Python2和Python3编码问题-从底层出发
首先需要强调---无论是python2还是python3都可以理解成是Unicode编码,但是在电脑硬盘上存储是按照不同的映射关系的。
Python的encode和decode 首先明白一件事情,之前说过Unicode将所有的字符都对应上了相应的码点,而UTF-8或者ASCII码不过是对应从Unicode到字节的映射方式,既然有映射方式,那么就有映射方向。
我们把从Unicode到字节码(byte string)称之为encode,把从字节码(byte string)到Unicode码称之为decode
Python2
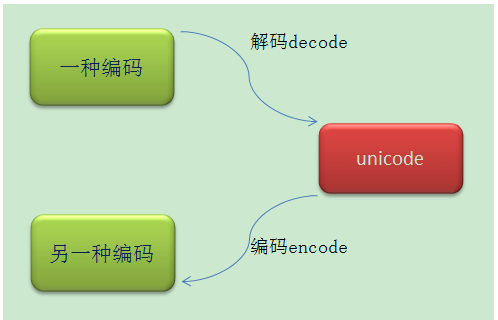
1.编码转换
- 编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
![]()
2.存储方式
python2中,有两种不同的字符串数据类型,
- 一种是 “str”对象,字节存储,
- 如果在字符串前使用一个’u’的前缀,表示的是这个字符的Unicode码点
- 详细说明
1. Python2 处理英文字符
>>> str='hello' #首先’hello'字符串的每个英文字符变换成unicode编码;在存储时python2对英文按照ascii射的方式编码存储5个字节编码
>>> str
'hello'
>>> type(str) #此时赋值给str,就是第一种: “str”对象,存储着字节
<type 'str'>
>>> len(str) #len字符数,就是一字节一英文字符
5
>>> str.decode('ascii') #'ascii'解码:按照ascii规则吧str英文字符由字节编码映射成字符编码,也就是把str对象类型变为unicode字符码
u'hello'
>>> str.decode('uTf-8') #'utf-8'解码:按照utf-8规则吧str英文字符由字节编码映射成字符编码,也就是把str对象类型变为unicode字符码
u'hello'
#结果为什么结果一样,因为对待英文字符AscII和utf-8都是按照一个字节存储的, 没有什么差别
>>> print(u'hello') #关于print 函数,无论字符unicode编码还是字节ascii编码都能正常输出
hello
>>> print(str)
hello
2.Python2处理中文字符
直接输入
>>> str="中国" #中文在python2中是按照gbk编码的;
>>> type(str)
<type 'str'>
>>> str #str仍然是一个str对象(字节存储)
'\xd6\xd0\xb9\xfa'
>>> len(str) #len函数处理str对象,是统计str字节的个数;因为str是字节编码的
4
以下是对str对象的解码操作;不难发现中文在python2中是按照gbk编码的
>>> str.decode('ascii') #'ascii'解码报错
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
str.decode('ascii')
UnicodeDecodeError: 'ascii' codec can't decode byte 0xd6 in position 0: ordinal not in range(128)
>>> str.decode('utf-8') #'utf-8'解码报错
Traceback (most recent call last):
File "<pyshell#17>", line 1, in <module>
str.decode('utf-8')
File "C:\Python27\lib\encodings\utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeDecodeError: 'utf8' codec can't decode byte 0xd6 in position 0: invalid continuation byte
>>> str.decode('gbk') #'gbk'解码成功
u'\u4e2d\u56fd'
>>> str1= str.decode('gbk') #str(gbk)字节编码 解码为 unicode字符编码 存到str1
>>> str1.encode('ascii') #str1 (unicode字符编码) 按照'ascii'编码 出错
#显然:ascii编码并不能处理unicode编码的中文,所以出错
Traceback (most recent call last):
File "<pyshell#25>", line 1, in <module>
str1.encode('ascii')
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
对于unicode编码的中文在python2中是按可以用'gbk','utf-8'编码的,但是不能被'ascii'编码
>>> str1.encode('gbk') #'gbk'编码
'\xd6\xd0\xb9\xfa'
>>> str1.encode('utf-8') #'utf-8'编码
'\xe4\xb8\xad\xe5\x9b\xbd'
print输出语句:再次证明:无论是unicode还是utf-8,gbk的字节编码都可以很好的输出
>>> print(u'\u4e2d\u56fd')
中国
>>> print('\xd6\xd0\xb9\xfa')
中国
>>> print('\xe4\xb8\xad\xe5\x9b\xbd')
中国
>>> str3=str1.encode('utf-8') #又一次证明:len函数对于字节编码,按照字节算个数
>>> len(str3)
6
u'字符串输入'
>>> str=u'中国'
>>> str
u'\u4e2d\u56fd'
>>> type(str)
<type 'unicode'>
