基础数论知识点+例题
知识清单
欧拉函数
时间复杂度
O(√¯n)
欧拉函数的作用:
给定一个数n,求1 ~ n与n互质的数的个数。
互质:
两个数没有公共的质因数称之为互质。
欧拉函数:
φ(n)=n*(1-1/p1)(1-1/p2)(1-1/p3)*(1-1/p4)……(1-1/pk)
(其中p1,p2…pk就是n的质因子)
这个函数的证明简单说一下,1 ~ n中互质的数的个数=n-n与1 ~ n中有公因数的数的个数
那我们就可以n-是p1倍数的数(包括p1)-是p2倍数的数-…-是pk倍数的数
但是在减的过程中,如果一个数既是p1的倍数又是p2的倍数那么这个数就相当于被减了两次,所以再加上是p1和p2倍数的数的个数,(加上所有既是pi也是pj的倍数,pi,pj是质因数中任意两个数),那如果一个数既是p1的倍数还是p2,p3的倍数,那这个数在减去p1的倍数被减去一次,在减去p2,p3的倍数又被减去两次,而在加上p1和p2的倍数加上一次,p2和p3的倍数和p3和p1的倍数的倍数又加上两次,共三次,不加也不减,所以还要再减去p1,p2,p3的倍数,后面的类比这样的规律
就得到公式n-n/p1-n/p2-…n/pk+n/p1p2+n/p1p3+…+n/pk-1pk-n/p1p2p3-…
整理以后就是n*(1-1/p1)(1-1/p2)(1-1/p3)*(1-1/p4)……(1-1/pk)
这个详细证明可以参考容斥原理
题目链接–欧拉函数
#include<iostream>
using namespace std;
typedef long long ll;
int main()
{
int n; ll a;
cin >> n;
while (n--) {
cin >> a;
ll cnt = a;
for (int i = 2; i <= a / i; i++){
if (a % i == 0) {
cnt = cnt / i * (i - 1);
//这块不要写成cnt*(1-1/a)这样1/a==0,根据原式的推导个数是n/p取整
while (a % i == 0) a /= i;
}
}
if (a > 1) cnt = cnt / a * (a - 1);
cout << cnt << endl;
}
return 0;
}
筛法优化欧拉函数
上面的方法适用于单次求欧拉函数,如果是对一个范围内的数求欧拉函数,下面这种通过线性筛的方法更加适用。
对里面的几个细节进行一下说明就明白了:
- if(!vis[i]),说明i是质数,那么1~i-1这i-1个数都与i互质,所以ola[i]=i-1;
if (!vis[i]) {
prime[cnt++] = i;
ola[i] = i - 1;
}
- if (i % prime[j] == 0),那么prime[j]是i的质数,那么(1-1/prime[j])在ola[i]的式子里就已经出现了,所以这时候的prime[j]*i的质因数与i的质因数相同,根据欧拉函数的式子,所以ola[prime[j]*i]=ola[i]*prime[j];
if (i % prime[j] == 0) {
ola[prime[j] * i] = ola[i] * prime[j];
}
- 如果prime[j]不是i的质因数,那么prime[j]就是prime[j]*i的质因数,并且prime[j]在ola[i]的式子里没有出现过
所以ola[prime[j]i]=ola[i]prime[j](1-1/prime[j])=ola[i](prime[j]-1);
ola[prime[j] * i] = ola[i] * (prime[j] - 1);
#include<iostream>
using namespace std;
const int N = 1e6 + 5;
bool vis[N];
int prime[N], ola[N];
void get_eulers(int n)
{
ola[1] = 1;
int cnt = 0;
for (int i = 2; i <= n; i++) {
if (!vis[i]) {
prime[cnt++] = i;
ola[i] = i - 1;
}
for (int j = 0; prime[j] <= n / i; j++) {
vis[prime[j] * i] = true;
if (i % prime[j] == 0) {
ola[prime[j] * i] = ola[i] * prime[j];
break;
}
ola[prime[j] * i] = ola[i] * (prime[j] - 1);
}
}
}
int main()
{
int n;
cin >> n;
get_eulers(n);
long long sum = 0;
for (int i = 1; i <= n; i++)
sum += ola[i];
cout << sum;
return 0;
}
欧拉定理+费马小定理
欧拉定理
如果a和n互质,那么aφ(n)≡1(mod n)
先解释一下这个式子的意思:aφ(n)mod n=1mod n,或者说aφ(n)除以n,余数是1
费马小定理
费马小定理:ap-1≡ 1 ( m o d p ) (要求p是质数,因为如果p是质数,那么φ( p )=p-1. 是欧拉定理的一种特殊情况。
关于欧拉定理的证明,我不会呜呜…所以我找了一篇博客
原博客链接–https://blog.csdn.net/ymzqwq/article/details/96269772

就是想自己再写一遍证明:(这段可以自动忽略了)
假设x1,x2,x3…xφ(n)是 1~n 与n互质的数,这φ(n)个数必然两两不相等。因为x1,x2,x3…xφ(n)与n互质,且a与n互质,那么ax1,ax2,ax3…axφ(n)
那么ax1,ax2,ax3…axφ(n)每个数mod n 后仍与n互质(这个我不理解,以后知道了再补充吧),并且范围在1~ n,所以ax1,ax2,ax3…axφ(n)mod n后的这组数就是x1,x2,x3…xφ(n)这组数字,不过顺序可能发生变化,但是几个数相乘顺序不影响最终结果。
所以:(ax1*ax2*ax3…*axφ(n))mod n
=(aφ(n)(x1*x2*x3…*xφ(n)))mod n
=x1*x2*x3…*xφ(n),
等式两边x1*x2*x3…*xφ(n)一约,
所以aφ(n) mod n=1 mod n,
即 aφ(n)≡1(mod n)
辗转相除法(欧几里得算法)
这个算法是用来求最大公约数的,其实早在上大一的那个暑假就接触到了,但是当时不知道怎么证明,最近学到了它的证明方法,专门记录下来:
我们假设三个数a,b,c,c能整除a,c能整除b,那么c也可以整除a+b,甚至是k1a+k2b。
接下来我们想证明(a,b)的最大公约数与(b,a%b)的最大公约数相等:
a%b=a-a/b*b (a/b是整除)=a-kb,设a,b的最大公约数为r,那么r可以整除a,可以整除b,也就可以整除a-kb,所以r是b和a%b(a-kb)的最大公约数
就按照这样的操作,一直到b为0不再可以a%b。
y总永远的神!!!
