
Diffusers实战
Smiling & Weeping
---- 一生拥有自由和爱,是我全部的野心
1. 环境准备
%pip install diffusers
from huggingface_hub import notebook_login # 登录huggingface notebook_login()
import numpy as np import torch import torch.nn.functional as F from matplotlib import pyplot as plt import torchvision from PIL import Image def show_images(x): """给定一批图像,创建一个网格并将其转换成PIL""" x = x*0.5 + 0.5 grid = torchvision.utils.make_grid(x) grid_im = grid.detach().cpu().permute(1, 2, 0).clip(0, 1)*255 grad_im = Image.fromarray(np.array(grid_im).astype(np.uint8)) return grad_im def make_grid(images, size=64): """给定一个PIL图像列表,将他们叠加成一行以便查看""" output_im = Image.new("RGB", (size*len(images), size)) for i, im in enumerate(images): out_im.paste(im.resize((size, size)), (i*size, 0)) return output_im device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') device
from diffusers import DDPMPipeline, StableDiffusionPipeline model_id = "sd-dreambooth-library/mr-potato-head" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to(device)
prompt = "a cute anime characters using 8K resolution" image = pipe(prompt, num_inference_steps=50, guidance_scale=5.5).images[0] image
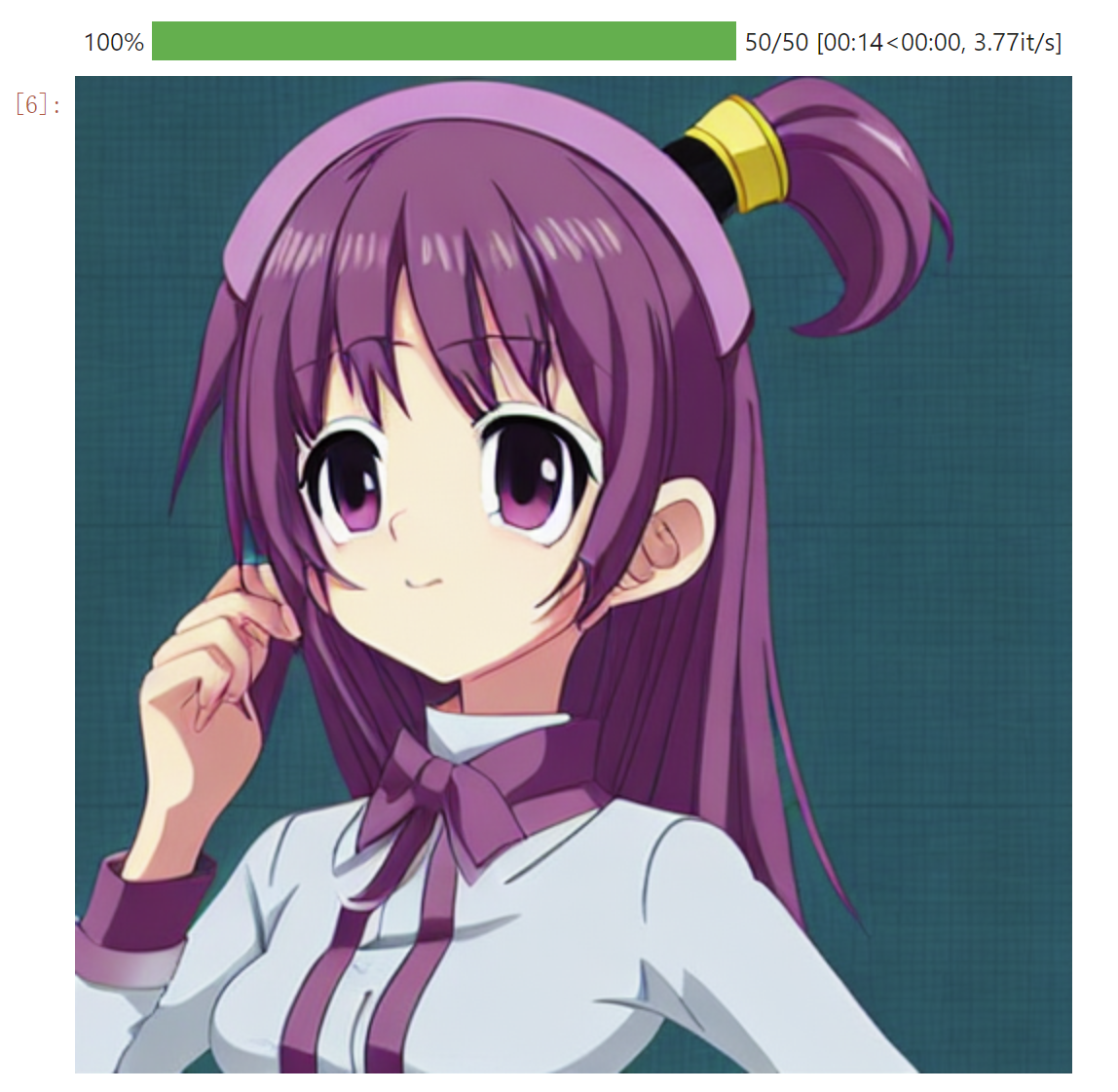
Diffusers核心API:
- 管线:从高层次设计的多种类函数,便于部署的方式实现,能够快速利用预训练的主流扩散模型来生成样本。
- 模型:在训练新的扩散模型时需要用到的网络结构。
- 调度器:在推理过程中使用多种不同的技巧来从噪声中生成图像,同时可以生成训练过程中所需的“带噪”图像。
import torchvision
from datasets import load_dataset
from torchvision import transforms
from diffusers import DDPMScheduler
from diffusers import DDPMPipeline, StableDiffusionPipeline
dataset = load_dataset('lowres/anime', split="train")
image_size = 256
batch_size = 8
preprocess = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.RandomHorizontalFlip(),
transforms.Normalize([0.5], [0.5]),
])
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples["image"]]
return {"images": images}
dataset.set_transform(transform)
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
xb = next(iter(train_dataloader))['images'].to(device)[:8] print("X shape:", xb.shape) show_images(xb).resize((8*256, 256), resample=Image.NEAREST)

