(本文仅作为学习记录使用)
01. 昨日内容回顾
02. 作业讲解
03. 动态参数
04. 函数的注释
05. 名称空间
06. 函数的嵌套
07. global , nonlocal
01. 昨日内容回顾
昨日主要是函数的初识:
1.什么是函数?----------函数是需要重复使用代码的时候考虑的,用于减少重复量. -----------将一些功能进行封装和复用.
2.函数怎么定义?--------
def do():
print(666)
#关键字 函数名 ( ) :
函数体
#结构如上
3.函数的调用.-----------函数名+ ( )
4.函数的执行过程.------定义函数------>建立内存空间------->调用函数-------->运行函数体-------->销毁内存空间.
5.函数的返回值.--------return: 作用: 1.返回值给调用者. 2.结束程序(在try语句块可继续运行,仅作了解). return只能用在函数内.
若return后不写别的,默认返回none;若不写return,默认返回none.
若return返回一个值,那么返回它本身; 若return返回多个值,那么返回一个由它们构成的一个元组.
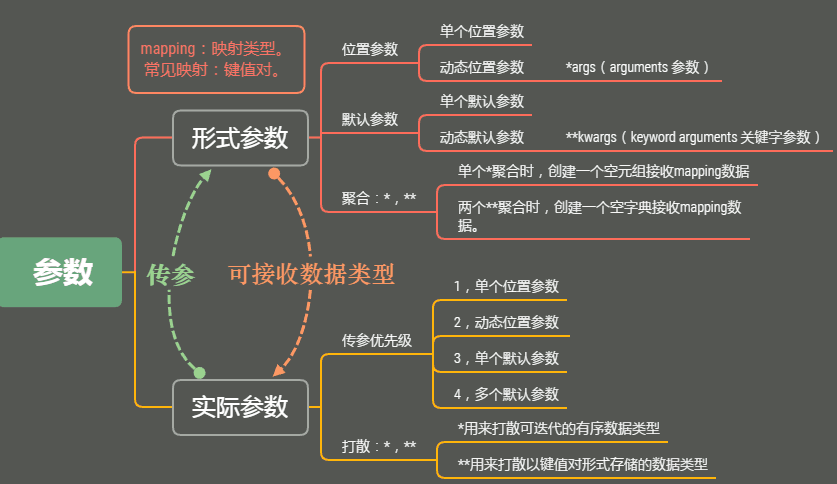
6. 函数的参数.---------形参/实参/混合参/传参. ------------位置参数/默认参数/关键字参数. PS:三元运算符
02. 作业讲解
# Day09作业及默写 # 1.整理函数相关知识点,写博客。 # pass # 2.写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。 #法一: # li = [1,2,3,4,5,6,7,8,9] # def func(a): # l1 = [] # for i in range(len(a)): # if i%2 ==1 : # l1.append(a[i]) # a = l1 # return a # print(func(li)) #法二: # li = [1,2,3,4,5,6,7,8,9] # def func(a): # return a[1::2] # print(func(li)) # 检查元组是否可行 # li = (1,2,3,4,5,6,7,8,9) # def func(a): # l1 = [] # for i in range(len(a)): # if i%2 ==1 : # l1.append(a[i]) # a = l1 # return a # print(func(li)) # 回答,可行. # 3.写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5。 #法一: # li = '1,2,3,4,6,5' # def func(a): # if len(a) > 5: # return '长度大于5' # else: # return '长度不大于5' # print(func(li)) #法二:(返回三元运算符) # def func2(a): # return '大于5' if len(a) >5 else '不大于5' # li = '1,2,3,4,6,5' # print(func2(li)) # 4.写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。 #法一: # li = {1,2,3,4,5} # def func(a) : # if len(a) > 2: # b = type(a) # a = list(a) # del a[2::] # a = b(a) # return a # print(func(li)) #法二: # def func3(a): # if len(a) > 2: # new_list = a[:2] # return new_list # print(func3([1,2,3,4])) #法三:(三元运算符) # 5.写函数,计算传入函数的字符串中,[数字]、[字母]、[空格] 以及 [其他]的个数,并返回结果。 # s = 'sadada123 12 3ADAD!@!# ' # def func(a): # b = 0 # c = 0 # d = 0 # e = 0 # for i in a: # if i.isdigit(): # b += 1 # elif i.isalpha(): # c += 1 # elif i == ' ': # d += 1 # else: # e += 1 # return '该字符串中,数字的个数是%s个,字母的个数是%s个,空格的个数是%s个,其他的个数是%s个'%(b,c,d,e) # print(func(s)) #法二:(老师做的) # def func4(str): # dic ={'num_of_digit': 0, 'num_of_char': 0, 'num_of_space': 0, 'num_of_other': 0 } # for i in str: # if i.isdigit(): # dic['num_of_digit'] += 1 # elif i.isalpha(): # if 66 < ord(i) < 123: # dic['num_of_other'] += 1 # else: # dic['num_of_char'] += 1 # elif i.isspace(): # dic['num_of_space'] += 1 # else: # dic['num_of_other'] += 1 # return '数字个数为%s,字母个数为%s,空格个数为%s,其他个数为%s,' \ # %(dic['num_of_digit'], dic['num_of_char'], dic['num_of_space'], dic['num_of_other']) # input_str = input('请输入任意字符串:') # print(func4(input_str)) # 6.