#include<iostream>
using namespace std;
typedef long long ll;
ll gcd(int a, int b) {//a>b
return b ? gcd(b, a % b) : a;//如果b不为0执行:之前,如果为0执行冒号后面
}
int main()
{
int n; ll a, b;
cin >> n;
while(n--) {
cin >> a >> b;
cout << gcd(a, b) << endl;
}
return 0;
}
扩展欧几里得算法
在解释扩展欧几里得之前先提一个定理–裴蜀定理(也叫贝祖定理)
对于任意正整数a,b,都存在非零整数x,y,满足ax+by=gcd(a,b) (a,b的最大公约数),通过欧几里得算法的证明我们知道gcd(a,b)=gcd(b,a%b)
所以ax+by=gcd(a,b)=bx1+(a%b)y1=gcd(b,a%b)
a%b=a-(a/b)(整除)
所以ax+by=bx1+(a%b)y1=bx1+(a-(a/b))y1
ax+by=ay1+b(x1-(a/b)y1)
所以x=y1, y=x1-(a/b)y1 (x,y是当前值,x1,y1是递归函数返回来改变的值)
当b=0,a!=0,ax+by=gcd(a,b)=a,所以x=1,y=0
如果式子不是ax+by=gcd(a,b),而是ax+by=d,那么要判断是否有解,有解的前提是gcd(a,b)能够整除d
注意!这里求出来的解(x,y)并不唯一,
ax+by=gcd(a,b)
a(x-b/dk)+b(y+a/dk)=d
所以x=x0+k *b/d, y=y0-k *a/d都是解
题目链接–扩展欧几里得算法
代码倒是不难,难在公式的推导
#include<iostream>
using namespace std;
typedef long long ll;
void exgcd(ll a, ll b,ll &x,ll &y)
{
if (!b) {
x = 1, y = 0;
}
else {
exgcd(b, a % b, x, y);
ll tx = x, ty = y;
x = ty, y = tx - (a / b) * ty;
}
}
int main()
{
ll n, a, b, x, y;
scanf("%lld", &n);
while (n--) {
scanf("%lld %lld", &a, &b);
exgcd(a, b, x, y);
cout << x << " " << y << endl;
}
return 0;
}
再来一题
题目链接–线性同余方程
先对本题进行题意转换,将其变为扩展欧几里得算法
题目大概:
给定 n 组数据 a,b,m,对于每组数求出一个 x,使其满足 ax≡b(modm),如果无解则输出 impossible。
ax≡b(modm)可以转换为ax=my+b,ax-my=b
所以ax+my=b(x,y解不唯一,直接用y代替-y也可以),如果有解,根据扩展欧几里得算法,gcd(a,m)能够整除b,剩余的问题就转化为求解一组(x,y)满足ax+my=b
#include<iostream>
using namespace std;
typedef long long ll;
//ax+my=b
ll exgcd(ll a, ll b, ll &x, ll &y) {
//ax+by=bx+(a%b)y=bx1+(a-a/b*b)y1
//ax+by=ay1+b(x1-a/by1)
ll d;
if (!b) {
x = 1, y = 0;
return a;
}
else {
d=exgcd(b, a % b, x, y);
ll tx = x, ty = y;
x = ty, y = tx - a / b * ty;
}
return d;
}
int main()
{
ll n, a, b, m, x, y;
scanf("%lld", &n);
while (n--) {
scanf("%lld %lld %lld", &a, &b, &m);
ll d = exgcd(a, m, x, y);
if (b % d == 0) printf("%lld\n", x*(b/d)%m);
//这里记住还要mod m,不%m可能超过int,但是题目要求在int范围内(其他的原因暂时没想到)
else printf("impossible\n");
}
return 0;
}
快速幂
快速幂的作用就是快速求出akmod p的结果, 如果暴力计算,res=res*a mod p,时间复杂度是O(k),但如果是快速幂的话时间复杂度是log k,也就是说如果k=109,大概是log k=30
快速幂的核心思路是反复平方法
a = a * a % p;
算法思路是先预处理出a^ 20 mod p ,a^ 21 mod p…a^ 2^log k^ mod p 一个log k个
然后问题就是如何用上面预处理的数据组合
ak
=a^ 2i * a^ 2j * a^ 2k
=a^ (2i+2j+2k)
比如k=1078,k=1101102,所以k=21+22+24+25,如果二进制位位1就相乘
if (k & 1) res = res * a % p;
下一个问题,预处理怎么实现:
a^ 21=a^ 20 * a^ 20
a^ 22=a^ 21 * a^ 21
a^ 23=a^ 22 * a^ 22
…
a = a * a % p;
//mod是防止a*a超数据范围,数据溢出就会变成负的了,可以自己试一下,给个数据99 89 4
#include<iostream>
using namespace std;
typedef long long ll;
ll qmi(ll a, ll k, ll p)
{
ll res = 1;
while (k) {
if (k & 1) res = res * a % p;
a = a * a % p;
//因为公式是(a*res) % p = ((a % p) * (res % p)) % p;,所以a也要取模一次
k >>= 1;
}
return res;
}
int main()
{
ll n, a, k, p;
scanf("%lld", &n);
while (n--){
scanf("%lld %lld %lld", &a, &k, &p);
printf("%d\n", qmi(a, k, p));
}
return 0;
}
快速幂求逆元
先总结一下:逆元的作用就是用乘法代替除法,1/b≡1 * b-1(b-1就是逆元)
实现的效果,当计算k/b只需要计算k * b-1,两式同余的值是相同的
最长用的情况,模m为质数,那么根据费马小定理,b-1=bm-2,快速幂求逆元qim(b,m-2,m)
说一下逆元的定义:
若整数 b,m 互质,并且对于任意的整数 a,如果满足 b|a,则存在一个整数 x,使得 a/b≡a*x(modm),则称 x 为 b 的模 m 乘法逆元,记为 b−1(modm)。
b 存在乘法逆元的充要条件是b 与模数 m 互质。当模数 m 为质数时,bm−2 即为 b 的乘法逆元。
简单解释一下:
当前有三个整数a,b,m。b,m互质,如果b能够整除a,那么a/b也是一个整数,这时候存在一个整数x,满足a/b≡ax mod m,也就是对a/b取模与ax取模相同,这里的 x 就叫做 b 的模 m 乘法逆元,记为 b−1(mod m),记住是针对b的,而a/b取模与ax取模相等,a/b必然小于a(b是整数),ax必然大于a(x是整数),而ax mod m之后与a/b相等也就是说ax是大于m的。这样子理一下应该就能理解这个式子了。
那么继续,我们记x为b-1,那么就是a/b≡ab-1mod m(为什么要把式子这样弄呢,因为除法不如乘法好计算,所以我们就通过mod的方法使得除法转化为乘法)
a/b≡ab-1mod m 两边乘以b
b * a/b≡b * ab-1mod m
a≡b * ab-1mod m
≡a* bb-1mod m 两边同约去a
bb-1≡1 mod m (这里的b-1是整数,不是1/b,解释上面有)
如果m是质数,质数的欧拉公式(费马小定理)是 bφ(m)≡bm-1≡1 mod m
bm-1
≡1 mod m=b*b-1 ≡ b*bm-2
所以b-1=bm-2
当m为质数的时候直接使用费马小定理,m非质数时使用欧拉函数。
之前提到的:b 存在乘法逆元的充要条件是b 与模数 m 互质(题目已经给出m是质数,那如果b,m不是互质b就是m的倍数)
解释一下原因:b * x ≡ 1 (mod m) 如果b和m不互质,则 b * x肯定也是m的倍数,b * x%m=0,所以b%m=0 ,b不存在乘法逆元
题目链接–快速幂求逆元
下面代码的写法和快速幂基本一样
#include<iostream>
using namespace std;
typedef long long ll;
ll qim(ll a, ll k, ll m)
{
ll res = 1;
while (k) {
if (k & 1) res = res * a % m;
a = a * a % m;
k >>= 1;
}
return res;
}
int main()
{
ll n, a, p;
scanf("%lld", &n);
while (n--) {
scanf("%lld %lld", &a, &p);
if (a % p) printf("%lld\n", qim(a, p - 2, p));
else printf("impossible\n");
}
return 0;
}
中国剩余定理
对于2k个数 a1,a2…ak和 m1,m2…mk,假设整数m1,m2…mk两两互质,则对任意的整数: a1,a2…ak
满足一元线性同余方程组有解:
x≡a1 mod m1
x≡a2 mod m2
…
x≡ak mod mk
并且通解可以用如下方式构造得到::
设M是整数m1,m2…mk的乘积,并设Mi是除了mi以外的k- 1个整数的乘积,Mi=M/mi. 设 Mi-1 为 Mi 模mi 的逆元,根据a/b=a*x mod m(逆元),所以
Mi * Mi-1 ≡ 1 mod mi
x的通解形式为 x=(a1 *M1 *M1-1 + a2 *M2 *M2-1+…+ ak *Mk *Mk-1) mod p
p=a1a2…*ak
唯一解的话就再实行 x = x mod M
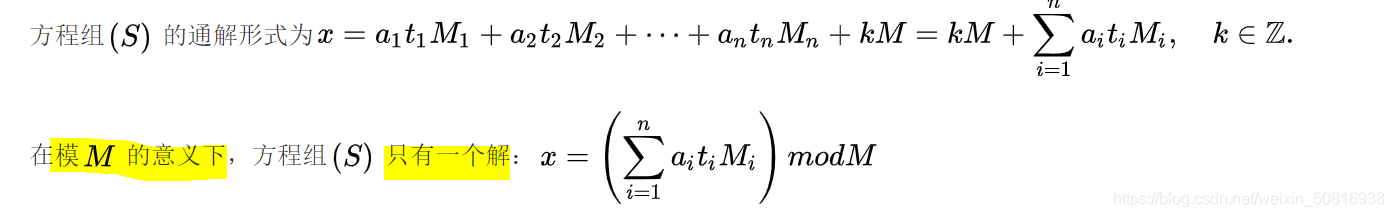
接着我们来验证一下这个式子是否成立:
对于x≡a1 mod m1
