

【Redis系列】- Redis 为什么这么快?
1. 背景
Redis现在广泛应用于大中型互联网项目中,最重要的场景就是作为分布式缓存,来应对大流量高并发的冲击,那么为什么Redis有如此高的性能,这篇文章就来分析一下Redis高性能实现原理。
2. Redis高性能能分析
2.1 存储模式:基于内存存储实现
我们都知道内存读写是比在磁盘快很多的,Redis 基于内存存储实现的数据库, 相对于数据存在磁盘的 MySQL 数据库,省去磁盘 I/O 的消耗。
2.2 数据结构:高效的数据结构
每种软件都会选择适合自己的数据结构,比如Mysql选择了 B+树的数据结构,可以方便进行范围查找以及查询时候的算法稳定性。那么Redis也设计了适合自己的数据结构,包含如下图:

Redis提出多种数据结构各有特点,用于不同的业务场景。
2.2.1 简单动态字符串(SDS)
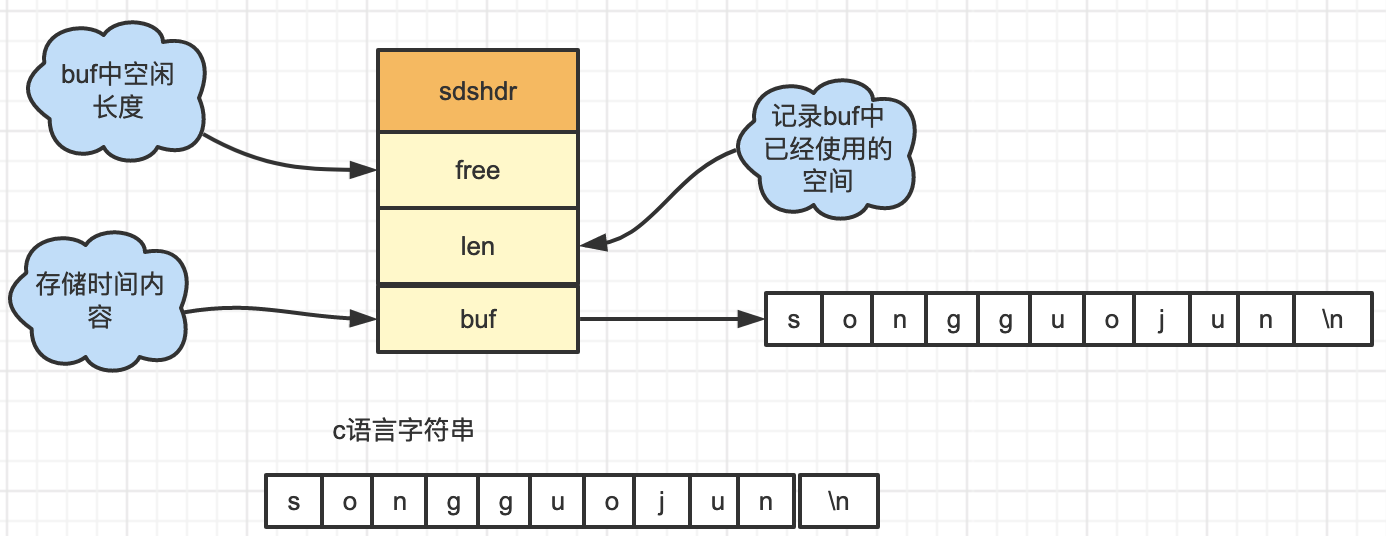
字符串长度处理: Redis 获取字符串长度,时间复杂度为 O(1),而 在C 语言中需要从头开始遍历,复杂度为 O(n)。
空间预分配: 字符串修改越频繁的话,内存分配越频繁,就会消耗性能,而 SDS 修改和空间扩充,会额外分配未使用的空间,减少性能损耗。
惰性空间释放: SDS缩短时,不是回收多余的内存空间,而是在free属性中记录下多余的空间,后续有变更直接使用 free 中记录的空间,可以减少分配操作。
二进制安全: Redis可以存储一些二进制数据,在C语言中字符串遇到'\0'会结束,而 SDS 中标志字符串结束的是len属性。
代码结构:
struct sdshdr { //SDS简单动态字符串 int len; //记录buf中已使用的空间 int free; // buf中空闲空间长度 char buf[]; //存储的实际内容 }
