(本文仅作为学习记录)
01. 之前知识点回顾
02. 装饰器
03. 内置函数
04. 模块
01. 之前知识点回顾
global,nonlocal
三元运算符
推导式:列表[i for i in range(3)],字典{i:i+1 for i in range(3)},集合{i for i in range(3)},生成器(i for i in range(3))
迭代器,生成器,装饰器
函数的参数: 形参:(位置参数,动态位置参数,默认参数,动态默认参数);实参:(位置参数,关键字参数)
函数返回值,注释和执行过程,打散与聚合
02. 装饰器
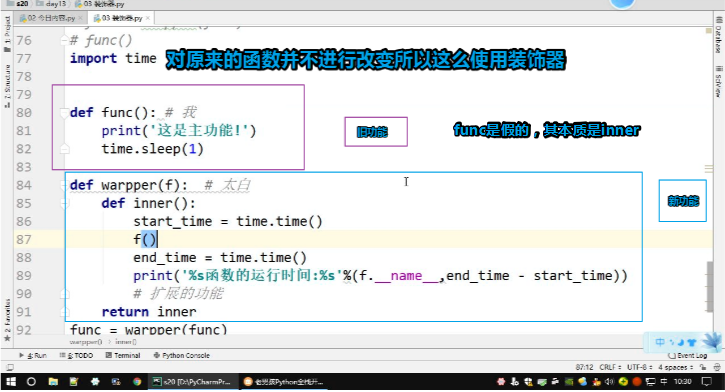
1.装饰器要看到其本质
所谓装饰器就是为了不破坏原有函数运行情况的时候,给它在外面再套一个函数罢了。
def func(): print('这是主功能') def warpper(f): print('这是新功能!') return f func = warpper(func) func()
2.装饰器原则
开放封闭原则:
对拓展开放,对修改源码封闭,不改变调用方式
def warpper(f): # 接受被装饰的函数内存地址 def inner(*args,**kwargs): # 接受被装饰函数的参数 start_time = time.time() # 新功能 ret = f(*args,**kwargs) # 调用被装饰的函数,被装饰参数带上 end_time = time.time() print('%s函数的运行时间:%s'%(f.__name__,end_time - start_time)) return ret # 被装饰的函数返回值 return inner @warpper # func = warpper(func) 语法糖 def func(*args,**kwargs): print(args) # 打印被装饰的函数参数 print('这是主功能!') time.sleep(1) return '大妈' # 返回值 ret = func(5) #ret = func(5) == inner(5) 返回值 func(5) print(ret) # 被装饰的函数返回值
注意,@warpper是语法糖。
F = True #step 1 装饰器的开关变量 def outer(flag): #step 2 def wrapper(func): #step 4 def inner(*args,**kwargs): #stpe 6 if flag: #step 9 print('before') #step 10 ret = func(*args,**kwargs) #step 11 执行原函数 print('after') #step13 else: ret = func(*args,**kwargs) print('123') return ret #step 14 return inner #step 7 return wrapper #step 5 @outer(F) #先执行step 3 :outer(True)这个函数,然后step 6:@wrapper #此处把开关参数传递给装饰器函数 def hahaha(): pass #step 12 hahaha() # step 8 相当于inner()
import time def warpper(f): def inner(*args,**kwargs): start_time = time.time() f(args,kwargs) end_time =time.time() print('%s函数的运行时间是:%s'%(f.__name__,end_time - start_time)) return inner @warpper def func(*args,**kwargs): print('主函数') func(1)
03. 内置函数
内置函数链接:https://docs.python.org/zh-cn/3.7/library/functions.html
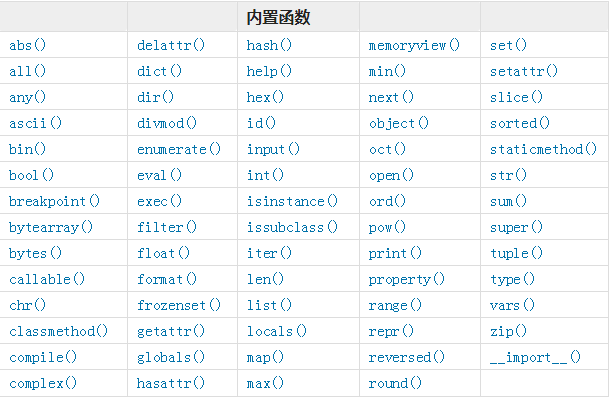
# print(abs(-98)) # 求绝对值 正的负的 出来后全都是正的 ** # print(all([1,0,3,4])) # all 判断元素中都为真的才是真 * # print(any([1,False,0])) # any 判断元素中只要有一个为真就是真 * # print(bin(10)) # 将10进制转行2进制 ** # print(bytes('你',encoding='utf-8')) * # print(callable(func)) # 检查这个对象是否可以调用 ** # print(chr(65)) # 输入数字,返回对应的ascii表位上对应的内容 ** # print(complex(8)) # 复数 * # print(dir([1,2])) # 查看对象的所有方法 *** # print(divmod(5,2)) # 返回一个元组,元组的第一个元素是商,第二个元素是余数 ** # for i,em in enumerate(li,1): # enumerate不写值默认是0 **** # print(globals()) # 查看全局都哪些内容 ** # print(hash([1,2,3])) #求对象的哈希值 * # print(hex(33)) # 将10进制转换成16进制 * # print(id('s')) # 查看数据的内存地址 *** # print(input(">>>")) # 获取用户输入的内容 ***** # print(int()) # 将数据转换成整型 ***** # print(isinstance([1,2,3],str)) #判断这个数据时什么类型 *** # iter # 判断是不是可迭代对象 *** # len() # 获取数据的长度 ***** # list() # 转换成一个列表 *** # def func(): # a = 1 # print(locals()) # 查看局部空间的内容 *** # # func() # print(max(1,2,3,4,5)) # 求最大值 *** # print(min(1,2,3,4)) # 求最小值 *** # print(memoryview(b'a')) # 