x mod m1= (a1 *M1 *M1-1 + a2 *M2 *M2-1+…+ ak *Mk *Mk-1) mod m1
因为 M1 * M1-1=1 ,a1与m1互质,所以a1mod m1=1,
而后面其他式子,因为M2 ~ Mk式子中都有m1,且Mi-i,ai都是 整数,Mi mod mi=0,
所以x mod m1 = 1,满足 x≡a1 mod m1(其余式子同样证明)
这个式子的应用举个例子吧,比如a={2,3,2},m={3, 5, 7},
M1=35,M1-1=2
M2=21,M2-1=1
M3=15,M3-1=1
x=(2352+3211+2151) mod 105=233 mod 105=23(x有唯一解,取最小满足条件的)
继续证明吧:
x≡a1 mod m1
x≡a2 mod m2
…
x≡ak mod mk
得到:
x+km1=a1
x+km2=a2
…
x+kmk=ak
我们先提出前两个式子
x+k1m1=a1
x+k2m2=a2
x=a1-k1m1=a2-k2m2
所以k2m2-k1m1=a2-a1,这个形式可以通过扩展欧几里得算法求出k1, k2(这里的k1,k2只是特解)
有解的条件是gcd(m2,m1)能够整除a2,a1,
k1,k2的通解分别为k1+k m2/d , k2+k m1/d (d=gcd(m1,m2) )
所以x=a1-(k1+k m2/d)m1=a1-m1k1+k m1m2/d ( [m1,m2]表示m1,m2的最小公倍数)
x=x0+ka ( x0=a1-m1k1,a=[m1,m2] )
x mod a = x0
这个就证明了求唯一解

题目链接–表达整数的奇怪方式
这篇题解感觉写的挺清楚
后面是自己理思路写的,如果觉得有点乱的话看上面那个链接的题解吧
本题a作为模,m作为余数
涉及的几个式子列一下
x=a1k1+m1=a2k2+m2
a1k1-a2k2=m2-m1,要想得到满足两式的x,已知a1,m1,所以要求k1,根据式子采用扩展欧几里得
得出解 k1+ka2/d,为了得到k1的最小解对k取模(为什么通解里有个/d,这个是之前学扩展欧几里得记得通解公式,相当于一个结论,为啥我还没搞明白)
找到解释了:

关于这里:为什么已经对k1取最小的特解了,在接下来的式子里k却存在说明一下:
因为当前的最小特解只是满足上述两个式子,但对接下来的式子不一定满足,所以要取通解代入,取最小特解是防止计算过程中数据溢出
x=(k1+ka2/d)a1+m1=k* a1a2/d+k1a1+m1
所以新的a1’=a1a2/d,m1’=k1a1+m1
#include<iostream>
using namespace std;
typedef long long ll;
ll exgcd(ll a, ll b, ll &x, ll &y) {
ll d;
if (!b) {
x = 1, y = 0;
return a;
}
else {
d = exgcd(b, a % b, x, y);
ll tx = x, ty = y;
x = ty, y = tx - a / b * ty;
}
return d;
}
int main()
{
int n;
ll a1, m1, a2, m2, k1, k2;
cin >> n;
cin >> a1 >> m1;
bool has_answer = true;
for (int i = 1; i < n; i++) {
cin >> a2 >> m2;
ll k1, k2;
ll d = exgcd(a1, a2, k1, k2);
if ((m2 - m1) % d) {//存在解的条件是m2-m1是d的倍数
has_answer = false;
}
k1 *= (m2 - m1) / d;
ll t = a2 / d;
k1 = (k1 % t + t) % t;//求解的k1只是满足式子的一个解,为了防止计算过程中出现溢出,则需要在通解k1中选出一个尽可能小的特解,通过取模t
m1 = k1*a1 + m1;//这个得在a1前变
a1 = a1 * a2 / d;
}
if (!has_answer) cout << -1;
else cout << (m1 % a1 + a1) % a1;//x=k1a1+m1,对x取模a1=对m1取模a1
return 0;
}
芜湖…总算把代码搞定了,我菜死了
高斯消元
解线性方程组
其实思路很简单,就是线性代数的知识,通过将矩阵化简为最简行列式求解(忽然发现线性代数我已经忘差不多了,这才半年啊!半年!对不起lyh和sh,知识全还给他们了)
思路很简单,代码实现起来还是有点绕的
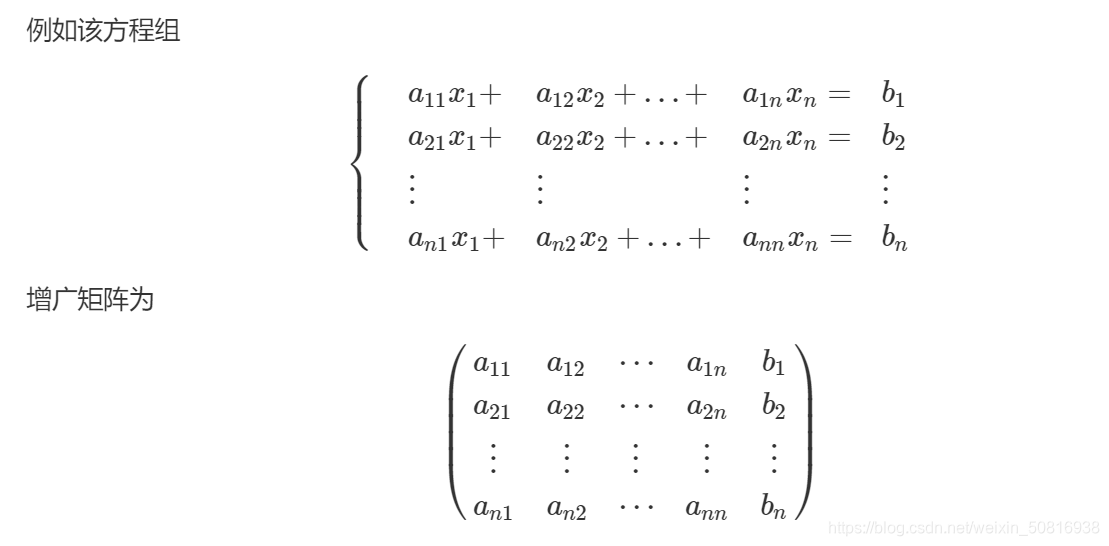
先说一下思路 :(就是线性代数的思路)
- 找到每一列数据的绝对值的最大值所在行数
- 将该行数据首元素更新为1,其余数据等比例减小,使该行现数据是原数据的倍数
- 将该行数据上移
- 运用该行数据更新未上移的行数据,该列(循环是按列执行)元素置0,其余列数据相应减小
- 重复以上动作
- 判断解的个数,如果有唯一解,用元素最少的行减其余行,得出最终解
然后关于解的处理:
有三种情况:唯一解,无解,不止一个解
唯一解的话就要求变换后的矩阵满足上三角行列式,无解的话就是左边式子为0,右边式子非0,不止一个解就出现有式子左右都为0.