# 定义调度器 from diffusers import DDPMScheduler noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_start=0.001, beta_end=0.004)
timesteps = torch.linspace(0, 999, 8).long().to(device)
noise = torch.rand_like(xb)
noisy_xb = noise_scheduler.add_noise(xb, noise, timesteps)
print("Noise X Shape", noisy_xb.shape)
show_images(noisy_xb).resize((8*64, 64), resample=Image.NEAREST)
from diffusers import UNet2DModel model = UNet2DModel( sample_size=image_size, # 目标图像的分辨率 in_channels=3, out_channels=3, layers_per_block=2, # 每一个UNet块中的ResNet层数 block_out_channels=(64, 128, 128, 256), down_block_types=( "DownBlock2D", "DownBlock2D", "AttnDownBlock2D", # 带有空域维度的self-att的ResNet下采样模块 "AttnDownBlock2D", ), up_block_types=( "AttnUpBlock2D", "AttnUpBlock2D", # 带有空域维度的self-att的ResNet上采样模块 "UpBlock2D", "UpBlock2D", ), ) model = model.to(device)
with torch.no_grad():
model_pred = model(noisy_xb, timesteps).sample
model_pred.shape
训练
# 设定噪声调度器 noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule="squaredcos_cap_v2") # 训练循环 optimizer = torch.optim.Adam(model.parameters(), lr=4e-4) losses = [] # 定义损失函数 loss_fn = torch.nn.MSELoss() for epoch in range(45): for step, batch in enumerate(train_dataloader): # 未添加噪声的数据(clean data) clean_data = batch['images'].to(device) # 生成噪声 noise = torch.randn(clean_data.shape).to(device) bs = clean_data.shape[0] # 为每张图片随机采样一个时间步 timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bs, ), device=device).long() # 噪声数据 # 根据每个时间步的噪声幅度(迭代次数),向清晰的图片中添加噪声 noisy_data = noise_scheduler.add_noise(clean_data, noise, timesteps) # 获得预测模型 pred_data = model(noisy_data, timesteps, return_dict=False)[0] # 计算损失 loss = loss_fn(pred_data, clean_data) loss.backward() losses.append(loss.item()) # 迭代模型参数 optimizer.step() optimizer.zero_grad() if (epoch+1) % 5 == 0: loss_last_epoch = sum(losses[-len(train_dataloader):]) / len(train_dataloader) print(f"Epoch: {epoch+1}, loss: {loss_last_epoch}")
torch.save(model.state_dict(), 'save.pt')
绘制损失图线
fig, axs = plt.subplots(1, 2, figsize=(12, 4)) axs[0].plot(losses) axs[1].plot(np.log(losses)) plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号