

Hadoop 简介(转)
Hadoop - 简介
Hadoop可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点
特别适合写一次,读多次的场景
适合
- 大规模数据
- 流式数据(写一次,读多次)
- 商用硬件(一般硬件)
不适合
- 低延时的数据访问
- 大量的小文件
- 频繁修改文件(基本就是写1次)
Hadoop架构
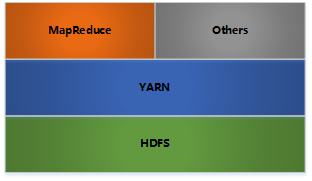
- HDFS: 分布式文件存储
- YARN: 分布式资源管理
- MapReduce: 分布式计算
- Others: 利用YARN的资源管理功能实现其他的数据处理方式
内部各个节点基本都是采用Master-Woker架构
Hadoop安装
-
单节点安装
所有服务运行在一个JVM中,适合调试、单元测试
-
伪集群
所有服务运行在一台机器中,每个服务都在独立的JVM中,适合做简单、抽样测试
-
多节点集群
服务运行在不同的机器中,适合生产环境
配置公共帐号
方便主与从进行无密钥通信,主要是使用公钥/私钥机制 所有节点的帐号都一样 在主节点上执行 ssh-keygen -t rsa生成密钥对 复制公钥到每台目标节点中
Hadoop配置
有两种配置文件:
一种是**-default.xml(只读,默认的配置)
一种是**-site.xml(替换default中的配置)
-
core-site.xml 配置公共属性
-
hdfs-site.xml 配置HDFS
-
yarn-site.xml 配置YARN
- mapred-site.xml 配置MapReduce
配置文件应用的顺序:
- 在JobConf中指定的
- 客户端机器上的**-site.xml配置
- slave节点上的**-site.xml配置
- **-default.xml中的配置
如果某个属性不想被覆盖,可以将其设置成final
<property>
<name>{PROPERTY_NAME}</name>
<value>{PROPERTY_VALUE}</value>
<final>true</final>
</property>


 浙公网安备 33010602011771号
浙公网安备 33010602011771号