spring学习总结010 --- 循环依赖
先说一下循环依赖常见问题的个人理解:
1、spring只能解决属性或者setter注入场景下的循环依赖?? ------ 我理解不是,在构造器注入和属性注入混合场景下也是能够解决的
2、spring解决循环依赖采用了三级缓存,之所以用三级缓存是为了提升效率?? ------- 我理解三级缓存和二级缓存效率相差无几,只不过为了解决AOP场景下生命周期问题
什么是循环依赖
A依赖B的同时,B也依赖A,这就是循环依赖,用代码表示如下:
public class BeanB { @Autowired private BeanA beanA; }
public class BeanA { @Autowired private BeanB beanB; }
spring能解决哪种场景下的循环依赖
1、A和B均通过构造器依赖注入 ----- spring无法解决
2、A和B均通过属性注入 ----- spring可以解决
3、A通过属性注入B,B通过构造器注入A ----- spring可以解决
4、A通过构造器注入B,B通过属性注入A ----- spring无法解决
spring如何解决循环依赖
spring中解决循环依赖bean的主要创建过程如下:
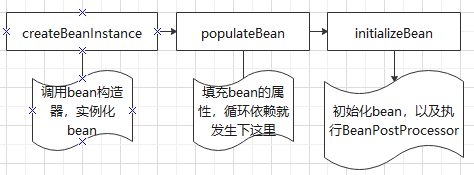
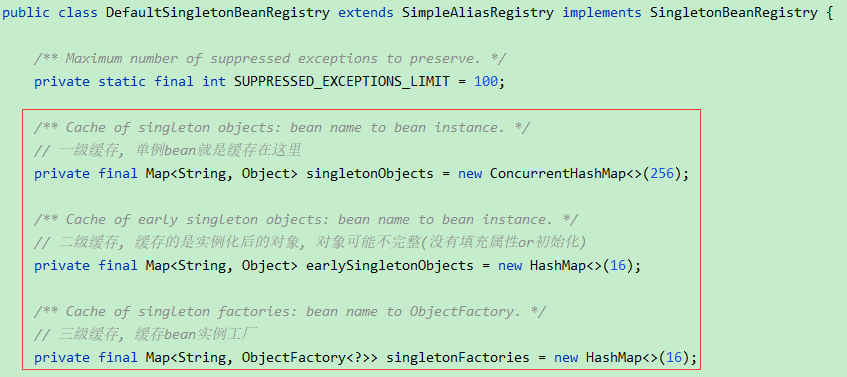
三级缓存源码中的位置及缓存的内容如下:
以A和B均属性注入产生循环依赖,说明spring如何解决循环依赖:
创建bean都是从AbstractBeanFactory的getBean方法入口,然后调用getSingleton获取bean,当然创建BeanA的时候,getSingleton返回空;getSingleton方法源码:
protected Object getSingleton(String beanName, boolean allowEarlyReference) { // 从一级缓存中获取bean Object singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { synchronized (this.singletonObjects) { // 一级缓存中没有从二级缓存中获取 singletonObject = this.earlySingletonObjects.get(beanName); if (singletonObject == null && allowEarlyReference) { // 二级缓存中没有, 从三级缓存中获取 ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); if (singletonFactory != null) { // 命中三级缓存, 将bean实例从三级缓存移动到二级缓存 singletonObject = singletonFactory.getObject(); this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); } } } } return singletonObject; }
然后进入另一个getSingleton方法,该方法的第二个参数是lamba表达式,里面调用了createBean方法,返回单例工厂实例:
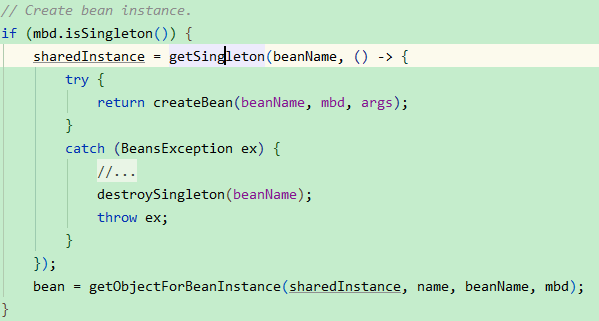
然后在doCreteBean方法中调用前面提到的三个方法,调用createBeanInstance创建实例,然后将该实例转换成实例工厂对象,存放到三级缓存:

接下来在populateBean方法中填充属性,发现bean定义中BeanA依赖BeanB,然后调用getBean方法获取BeanB;获取BeanB实例方法和获取BeanA一致,直到BeanB处理属性填充;
BeanB填充属性BeanA时,先从缓存中获取,这里命中的是三级缓存;然后完成了BeanB的属性填充、初始化等操作,得到了完整的BeanB实例;
接下来继续执行BeanA的初始化,直到创建完成。
前面说到命中三级缓存返回的对象是不完整的,那么是否意味着BeanB持有的BeanA实例是不完整的??当然不是,因为BeanB持有的是引用,BeanA的初始化完成也意味着BeanB持有的引用初始化完成
为什么spring只能解决特定场景下的循环依赖
1、A和B均通过构造器依赖注入 ----- spring无法解决
A创建实例的时候发现需要注入B对象,然后调用B的创建流程,当创建B的时候,检测到需要注入A,但是此时缓存中没有只能去创建,因此循环依赖无法解决
2、A和B均通过属性注入 ----- spring可以解决
3、A通过属性注入B,B通过构造器注入A ----- spring可以解决
4、A通过构造器注入B,B通过属性注入A ----- spring无法解决
和前面类似,A创建实例的时候发现需要注入B对象,然后调用B的创建流程;B是通过属性注入A,此时能够创建成功B的实例;接下来会执行填充B的属性,发现要注入A,执行getBean(A),因为此前A被标记在创建中,因此抛出异常
示例:
@Component @Slf4j public class BeanA { @Autowired public BeanA(BeanB beanB) { } }
@Component @Slf4j public class BeanB { @Autowired private BeanA beanA; }
执行结果:
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'beanA': Requested bean is currently in creation: Is there an unresolvable circular reference? at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.beforeSingletonCreation(DefaultSingletonBeanRegistry.java:347) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:219) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:202) at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:276) at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1304) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1224) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:640) ... 56 more
spring为什么解决循环依赖时用了三级缓存,用二级行不行?
我的理解,没有使用AOP的bean二级缓存完全够用,但是有了AOP,需要用三级缓存,也并不是说三级缓存是必须的,而是引入三级缓存为了使AOP场景下的bean生命周期标准化;至于三级缓存效率更高,我没觉得;
先看看三级缓存里面存储了什么:三級缓存中存储的是工厂对象,在AOP场景下该工厂返回代理对象,非AOP场景下返回的是源对象

protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { Object exposedObject = bean; // 存在AOP代理, 为原来的bean创建代理对象; 否则返回原对象 // AnnotationAwareAspectJAutoProxyCreator为AOP后置处理器 if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) { for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) { exposedObject = bp.getEarlyBeanReference(exposedObject, beanName); } } return exposedObject; }
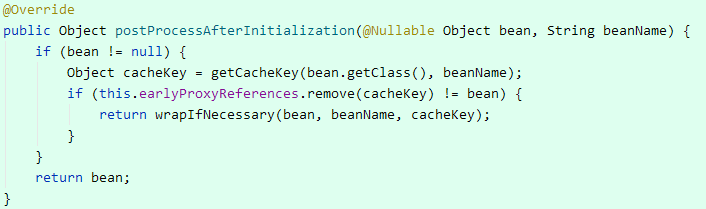
public Object getEarlyBeanReference(Object bean, String beanName) { Object cacheKey = getCacheKey(bean.getClass(), beanName); this.earlyProxyReferences.put(cacheKey, bean); // 如果需要返回代理对象 return wrapIfNecessary(bean, beanName, cacheKey); }
在初始化完成后,又调用了一次getSingleton方法,这里allowEarlyReference参数为false,也就是禁用三级缓存的含义;
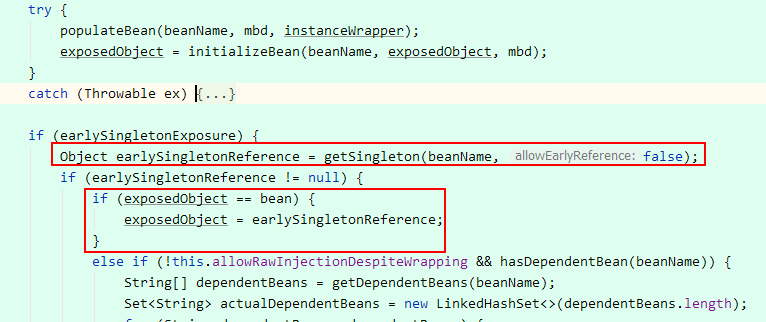
exposedObject == bean是恒等于的,除非没事闲的蛋疼,自定义了一个BeanPostProcessor,修改了bean;
PS:虽然AnnotationAwareAspectJAutoProxyCreator也是一种后置处理器,并且返回了代理对象,会造成bean的修改,不过这个后置处理器在执行postProcessAfterInitialization方法时,会判断代理对象是否存在,不存在则返回代理对象;
而在将bean存入三级缓存时,实际上就已经创建了代理对象;因此AnnotationAwareAspectJAutoProxyCreator不会影响exposedObject == bean
前面这一坨做个总结:B在注入A时,从三级缓存拿到A,并将A存入二级缓存;A在注入了B之后,从二级缓存将A实例取出(此时的实例是完整的),然后将A存入单例池singletonObjects
回到最开始的问题,为啥非得用三级缓存这个工厂对象,直接用二级缓存将对象暴露出去不可以么???三级缓存是为了延迟实例化期间生成代理对象;注:这里的三级缓存指的是一个lamba表达式

1、无论是否存在循环依赖,只要有AOP,那么注入的对象一定是代理对象;
2、不存在循环依赖时,如果只有二级缓存,那么先创建代理对象,然后存入二级缓存;这么早创建代理对象完全没必要并且违背AOP和spring结合的生命周期;
3、spring结合AOP的处理类是AnnotationAwareAspectJAutoProxyCreator,是一种后置处理器,并且要求在初始化后创建代理对象
4、因此引入三级缓存,提前暴露一个工厂对象,只有在循环依赖的时候才提前创建代理对象;
三级缓存真的提升了效率??
还是以A、B循环依赖为例,A被定义为切面,并开启aop代理
1、三级缓存场景

2、假设只有二级缓存场景

能够看到有无三级缓存只是创建A代理对象的时机不一样,并没有带来什么效率提升

 浙公网安备 33010602011771号
浙公网安备 33010602011771号