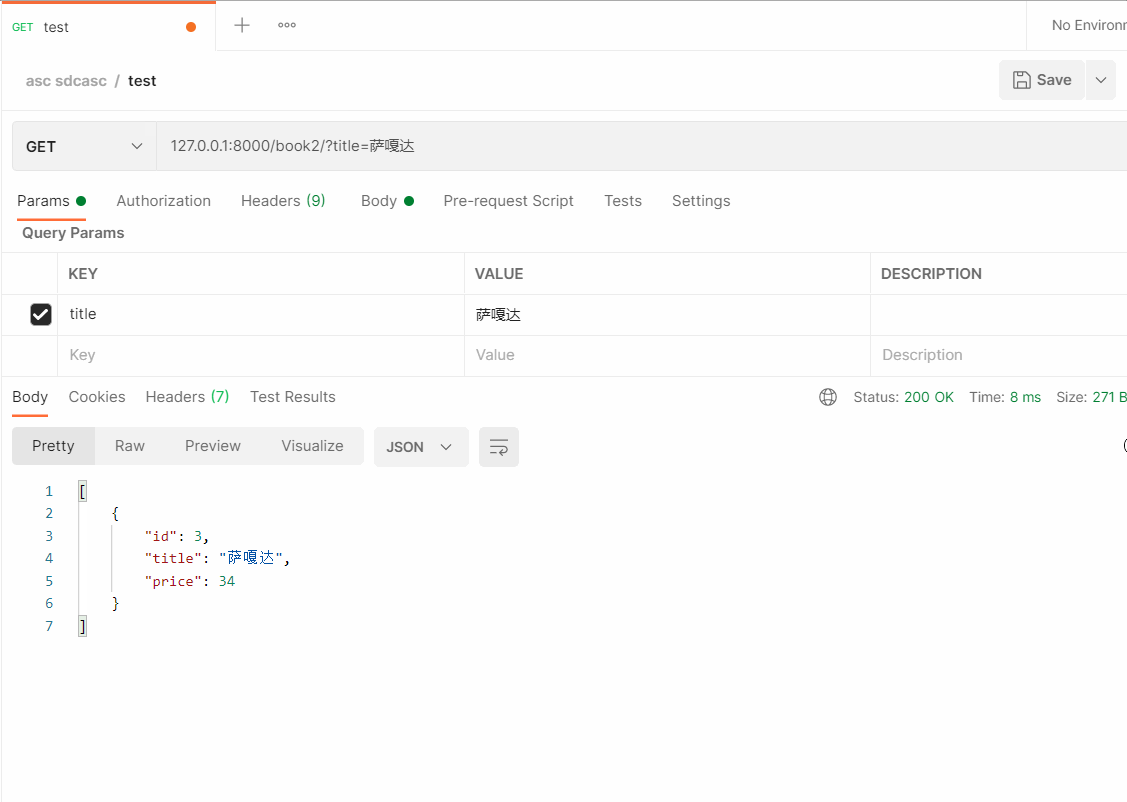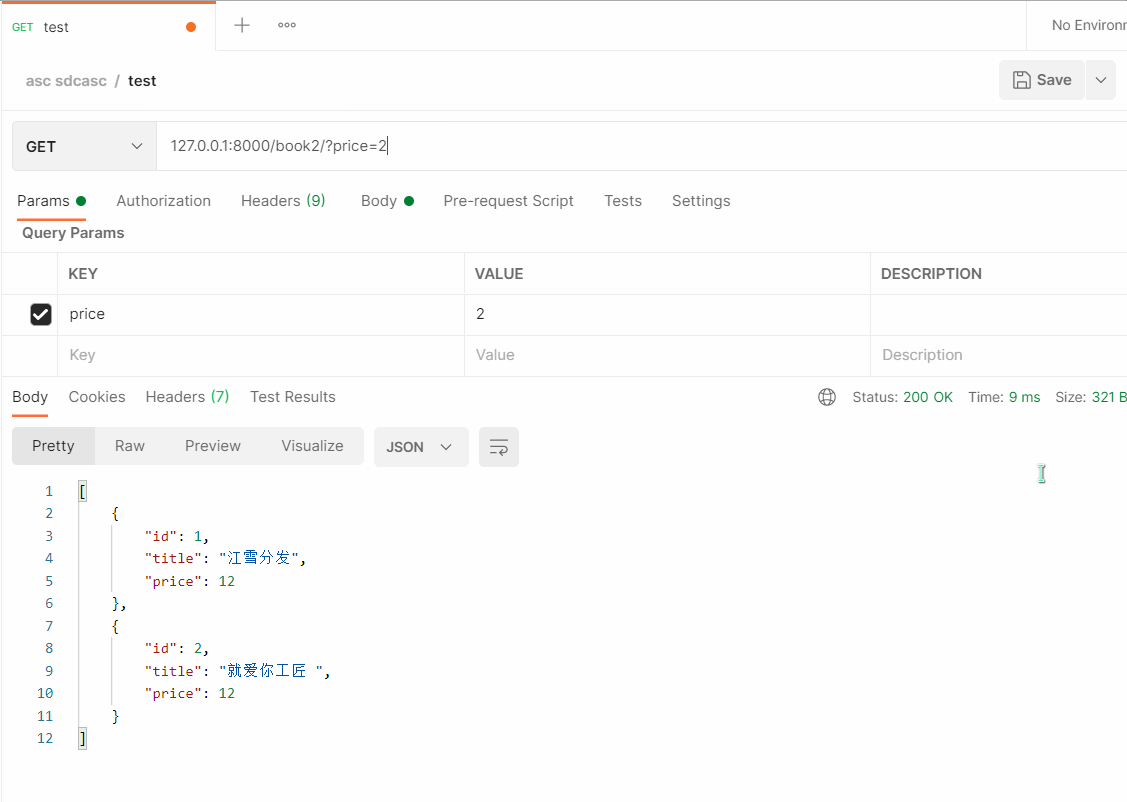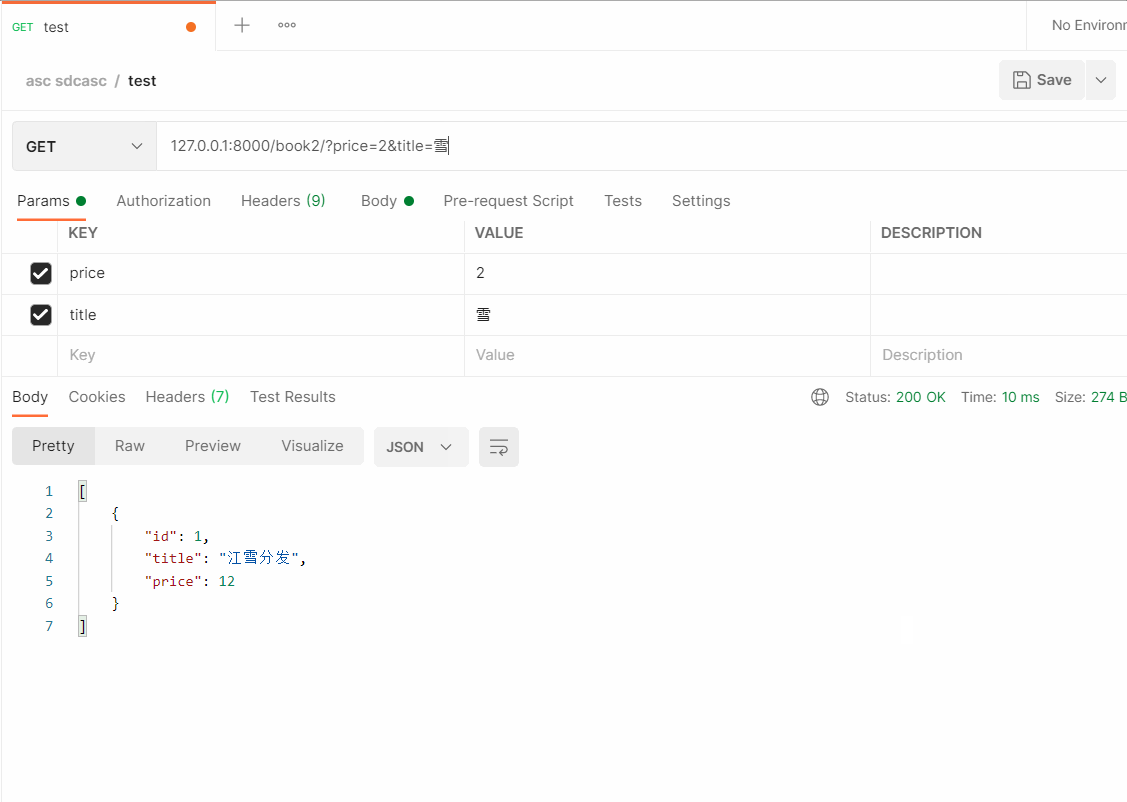
- 总结
# 可以自定义匹配逻辑
# 自定义模糊匹配等等, 扩展性比较强
二.排序组件 Ordering
1.配置
- 全局配置
REST_FRAMEWORK = {
# 过滤
# 'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',),
# 排序(key都是一样的)
# 'DEFAULT_FILTER_BACKENDS': ('rest_framework.filters.OrderingFilter'),
# 过滤和排序放一起
'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend', 'rest_framework.filters.OrderingFilter'),
}
- 局部配置
# 导入排序组件
from rest_framework.filters import OrderingFilter
# 在视图类中使用
filter_backends = [OrderingFilter,]
ordering_fields="__all__"
2.使用
- views.py
from rest_framework.filters import OrderingFilter
class BookView2(ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = BookModelSerializer
filter_backends = [OrderingFilter]
ordering_fields="__all__"
- Postman 测试
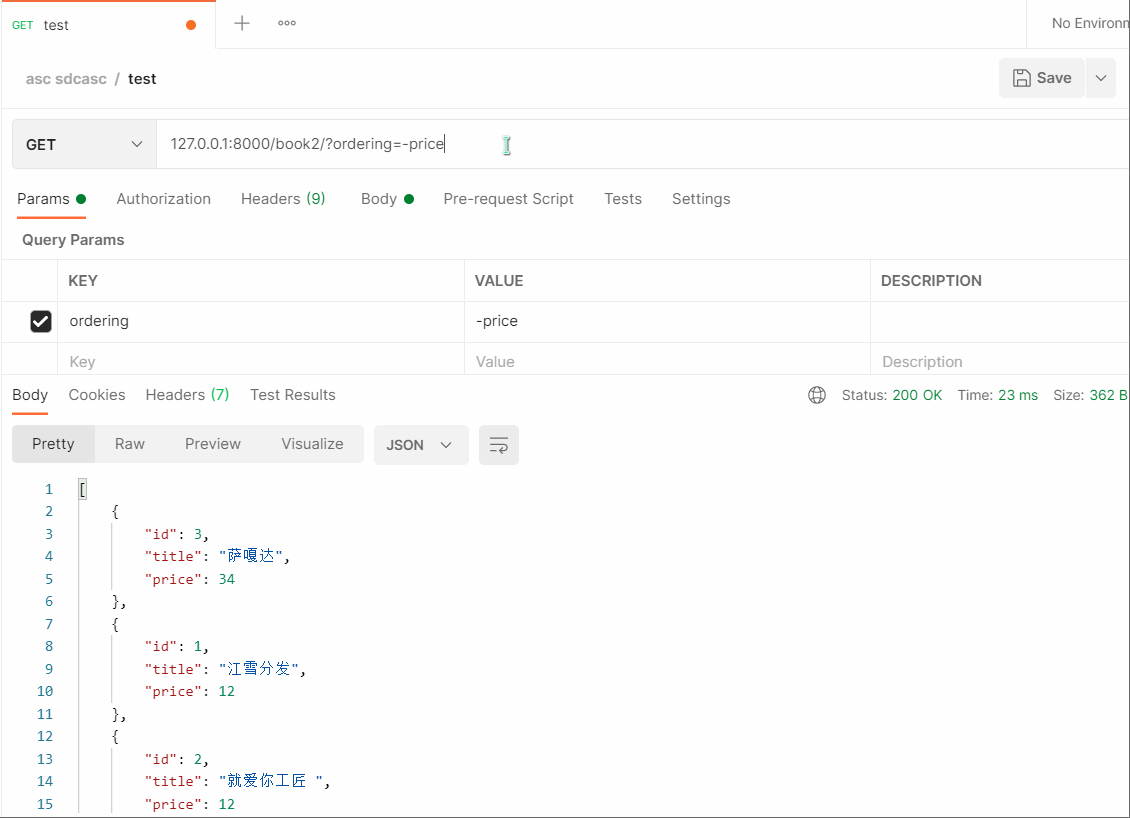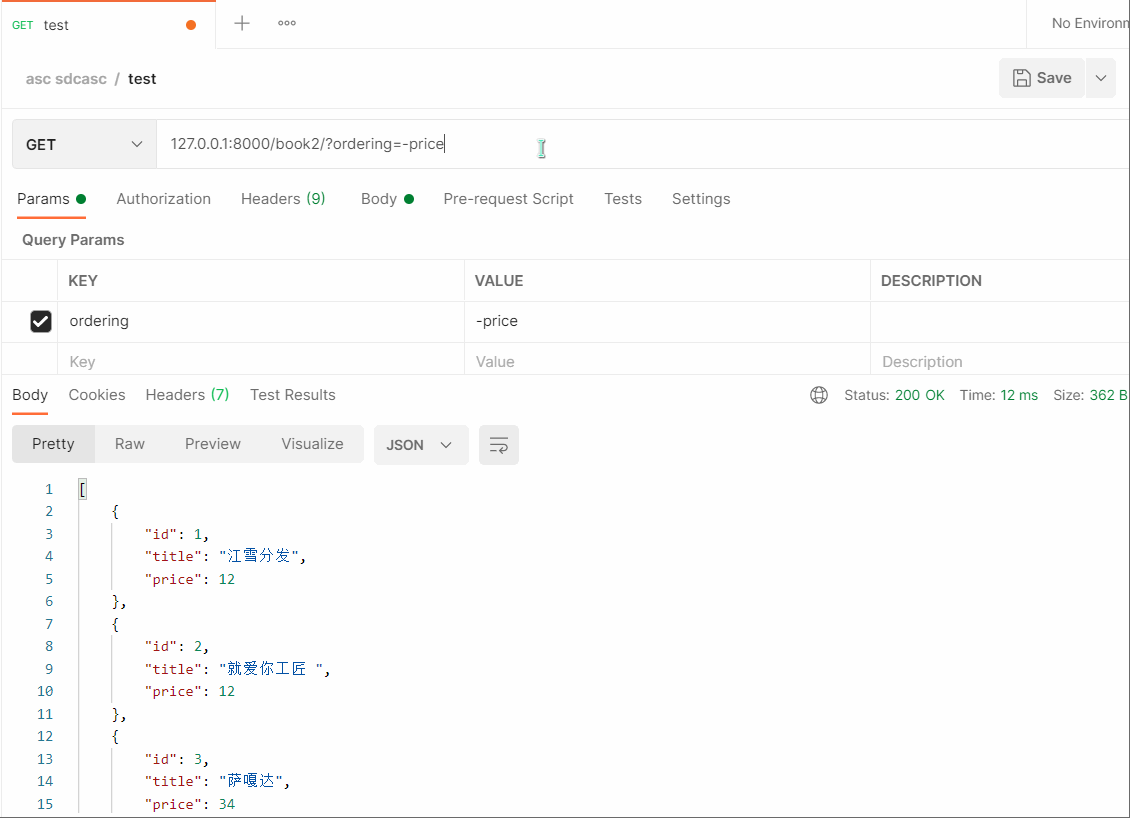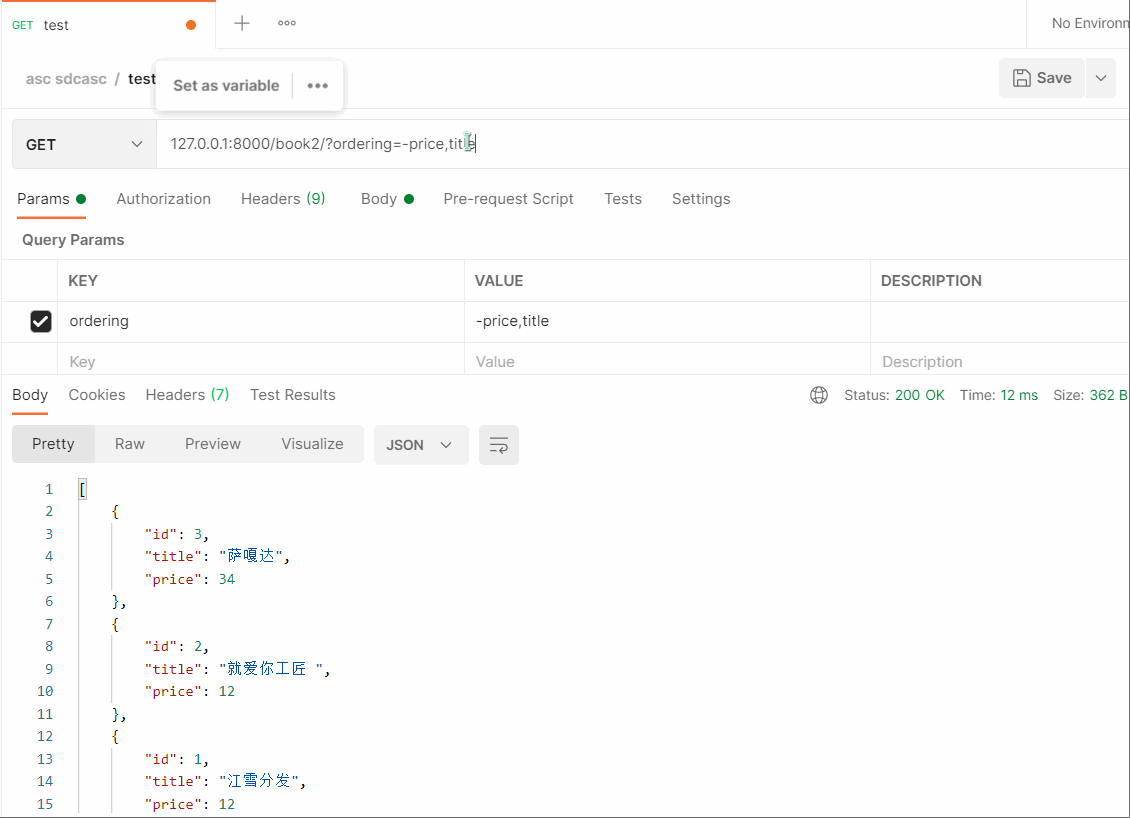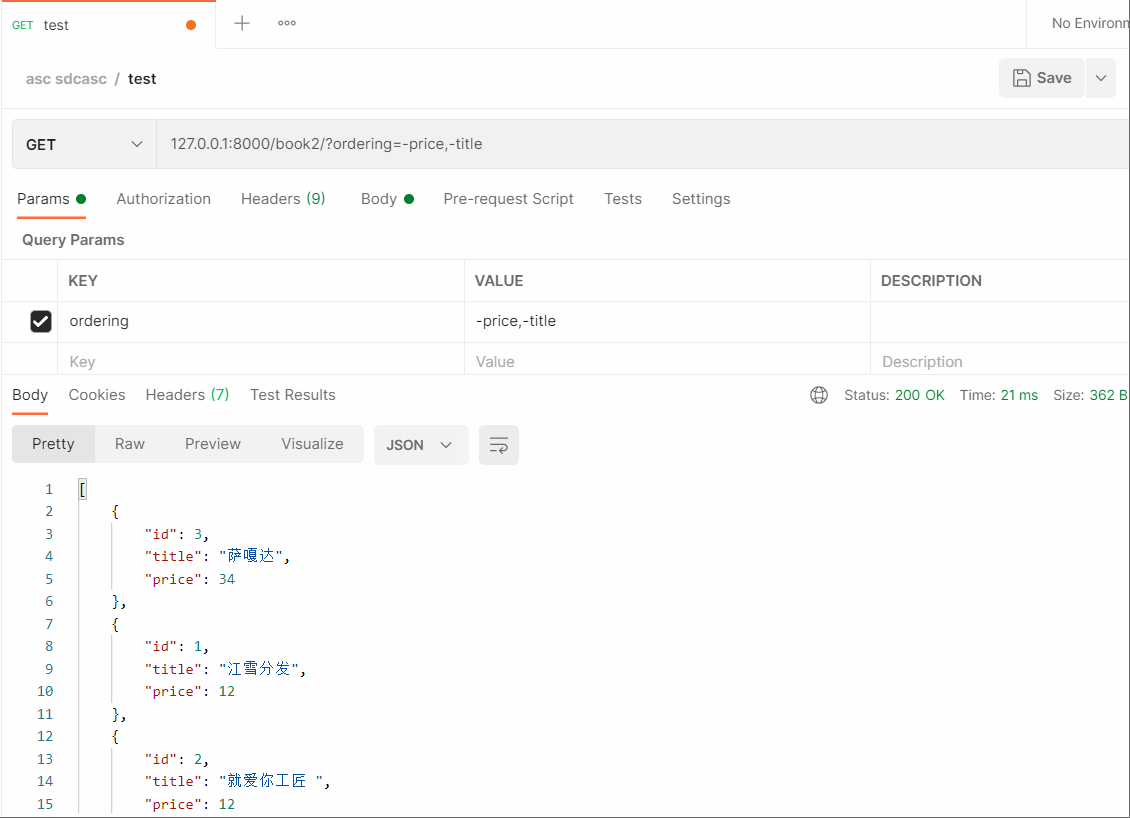
# 127.0.0.1:8000/book2/?ordering=price # 默认升序
# 127.0.0.1:8000/book2/?ordering=-price # - 号,反序
# 127.0.0.1:8000/book2/?ordering=-price,title # 若第一个条件重复可以继续使用第二个天剑进行
# 127.0.0.1:8000/book2/?ordering=-price,-title
3.注意点
- 过滤和排序组件的全局配置使用的都是同一个Key, 任何一个组件局部进行单一的配置都会覆盖全局的配置

三.异常处理 Exception
REST framework 提供了异常处理, 错误有时候被 drf 捕获并处理, 有时候被 Django 捕获处理, 对于他们的处理可能不太符合我们的需求, 那么我们可以自定义异常处理函数
1.异常处理源码分析
- 自定义异常处理之前先进源码看看其异常如何处理的
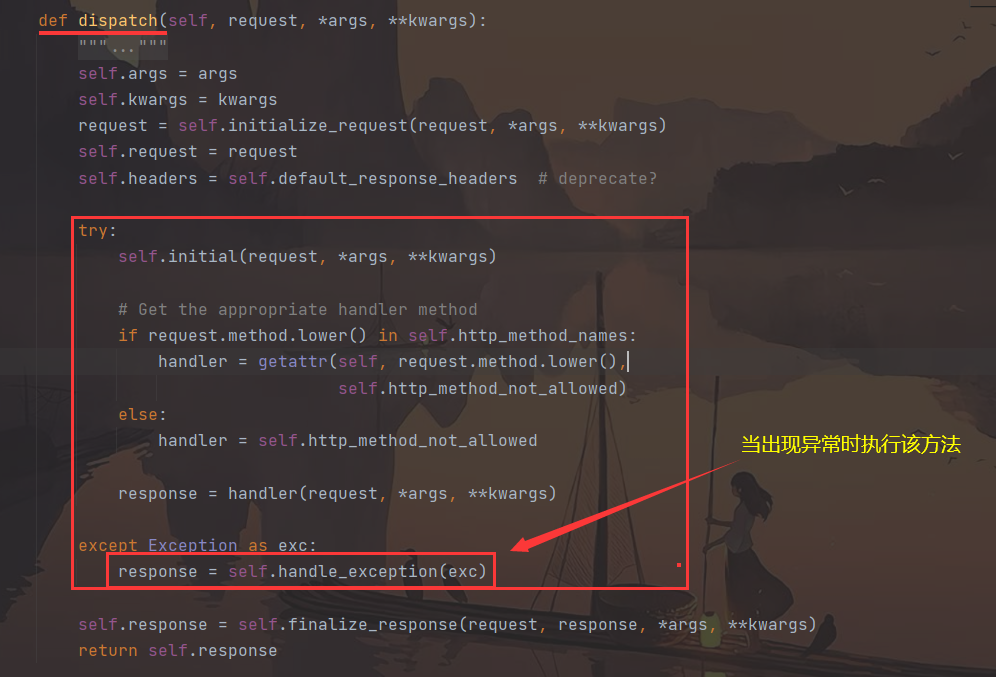
- 步骤 : APIView---->dispatch---->try---->
handle_exception
- 再点击
handle_exception源码进行查看
def handle_exception(self, exc):
"""
Handle any exception that occurs, by returning an appropriate response,
or re-raising the error.
"""
# exc是捕获到的异常,判断该异常是不是后边两种异常的对象,如果是则交给drf处理
if isinstance(exc, (exceptions.NotAuthenticated,
exceptions.AuthenticationFailed)):
# WWW-Authenticate header for 401 responses, else coerce to 403
auth_header = self.get_authenticate_header(self.request)
if auth_header:
exc.auth_header = auth_header
else:
exc.status_code = status.HTTP_403_FORBIDDEN
# 该方法返回 self.settings.EXCEPTION_HANDLER(下面有图)
# 默认指向 rest_framework.views.exception_handler(下面有图)
# 得到异常处理函数 exception_handler (如果自定义了,找到自定义的,没有则找默认的)
exception_handler = self.get_exception_handler()
# 该方法返回的是异常内容(字典), 赋值给context(下面有图)
context = self.get_exception_handler_context()
# 执行异常函数,处理异常(重点)
response = exception_handler(exc, context)
# 如果response是空,说明没有捕获到异常
if response is None:
self.raise_uncaught_exception(exc)
response.exception = True
return response