写函数,接收两个数字参数,返回比较大的那个数字。 # def func(a,b): # c = a if a > b else b # return c # print(func(1,2)) # 7.写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。 # dic = {"k1": "v1v1", "k2": [11,22,33,44]} # PS:字典中的value只能是字符串或列表 # dic = {"k1": "v1v1", "k2": [11, 22, 33, 44]} #法一: # def func(a): # for key in dic: # if len(dic['%s' % key]) > 2: # if type(dic['%s' % key]) is str: # dic['%s' % key] = list(dic['%s' % key]) # del dic['%s' % key][2::] # dic['%s' % key] = ''.join(dic['%s' % key]) # else: # dic['%s' % key] = list(dic['%s' % key]) # del dic['%s' % key][2::] # return a # print(func(dic)) #法二:(老师写的) # def func6(argv): # for key in argv: # if len(argv[key]) > 2: # argv[key] = argv[key][0:2] # return argv # print(func6({"k1": "v1v1", "k2": [11,22,33,44]})) # 8.写函数,此函数只接收一个参数且此参数必须是列表数据类型,此函数完成的功能是返回给调用者一个字典,此字典的键值对为此列表的索引及对应的元素。例如传入的列表为:[11,22,33] 返回的字典为 {0:11,1:22,2:33}。 # li = [11,22,33,44,55,66,77] # def func(a): # dic = {} # for i in range(len(a)): # dic[i] = '%s'%li[i] # return dic # print(func(li)) # 9.写函数,函数接收四个参数分别是:姓名,性别,年龄,学历。用户通过输入这四个内容, # 然后将这四个内容传入到函数中,此函数接收到这四个内容,将内容追加到一个student_msg文件中。 #法一: # while 1: # num = input('请输入姓名:') # sex = input('请输入性别:') # age = input('请输入年龄:') # edu = input('请输入学历:') # def func(a,b,c,d): # with open('student_msg','a',encoding='utf8') as f: # f.write('\n%s,%s,%s,%s'%(a,b,c,d)) # return '已添加' # print(func(num,sex,age,edu)) # msg = input('按N/n结束,是否结束?') .strip() # if msg.upper() == 'N' : # break #法二:(老师写的) # def register1(name,sex,age,education): # with open('student_msg',encoding='utf-8',mode='a') as f1: # f1.write('\t{}|{}|{}|{}'.format(name,sex,age,education)) # name,sex,age,educaiton = input('请依次输入姓名,性别,年龄,学历,以逗号隔开').replace(',',',').split(',') # register1(name,sex,age,educaiton) # 10.对第9题升级:支持用户持续输入,Q或者q退出,性别默认为男,如果遇到女学生,则把性别输入女。 # 法一: # while 1: # num = input('请输入姓名:').strip() # sex = input('请输入性别(默认男,如果是女请输入,如果是男可按回车跳过):').strip() # age = input('请输入年龄:').strip() # edu = input('请输入学历:').strip() # def func(a, c, d, b='男'): # with open('student_msg', 'a', encoding='utf8') as f: # f.write('\n%s,%s,%s,%s' % (a, b, c, d)) # return '已添加' # if sex == '女': # print(func(num, c=age, d=edu, b=sex)) # else: # print(func(num, c=age, d=edu)) # msg = input('按N/n结束,是否结束?').strip() # if msg.upper() == 'N': # break #法二:(老师写的) # def register1(name,age,education,sex='男'): # sex = '男' if sex == '' else sex # with open('register1','a+' encoding='utf-8') as f1: # f1.write('{},{},{},{}\n'.format(name,age,sex,education)) # # while 1: # name = input('请输入名字(q或者Q退出):').strip() # if name.upper() == 'Q': break # age = input('请输入年龄:').strip() # sex = input('请输入性别(性别为男则直接回车):').strip() # education = input('请输入学历:').strip() # register1(name,age,education,sex) # 11.写函数,用户传入修改的文件名与要修改的内容,执行函数,完成整个文件的批量修改操作(升级题)。 # f1 要修改文件 # def func(a, b): # import os # with open('info', 'r+', encoding='utf8') as f1, open('info.bak', 'w', encoding='utf8') as f2: # for i in f1.readlines(): # msg = i.replace(a, b) # f2.write(msg) # os.remove('info') # os.rename('info.bak', 'info') # return '替换成功' # while 1: # old_comment = input('请输入需要修改的内容:') # new_comment = input('请输入修改后的内容:') # print(func(old_comment, new_comment)) # msg = input('按N/n结束,是否结束?').strip() # if msg.upper() == 'N': # break # 需要传入文件名 # def func(a, b, c ): # import os # with open('%s'%c, 'r+', encoding='utf8') as f1, open('%s.bak'%c, 'w', encoding='utf8') as f2: # for i in f1.readlines(): # msg = i.replace(a, b) # f2.write(msg) # os.remove('info') # os.rename('info.bak', 'info') # return '替换成功' # while 1: # file_name = input('请输入文件名:') # old_comment = input('请输入需要修改的内容:') # new_comment = input('请输入修改后的内容:') # print(func(old_comment, new_comment,file_name)) # msg = input('按N/n结束,是否结束?').strip() # if msg.upper() == 'N': # break #老师写的: # def file_alter(file_name,old_content,new_content): # with open(file_name,encoding='utf-8') as f: # for i in f: # i = i.replace(old_content,new_content) # f.write(i) # file_alter('log.txt','SB','alex') # 明日默写内容。 # ①return的作用。 # 返回定义的值. # return后面不写东西返回值为None. # 不写return返回值为None. # return后面写一个返回值返回其本身. # return后面跟着多个返回值的时候返回多个返回值,其形式以元组表示. # 遇到return就结束函数运行. # return返回的是结果. # ②传参的几种方法,每个都简单写一个代码。 # 如,实参,按位置传参。 # def func(x,y): # pass # func(‘a’,’b’) # 传参有三种方法: # 1.位置传递 # def do(a,b,c): # return a + b +c # print(do(1,2,3)) # 2.关键字传递 # def do(a,b,c) : # return a+b+c # print(do(a=2,b=3,c=1)) # 3.默认值传递 # def do(a, b, c=3): # return a + b + c # print(do(2,1))
03. 动态参数
def func(): 形参
pass
func() 实参
demo1:
def func(a,b,c,*args): #在形参位置上 * 叫做聚合
print(a,b,c)
print(args) #此时的是以元祖形式出现的(单个元素会加上逗号)
print(1,2,3,4,5,6,7)
#args会接收后面所有的实参
demo2:
def func(**kwargs): #**也是聚合
print(kwargs)
func(a=1,b=2,c=3)#形成的是字典.
