
指导手册04:运行MapReduce
指导手册04:运行MapReduce
Part 1:运行单个MapReduce任务
情景描述:
本次任务要求对HDFS目录中的数据文件/user/root/email_log.txt进行计算处理,统计出第个用户的登录次数。
情景分析:统计出每个用户登录次数,等同于求出每个email出现的次数,可以进一步抽象为统计每个单司出现的频次。在Hadoop官方提供的示例包中,正好有进行记频统计的模块。
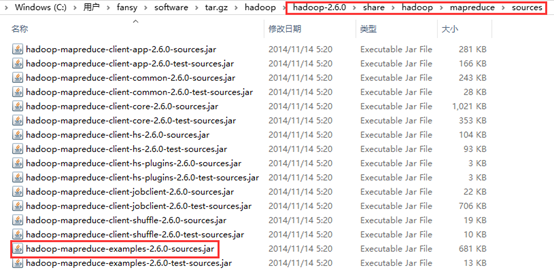
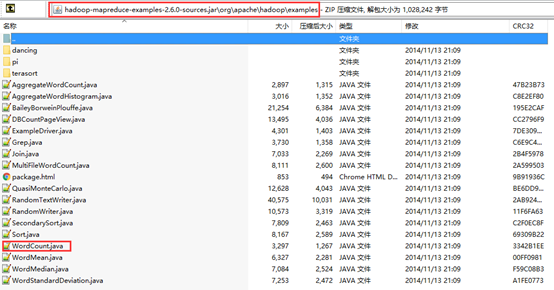
1.Hadoop官方的示例程序包
在集群服务器的本地目录”$HADOOP_HOME/share/hadoop/mapreduce/中可发现示例程序包hadoop-mapreduce-examples-2.6.4.jar
|
模块名称 |
内容 |
|
multifilewc |
统计多个文件中单词的数量。 |
|
pi |
应用quasi-Monte Carlo 算法来估算圆周率π的值。 |
|
randomtextwriter |
在每个数据节点随机生成1个10GB的文本文件。 |
|
wordcount |
对输入文件中的单词进行频数统计。 |
|
wordmean |
计算输入文件中单词的平均长度。 |
|
wordmedian |
计算输入文件中单词长度的中位数。 |
|
wordstandarddeviation |
计算输入文件中单词长度的标准差。 |
2.提交MapReduce任务给集群运行
提交MapReduce任务,通常使用hadoop jar 命令。它的基本用法格式如下
Hadoop jar <jar> [mainClass] args
因为hadoop jar 命令的附带参数较多,下面结合实际任务,对它的各项参数依次进行说明。
例:
[root@maste opt]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-exampes-2.6.4.jar wordcount /user/root/emil_log.txt /user/root/output (emil_log.txt请参考指导手册03上传)
参数说明:
$HADOOP_HOME:指主机中设置的环境变量
hadoop-mapreduce-exampes-2.6.4.jar :Hadoop官方提供的示例程序包
wordcount:程序中的主类名称
/user/root/emil_log.txt:HDFS上的输入文件名称
/user/root/output: HDFS上输出的文件目录
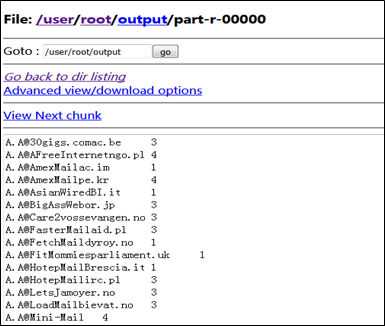
3.执行结果查看
Part 2: 管理多个MapReduce任务
情景描述:
Hadoop是一个多任务系统,它可以同时为多个用户、多个作业处理多个数据集。对于提交到Hadoop集群的多个任务,用户如何进行有效管理。比如,想知道集群完成了哪些任务;执行结果是成功还是失败;怎么检查任务的实际执行情况;如果某个任务执行时间过长,怎么中断它。
当用户提交了多个任务后,通常可以使用资源管理器的服务接口,对提交后的任务进行查询。当发现有异常时,可以中断当前作业或查询指定的日志文件。
1.查询MapReduce任务
例:调用Hadoop的示例程序包,采用Qqusi-Monte Carlo算法来估算PI的值。后面两个参数代表Map数量与每个Map的测量次数,参数的值越大,计算出来的结果精度越高。
Hadoop jar /usr/local/hadoop-2.6.4/share/hadoop/mapredduce/hadoop-mapreduce-example-2.6.2.jar pi 10 100
查看MapReduce任务的计算机资源使用情况:http://master:8088,再单击左侧菜单栏的”Nodes”.
