

Go Map底层实现原理
Map底层实现原理
Go Map是一种key-value的键值对存储结构,其中key不能重复。它是一个指针,占用8字节,指向一个hmap结构体。
Map的数据结构源代码在src/runtime/map.go中
我们通过go env 命令先找到go源代码路径
找到对应文件map.go
找到hmap结构体所在的地方
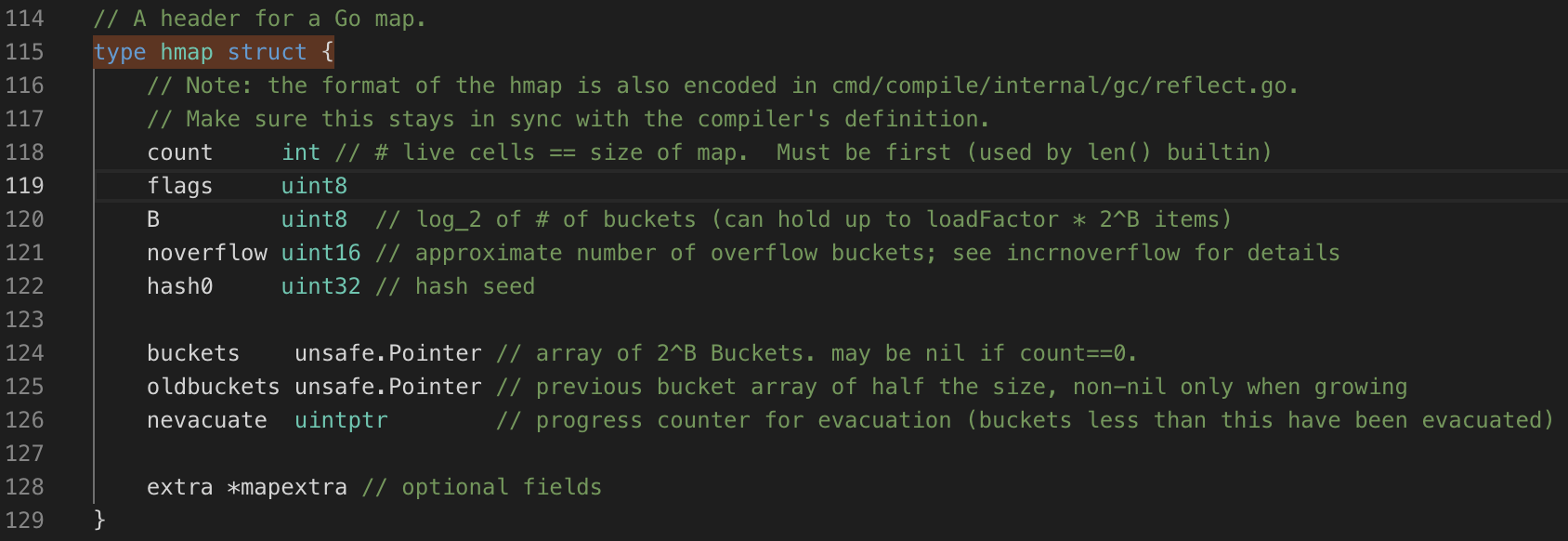
翻译一下hmap结构体代码
// A header for a Go map. type hmap struct {
// 代表哈希表中元素个数,点那个调用len函数时候就会返回该字段的值 count int
// 状态标准,表示是否处于正在写入状态等,用于读写时候的冲突 flags uint8
// buckets桶的对数, 2^B ,如果B是5,则有32个桶 B uint8
// 溢出桶等数量 noverflow uint16
// 生成hash的随机因子(seed),用来哈希函数对key求哈希值初始化这个随机数种子。 hash0 uint32 // 指向Buckets数组的指针,数组大小为2^B,如果元素个数等于0,则它为nil ( nil if count==0) buckets unsafe.Pointer
// 如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2,在非扩容状态下,它为nil oldbuckets unsafe.Pointer
// 表示扩容进度,小于此地址的buckets则代表已经迁移完毕 nevacuate uintptr //用于保存溢出桶的地址,这个字段是为了优化GC扫描设计的 extra *mapextra }
根据上面结构体我们在下面结构图中能找到对应的部分。
hmap包含了若干个结构为bmap的数组,每个bmap结构底层采用的是链表结构,bmap一般称其bucket。