#再次使用*或者**是打散(但**很难表现出来)
注意,----------------位置参数--------->关键字参数------------>动态位置参数----------->默认参数---------->动态关键字参数(形参顺序)
demo3:
#关于打散的情况
def func(*args,**kwargs): # * 聚合
print(*args) # args = () *args = 1 2 3 *打散
print(*kwargs) # args = () **kwargs = 1 2 3 *打散 字典的键
func(1,2,3,a=4,b=5)
li = [1,2,3,5,4]
def func(*args): # 聚合 (1,2,3,5,4)
print(args)
print(*args) # 打散 1,2,3,5,4
func(*li) # 1,2,3,5,4
小结:
args和 kwargs 是可以更换的,但是程序员约定都用它
用途:在不明确接受参数,数量时使用*args和**kwargs
动态位置参数 > 动态关键字参数
形参: 位置 > 动态位置 > 默认参数 > 动态默认参数
实参: 位置 > 关键字参数
在实参调用的时候 *将可迭代的对象打散,字典是将键取出
在形参处出现*就是在聚合
在实参调用的时候 **将字典打散成 关键字参数(键=值)
在形参处出现**就是将关键字参数聚合成一个字典
图片如下:
04. 函数的注释
demo4:
def msg(username,password) :
"""
登录函数
:param username:用户名
:param password:密码
:return:校验后的账号和密码
""" #三个单引号会有波浪线,三个双引号不会有
print(111)
#print(msg.__doc__) #此时能调用出注释
05. 名称空间(nameplace)
内置空间:内置空间的所有代码
全局空间:自己写的py文件
局部空间:函数中的代码
加载顺序:内置空间------------>全局空间----------------------->局部空间
取值顺序:局部空间------------>全局空间----------------------->内置空间------------------->取不到就报错
作用域:
全局作用域:全局+内置=全局作用域
局部作用域:函数内的就是局部作用域
06. 函数嵌套
第一种嵌套:(在func内)
demo5:
def func():
print(3)
def f():
print(1)
print(2)
f()
func()
第二种嵌套:多个函数嵌套用(我认为名字可以为调查调用)
demo6:
def func2(): print(1) log() def func1(): print(3) def log(): print(5) func1() def fun() print(7) func2()
第三种嵌套:(不断嵌套)
demo7:
def func():
a = 1
def log():
a = 5
def info():
a = 10
print(a)
print(a)
print(a)
func()
07. global,nonlocal
global:在局部空间修改全局变量,如果全局变量不存在就创建一个新的变量. 不考虑局部空间的变量. 自上查找。
nonlocal:在局部空间内,修改离自己最近的变量,如果上一层没有就继续向上寻找,直到找到局部变量的顶层,局部空间里没有可修改的变量,就报错.(向上寻找)
global和nonlocal只用于声明变量, 后面跟变量名.