get_exception_handler( ) 方法获取异常对象
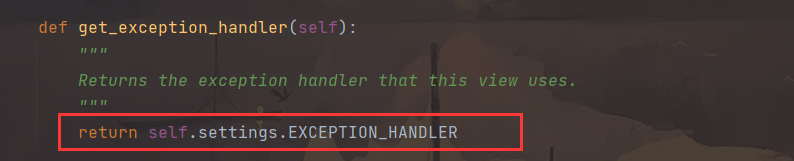
drf 的 settings.py 配置文件中 EXCEPTION_HANDLER 的指向

get_exception_handler_context( ) 方法获取异常内容
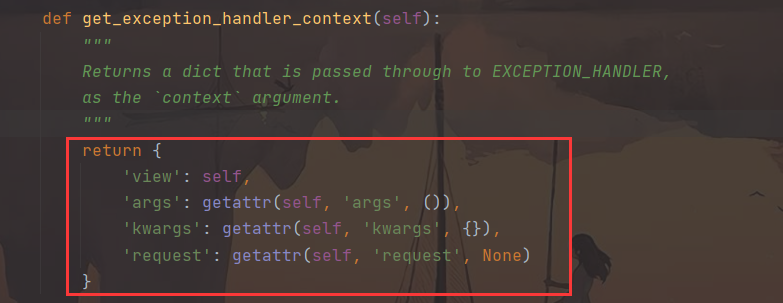
- 我们再查看
exception_handler默认异常函数如何处理异常的
def exception_handler(exc, context):
"""
Returns the response that should be used for any given exception.
By default we handle the REST framework `APIException`, and also
Django's built-in `Http404` and `PermissionDenied` exceptions.
Any unhandled exceptions may return `None`, which will cause a 500 error
to be raised.
"""
# 上面的注释大致 : 会处理REST框架的APIException异常
# Django内置的Http404和PermissionDenied异常
# 任何未处理的异常都可能返回None,这会引发500错误(我们可以处理该异常!)
# Http404异常处理
if isinstance(exc, Http404):
exc = exceptions.NotFound()
# PermissionDenied异常处理
elif isinstance(exc, PermissionDenied):
exc = exceptions.PermissionDenied()
# APIException异常处理
if isinstance(exc, exceptions.APIException):
headers = {}
if getattr(exc, 'auth_header', None):
headers['WWW-Authenticate'] = exc.auth_header
if getattr(exc, 'wait', None):
headers['Retry-After'] = '%d' % exc.wait
if isinstance(exc.detail, (list, dict)):
data = exc.detail
else:
data = {'detail': exc.detail}
set_rollback()
return Response(data, status=exc.status_code, headers=headers)
# drf未捕获到能处理的异常返回 None
return None
经过上面的分析, 我们知道 : 对捕获到的异常, 都会被
exception_handler(exc, context)函数处理, 我们只需要重写该函数, 就可以让其运行我们写的函数来进行异常的处理
2.自定义异常处理
通过翻译exception_handler的注释我们知道的是对于 drf 处理不了的异常会返回 None, 引发500错误, 我们的思路路就是 drf 能处理的异常还是交给它处理, 它不能处理的异常我们再来处理
- 重写
exception_handler(exc, context)函数 (新建一个异常处理的文件 : customecception.py)
from rest_framework.response import Response
from rest_framework.views import exception_handler
def custom_exception_handler(exc, context):
# 先交给 drf 默认的异常处理, 处理不了了(返回None)再我们处理
response = exception_handler(exc, context)
print(response) # None
print(exc) # division by zero(异常)
print(context.get('view')) # <drf_test.views.TestView object at 0x000002482D0C0FC8>
print(context.get('request').get_full_path()) # /test/(异常路径)
# 如果是None, 我们就更细粒度的对异常进行处理并进行记录日志
if not response:
# 超出索引异常
if isinstance(exc, IndexError):
response = Response({'status': 5001, 'msg': '越界异常'})
# 除数为零异常 (4/0)
elif isinstance(exc, ZeroDivisionError):
response = Response({'status': 5002, 'msg': '除数零异常'})
elif isinstance(exc, TypeError):
response = Response({'status': 5002, 'msg': '类型异常'})
elif isinstance(exc, AttributeError):
response = Response({'status': 5002, 'msg': '属性异常'})
else:
response = Response({'status': 5000, 'msg': '没有权限'})