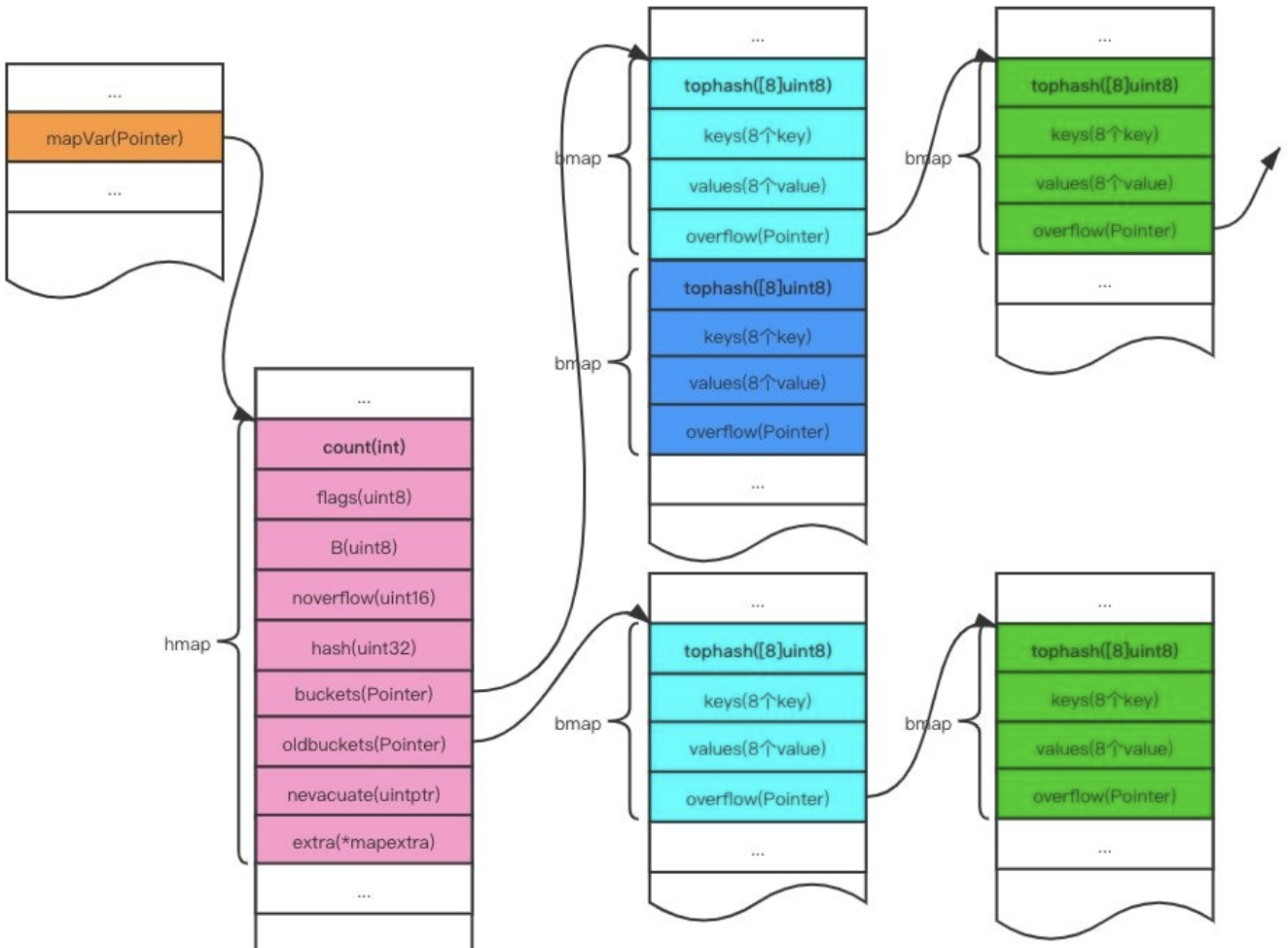
hmap我们可以理解为是一个哈希表,它自身包含了若干个结构为bmap的数组,bmap内部是通过链表串联起来的,bmap通常也被称作bucket(桶)。
上面最左边黄色块是一个变量mapVar,它指向了hmap,上图红色块中比较重要的元素是中间的buckets(Pointer)和oldbuckets(Pointer),它们分别指向了多个bmap(后面我们统一称bucket),每个bucket最多只能放8个键值对,如果超过8个,落入当前的bucket,则需要再创建一个bucket,也叫做溢出桶,通过overflow(Pointer)指针连接起来,组成了一个大的结构。
bmap 结构体说明

bmap就是上面说的桶(bucket),一个bucket里会存放最多8个key/value,落入到同一个bucket的key是因为它们进过哈希计算后,哈希结果的低B位是相同的,什么意思呢?就是说比如第32号桶,然后B是5,那么就取哈希结果的低5位,低5位如果相同这些key就是命中同一个桶。
上面决定落在哪个bucket,在bucket内,又会根据key计算出来的哈希值的高8位来决定key到底落入到bucket内具体位置(一个bucket内最多有8个位置)。
在编译器编译之前bmap只有tophash这一个字段,是一个8位长度的数组,用来快速定位key是否在这个bucket内
// A bucket for a Go map. type bmap struct { tophash [bucketCnt]uint8 }
编译后,会给bmap会多处几个字段,如下
type bmap struct{ tophash [8]uint8 keys [8]keytype // 8个key,keytype 由编译器编译时候确定 values [8]elemtype // 8个value,elemtype 由编译器编译时候确定 overflow uintptr // 如果桶溢出,overflow指向下一个bmap,overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,