>>> len(str)
2
又一次证明:len函数对于unicode编码,按照字符个数算
所以,对于python2,强烈建议在输入字符串加个u,按照unicode编码存储。
3. Python2程序开头写#coding=utf-8的作用
Python文件编译最终还是要转换成字节码,Python2程序开头写#coding=utf-8的作用其实就是把这个Python程序文件按照utf-8编码的方式映射到字节码,如果不加这个开头,程序里面的中文会按照Python默认的ascii码方式encode,这个肯定是要报错的,大家都知道,如果程序里写了中文但是没有加这个开头,那么pycharm会在一开始就报错,也是这个道理。加了这个开头之后,程序里面的字符都将会使用utf-8编码的方式被映射到字节码,也就是上一个大节里面的byte string,值得注意的是,程序中的汉字将会以utf-8的形式编码成为字节码,因此如果需要将其decode到Unicode字符,也是需要使用utf-8方式decode。
4.中文编码处理--补充
1.python2因为ascii对中文(unicode)编码解码错误
(1)错误写法:
原因:开头并没有改变Python的系统编码方式:Python2默认的编码解码方式是ascii码
s='中国'
s_decode=s.decode('utf-8')
ps=s_decode+s #字节编码与字符编码拼接最后是 字符编码;所以s字节编码需要解码,这时按照ascii码
print ps # 中文不能被'ascii'解码编码 ,出错
Traceback (most recent call last):
ps=s_decode+s
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
(2)解决办法:正确写法
>>> import sys
>>> reload(sys)
<module 'sys' (built-in)>
>>> sys.setdefaultencoding('utf-8')
>>> s_decode+s
u'\u4e2d\u56fd\u4e2d\u56fd'
这个代码将Python的编码默认编码方式由ascii码换成了utf-8编码,因此s_decode+s这个就不像上面一样报错了。
或则显示指明:
#coding=utf-8
s='中国'
s_decode=s.decode('utf-8')
ps=s_decode+s.decode('utf-8')
print ps
python test.py
中国中国
Python3
在python3 中 Python 3 也有两种类型,一个是 str(unicode), 一个是 byte 码。但是它们有不同的命名。
Python 3 中对 Unicode 支持的最大变化就是没有对 byte 字符串的自动解码。
如果你想要用一个 byte 字符串和一个 unicode 相连接的话,你会得到一个错误,不管包含的内容是什么。 可以简单理解为: python2 中的unicode -> python3 的str python2 中的str-> python3 的byte
py3里,只有 unicode编码格式 的字节串才能叫作str, 其他编码格式的统统都叫bytes,如:gbk,utf-8,gb2312…………
在py3中,Unicode编码就像是一个枢纽,例如gbk的格式要想转化成utf-8,那么必须先转化成Unicode,然后再从Unicode转化成utf-8
1. python3处理中文
>>> s="中"
>>> type(s)
<class 'str'>
>>> s
'中'
>>> len(s) #s是unicode编码 字符编码
1
>>> s.encode('utf-8')
b'\xe4\xb8\xad'
'''任何中文的unicod编码,都不能用ascii编码/解码'''
>>> s.encode('ascii')
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
s.encode('ascii')
UnicodeEncodeError: 'ascii' codec can't encode character '\u4e2d' in position 0: ordinal not in range(128)
>>> s1=s.encode('utf-8')
>>> s1
b'\xe4\xb8\xad'
>>> type(s1)
<class 'bytes'>
>>> s1.decode('utf-8') #只要是unicode(str对象)就可以直接输出
'中'
'''对于byte.decode()解码:python3不支持二进制形式解码,python2支持'''
#python3
>>>'\xe4\xb8\xad'.decode('utf-8')
Traceback (most recent call last):
File "<pyshell#11>", line 1, in <module>
'\xe4\xb8\xad'.decode('utf-8')
AttributeError: 'str' object has no attribute 'decode'
#python2
>>> '\xe4\xb8\xad'.decode('utf-8')
u'\u4e2d'
2. python3处理英文字符
>>> s='dv'
>>> s
'dv'
>>> len(s)
2
>>> s.encode('utf-8')
b'dv'
>>> s1= s.encode('utf-8')
>>> s2=s+s1
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
s2=s+s1
TypeError: can only concatenate str (not "bytes") to str
>>> s3=s+s1.decode('utf-8')
>>> s3
'dvdv'
3.文件操作
文件读写:open还是 codecs.open?