# 记录日志操作(省略...)
return response
- 在 setting.py 文件中的 drf 配置指定自己的异常类
REST_FRAMEWORK = {
# 自定义异常处理
'EXCEPTION_HANDLER': 'drf_test.exception.customexception.custom_exception_handler'
}
# 如果未配置自定义的,将会使用默认的
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler'
}
- 在 views.py 中写一些错误的逻辑进行测试
class TestView(APIView):
def get(self,request):
x = 4/0
print(x)
return Request()
class TestView2(APIView):
def get(self,request):
li = [1,2,3]
print(li[20])
return Request()
- urls.py
path('test/', views.TestView.as_view()),
path('test2/', views.TestView2.as_view()),
- Postman 测试

3.REST framework定义的异常
- APIException 所有异常的父类
- ParseError 解析错误
- AuthenticationFailed 认证失败
- NotAuthenticated 尚未认证
- PermissionDenied 权限决绝
- NotFound 未找到
- MethodNotAllowed 请求方式不支持
- NotAcceptable 要获取的数据格式不支持
- Th`rottled 超过限流次数
- ValidationError 校验失败
drf 处理不了的其他异常, 就需要我们自定义异常处理
四.分页组件 Pagination
0.分页介绍
DRF 框架提供了三个类来实现分页功能
PageNumberPagination: 可选分页类, 可以选择查询某一页内容
# 子类中可定义的属性 :
- page_size # 每页数目
- page_query_param # 前端发送的页数关键字名,默认为”page”
- page_size_query_param # 前端发送的每页数目关键字名,默认为None
- max_page_size # 前端最多能设置的每页数量
LimitOffsetPagination: 偏移分页类, 可以指定从第几条数据开始查询
# 子类中可定义的属性
- default_limit # 默认限制,默认值与PAGE_SIZE设置一直
- limit_query_param limit # 参数名,默认’limit’
- offset_query_param offset # 参数名,默认’offset’
- max_limit # 最大limit限制,默认None