查看字节的内存地址 # print(next()) # 迭代器中的取下一个值 *** # print(oct(9)) # 将10进制转换成8进制 ** # print(ord('中')) # 输入的是unicode编码的内容 ** # print(chr(20013)) # 输入的是unicode的内容 ** # print('123') # 是处理后给你显示的 ***** # print(repr('123')) # 显示的是原数据 *** # print(list(reversed())) # 反转 元组,列表,字符串 **** # print(round(5.472343212,3)) #四舍五入 *** # print(sum({1:4,2:5})) #求和 *** # print(list(zip(li,ls,lst))) #拉链 **** # 重要的:************************************************* # 匿名函数: # lambda 关键字 x参数:x是返回值 # 一行函数 用于简单需求 # print((lambda x:x)(5)) # lambda 的返回值只能是一个 # f = lambda x,y:x*y # print(f.__name__) #<lambda> # print(f(5,6)) # print(sorted([7,2,3,4],reverse=True)) # li = ['你好啊','我好','大家都挺好'] # def func(li): # return len(li) # print(sorted(li,key=func)) # key指定一个排序的规则 # print(sorted(li,key=lambda x:len(x))) # li = [ # {'age':19}, # {'age':52}, # {'age':48}, # {'age':30}, # ] # def func(li): # return li['age'] # print(sorted(li,key=func)) # print(sorted(li,key=lambda x:x['age'])) # li = [1,2,3,4] # # def func(a): # if a > 2: # return a # print(list(filter(func,li))) # def func(li): # for i in li: # if i > 2: # print(i) # # func(li) # li = [1,2,3,4] # # print(list(filter(lambda x:x>2,li))) # li = [1,2,3,4,5] # # def func(i): # return i+10 # print(list(map(func,li))) #映射 # li = [1,2,3,4,5] # print(list(map(lambda x:x+10,li))) # from functools import reduce # # li = [1,2,3,4,5] # # def func(x,y): # x=12345 # return x*10+y # reduce 是做累计算的 # print(reduce(func,li))
04. 上述知识点总结
# 1.装饰器: # 原则: # 对扩展开发 # 对修改封闭 # 不改变调用方式 # def warpper(f): # 接受被装饰的函数 # def inner(*args,**kwargs): #接受参数 # ret = f(*args,**kwargs) # return ret # return inner # # @warpper # def func(): # pass # # func() # from functools import wraps # # def log(flag): # def warpper(f): # 接受被装饰的函数 # if flag: # @wraps(f) # def inner(*args,**kwargs): #接受参数 # """ # 这是inner的注释 # :param args: # :param kwargs: # :return: # """ # print('这是一个装饰器') # ret = f(*args,**kwargs) # return ret # return inner # else: # return f # return warpper # # # @log(True) # func = log(False) # def func(): # """ # 这是func函数 # :return: # """ # print(1) # # func() # print(func.__doc__) # 装饰器:应用场景 后期框中会大量出现, 面向对象会出现 登录认证的时候 # 内置函数: # lambda 匿名函数 这个函数真的没有名字 # 一行函数,不用纠结起什么名字,简单 # sorted() 可迭代对象 key=指定排序方式 可以调整排序方式 # filter() 函数,可迭代对象 过滤的规则在函数中写 # map() 函数,可迭代对象,将每个元素进行同样的操作 from functools import reduce # reduce() 函数,可迭代对象 累计算 # 以上4个内置函数,都帮咱们提前实现了for循环
# 1. 利用map()函数,把用户输入的不规范的英文名字,变为首字母大写,其他小写的规范名字。 # def func(a): # for i in a: # i.lower() # return a.title() # l = ['dasda','SDadADda','ASSDZad','asdada FASS'] # print(list(map(func,l))) # 2.Python提供的sum()函数可以接受一个list并求和,请编写一个prod()函数,可以接受一个list并利用reduce()求积: # from functools import reduce # def prod(x,y): # return x*y # li = [1,2,3,4,5,6,7] # print(reduce(prod,li)) # def do(n): # if n <= 1: # return n # else: # return n*do(n-1) # print(do(7))
05. 模块
