公司新来的00后老板让我们把数据库改成PostgreSQL,大家怒了😂
如果你现在要做一个新项目,那么在 PostgreSQL vs MySQL 之间的数据库选型会选择哪一个?
Mysql在国内非常流行,但是行业内最稳、可扩展性最高的推荐是:
🧭 优先推荐:PostgreSQL
下面是mysql和PG的简易对比:
| 功能 | PostgreSQL | MySQL |
|---|---|---|
| JSON 性能 | 快 + 正规 | 慢 + 不是正统 JSON |
| 复杂查询优化器 | 强 | 弱 |
| 索引类型 | 超多 | 较少 |
| 并发事务(MVCC) | 原生、稳定 | 不如 PG |
| 分析查询 | 强 | 一般 |
| 插件生态(向量、搜索等) | 爆炸 | 少 |
| 地理信息(GIS) | 最佳 | 一般 |
没错,本文又是一篇PG的推广文
准备工作
PG的安装方式很多,你可以自行百度
| 方案 | 免费 | 免费额度/限制 | 长期用要不要花钱 | 推荐场景 |
|---|---|---|---|---|
| Neon Serverless | 完全免费 | 3个项目,>0.5 CPU (burst到2核)>3 GB 存储 | 300 计算小时/月 | 够个人学习、写demo、小项自用,超过才付费 |
| Postgres.app (Mac) | 完全免费 | 无任何限制,本地跑多少都行 | 永久免费 | Mac 用户首选 |
| 官方 Windows 安装包 | 完全免费 | PostgreSQL 本身永远开源免费,安装器是 EnterpriseDB 做的,也免费 | 永久免费 | Windows 用户首选 |
| Homebrew/apt 安装 | 完全免费 | 社区包,永久免费 | 永久免费 | Linux 或喜欢命令行的同学 |
| Docker(官方镜像) | 镜像免费 | 镜像本身免费,只是可能拉不动 | 永久免费 | 学会以后也很好用 |
安装好以后会有三个数据库:
- postgres:默认空数据库,专门给你玩的
- template1:模板数据库,你新建数据库时会复制它
- 用户名:自动用你的用户名创建的一个同名数据库(相当于 MySQL 的 test 库)
简单用法
在 PostgreSQL 里没有 SHOW TABLES 这个命令(那是 MySQL 的),但有好几种更强大的方式可以列出当前数据库里的所有表:
最常用、最像 SHOW TABLES(强烈推荐记这一条)
\dt
直接在 psql 终端敲 \dt 回车,立刻列出当前数据库里所有表(但是不能在客户端执行SQL的地方用)。
输出带了 schema、表名、类型、拥有者,一目了然。
如果想看得更详细(带表大小、描述等):
\dt+
标准 SQL 写法(任何图形化工具都通用)
-- 列出所有表(带 schema)
SELECT schemaname, tablename
FROM pg_tables
WHERE schemaname IN ('public') -- 只看 public
ORDER BY tablename;
-- 或者更全(包括视图、物化视图、序列等)
SELECT schemaname || '.' || tablename AS table_full_name,
tableowner,
hasindexes,
tablespace
FROM pg_tables
WHERE schemaname = 'public';
pg的表都是在public这个schema下面。schema和database是两个层级
浅尝则止
想马上看到点东西吗?复制下面这三行粘贴到 psql 里跑,建 3 张表玩:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username TEXT UNIQUE NOT NULL,
tags TEXT[],
profile JSONB,
created_at TIMESTAMPTZ DEFAULT now()
-- 比 MySQL datetime 好用100倍
);
CREATE TABLE orders (
id BIGSERIAL PRIMARY KEY,
user_id INT REFERENCES users(id),
amount NUMERIC(12,2),
status TEXT DEFAULT 'pending',
items JSONB
);
-- 顺便玩一下2025年最火的向量搜索
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536)
);
\dt public.* -- 再看一遍,就有 3 张表啦!