CursorPagination: 游标分页类(加密分页), 只能上一页下一页, 不能指定, 并且url中的页码是加密的
# 子类中可定义的属性
- cursor_query_param # 默认查询字段
- page_size # 每页数目
- ordering # 按什么排序,需要指定
1.可选分页类的使用 : PageNumberPagination
- 方式一 : 直接使用类实例化来实现
#🔰 views.py 视图类
from rest_framework.response import Response
from rest_framework.pagination import PageNumberPagination
class PageNumberView(APIView):
def get(self, request, *args, **kwargs):
# 拿到所有数据
book_obj = models.Book.objects.all()
# 使用类实例化得到分页器对象
page_obj = PageNumberPagination()
# 设置四个参数
page_obj.page_size = 2 # 默认每页显示的条数
page_obj.max_page_size = 4 # 每页最大显示条数
page_obj.page_query_param = 'page' # 查询页数的关键字(?page=2)
page_obj.page_size_query_param = 'size' # 每页显示查询条数条件关键字(?page=2&size=2)
# 调用分页器对象方法对数据进行分页处理
# 参数: queryset(数据集),request(请求),view(处理分页的视图类)
page = page_obj.paginate_queryset(queryset=book_obj, request=request, view=PageNumberView)
# 将分页后的数据对象进行序列化处理
page_ser = BookModelSerializer(instance=page, many=True)
# get_next_link() : 下一页
# get_previous_link() : 上一页
return return Response({'status': 200, 'msg': '查询成功', 'data': page_ser.data, 'next': page_obj.get_next_link(),'previous': page_obj.get_previous_link()})
# 或者直接使用分页类自带的Response(自带上一页下一页)
# return page_obj.get_paginated_response(page_ser.data)
#🔰 urls.py 路由
path('book1/', views.PageNumberView.as_view()),
- 展示效果