// 溢出桶存储到extra字段中。这个uintptr最终可以转换成指针,这个指针就指向了extra。 }
bmap结构体字段说明:
- tophash字段是用于快速查找key是否在该bucket中,在实现过程中会使用key的hash值的高8位作tophash值,存放在bmap tophash字段中。tophash字段不仅存储key哈希值的高8位,还会存储一些状态值,用来表明当前桶单元状态。这些状态值都是小于minTopHash的。
为了避免key哈希值高8位和这些状态相等,产生混淆情况,所以当key哈希值高8位若小于minTopHash时候,自动将其值添加加上minTopHash作为该key的tophash。
其实在bmap代码注释里也写了
// tophash generally contains the top byte of the hash value // for each key in this bucket. If tophash[0] < minTopHash, // tophash[0] is a bucket evacuation state instead.
下面是map源码中对tophash状态值的定义。
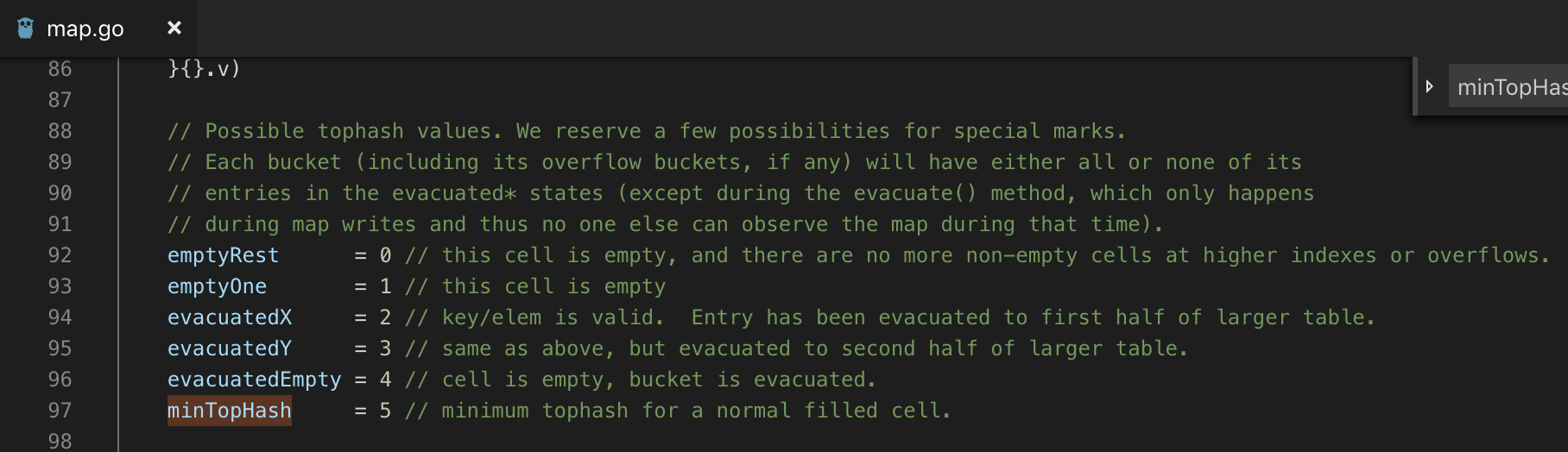
翻译一下
emptyRest = 0 // 表示此桶单元为空,并且更高的索引单位也是空 emptyOne = 1 // 此桶单元为空,但更高层索引下表单元不一定是空 evacuatedX = 2 // 扩容相关:用于表示扩容迁移到新桶前半段区间 evacuatedY = 3 // 扩容相关:用于表示扩容迁移到新桶后半段区间
evacuatedEmpty = 4 // 表示此单元已经迁移