demo 8:
#global:
a = 2
def f():
def a1():
def l():
global a
a += 2
print(a)
l()
print(a1())
print(a)
f()
#nonlocal:
def f():
def a1():
def l():
nonlocal a
a = 8
print(a)
l()
print(a1())
f()
总结:
函数的进阶:
1.1 动态参数
位置参数 > 动态位置参数 > 默认参数 > 动态(关键字)默认参数
1.2 *,**
在实参位置是打散
在形参位置是聚合
1.3 *args,**kwargs 可以修改,但是不建议修改
1.4 将(列表,元组,字符串,字典,集合)打散传入
2.1 函数的注释:
""" """ 官方推荐
查看注释: func名.__doc__
查看注释: func名.__name__
3.1 名称空间
加载顺序:
1.内置空间
2.全局空间
3.局部空间
取值顺序:
1.局部空间
2.全局空间
3.内置空间
作用域;
全局作用域 内置 + 全局
局部作用域 局部
global : 在局部修改全部变量,如果没有就创建一个新的,只能自上寻找。 下面有的不作数。
nonlocal : 在局部空间内,修改离自己最近的变量,如果上一层没有就继续向上找,
直到找到局部变量的顶层,局部空间内没有可以修改的变量,就报错
4.1 函数的嵌套
看文件06 函数的嵌套
4.2:
函数嵌套内,从最里层返回一个任意字符串,在外部接受打印
demo9:
def do(): print(6) def info(): print(123) def www(): return 'sadad' print(123) return www() return info() print(do())
PS :
1. 一个py文件是一个全局变量,全局空间.
2. 直接print(函数名)输出的是内存地址,print(函数名())是输出的是返回值.
3. 
上面的执行顺序是:def------->make()调用:--------->执行make函数体---------->返回return(生成和销毁内存空间不提)
4. return可以写多个,但只执行一个.(因为到第一个return就结束函数了)
5. return里面是公式的话,先计算公式;有数值计算数值;字符串的话就是正常输出字符串.
6. 不管在什么地方,函数名+()就是在调用函数.
7. 三元运算符只支持if...else...运算,在不确定赋什么值时候就会用到.
8. pycharm中飘红不代表报错,但有些时候的确是报错.
9. pycharm中没用上的变量会发灰,用上了的发黑.(def中)
10.解构:
参数规则
参数列表参数一般顺序是,普通参数、缺省参数、可变位置参数、keyword-only参数、可变关键字参数
例如def fn(x,y,z=3,*arg,m=4,n,**kwargs)
参数解构
举例
add(*t)或add(*(4,5)) [4,5] {4,5}
add(*range(1,3))
给函数提供实参的时候,可以在集合类型前使用*或者**,把集合类型的解构解开,提出所有的元素作为函数的实参
非字典类型使用*解构成位置参数
字典类型使用**解构成关键字参数
提取出来的元素数目要和参数的要求匹配,也要和阐述的类型匹配
---------------------
作者:tc2019
来源:CSDN
原文:https://blog.csdn.net/tc2019/article/details/79956124
版权声明:本文为博主原创文章,转载请附上博文链接!
11. 可以一下子对很多变量赋很多值.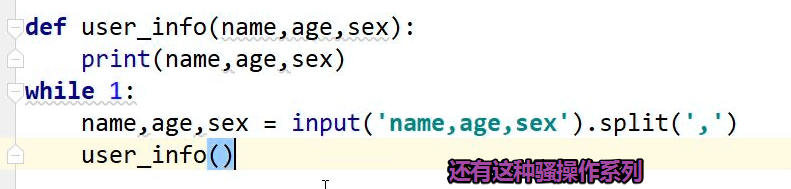
12. 存在连等.
13. split可以如下操作获取值,在字典中想必很有用.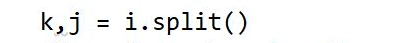
14. 前期最好的排bug方法就是print.
15. %S(大写)不是占位符.
16. f.wirte的花式写法.
17. 三种格式化输出: %s(占位符), format , #f
eg:在例子中,单引号报错,双引号不报错,注意.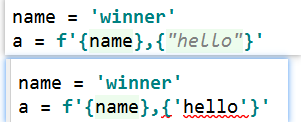
还可以在input中输入,天哪!
还可以写在文件操作中!
18. 注意,*args和**kwargs的区别. 前者的实参写数字,字符串等,后者需要写诸如a = 3这样的格式(字典用的).用途是在不明确接受参数数量的情况下使用. 并且要注意书写顺序.

19. 排bug从下往上读代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号