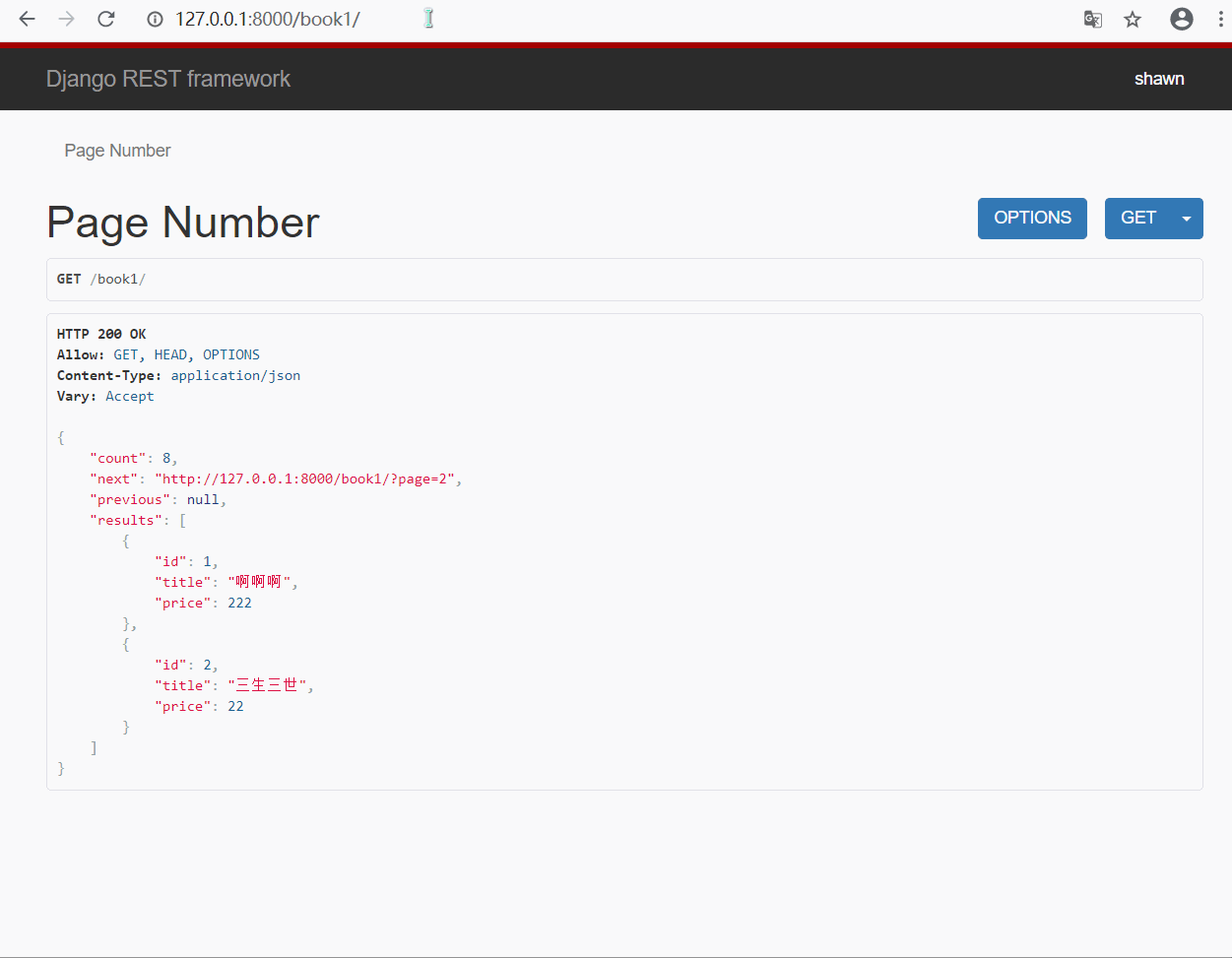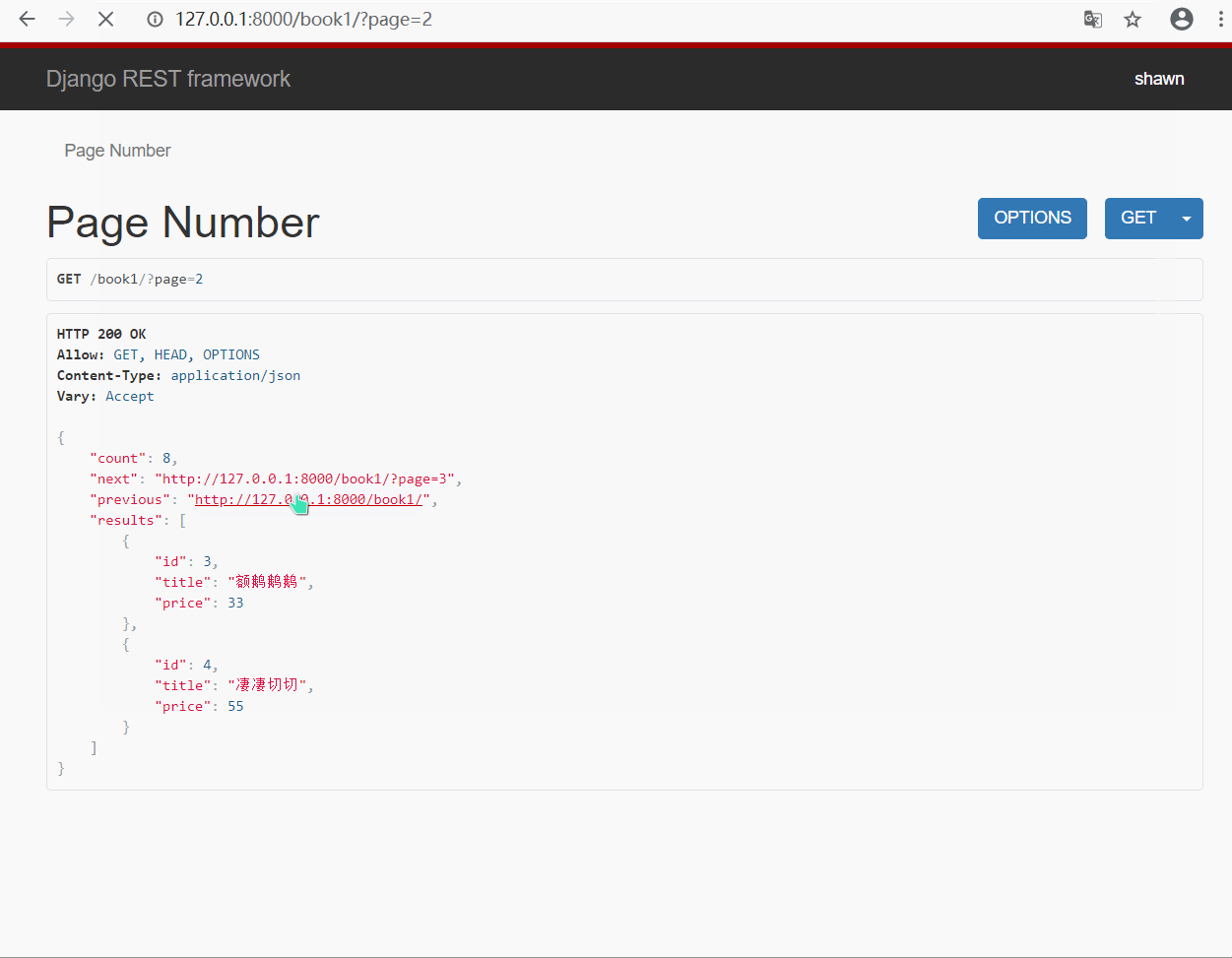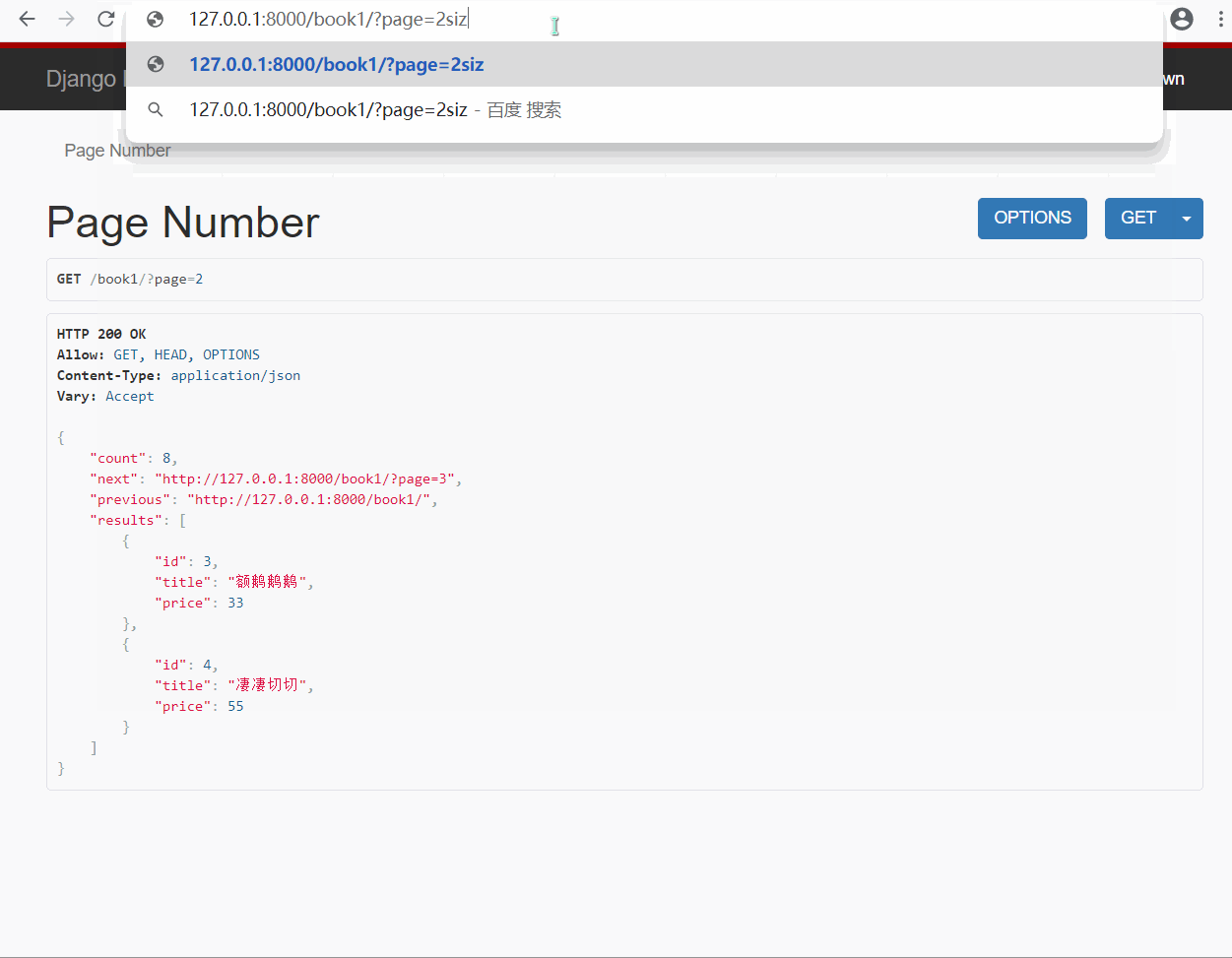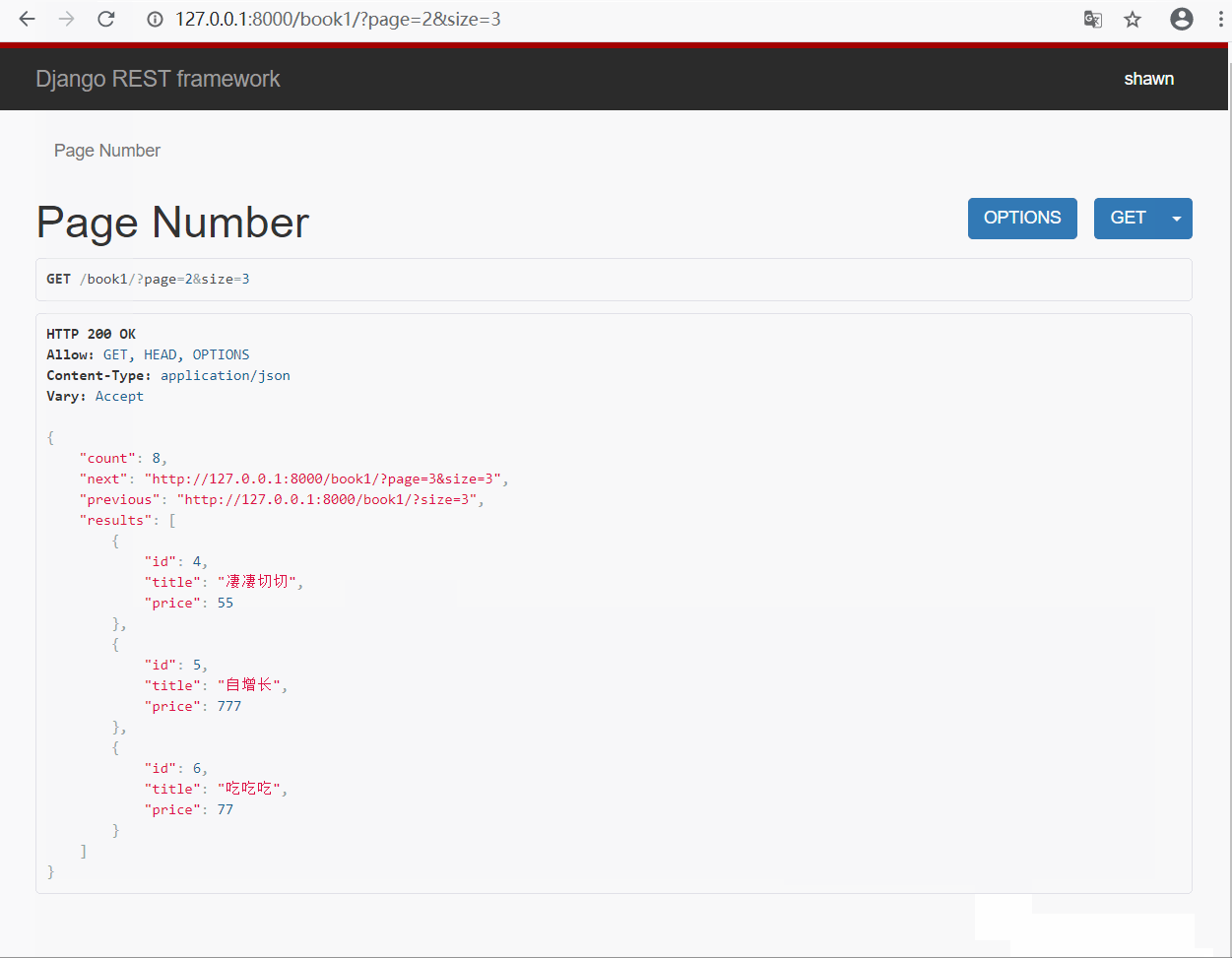
- 默认显示 2 条, 最大显示 4 条, 如果你在 url 中输入的 size 超过最大条数, 则只显示最大条数
- 超过显示的页数, 则显示 "无效页面"
- 方式二 : 自定义普通(页码)分页类
#🔰 custompage.py 新建一个自定义分页类文件
# 写一个类, 继承分页类, 重写类属性
from rest_framework.pagination import PageNumberPagination
class CustomPageNum(PageNumberPagination):
page_size = 3
max_page_size = 4
page_query_param = 'page'
page_size_query_param = 'size'
#🔰 views.py 视图类
# 导入自定义分页类
from drf_test.page.custompage import CustomPageNum
class PageNumberView2(ViewSetMixin,ListAPIView):
queryset = models.Book.objects.all()
serializer_class = BookModelSerializer
# 指定使用的分页类
pagination_class = CustomPageNum
#🔰 urls.py 路由
path('book2/', views.PageNumberView2.as_view(actions={'get':'list'})),
- 展示效果
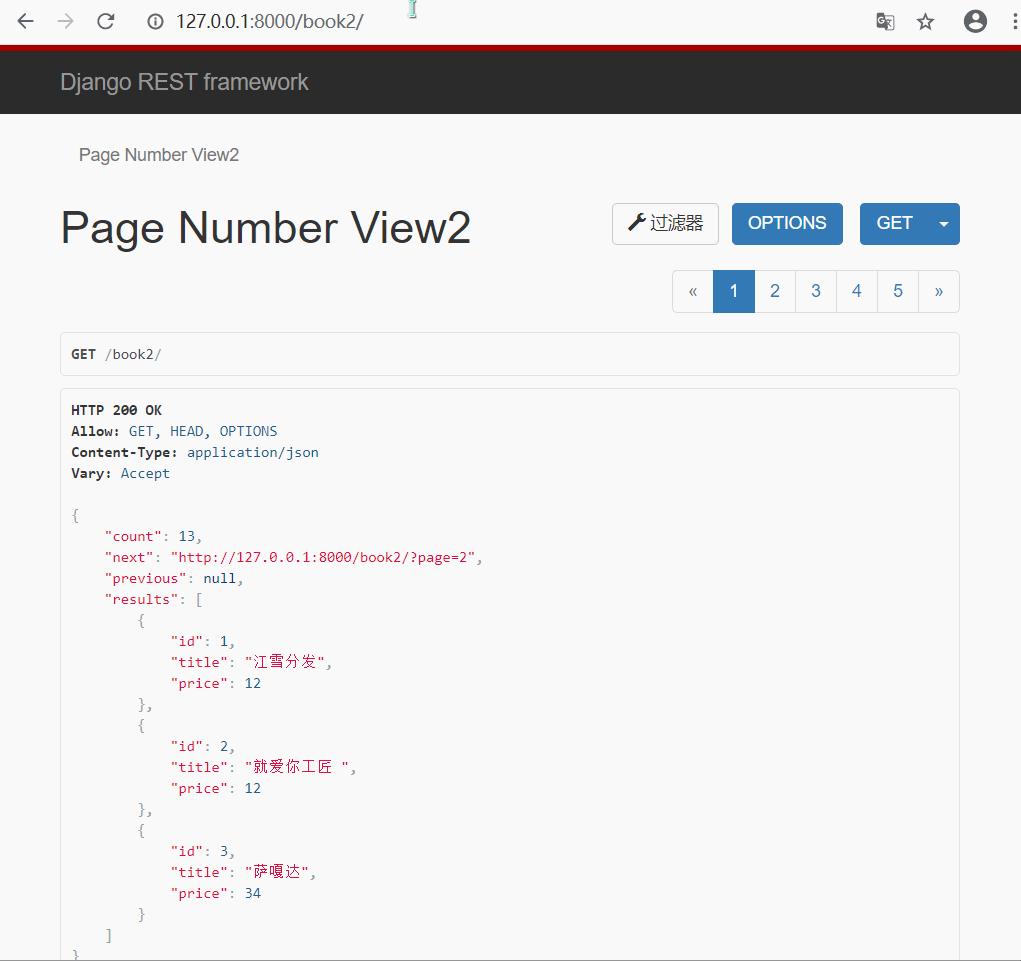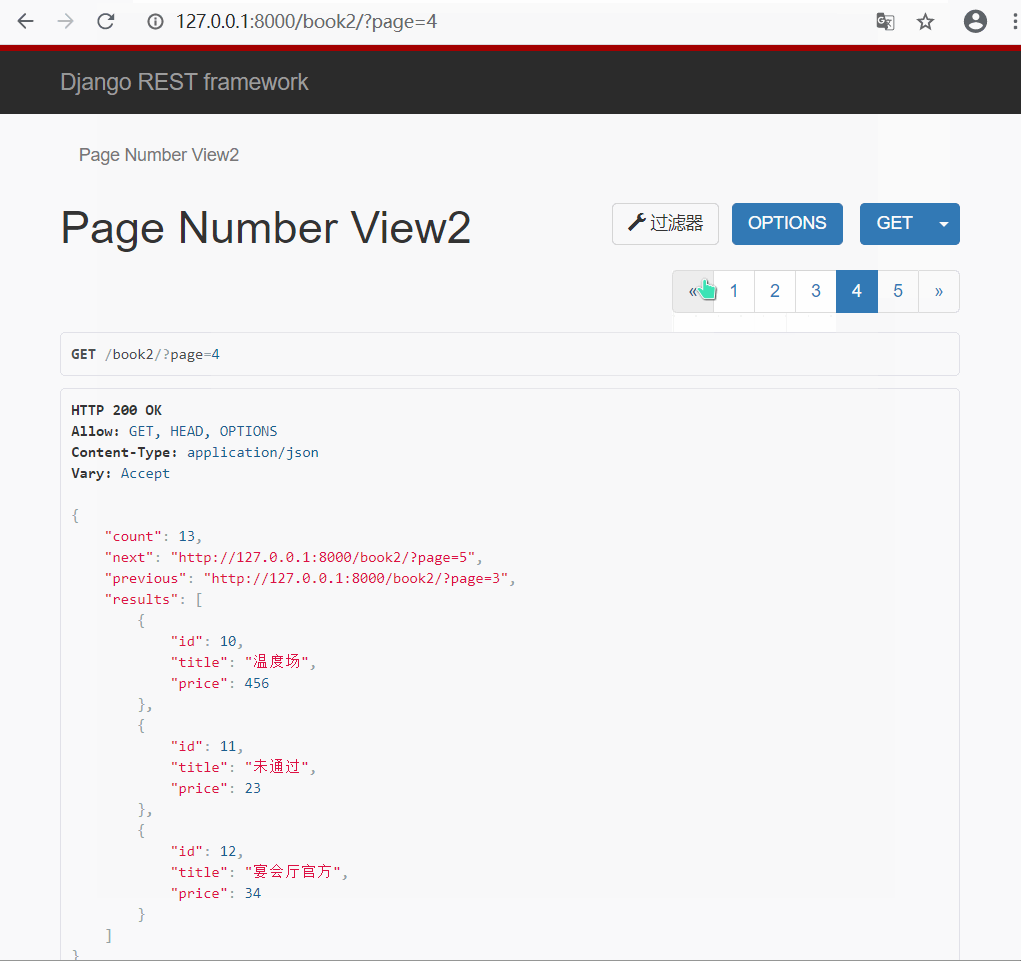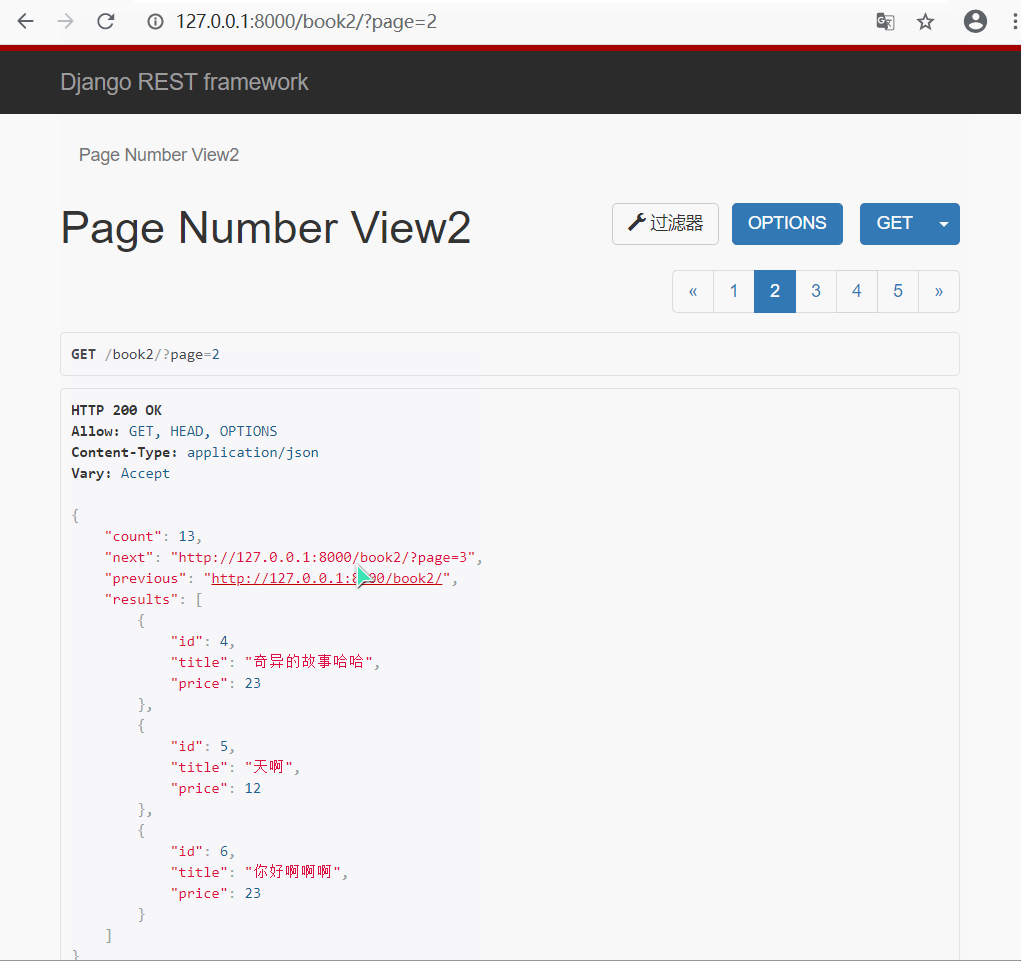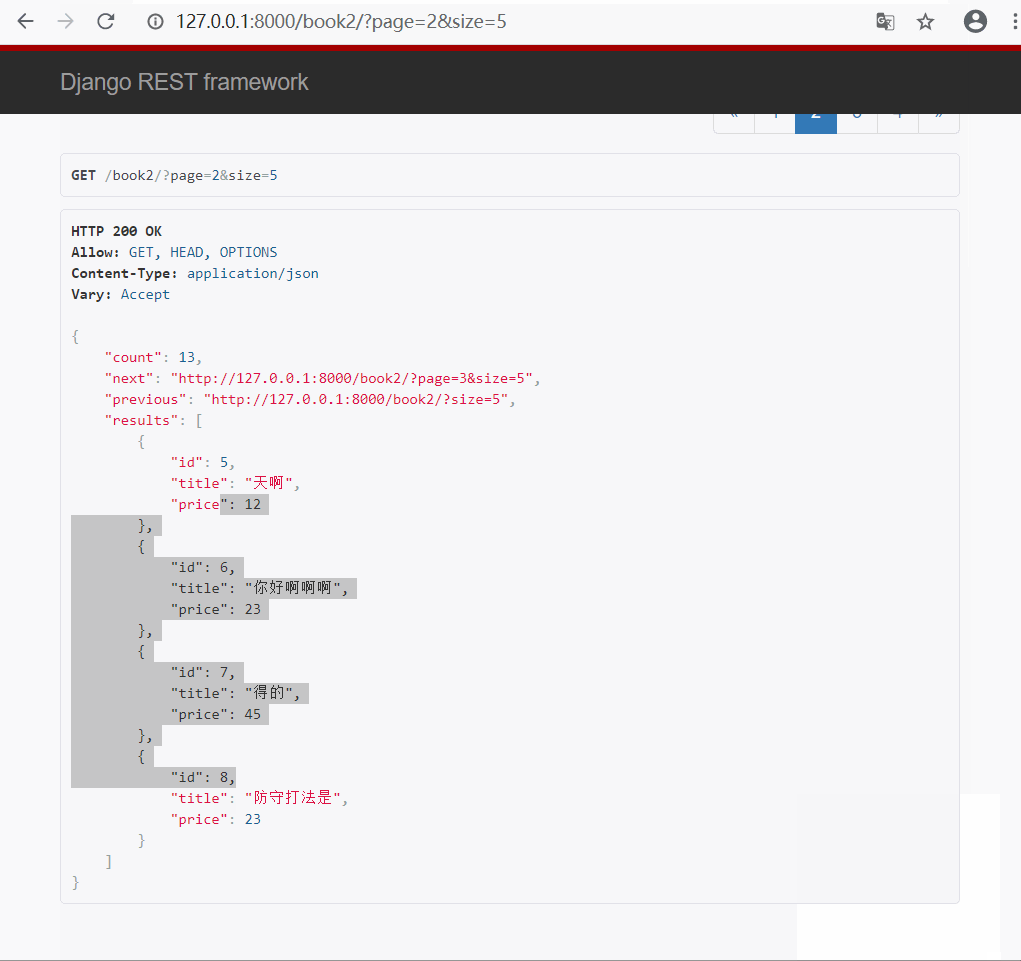
2.偏移分页类的使用 : LimitOffsetPagination
- 方式一 : 直接使用类实例化来实现
#🔰 views.py 视图类
from rest_framework.pagination import LimitOffsetPagination
class LimitOffView(APIView):
def get(self,request,*args,**kwargs):
book_obj = models.Book.objects.all()
# 使用类实例化得到分页器对象
page_obj = LimitOffsetPagination()
# 设置四个参数
page_obj.default_limit = 2 # 默认显示几条
page_obj.max_limit = 5 # 最多显示几条