你可能在客户端会看到很多东西
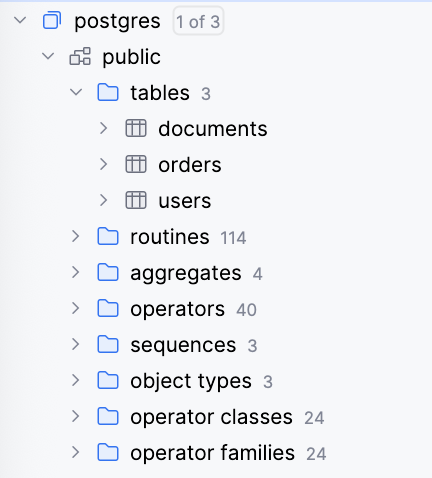
| 你看到的名称 | 其实是什么 | 要不要管它? | 备注 |
|---|---|---|---|
| tables 3 → documents / orders / users | 你自己建的业务表,以后所有数据都在这里面 | 重点关注! | 这才是你真正要用的 |
| sequences 3 | 自动为 SERIAL/BIGSERIAL 生成自增 ID 的序列 | 不用管 | 每张表一个,自动关联 |
| routines 114 | 系统自带的上百个函数(类似 MySQL 的内置函数) | 不用管 | 比如 now()、substring() |
| aggregates 4 | 聚合函数(count、sum、avg、string_agg) | 偶尔用 | |
| operators 40 | 操作符(=、>、、@>、<@ 等) | ||
| operator classes 24 / operator families 24 | 给索引用的底层实现 | 不用管 | GIN、GiST 索引会用到 |
| object types 3 | 复合类型、枚举、range 类型等 | 不用管 | 高级玩法才用 |
| 其他一堆数字 | PostgreSQL 系统自己跑需要的元数据 | 完全不用管 | 相当于 MySQL 的 information_schema |
先插入点数据
INSERT INTO users (username, tags, profile) VALUES
('张三', ARRAY['VIP','北京','90后'], '{"age": 33, "city": "北京", "hobbies": ["羽毛球","摄影"]}'),
('李四', ARRAY['深圳','00后'], '{"age": 24, "city": "深圳", "hobbies": ["王者","滑板"]}'),
('王五', ARRAY['VIP','上海','美食家'], '{"age": 41, "city": "上海", "hobbies": ["米其林","红酒"]}');
INSERT INTO orders (user_id, amount, items, status) VALUES
(1, 998.00, '["iPhone 16 Pro","AirPods Pro 2"]', 'paid'),
(1, 129.00, '["星巴克月卡"]', 'paid'),
(2, 5999.00, '["MacBook Pro M4"]', 'pending'),
(3, 2888.00, '["米其林三星代金券"]', 'paid'),
(1, 66.60, '["奶茶3杯"]', 'paid');
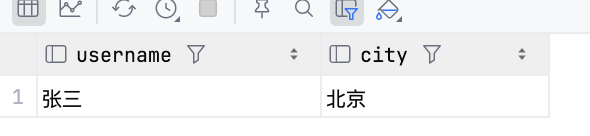
然后查询一下北京的用户:
-- JSONB 神操作 查所有住在北京的人
SELECT username, profile->>'city' AS city FROM users WHERE profile->>'city' = '北京';
Mysql能做吗?能!