关于eps
因为c++存数据的时候是有误差大,比如存0可能时0.0000000xxx,所以设置一个比较小的数来特判,默认绝对值小于1e-6的均为0.
题目链接–高斯消元解线性方程组
#include<iostream>
#include<math.h>
using namespace std;
const int N = 100;
double a[N][N + 1];
int n;
const double eps = 1e-6;
int gauss()
{
int i, j;
for (i = 0, j = 0; j < n; j++)//i为行,j为列(每次操作对应新的一行一列)
{
int Max = i;
for (int k = i + 1; k < n; k++)//找当前列的最大值所在行,这里的k是行
if (fabs(a[k][j]) > fabs(a[Max][j])) Max = k;
if (fabs(a[Max][j]) < eps) continue;
//该行系数在之前更新时被消除了(上下两式成比例,抵消)
for (int k = n; k >= j; k--) {//该行首元素置1,上移,这里的k是列
a[Max][k] /= a[Max][j];
swap(a[i][k], a[Max][k]);
}
for (int h = i + 1; h < n; h++)//将未跟新的行当前列清0,
for (int l = n; l >= j; l--)
a[h][l] -= a[i][l] * a[h][j];
i++;
}
//判断解
if (i < n) {//左式为0不满足上三角行列式(存在上下式子未知数系数成比例,抵消)
for (int k = i; k < n; k++)
if (fabs(a[k][n])>eps) return 0;//右式非0,等式不成立,无解
return 2;//多组解
}
for (int i = n - 1; i >= 0; i--)//减数
{
for (int j = i - 1; j >= 0; j--)//被减数
a[j][n] -= a[i][n] * a[j][i];
}
return 1;//唯一解
}
int main()
{
cin >> n;
for (int i = 0; i < n; i++)
for (int j = 0; j <= n; j++)
cin >> a[i][j];
int ans = gauss();
if (ans == 1)
for (int i = 0; i < n; i++)
printf("%.2f\n",a[i][n]);
else if (ans == 2) cout << "Infinite group solutions" << endl;
else cout << "No solution";
return 0;
}
再来个2.0版,重写了一份,这份没有注释,把消元那块合并了一下
#include<iostream>
#include<cstdio>
#include<cmath>
using namespace std;
const int N = 100;
const double eps = 1e-6;
double a[N][N + 1];
int n;
int gauss()
{
int h, l;
for (h = 0, l = 0; l < n; l++) {
int maxp = h;
for (int i = h + 1; i < n; i++)
if (fabs(a[i][l]) > fabs(a[maxp][l])) maxp = i;
if (fabs(a[maxp][l]) < eps) continue;
for (int j = n; j >= l; j--){
a[maxp][j] /= a[maxp][l];
swap(a[maxp][j], a[h][j]);
}
for (int i = 0; i < n; i++)//这里合并了一下,直接求解
for (int j = n; i != h && j >= l; j--)
a[i][j] -= a[h][j] * a[i][l];
h++;
}
if (h < n) {
for (int i = h; i < n; i++)
if (fabs(a[i][n]) > eps) return 0;
return 2;
}
return 1;
}
int main()
{
cin >> n;
for (int i = 0; i < n; i++)
for (int j = 0; j <= n; j++)
cin >> a[i][j];
int ans = gauss();
if (ans == 1)
for (int i = 0; i < n; i++)
printf("%.2f\n", a[i][n]);
else if (ans == 2) cout << "Infinite group solutions" << endl;
else cout << "No solution" << endl;
}
解异或线性方程组
思路和解线性方程组差不多
步骤(化最简行列式):
- 找出每列的第一个系数为1的所在行pos
- 将该行pos移到未处理行中第一行位置h,两行交换
- 将除该行h外所有行i当前列 l 为1的该列 l 置为0
if (m[i][l]&&i!=h)
for (int j = l; j <= n; j++) m[i][j]^=m[h][j] - 判断解的情况,输出解
#include<iostream>
using namespace std;
const int N = 105;
int m[N][N];
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++)
for (int j = 0; j <= n; j++)
cin >> m[i][j];
//化最简行列式
int l, h;
for (l = 0, h = 0; l < n; l++) {
int pos = -1;
//找出每列的第一个系数为1的所在行pos
for (int i = h; i < n; i++)
if (m[i][l]) {
pos = i;
break;
}
if (pos == -1) continue;
//将该行pos移到未处理行中第一行位置h,两行交换
for (int j = l; j <= n; j++)
swap(m[pos][j], m[h][j]);
//将除该行h外所有行i当前列 l 为1的该列 l 置为0
for (int i = 0; i < n; i++) {
if (m[i][l]&&i!=h)
for (int j = l; j <= n; j++) {
m[i][j] ^= m[h][j];
}
}
h++;
}
// 判断解的情况,输出解
if (h < n) {
int sign = 1;
for (int i = h; i < n; i++)
if (m[i][n]) {
cout << "No solution" << endl;
sign = 0;
}
if (sign) cout << "Multiple sets of solutions" << endl;