page_obj.limit_query_param = 'limit' # 关键字指定取几条(?limit=3)
page_obj.offset_query_param = 'offset' # 偏移,从第几个位置后开始取(?offset=5&limit=3)
# 调用分页器对象方法对数据进行分页处理
# 参数: queryset(数据集),request(请求),view(处理分页的视图类)
page = page_obj.paginate_queryset(queryset=book_obj, request=request, view=self)
# 将分页后的内容进行序列化处理
page_ser = BookModelSerializer(instance=page,many=True)
return page_obj.get_paginated_response(page_ser.data)
#🔰 urls.py 路由
path('book3/', views.LimitOffView.as_view()),
- 效果展示
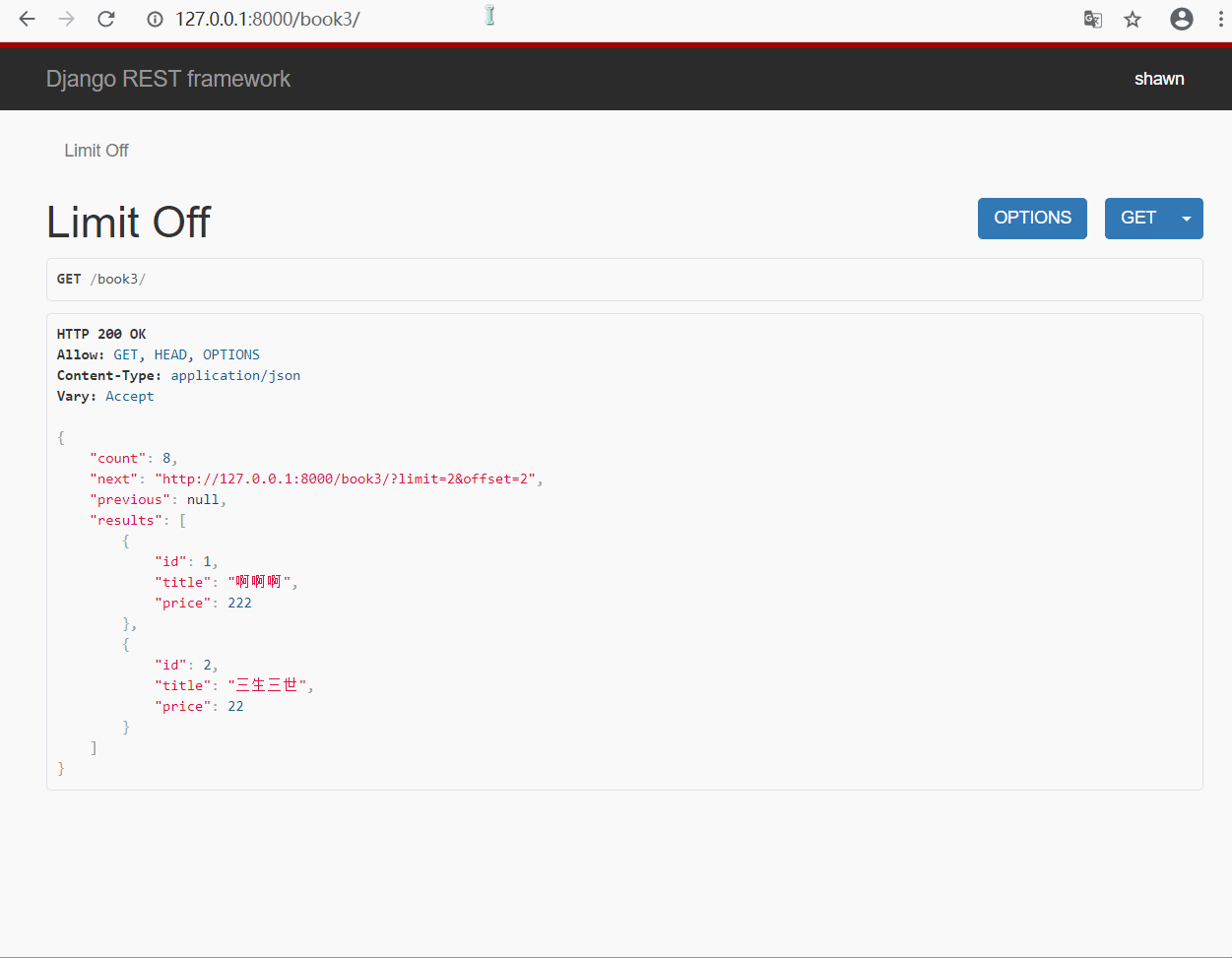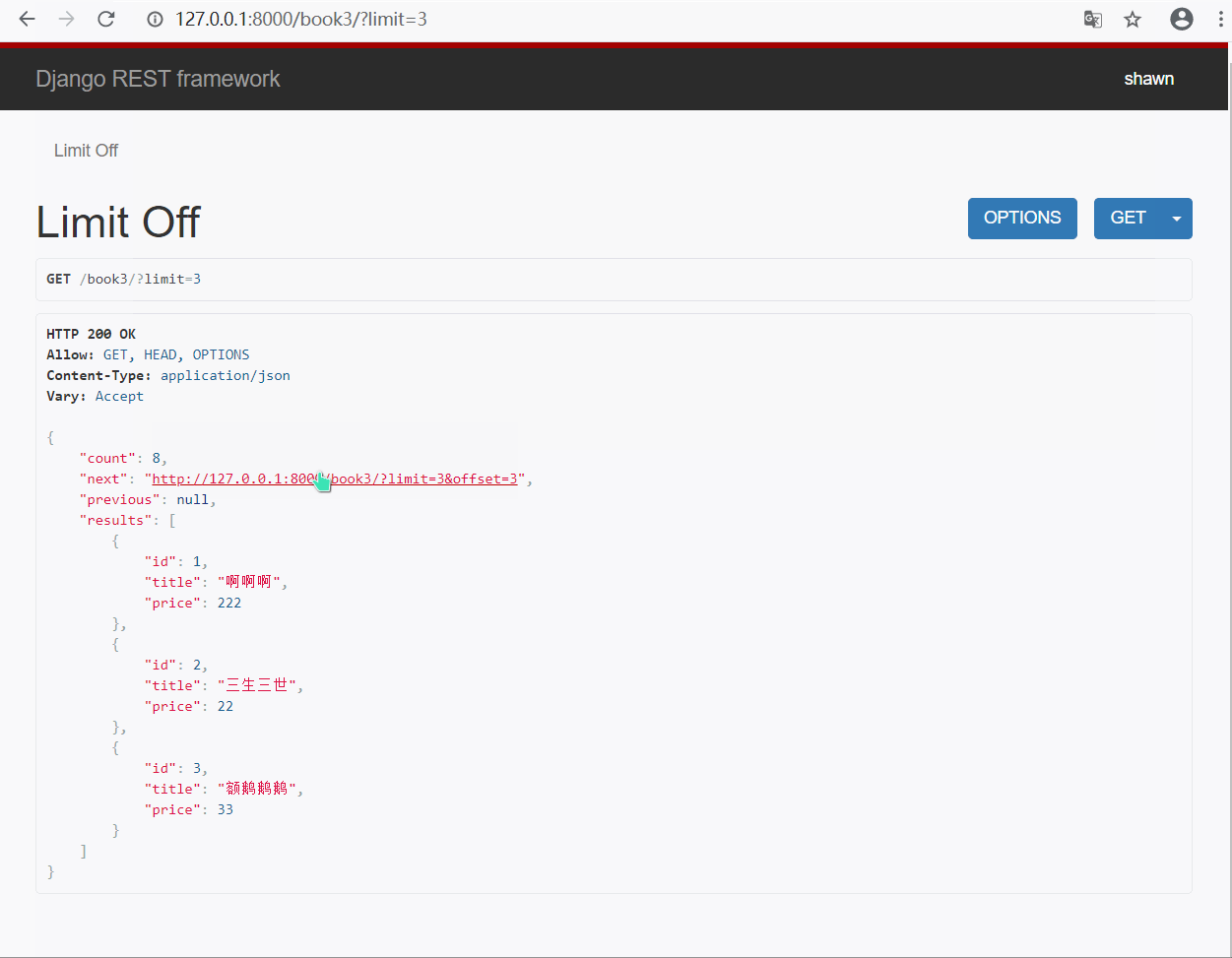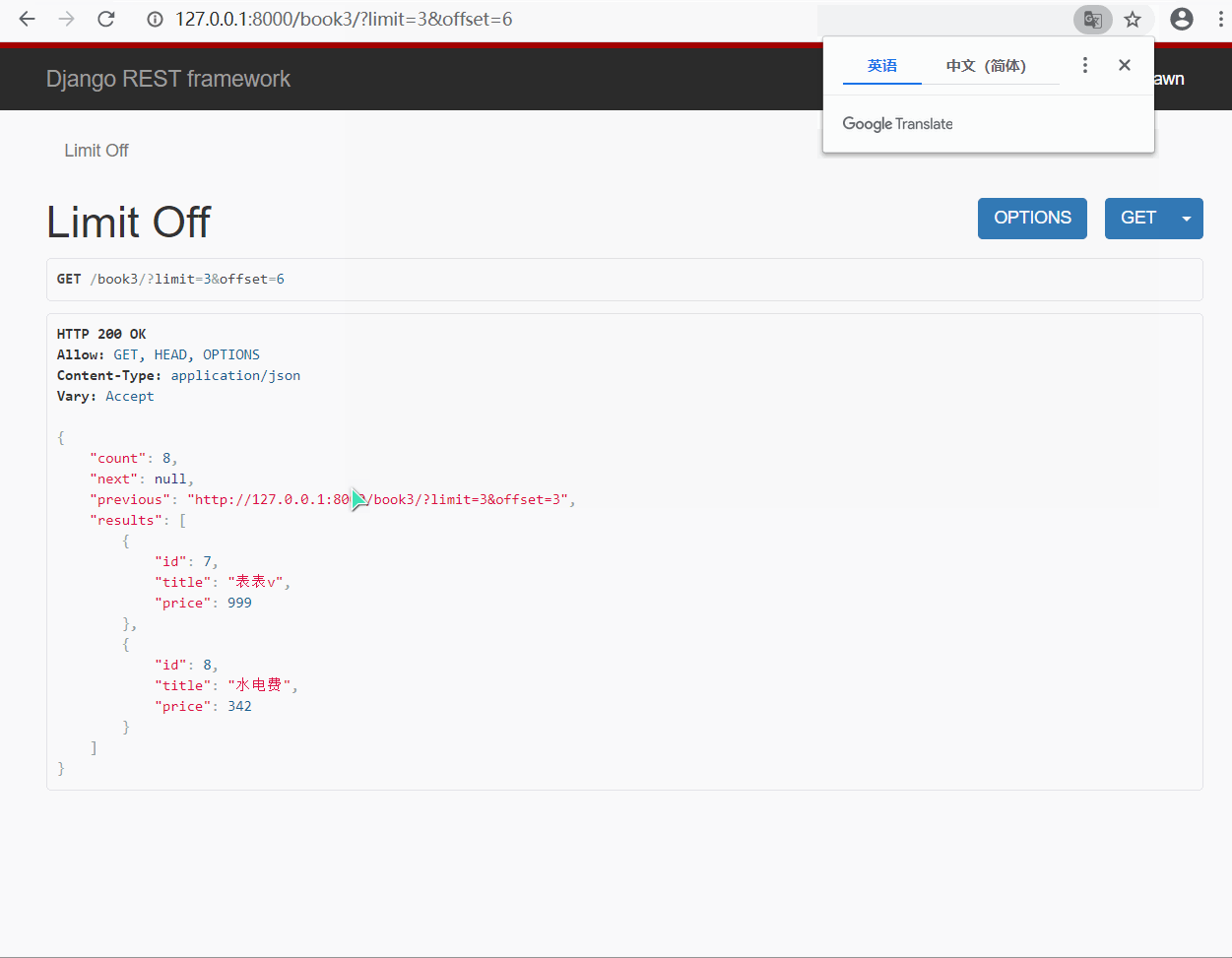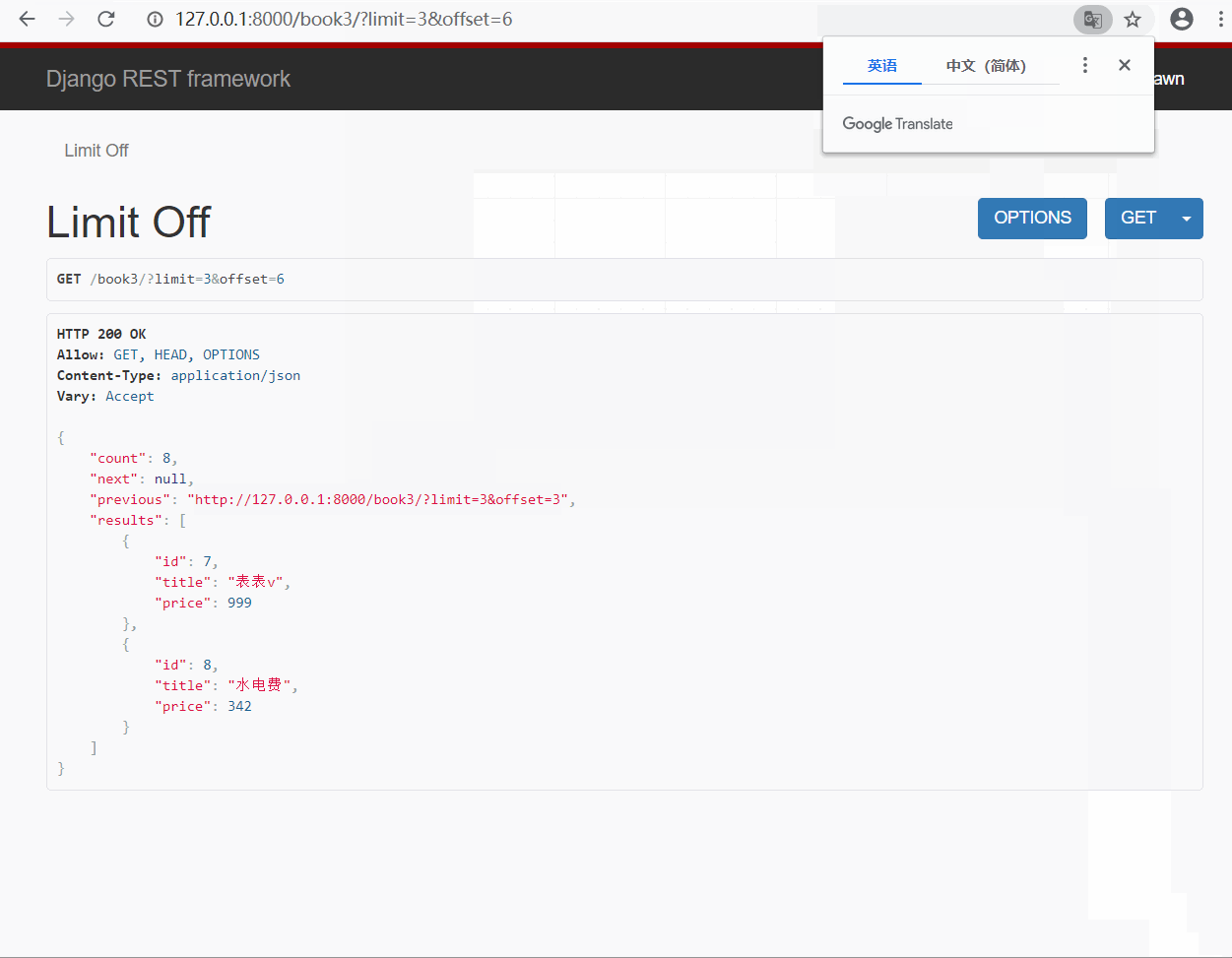
- limit 指定显示几条就显示几条, 超过设置的最大显示条数则只显示最大条数
- offset 指定从哪个位置后开始显示, 比如指定为 2 , 则从第三条开始显示指定的条数
- 方式二 : 自定义偏移分页类
#🔰 custompage.py 自建分页类
# 写一个类, 继承分页类, 重写类属性
from rest_framework.pagination import LimitOffsetPagination
# 继承LimitOffsetPagination重写
class CustomLimitOff(LimitOffsetPagination):
default_limit = 2
max_limit = 5
limit_query_param = 'limit'
offset_query_param = 'offset'
#🔰 views.py 视图类
# 导入自定义的偏移分页类
from drf_test.page.custompage import CustomLimitOff
class LimitOffView2(ViewSetMixin,ListAPIView):
queryset = models.Book.objects.all()
serializer_class = BookModelSerializer
# 指定自定义的偏移分页类
pagination_class = CustomLimitOff
#🔰 urls.py 路由