模块的官方解释:https://docs.python.org/zh-cn/3.7/tutorial/modules.html
模块非常全的一个网站:https://blog.csdn.net/sinat_22991367/article/details/79435705
关于模块其他老师大牛的:https://www.cnblogs.com/jin-xin/articles/9265561.html
https://www.cnblogs.com/guobaoyuan/p/10111133.html
json.load() #参数文件句柄(r), 将文件中字符串转换成字典 json.dump() #对象(字典),文件句柄(w) 将字典转换字符串写入到文件中 json.dumps() #对象(字典) 将字典转换成字符串 json.loads() #字符串(字典) 将字符串转换成字典 import json # 导入一个json模块 dic = {‘a’:2} s = json.dumps(dic) #将字典转化为字符串 print(s) s = json.loads(dic) #将字符串转化为字典 json.dump({'1':4},open('a','w',encoding='utf-8')) d = json.load(open('a','r',encoding='utf-8')) d['1'] = 10 print(d) json.dump(d,open('a','w',encoding='utf-8')) d = json.load(open('a','r',encoding='utf-8')) print(d)
# 1.pickle 只支持python # dumps loads # dump load 持久化 import pickle # print(pickle.dumps({'1':4})) #将对象转换成类似二进制的东西 # print(pickle.loads(b'\x80\x03}q\x00X\x01\x00\x00\x001q\x01K\x04s.')) # 将一个堆类似于二进制的东西转换成字典 # pickle.dump({'2':4},open('b','wb')) # d = pickle.load(open('b','rb')) # print(d) # 总结: # josn,pickle 对比 # loads json里的将字符串转换成字典 pickle 将字节转换成字典 # dumps json里的将字典转换成字符串 pickle 将字典转换成字节 # load json里的将文件中的字符串转换成字典 pickle 将文件中的字节转换成字典 # dump json里的将字典转换字符串写入到文件中,pickle 将字典转换成字节写入到文件中 # import json # ATM # d = json.load(open('a','r',encoding='utf-8')) # print(d) # d['money'] += 500 # print(d) # d['money'] -= 100 # import json # d = json.load(open('a','r',encoding='utf-8')) # print(d) ------------------------------------------------------------------- ------------------------------------------------------------------- # 序列化: # 1.文件 + 字典操作 # import shelve # f = shelve.open('c',writeback=True) #创建文件 # writeback = True 回写 # f['name'] = 'alex' # # f['age'] = 18 # # print(f['name'],f['age']) # f['name'] = ['alex','wusir'] # # print(f['name']) # print(f) # 这样是查看不了字典 # for i in f: # print(i) #获取到所有的键 # print(f.keys()) #keys也不行 # for i in f: # print(f[i]) # dump load 咱们不用写,自动帮咱们写的 # f['name'] = {'2':4} # print(f['name']) # for i in f: # print(i) # 注意:以后你们会出现一个问题,咱们对字典的操作内容,有时候写不进去.在open # print(f['name']) # f['name'] = 'wusir' # print(f['name']) # {'2':4} # f['name'] = [1,2,34] # print(list(f.keys())) # json 最常用,前后端分离的时候数据交互 前后端分离 必会 # pickle python 不怎么常用 河南方言 必了解 # shelve 建议使用它,它简单 重庆,东北,容易学 必了解
# 随机数 import random # 内置的 # print(random.random()) # 0-1 之间随机小数 # print(random.randint(1,10)) # 起始位置,终止位置 两头都包含 # print(random.randrange(1,21,2)) # 起始位置,终止位置(不包含),步长 # print(random.choice(['alex','wusir','eva_j'])) # 从有序数据结构中随机选择一个 # print(random.choices(['wusir','tialaing','taihei','ritian'],k=2)) # 随机选择两个,但是有重复 # print(random.sample(['wusir','tialaing','taihei','ritian'],k=2)) # 随机选择两个,没有重复 # li = [1,2,3,4,6] # random.shuffle(li) # 洗牌 打乱顺序 # print(li) # 随机数 