2.2.2 字典
Redis 作为 Key-Value 型内存数据库,所有的键值就是用字典来存储。字典就是哈希表,比如 HashMap,Go map。通过 key 就可以直接获取到对应的 value。而哈希表的特性,在 O(1)时间复杂度就可以获得对应的值。
2.2.3 跳跃表(SkipList)
跳跃表是Redis特有的数据结构,它其实就是在链表的基础上,增加多级索引,以提高查找效率。跳跃表的简单原理图如下:
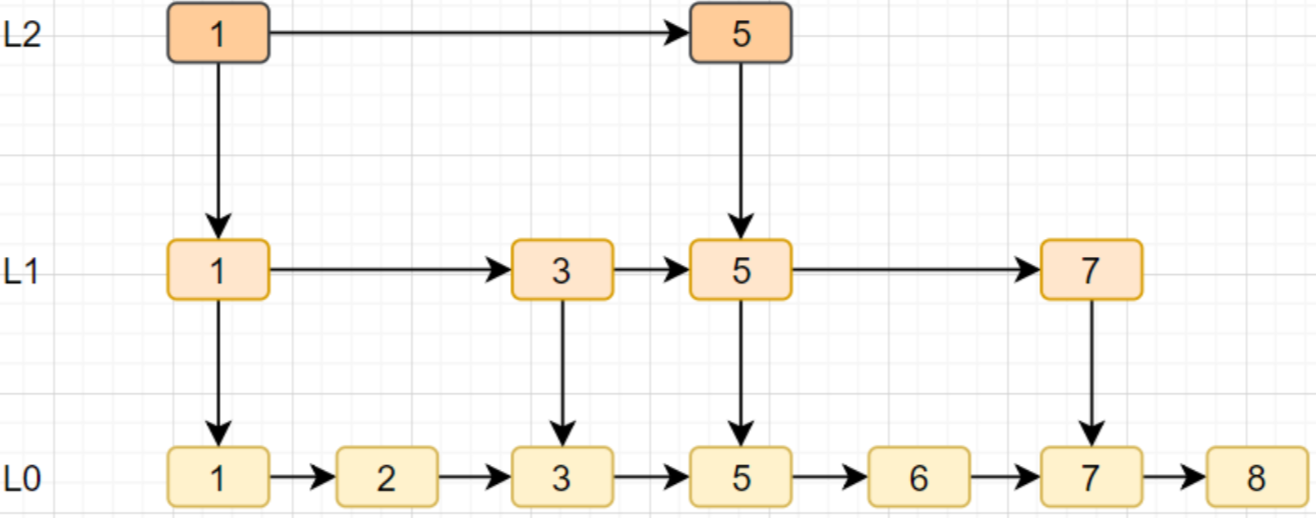
跳跃表特点:
- 跳跃表是 Redis 特有的数据结构,就是在链表的基础上,增加多级索引提升查找效率。
-
跳跃表支持平均 O(logN),最坏 O(N)复杂度的节点查找,还可以通过顺序性操作批量处理节点。
有关跳跃表可以看我之前写的文章:https://www.cnblogs.com/songgj/p/9124929.html
2.2.4 压缩列表ziplist
压缩列表ziplist是列表和字典的的底层实现之一。它是由一系列特殊编码的内存块构成的列表, 一个ziplist可以包含多个entry, 每个entry可以保存一个长度受限的字符数组或者整数,如下:

各个属性含义:
- zlbytes :记录整个压缩列表占用的内存字节数。
- zltail: 尾节点至起始节点的偏移量。
- zllen : 记录整个压缩列表包含的节点数量。
- entryX: 压缩列表包含的各个节点。
- zlend : 特殊值0xFF(十进制255),用于标记压缩列表末端。
由于内存是连续分配的,所以遍历以来速度很快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号