python读写文件估计大家都用open内置函数,但是用open方法打开会有一些问题。open打开文件只能写入str类型,不管字符串是什么编码方式。例如
>>> fr = open('test.txt','a')
>>> line1 = "我爱祖国"
>>> fr.write(line1)
这样是完全可以的。但是有时候我们爬虫或者其他方式得到一些数据写入文件时会有编码不统一的问题,所以就一般都统一转换为unicode。此时写入open方式打开的文件就有问题了。例如
>>> line2 = u'我爱祖国'
>>> fr.write(line2)
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
fr.write(line2)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-11: ordinal not in range(128)
怎么办,我们可以将上面的line2编码成str类型,但是太麻烦。我们要把得到的东西先decode为unicode再encode为str。。。
input文件(gbk, utf-8...) ----decode-----> unicode -------encode------> output文件(gbk, utf-8...)
代替这繁琐的操作就是codecs.open,例如
>>> import codecs
>>> fw = codecs.open('test1.txt','a','utf-8')
>>> fw.write(line2)
>>>
不会报错,说明写入成功。这种方法可以指定一个编码打开文件,使用这个方法打开的文件读取返回的将是unicode。写入时,如果参数 是unicode,则使用open()时指定的编码进行编码后写入;如果是str,则先根据源代码文件声明的字符编码,解码成unicode后再进行前述 操作。相对内置的open()来说,这个方法比较不容易在编码上出现问题。
还是文件读写操作
上文中介绍的codecs.open()方法虽然明显比open要方便好用很多,但是使用这个函数的前提是我们需要知道文件的编码方式,但是事实是我们大多数情况下不知道文件的编码方式,所以一下给出两种解决办法。
-
1.最原始的方法。
ways = ["utf-8","gbk","gb2312","ASCII","Unicode"] for encoding in ways: print(encoding) try: with codecs.open("test.csv","r",encoding=encoding) as f: data = f.read() print(type(data)) break except Exception as e: pass
将python中常用的编码方式用list表示,然后用for循环逐一带入检验。由于utf-8和gbk用的较多,所以建议放在list的最前面。
一旦文件操作成功,则break,跳出循环。
- 2.比较高端的方法
可以以bytes的形式对文件进行操作,这样即使不知道文件的编码方式也同样可以进行读写操作了,但是在最后需要进行decode或者encode。
如果对decode和encode不了解,请阅读这篇文章python编码问题之"encode"&"decode"
with codecs.open("test.csv","rb") as f:
data = f.read()
print(type(data))
encodeInfo = chardet.detect(data)
print(data.decode(encodeInfo["encoding"]))
参考文章:
- https://www.cnblogs.com/zhengaiao/p/13295654.html
- https://www.cnblogs.com/marsggbo/p/6622909.html
- https://www.cnblogs.com/hester/p/5465338.html
欢迎各位大佬指正!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号