验证码 微信红包 # print(chr(65),chr(90),chr(97),chr(122)) # U = chr(random.randrange(65,91)) # L = chr(random.randrange(97,123)) # n1 = random.randrange(0,10) # n2 = random.randrange(0,10) # print(U, L,n1,n2)
# 1.os模块和当前电脑操作系统做交互 # os 内置模块 # 文件夹: import os # os.makedirs('app/a/b/c') # 递归创建文件 *** # os.removedirs('app/a/b/c') # 递归删除文件, 当这个要删除的目录有文件就停止删除 *** # os.mkdir('app') # 创建单个目录 *** # os.rmdir('app') # 删除单个目录,目录如果有东西就报错不进行删除 *** # print(os.listdir('D:\PyCharmProject\s20\day14')) **** # 查看某个目录下的内容 # 文件: # os.remove() #删除这个文件,删除了就不能恢复了 ***** # os.rename() #修改文件的名字 ***** # 操作系统: # print(repr(os.sep)) #\\ # C:\Users\lucky\Documents\Tencent Files\932023756\FileRecv # 路径符号 # print(repr(os.linesep)) # 换行符 # print(repr(os.pathsep)) # 环境变量的分割 # print(repr(os.name)) # print(os.system('dir')) # print(os.popen('dir').read()) *** # 在写程序的时候可以下发一些操作系统的指令 # 在linux系统上相当于发shell命令 # print(os.environ) 查看 高级 -- 环境变量 -- path * # 路径: # print(os.path.abspath('b')) **** # 获取当前文件的绝对路径 # print(os.path.split(r'D:\PyCharmProject\s20\day14\b')) # 将这个文件的绝对路径分成目录和文件 # print(os.path.basename(r'D:\PyCharmProject\s20\day14\b')) ** # 获取的是这个文件的名字 # print(os.path.dirname(r'D:\PyCharmProject\s20\day14\b')) *** # 获取的是这个文件的目录路径 # print(os.path.exists(r'D:\PyCharmProject\s20\day10\07 今日总结.py')) ** # 判断这个文件是否存在 # print(os.path.isabs(r'D:\PyCharmProject\s20\day14\b')) # 判断是否是绝对路径 # print(os.path.join('C:\\','app','a','b')) ***** # #路径拼接的 软件开发规范 框架 # os.stat() # print(os.stat('b').st_size) #获取文件大小 ,坑目录 *** # print(os.getcwd()) # 获取工作路劲 *** # os.chdir('D:\PyCharmProject\s20\day13') # 路径切换 * # print(os.getcwd())
# 1. sys模块 python解释器交互的 # sys 内置的 import sys # print(sys.argv[-1]) *** # 接受cmd方式调用 后边的参数会传递进来 # linux系统上 -- 后端开发 -- 数据库(文件) ip + 端口 # print(sys.path) # 添加自定义模块路劲的 # ****** # print(sys.version) # 版本 获取解释的版本号 # sys.platform = 'win1988' # print(sys.platform) #获取当前操作系统的平台位数 # 不是定死的 # print(sys.exit(1))
# 1.# 加密算法 # 作用: 当做密码 # 判断一致性 # 2.加密后不可逆 不能解 (一年前暴力破解 -- 撞库) # (现在md5 反推) # 3.sha1,sha256,sha512 # alex3714 # ********** # import hashlib # md5 = hashlib.md5('盐'.encode('utf-8')) # 选择加密方式 加盐 # md5.update('alex3714'.encode('utf-8')) # 将明文转成字节然后进行加密 # print(md5.hexdigest()) # 生成密文 # md5 = hashlib.md5() # 选择加密方式 加盐 # md5.update('alex3714'.encode('utf-8')) # 将明文转成字节然后进行加密 # print(md5.hexdigest()) # 生成密文 # sha512 = hashlib.sha512() # sha512.update('alex3714'.encode('utf-8')) # print(sha512.hexdigest()) # # sha512 # 优点: # 安全 # 缺点: # 慢 # # # md5 # 优点: # 安全,快 # 缺点: # 容易破解 # user,pwd = input('user|pwd:').strip().split('|') # import hashlib # # md5 = hashlib.md5(str(user).encode('utf-8')) # md5.update(pwd.encode('utf-8')) # print(md5.hexdigest()) # md5,sha1,sha256,sha512
# 1.序列化 # json # 必会 # dump 把字典转成字符串存入文件 # load 将文件的字符串转成字典 # dumps 将字典转成字符串 # loads 将字符串转成字典 # pickle # 了解 # shevle # 了解 # 2. 