}
else
for (int i = 0; i < n; i++)
cout << m[i][n] << endl;
return 0;
}
组合数
小数据组合数 O(N2)
小数据指的时C(a,b) (a>=b)中a,b数据范围较小
采用的是dp的思想+组合数的这个性质C(n,m)=C(n-1,m-1)+C(n-1,m)
这个性质简单说一下:C(n,m)看作是n个苹果中拿m个,那么也就等于这两种情况的和:1.从n个苹果中拿走一个,这个苹果不在m里面,C(n-1,m),那么就从剩下的n-1里拿m个,2.或者这个苹果包含在这m个呢,也就是C(n-1,m-1);
所有C(n,m)=C(n-1,m-1)+C(n-1,m)
#include<iostream>
using namespace std;
typedef long long ll;
const int N = 1e5, mod = 1e9 + 7;
int fact[N+1], infact[N+1];
int qmi(int a, int k, int p)
{
int res = 1;
while (k) {
if (k & 1) res = (ll)res * a % p;
a = (ll)a * a % p;
k >>= 1;
}
return res;
}
int main()
{
fact[0] = infact[0] = 1;
for (int i = 1; i <= N; i++) {
fact[i] = (ll)fact[i - 1] * i % mod;
infact[i] = (ll) qmi(fact[i], mod - 2, mod) % mod;
//也可以写成 infact[i] = (ll)infact[i - 1] * qmi(i, mod - 2, mod) % mod;
}
int n, a, b;
cin >> n;
while (n--) {
cin >> a >> b;
cout << (ll)fact[a] * infact[a - b] % mod * infact[b] % mod << endl;
//*,%,/运算符的优先级都是从左往右
}
return 0;
}
稍大一些数据 O(n log n)
这个运用的就是组合数的基础公式
- 问题1–关于逆元存在的意义
因为电脑储存数据有限,所以在对数据进行处理的时候通过取模保证数据在范围内,所以处理除法计算的时候采用逆元
(a + b) % p = (a%p + b%p) %p (对)
(a - b) % p = (a%p - b%p) %p (对)
(a * b) % p = (a%p * b%p) %p (对)
(a / b) % p = (a%p / b%p) %p (错)—>转换成逆元计算
- 问题2–为什么可以用费马小定理
因为本题中mod 为1e9+7是个质数,可以运用费马小定理,得到求逆元的公式是
a*ap-2≡1 % mod
- 问题3–关于强制类型转换的优先级
为什么这样写就是对的:
cout << (ll)fact[a] * infact[a - b]%mod * infact[b] % mod << endl;
这样是错的:
cout << (ll)(fact[a] * infact[a - b]%mod * infact[b] % mod) << endl;
括号的优先级是最高的,对于第一个式子,先执行ll的类型转换,讲fact[a]转换为long long类型,long long x int=long long,这样就保证相乘过程中数据不会爆掉,但是如果采用第二个写法,先执行括号内部的计算,int x int的数据范围还是int,但如果结果是long long数据就爆掉了,这时候再执行强制类型转换也就没效果了
#include<iostream>
using namespace std;
typedef long long ll;
const int N = 1e5, mod = 1e9 + 7;
int fact[N+1], infact[N+1];
int qmi(int a, int k, int p)
{
int res = 1;
while (k) {
if (k & 1) res = (ll)res * a % p;
a = (ll)a * a % p;
k >>= 1;
}
return res;
}
int main()
{
fact[0] = infact[0] = 1;
for (int i = 1; i <= N; i++) {
fact[i] = (ll)fact[i - 1] * i % mod;
infact[i] = (ll)infact[i - 1] * qmi(i, mod - 2, mod) % mod;
//也可以写成 infact[i] = (ll)qmi(fact[i], mod - 2, mod) % mod;
//这样写应该更好理解
}
int n, a, b;
cin >> n;
while (n--) {
cin >> a >> b;
cout << (ll)fact[a] * infact[a - b]%mod * infact[b] % mod << endl;
}
return 0;
}
数据爆大 O(p log N log p)
本题a,b的数据达到1018,如果用上一种方法时间复杂度是O(N log N),时间复杂度太高了,这时候采用卢卡斯定理,可以把时间范围减小到
(n组数据)*p logp N log p=105 *20 *20=4 *107(大概)(注意一下, logp N 和 log p不会同时取极值,计算时间的时候注意一下就行)
卢卡斯定理:C(a,b)=C(a%p,b%p)*C(a/p,b/p)
证明一下吧,虽然我不想写:
我们把a,b转化成类似p进制
a=a0p0+a1p1+…+akpk
b=b0p0+b1p1+…+bkpk
(1+x)k=C(k,0)x0+C(k,1)x1+…+C(k,k-1)xk-1+C(k,k)xk
所以(1+x)k %p=C(k,0)x0+C(k,k)xk=1+xk
即(1+x)k ≡(1+xk)mod p
所以(1+x)a =((1+x)p0)a0 * ((1+x)p1)a1 …((1+x)pk-1)ak-1 *((1+x)pk)ak
(1+x)a≡(1+xp0)a0 * (1+xp1)a1 …(1+xpk-1)ak-1 *(1+xpk)ak mod p
求左边式子xb的系数:
C(a,b)=C(a0,b0) * C(a1,b1) * … * C(ak,bk);
也就得到:
C(a,b)=C(a%p,b%p)*C(a/p,b/p)
a=a/p * p1+a%p * p0
b=b/p * p1+b%p * p0
#include<iostream>
using namespace std;
typedef long long ll;
int qim(int a, int k, int p)
{
int res = 1;
while (k) {
if (k & 1) res = (ll)res * a % p;
a = (ll)a * a % p;
k >>= 1;
}
return res;
}