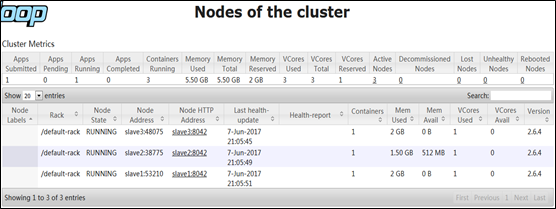
可以看到集群可用内存共有6GB,被使用了5.5G,剩余512MB,CPU核心有3个。
请运行程序,将你的集群信息填写如下:
|
可用内存 |
内存使用 |
剩余内存 |
CPU核心个数 |
|
|
|
|
|
继续查询当前任务的信息,单击左侧菜单栏中的“Applicatiions”,或者直接访问http://master:8088/cluster/apps显示如下结果。
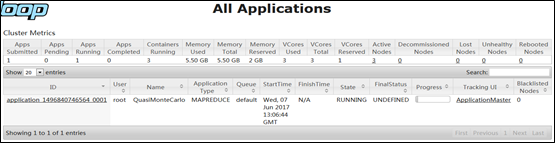
它的状态值为“RUNNNING”,表示这个任务正执行中。
2.同时提交两个任务,进行观察
示例任务1:统计用户登录次数
[root@maste opt]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-exampes-2.6.4.jar wordcount /user/root/emil_log.txt /user/root/output1 (emil_log.txt请参考指导手册03上传)
示例任务2:执行估算PI值
[root@maste opt]# Hadoop jar /usr/local/hadoop-2.6.4/share/hadoop/mapredduce/hadoop-mapreduce-example-2.6.2.jar pi 10 100
提交两个作业后,观察集群上的计算机资源使用情况。
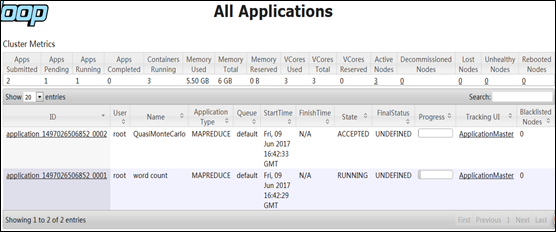
作业0001的状态“RUNNING”,表示它正在执行中。而作业0002的状态是“ACCEPTED”,表示它已被资源管理器YARN接受,目前在等待被分配计算资源,只有当计算资源满足后,才会开始执行。
3.中断MapReduce任务
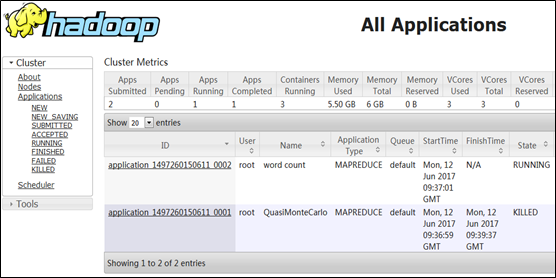
人为中断第1个作业:点击任务1的ID进入任务1,点击图中Kill Application即可中断该任务。

再次刷新任务界面,可以发现原来的作业1己被中断。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号