随机数 # random.random() 0-1 之间的小数 # 验证码 # random.randint(1,10) # 3. os 操作系统 # 路径部分 # os.path.join # os.path.abspath # os.path.basename # os.path.dirname # os.path.getsize() # 获取大小 # os.remove() # os.rename() # os.listdir() # os.chdir() # 切换目录 # os.makedirs('app/a/b') 递归创建文件夹 # os.removedirs('app/a/b') 递归删除 # os.mkdir() 创建单个文件夹 # os.rmdir() 删除单个文件夹 # sys python解释器 # sys.argv() 在cmd中执行 可以将文件 后的内容传递到文件中使用 # sys.path python解释器加载的路径,自定义模块添加到这里 # sys.exit() # sys.version() 获取解释器的版本号 # sys.platform 获取当前平台的位数 # hashlib 加密算法 # md5,sha1,sha256,sha512 # 1.先导入模块 # 2.创建一个加密方式 # 3.将要加密的内容编码成字节后加密 # 4.生成密文 # import hashlib # md5 = hashlib.md5(b'alex') # md5.update('alex3714'.encode('utf-8')) # print(md5.hexdigest())
PS:
1.alt + enter : 敲出需要导入的模块。
2.return的话加括号会先执行函数。
3. 
4.装饰器最常用于用户登录时使用。
1.用于多种语言交互 编程语言通用数据 # 内置的 无需安装的 直接导入使用 import json #导入一个json模块 #dumps loads dump load dumps 将字典对象转化为字符串. loads 将字符串变为字典.(列表行,其他的都不行) json主要做的是用json转换字典. json里面用load的时候,手动输入时候一定要用双引号. 主要是做变成语言通用数据, pinkle和Json用法相同. (序列化在开发序列上) pickle.dumps 将对象转换成类似二进制的东西 pickle.loads 将一堆二进制的东西转化为字典. pickle.dump 写入字节(不要写encoding) pickle.load 文件传输时候pickle比json快. 总结: pickle和json的对比: loads #json里的将字符串转化为字典. #pickle里的将字节转为字典. dumps #json里的将字典转换成字符串. pickle将字典转换成字节. load #json里的将文件中的字符串转换成字典. #pickle里的将文件中的字节转换为字典. dump #json将字典转换字符串写入到文件中. #pickle将字典转换字节写入到文件中.
12. os是与操作系统交互,sys是与Python解释器交互。
13.
# 文件夹: import os # os.makedirs('app/a/b/c') # 递归创建文件 *** # os.removedirs('app/a/b/c') # 递归删除文件, 当这个要删除的目录有文件就停止删除 *** # os.mkdir('app') # 创建单个目录 *** # os.rmdir('app') # 删除单个目录,目录如果有东西就报错不进行删除 *** # print(os.listdir('D:\PyCharmProject\s20\day14')) **** # 查看某个目录下的内容 # 文件: # os.remove() #删除这个文件,删除了就不能恢复了 ***** # os.rename() #修改文件的名字 ***** # 操作系统: # print(os.popen('dir').read()) *** # 在写程序的时候可以下发一些操作系统的指令 # 在linux系统上相当于发shell命令 # print(os.environ) 查看 高级 -- 环境变量 -- path * # 路径: # print(os.path.abspath('b')) **** # 获取当前文件的绝对路径 # print(os.path.basename(r'D:\PyCharmProject\s20\day14\b')) ** # 获取的是这个文件的名字 # print(os.path.dirname(r'D:\PyCharmProject\s20\day14\b')) *** # 获取的是这个文件的目录路径 # print(os.path.exists(r'D:\PyCharmProject\s20\day10\07 今日总结.py')) ** # 判断这个文件是否存在 # print(os.path.join('C:\\','app','a','b')) ***** # #路径拼接的 软件开发规范 框架 # print(os.stat('b').st_size) #获取文件大小 ,(注意,坑点在目录) *** # print(os.getcwd()) # 获取工作路劲 *** # os.chdir('D:\PyCharmProject\s20\day13') # 路劲切换 *
————————————————————————————————————————————————————————————————————————————————————————————
————————————————————————————————————————————————————————————————————————————————————————————
import sys
# print(sys.argv[-1]) ***
# 接受cmd方式调用 后边的参数会传递进来
# linux系统上 -- 后端开发 -- 数据库(文件) ip + 端口
# print(sys.path) # 添加自定义模块路劲的 # ******
14.数据库的名字叫ip. 通过端口可以访问数据库.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号