int C(ll a, ll b, int p)
//C(a,b)=a!/(b!*(a-b)!)=a(a-1)...(b+2)(b+1)/(1*2*3*...*(a-b))
{
int res = 1;
for (int i = 1; i <= a - b; i++) {
res = (ll)res * (i + b) % p;
res = (ll)res * qim(i, p - 2, p) % p;//快速幂求逆元
}
return res;
}
int lucas(ll a, ll b, int p)
{
if (a < p && b < p) return C(a, b, p) % p;
else return (ll)C(a % p, b % p, p) * lucas(a / p, b / p, p) % p;
}
int main()
{
int n, p;
ll a, b;
cin >> n;
while (n--) {
cin >> a >> b >> p;
cout << lucas(a, b, p) << endl;
}
return 0;
}
精确计算组合数(计算后数据超计算机所允许的数据范围–高精度)
#include<iostream>
using namespace std;
int n[20000] = { 1 };
int pos = 0;
void mul(int x)
{
int t = 0;
for (int i = 0; i <= pos; i++) {
n[i] = n[i] * x + t;
t = n[i] / 10;
n[i] %= 10;
}
while (t) {
n[++pos] = t % 10;
t /= 10;
}
}
void div(int x)
{
int t = 0;
for (int i = pos; i >= 0; i--) {
t = t * 10 + n[i];
n[i] = t / x;
t -= n[i] * x;
}
while (!n[pos]) pos--;
}
void C(int a, int b)
{
for (int i = 1; i <= a - b; i++) {
mul(b+i);
div(i);
}
}
int main()
{
int a, b;
cin >> a >> b;
C(a, b);
for (int i = pos; i >= 0; i--)
cout << n[i];
return 0;
}
上面的这个方法纯套组合数的公式,接着对上面这个方法进行优化一下,但本质还是高精度运算
说一下下面这个优化的思路:
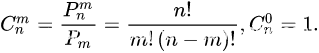
上面做法的计算有乘有除,那如果在进行高精度计算之间就把分子分母的抵消完成,就只剩乘法。
问题也就转换到提取分字分母的公约数,使他们相互抵消,关键就在下面这个函数
举个例子应该就明白了,假设x为8,p为2
x!=1* 2* 3* 4* 5* 6* 7* 8,含有因子2的只有2,4,6,8
初始x=8,x/2=4,这里的4就表示1-8中能被2整除的有四个数,接着x/2=4,4/2=2,这时候表示1-8中能被4整除的有两个,是4,8,接着x/2=2,x/2=1,也就是说1-8中能被8整除的有1各,就是8.
1-8被2整除的是4个
1-8被4整除的是2个,这个数也能被2整除
1-8被8整除的是1个,这个数也能被2,4整除
所以8!中包含6个2相乘
其实就是对1-8中的任意一个数统计包含几个2,就像8,在包含一个2中入选,在包含两个2中入选,在包含3个2又入选,所以8就包含3个2,而4在包含3个2的时候落选所以只包含两个2,每次循环的x/=p就是在判断一个数包含几个2.
int get(int x, int p)
{
int res = 0;
while (x) {
res += x / p;
x /= p;
}
return res;
}
这个函数说完以后
通过sum[i] = get(a, p) - (get(a - b, p) + get(b, p))就可以把分子分母中相同因子相互抵消,是整个式子C(a,b)在计算过程中只存在乘法
为什么分子分母抵消以后一定只剩分母,参考组合数的拿苹果那个案例,是从a个苹果中拿b个,问有多少种拿法,拿法一定是整数种,既然是整数,那么分字分母抵消后一定只有分子。
换一个方法证明:
证明组合数是整数,其实就是说组合数的分母能整除分子。你来想一想,a!被b!抵消部分以后,分字分母剩余数个数相同,分子从b+1开始,分母从1开始,2个连续的数里,有一个是2的倍数。3个连续的数里,有一个是3的倍数。以此类推,这样,在分子中就能“找到”所有的分母。分母就能整除分子了。
#include<iostream>
using namespace std;
const int N = 5005;
int prime[N], cnt, sum[N];
bool vis[N];
int n[20000] = { 1 }, pos = 0;
void get_prime(int n)//将1-a所有素数筛出来
{
for (int i = 2; i <= n; i++)
{
if (!vis[i]) prime[cnt++] = i;
for (int j = 0; prime[j] <= n / i; j++) {
vis[i * prime[j]] = true;
if (i % prime[j] == 0) break;
}
}
}
int get(int x, int p)
{
int res = 0;
while (x) {
res += x / p;//表示在[1,x]之间有几数能被p整除数
x /= p;
}
return res;
}
void mul(int k)
{
int t = 0;
for (int i = 0; i <= pos; i++) {
n[i] = n[i] * k + t;
t = n[i] / 10;
n[i] %= 10;
}
while (t) {
n[++pos] = t % 10;
t /= 10;
}
}
int main()
{
int a, b;
cin >> a >> b;
get_prime(a);
for (int i = 0; i < cnt; i++) {
int p = prime[i];
sum[i] = get(a, p) - (get(a - b, p) + get(b, p));
}
for (int i = 0; i < cnt; i++)
for (int j = 0; j < sum[i]; j++)
mul(prime[i]);
for (int i = pos; i >= 0; i--)
cout << n[i];
return 0;
}
碎碎念
芜湖~总算把四种组合数类型整理完了,数论简直让人头秃,我再也不敢说自己就数学能看,之前学的数学比起数论这块的就是渣渣,原来我竟是全学科辣鸡呜呜呜
卡特兰数
卡特兰数的基本模型:
给定 n 个 0 和 n 个 1将按照某种顺序排成长度为 2n 的序列,序列满足任意前缀序列中 0 的个数都不少于 1 的个数。
要解决整个问题dp应该也是可以实现的,但现在我没试,因为dp我还没学hh
也不知道是哪个大神想出的方法,真的是女少口阿!