minTopHash = 5 // key的tophash值和桶状态值分割线值,小于此值的一定代表桶单元的状态,当大于此值的一定是key对应的tophash值
简单说就是:
当tophash[i] < 5时,表示存的是状态;
当tophash[i] >= 5时,表示存的是哈希值;
下面是tophash字段计算代码:
// tophash calculates the tophash value for hash. func tophash(hash uintptr) uint8 { top := uint8(hash >> (sys.PtrSize*8 - 8)) if top < minTopHash { top += minTopHash } return top }
看上面3-5行代码可以知道,当计算的哈希值小于minTopHash时,会直接在原有哈希值基础上加上minTopHash,确保哈希值一定大于minTopHash。
还有一个重要的结构就是溢出桶,mapextra结构体,所有的的溢出桶就是存放在extra *mapextra里。
在代码里找到它

type mapextra struct { //记录所有使用的溢出桶 overflow *[]*bmap //用于在扩容阶段存储旧桶用到的溢出桶的地址 oldoverflow *[]*bmap // 指向下一个空闲溢出桶 nextOverflow *bmap }
这里总结下:
go map底层主要就由上面三个部分组成。
bmap(bucket)内存结构可视化如下图:
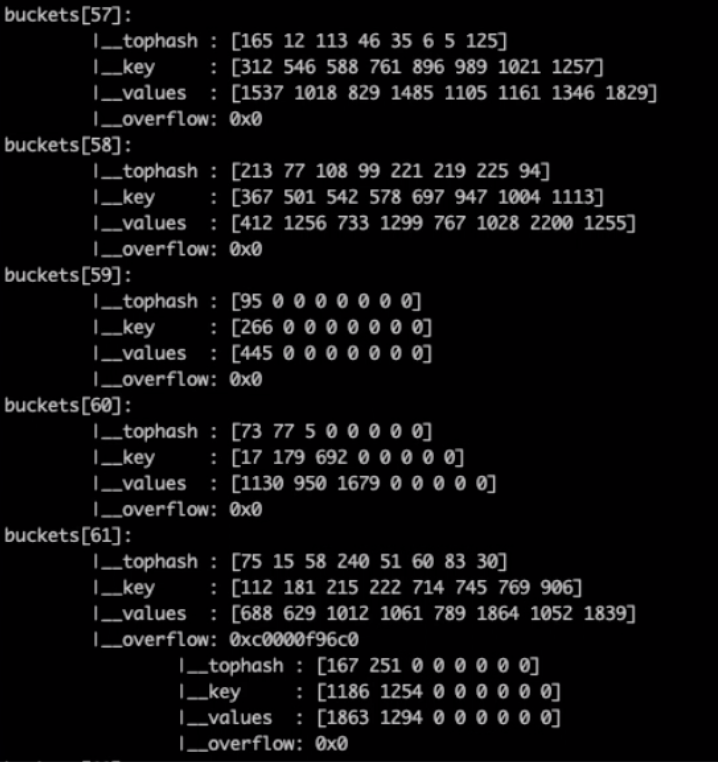
注意看key和value是各自放在一起的,而并不少key/value/key/value....这样的存放形式,当key和value类型不同时,key和value所占用字节大小不同,使得这种方式可能会因为内存对齐导致空间浪费,所以Go采用key和value分开存放来节省内存空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号