path('book4/', views.LimitOffView2.as_view(actions={'get':'list'})),
- 效果演示
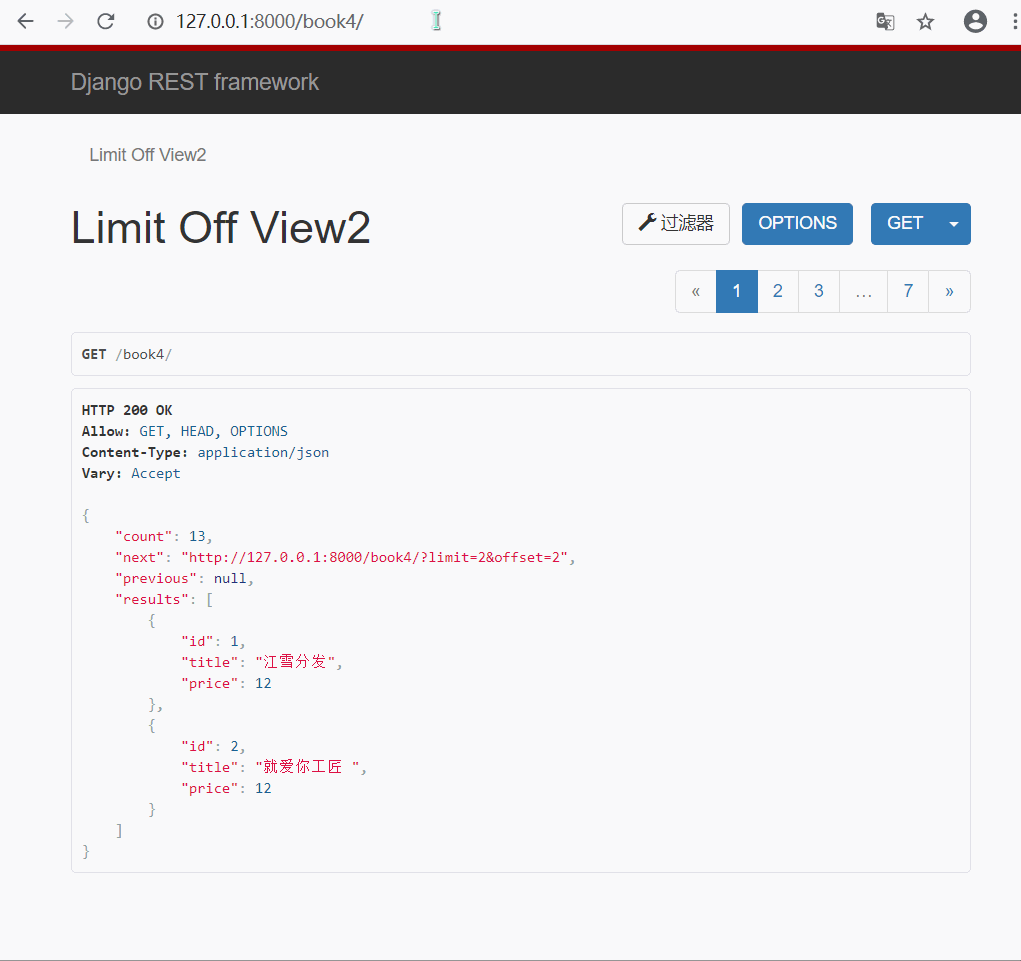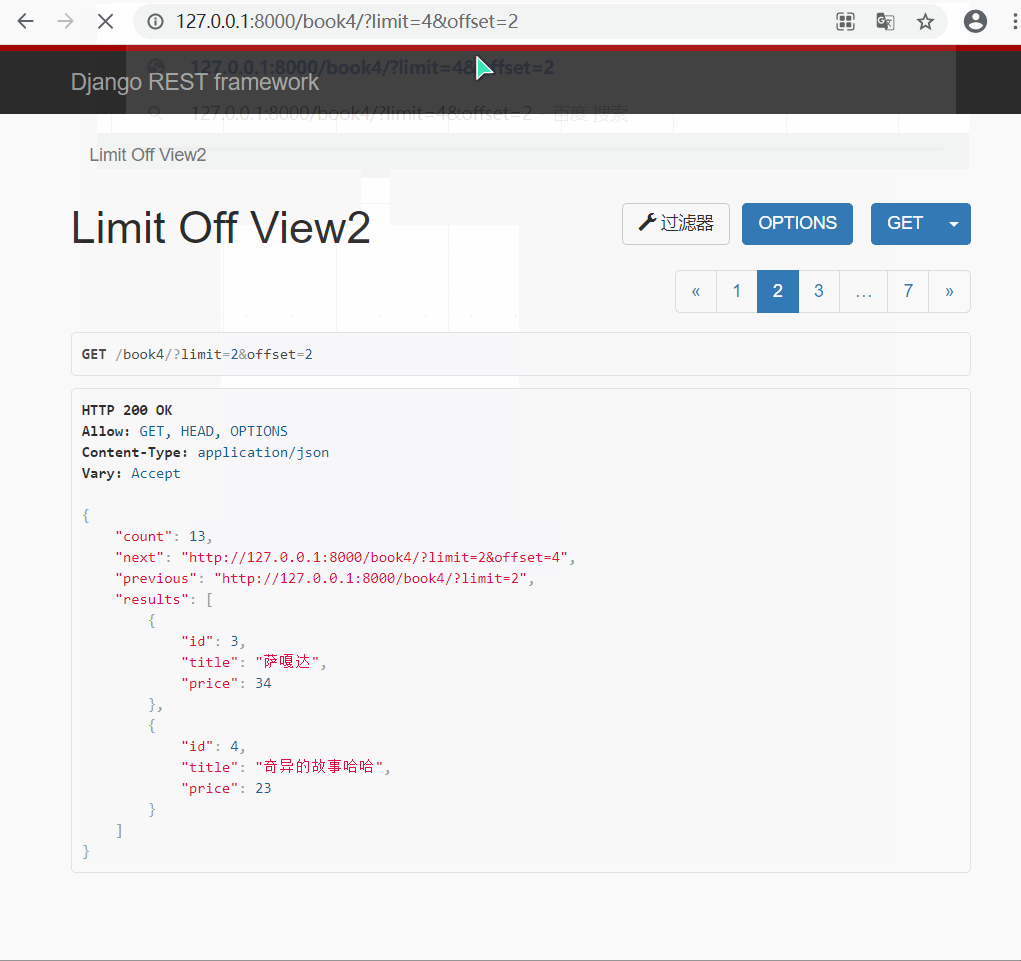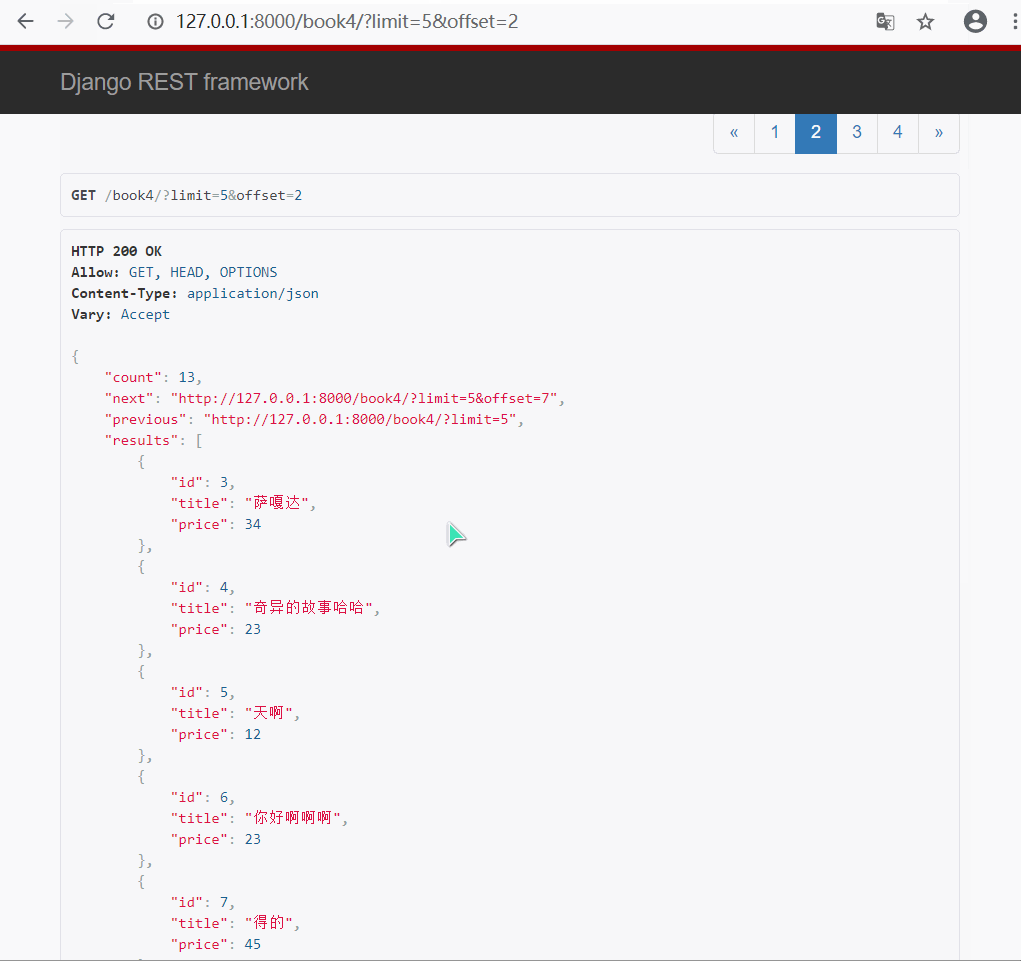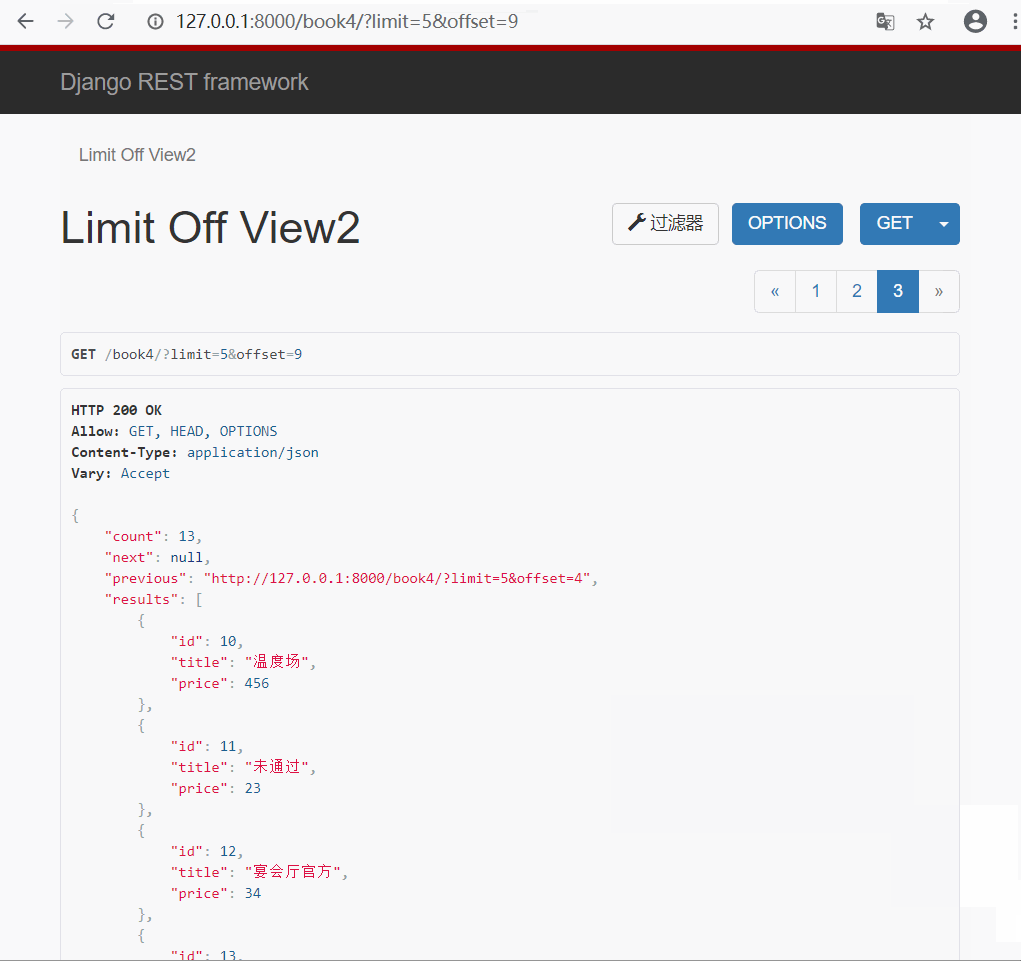
3.游标(加密)分页类的使用 : CursorPagination
- 方式一 : 直接使用类实例化来实现
#🔰 views.py 视图类
from rest_framework.pagination import CursorPagination
class CursorPageView(APIView):
def get(self,request,*args,**kwargs):
book_obj = models.Book.objects.all()
# 使用类实例化得到分页器对象
page_obj = CursorPagination()
# # 设置三个参数
page_obj.cursor_query_param = 'cursor' # 查询关键字
page_obj.page_size = 2 # 每页显示几条
page_obj.ordering = 'id' # 按照哪个字段进行排序
# 调用分页器对象方法对数据进行分页处理
# 参数: queryset(数据集),request(请求),view(处理分页的视图类)
page = page_obj.paginate_queryset(queryset=book_obj, request=request, view=self)
# 将分页后的内容进行序列化处理
page_ser = BookModelSerializer(instance=page,many=True)
return page_obj.get_paginated_response(page_ser.data)
#🔰 urls.py 路由
path('book5/', views.CursorPageView.as_view()),
- 效果演示
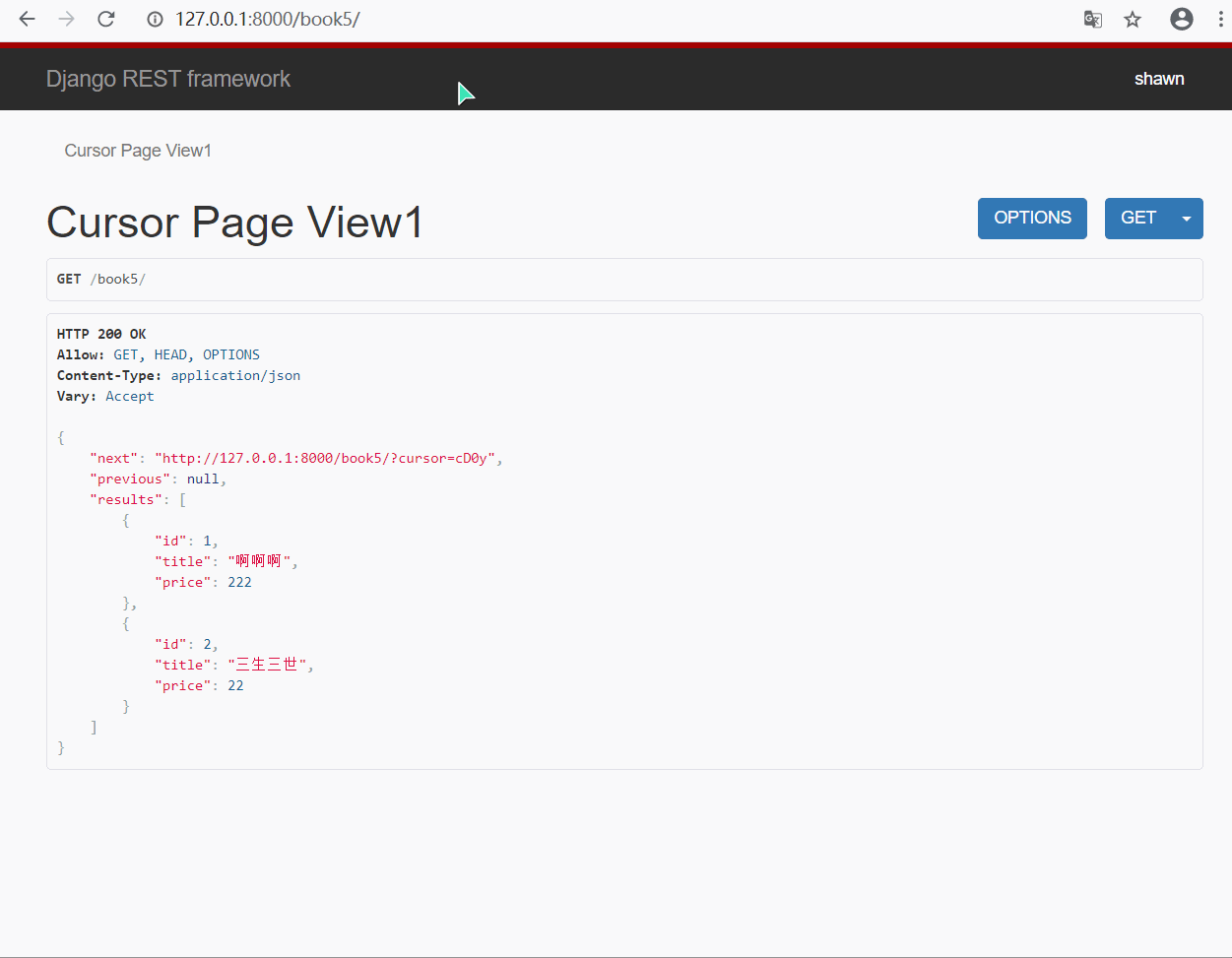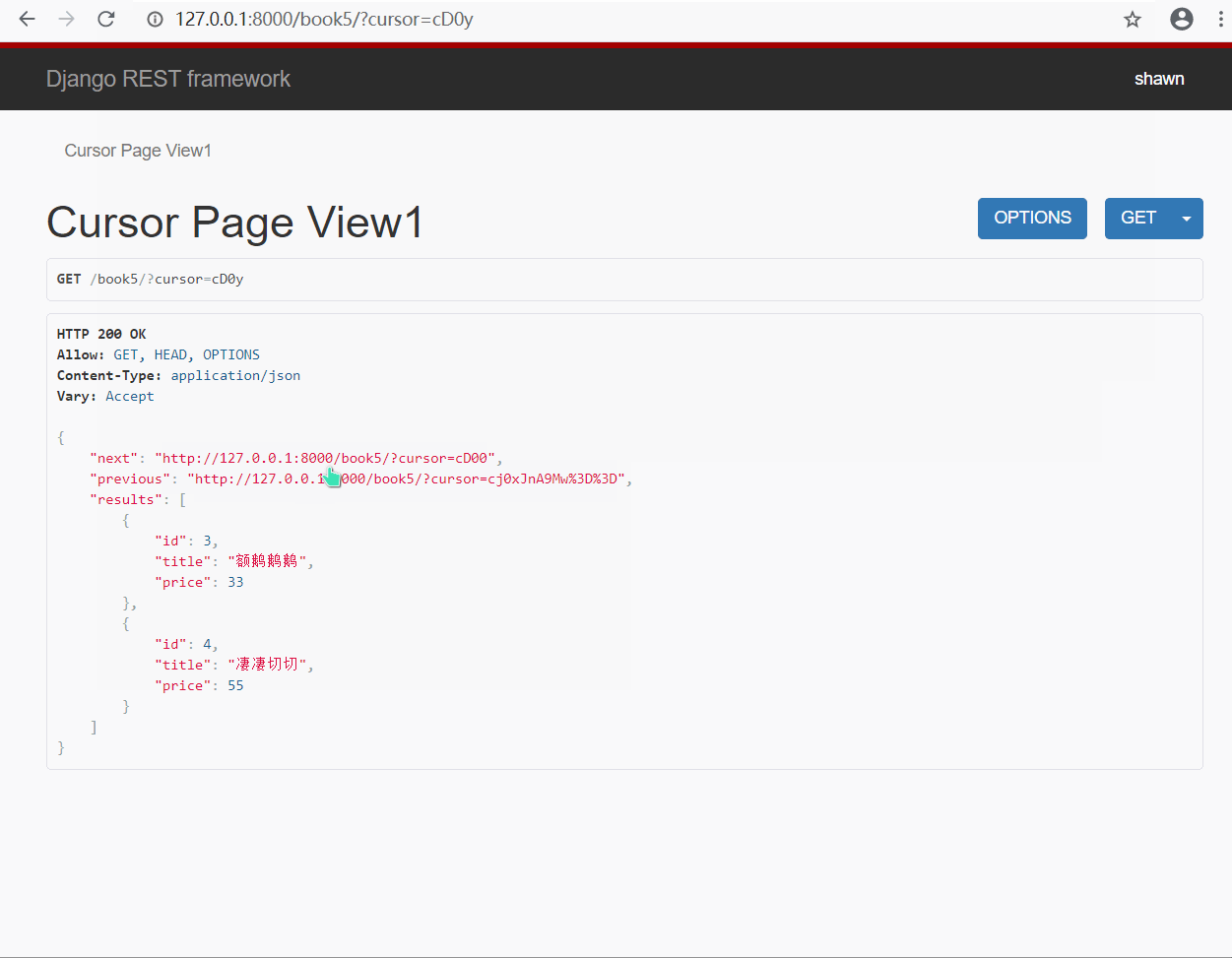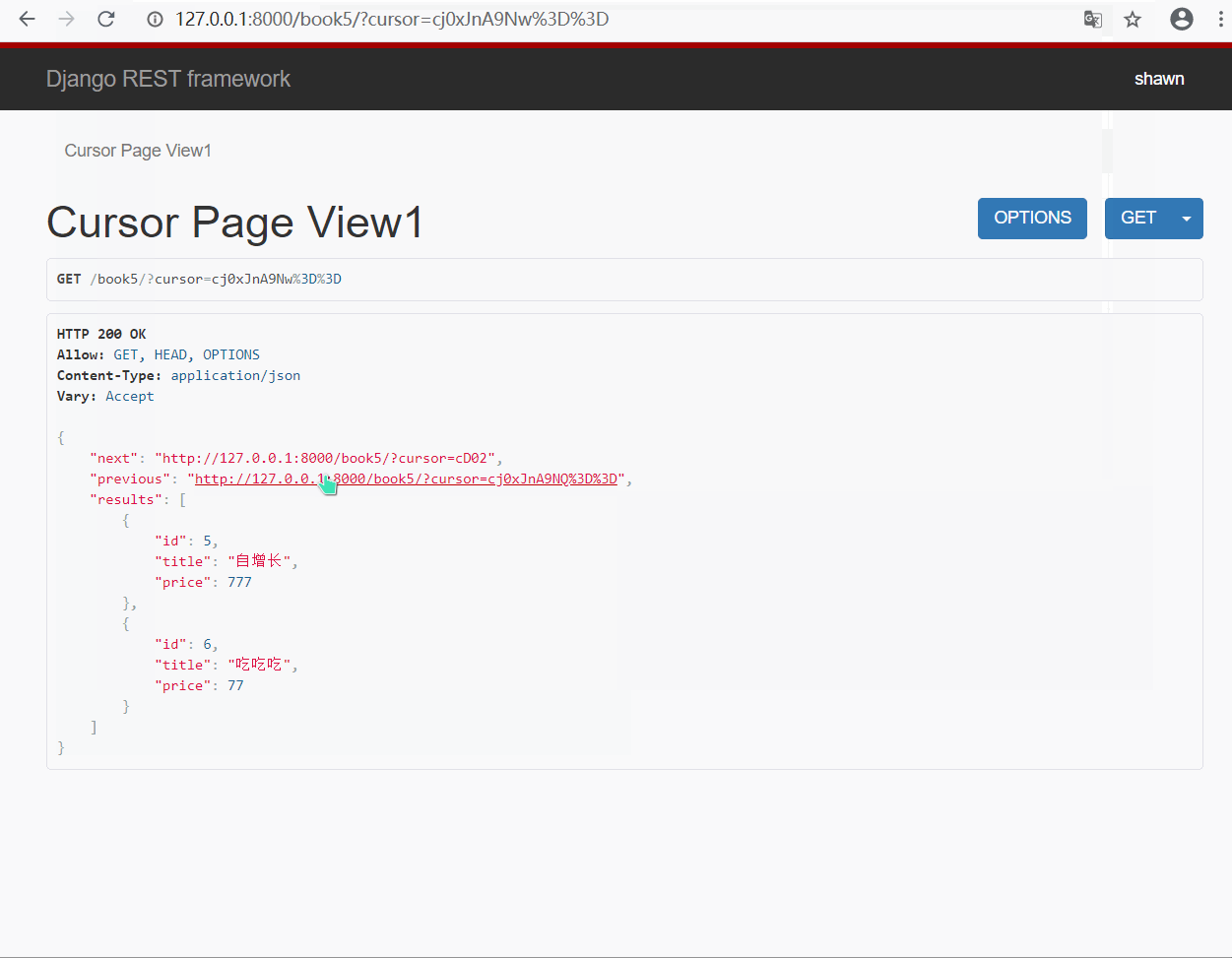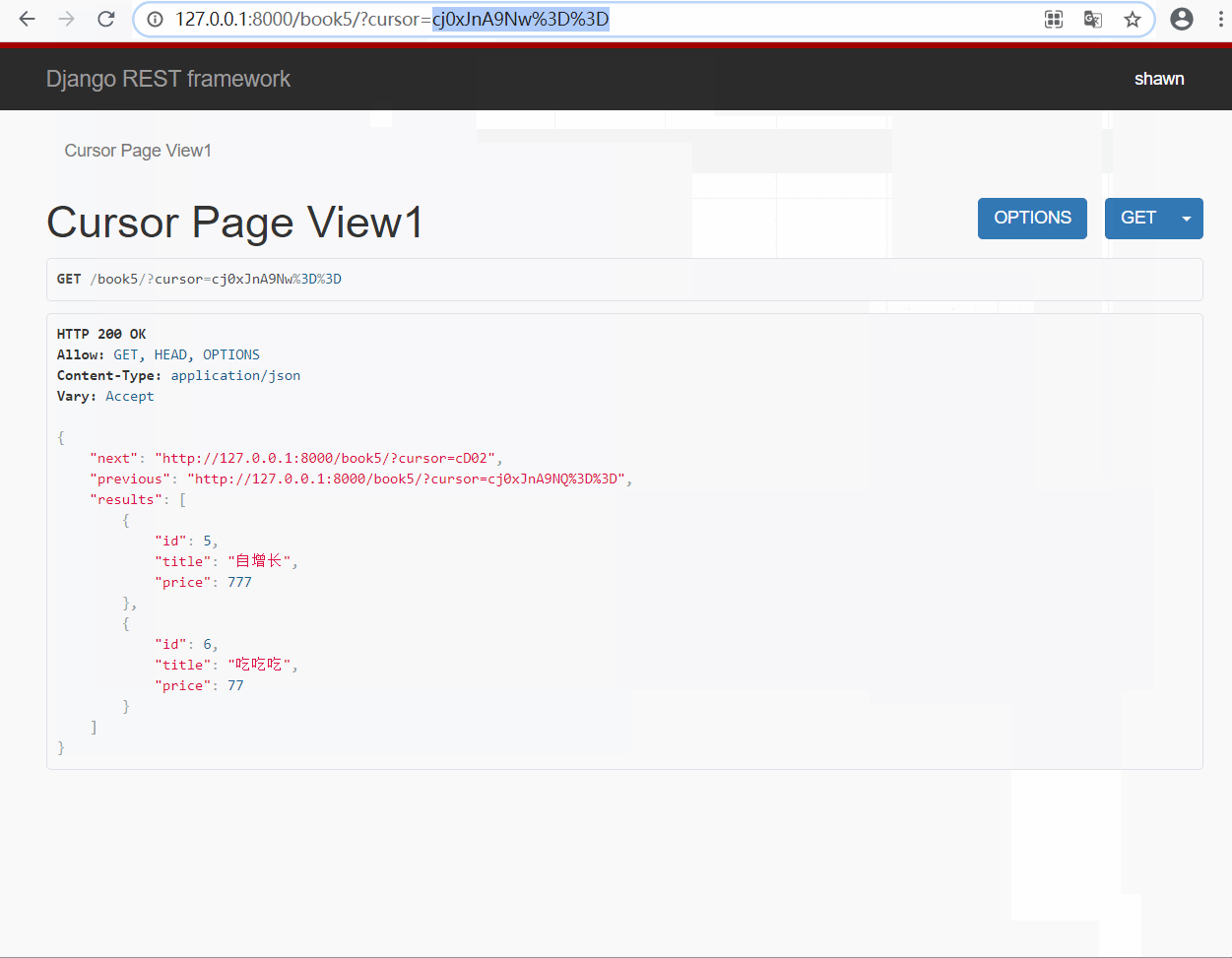
由于该分页类对也没进行了加密, 所以无法直接通过输入页码的方式进行查询(自定义CursorPaginator可以通过链接实现)
- 方式二 : 自定义游标类实现
#🔰 custompage.py 自建分页类
# 写一个类, 继承分页类, 重写类属性
from rest_framework.pagination import CursorPagination