-- mysql的做法
SELECT
username,
JSON_UNQUOTE(JSON_EXTRACT(profile, '$.city')) AS city
FROM users
WHERE JSON_EXTRACT(profile, '$.city') = '北京';
肉眼不可见的复杂!
| 能力 | MySQL | PostgreSQL |
|---|---|---|
| JSON 插入 | ✔ 支持 | ✔ 支持 原生 JSONB |
| JSON 查询 | ✔ 支持 | ✔ 强得多 @>、?、?|、?& |
| 原生 ARRAY | ❌ 不支持 | ✔ 支持 |
| JSON 索引性能 | ❌ 差,只能做前缀索引或虚拟列索引 | ✔ 极强 |
| JSON 语法 | ❌ 很麻烦(JSON_EXTRACT) | ✔ 很优雅 |
继续看几个SQL
-- 查有“摄影”爱好的人
SELECT username, profile->'hobbies' FROM users WHERE profile->'hobbies' @> '"摄影"';
-- 直接更新 JSON 字段里某个 key
UPDATE users SET profile = jsonb_set(profile, '{age}', to_jsonb((profile->>'age')::int + 1)) WHERE username = '李四';
-- string_agg 聚合拼接 每个用户买了啥,用 | 分隔
SELECT u.username,
string_agg(o.items::text, ' | ') AS 购买的商品,
count(o.id) AS 订单数,
sum(o.amount) AS 总消费
FROM users u
LEFT JOIN orders o ON o.user_id = u.id
GROUP BY u.id;
这个聚合查询的输出是

-- 窗口函数排行榜(MySQL 8 勉强能写,慢得要死)
SELECT
username,
sum(amount) AS total,
rank() OVER (ORDER BY sum(amount) DESC) AS "全国排名",
percent_rank() OVER (ORDER BY sum(amount) DESC) AS "百分位"
FROM users u
LEFT JOIN orders o ON o.user_id = u.id
GROUP BY u.id;

第三列是给用户按「总消费额」降序(DESC)排 “全国名次”。这个函数支持并列,比如把王五金额改成5999:

第四列计算用户的「百分位排名」(范围是 0~1),表示 “比当前用户消费高的用户占总用户数的比例”。计算公式:(当前排名 - 1) / (总用户数 - 1)。
向量数据
前面创建了一个1536维的向量表documents。有什么用?
这种“超级宽表”在传统业务里确实几乎不会出现,但它在 2024~2025 年的 AI 原生应用里已经烂大街了,属于标配。
如果你也是「要让机器理解语义相似度」而不是「精确关键词匹配」的场景,现在 99% 都用向量表。
-- 假装我们已经把下面三句话转成 OpenAI embedding 存进来了
INSERT INTO documents (content, embedding) VALUES
('我喜欢吃火锅和川菜', '[0.012, -0.005, 0.031, ...]'), -- 实际是1536维
('今天天气很好,适合出去滑板', '[0.008, 0.021, -0.011, ...]'),
('米其林三星餐厅推荐', '[0.045, -0.019, 0.067, ...]');
-- 找和“周末想吃辣的”最像的 2 条内容(真正语义搜索!)
SELECT
content,
embedding <=> '[周末辣的火锅推荐的向量]'::vector AS distance
FROM documents
ORDER BY embedding <=> '[周末辣的火锅推荐的向量]'::vector
LIMIT 2;
现在创建一个小表,三维的:
CREATE EXTENSION IF NOT EXISTS vector;
DROP TABLE IF EXISTS items;
CREATE TABLE items (id bigserial primary key, embedding vector(3));
-- 插入几条 3 维玩具向量
INSERT INTO items (embedding) VALUES
('[1,2,3]'),
('[4,5,6]'),
('[-1,0,1]'),
('[8,8,8]');
-- 找和 [3,4,5] 最近的 2 条(真正向量余弦距离)
SELECT id, embedding, embedding <=> '[3,4,5]' AS distance
FROM items
ORDER BY distance
LIMIT 2;

那 MySQL 有什么优势?
MySQL 的优势是:
-
对小团队、简单 CRUD 来说更简单、好上手
-
生态超级成熟
-
各种运维人员都熟
-
对业务系统(传统电商/订单系统)很稳
-
InnoDB 在 OLTP 非常优秀
如果你的项目:
-
CRUD 为主
-
数据结构相对简单
-
不会用 JSON/向量/全文/复杂查询
-
团队熟 MySQL
那么 MySQL 也是一个好的选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号