先大概文字叙述一下,我们要达到(n,n)这个位置,可以向右走也可以向上走,向右看作0,向上看作1,要求任意前缀序列中0的个数都大于等于1的个数,也就是到任意位置时,向右的步数都大于等于向上的步数,我们把它放到坐标上,就是在任意坐标位置,满足x>=y;
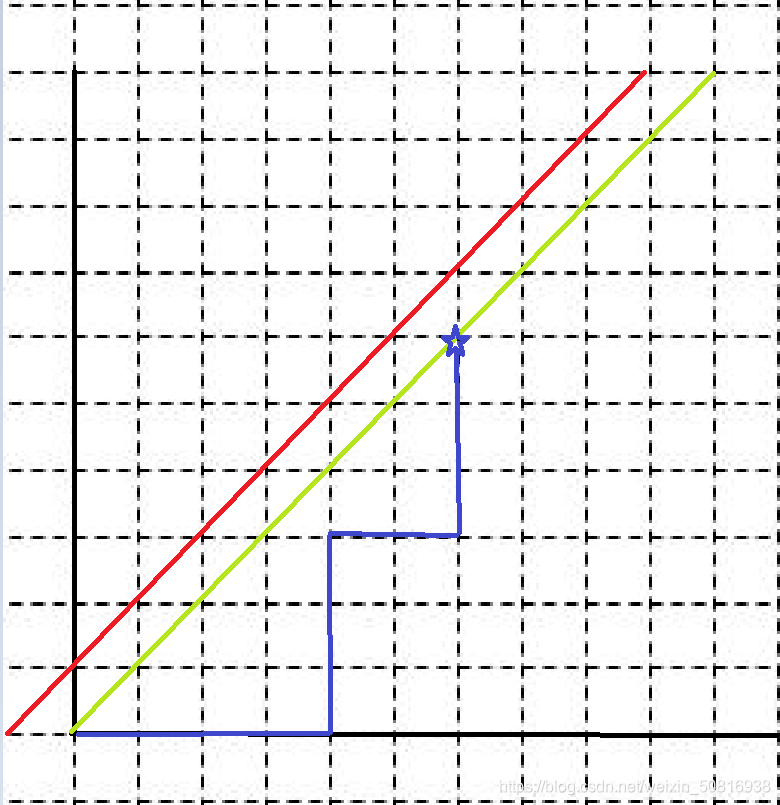
如图,当n=6,蓝色路径 就是一条满足题目要求的路线,也就是说,对于任意路径,都可以走在绿色线上和绿色线下方,一旦经过红色线该路径就不合法
合法路径数=总路径数-不合法路径数,
12步路,路径的不同就在于向右走向上走先后顺序的不同,所以总路径数等于C(12,6),十二个步子中选6步为向右走【C(2n,n)】
接下来的问题就在于怎么求不合法路径
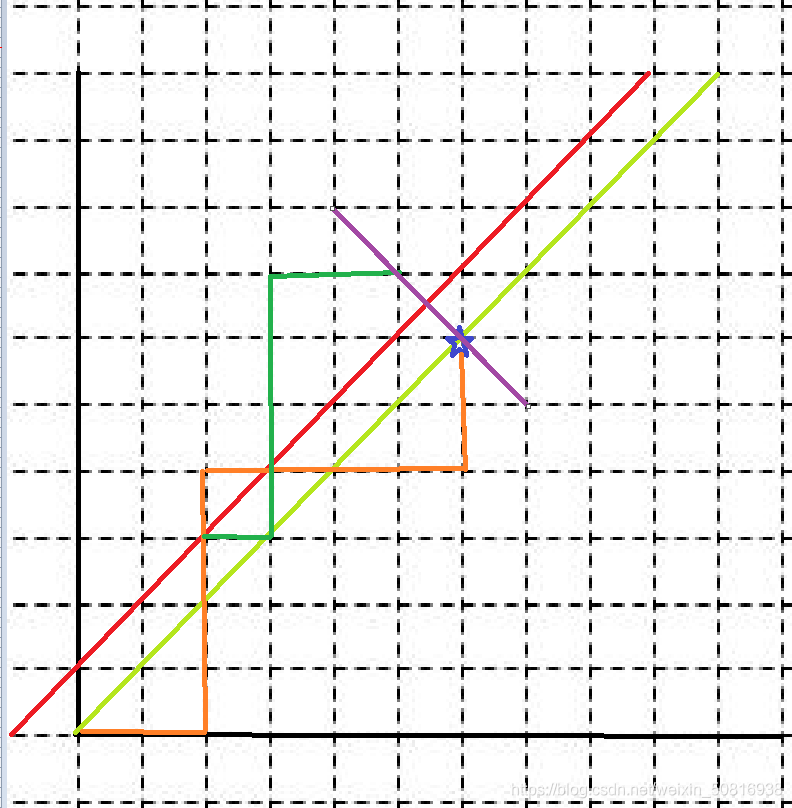
任意经过红线但是最终能到达(6,6)的路径都是不合法的,取路径经过红线的第一个点,从该点后的所有路径都关于红线做对称,发现无论路径怎么变化,只要经过红线,做的对称点都在(5,7),因为(5,7)于(6,6)关于y=x对称,也就是只要过线的路径和到(5,7)的路径是相联系的。
所以不合法路径就是C(12,5)【C(2n,n-1)】
所以合法路径
=C(2n,n)-C(2n,n-1)
=2n!/(n!* n!)-2n!/(n-1!* n+1!)
=(n+1)* 2n!/(n+1!* n!)-n* 2n!/(n!* n+1!)
=2n! / (n!* n+1!)
=n+1* 2n! / (n!* n!)
=C(2n,n)/n+1
#include<iostream>
using namespace std;
const int mod = 1e9 + 7, N = 1e5 + 5;
typedef long long ll;
int fact[N], infact[N];
int qim(int a, int k, int p)
{
int res = 1;
while (k) {
if (k & 1) res = (ll)res * a % p;
a = (ll)a * a % p;
k >>= 1;
}
return res;
}
void Inti(int n)
{
infact[0] = fact[0] = 1;
for (int i = 1; i <= 2 * n; i++)
fact[i] = (ll)fact[i - 1] * i % mod;
infact[n] = (ll)qim(fact[n], mod - 2, mod) % mod;
}
int main()
{
int n;
cin >> n;
Inti(n);
cout << (ll)fact[2 * n] * infact[n] % mod * infact[n] % mod * qim(n + 1, mod - 2, mod) % mod;
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号