# 1.继承CursorPagination类重写
class CustomCursor(CursorPagination):
cursor_query_param = 'cursor'
page_size = 2
ordering = 'id'
#🔰 views.py 视图类
# 导入自定义游标类
from drf_test.page.custompage import CustomCursor
class CursorPageView2(ViewSetMixin, ListAPIView):
queryset = models.Book.objects.all()
serializer_class = BookModelSerializer
# 指定游标类
pagination_class = CustomCursor
#🔰 urls.py 路由
path('book6/', views.CursorPageView2.as_view(actions={'get':'list'})),
- 效果演示
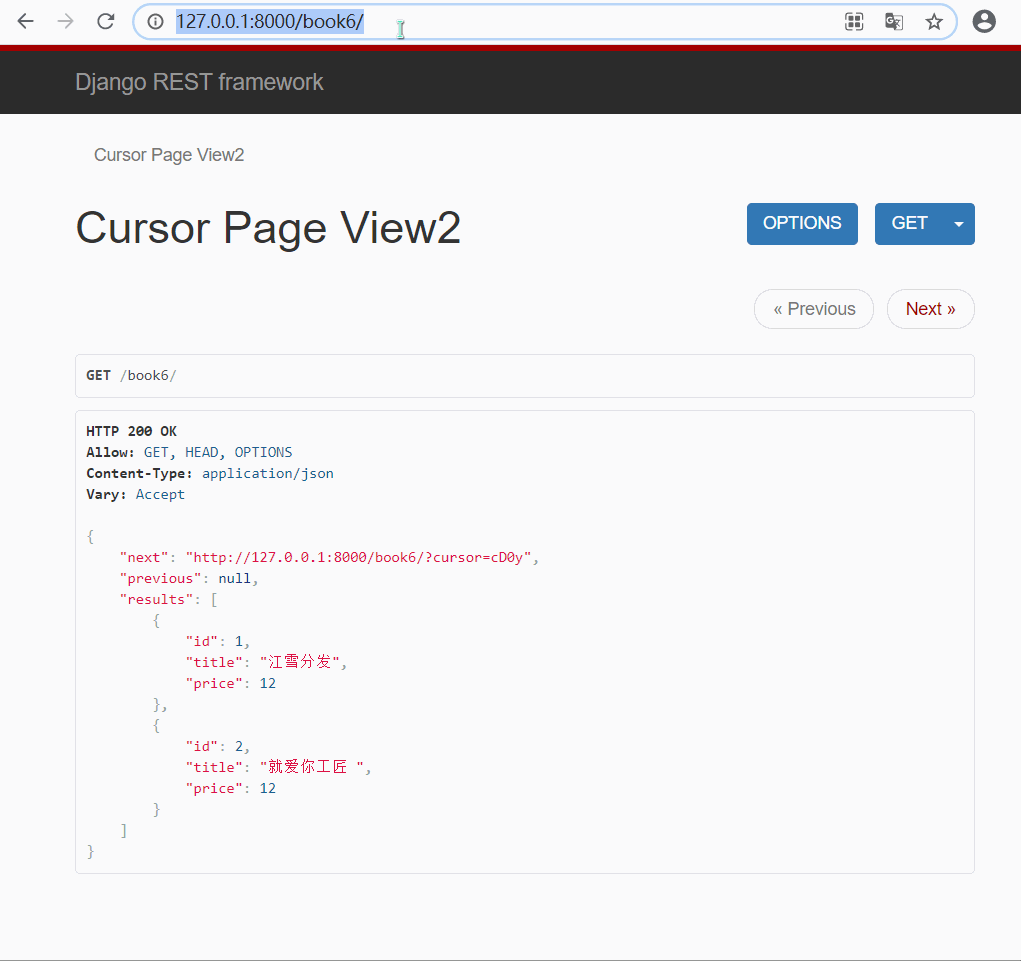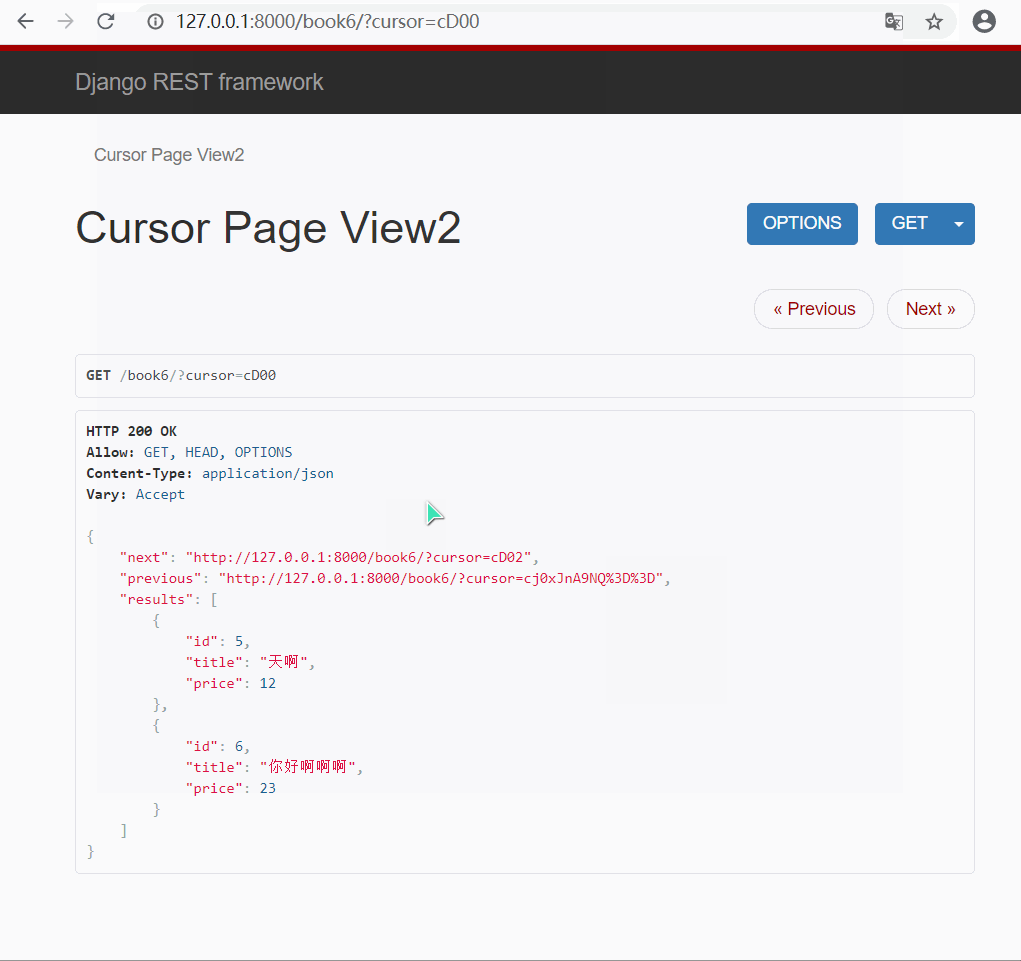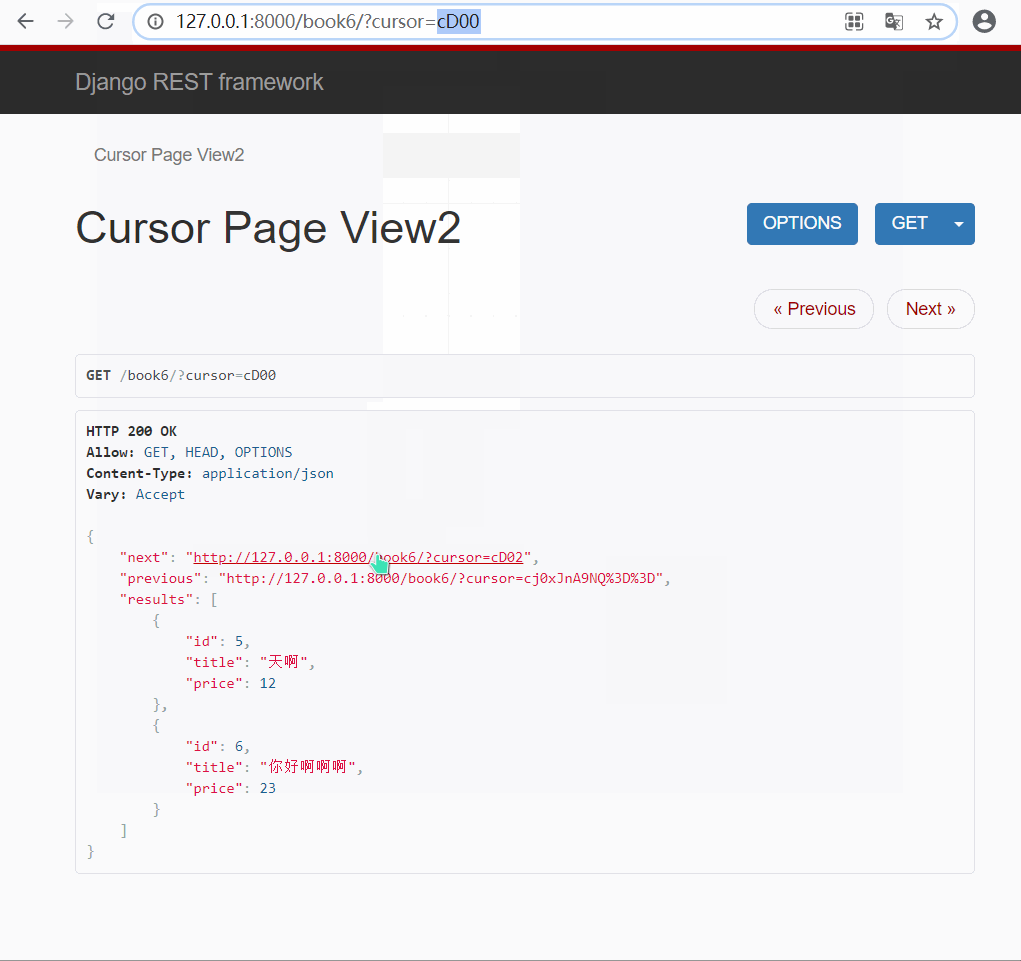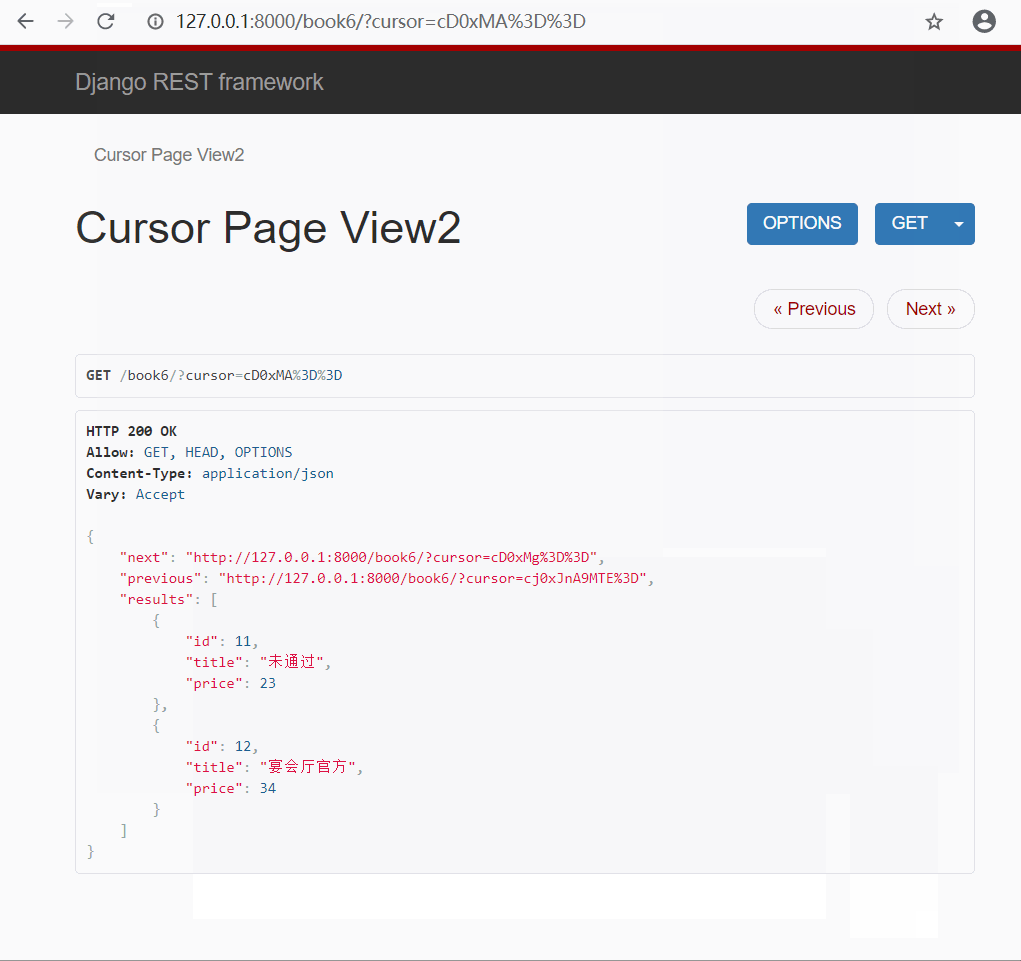
有上面演示结果可以看出 : url 中的页码是经过加密的, 页面提供给你两个链接, 只能进行上一页和下一页, 无法指定某一页跳转
- 报错问题 :
Using cursor pagination, but filter class OrderingFilter returned aNoneordering.
# 过滤以及排序与加密分页的冲突,如果setting.py设置了自定义的排序就会出现该问题
# 在setting.py文件中将'DEFAULT_FILTER_BACKENDS'注释
4.全局使用
- 在 settings.py 文件中进行配置
REST_FRAMEWORK = {
# 配置要使用的分页类
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
# 配置类属性
'PAGE_SIZE' : 3
}
5.三种分页类总结
- CursorPagination也可以被称为加密分页, 会对页码进行加密处理, 访问者无法通过修改页码来进行访问
- 这种方式相对于PageNumberPagination分页的优点是避免因用户任意修改页码, 从而数据库查询数量过大, 造成数据库过载和查询速度慢的问题
- 这个也是数据库查询性能优化, 例如PageNumberPagination中用户可以直接将页码改为10000, 数据库需要从头遍历检索到10000这条记录
- 而CursorPagination中只能查看上下页, 对数据库产生的压力极小, 但对用户的体验不友好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号