
4.2-主存中的数据组织
存储字长
- 主存的一个存储单元所包含的二进制位数
- 目前大多数计算机的主存按字节编址,存储字长也不断加大,如16位字长,32位字长
- ISA设计时要考虑的两个问题
-
- 如何根据字节地址读取一个32位的字?-字的存放问题
- 一个字能否放在主存的任何字节边界?-字的边界问题
数据存储与边界的关系
1. 按边界对其的数据存储
Int I(32), short(16) k, double(64) x, char(8) c, short j(32位系统中),一个字节8位
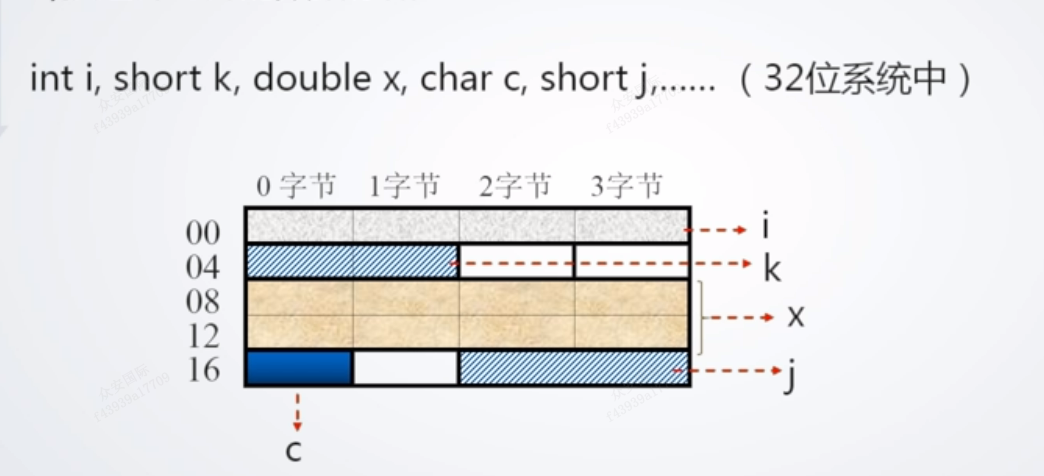
按照边界对齐的方式存储
缺点:会造成存储空间的浪费,比如k浪费了2个字节
2. 未按边界对齐的数据存储
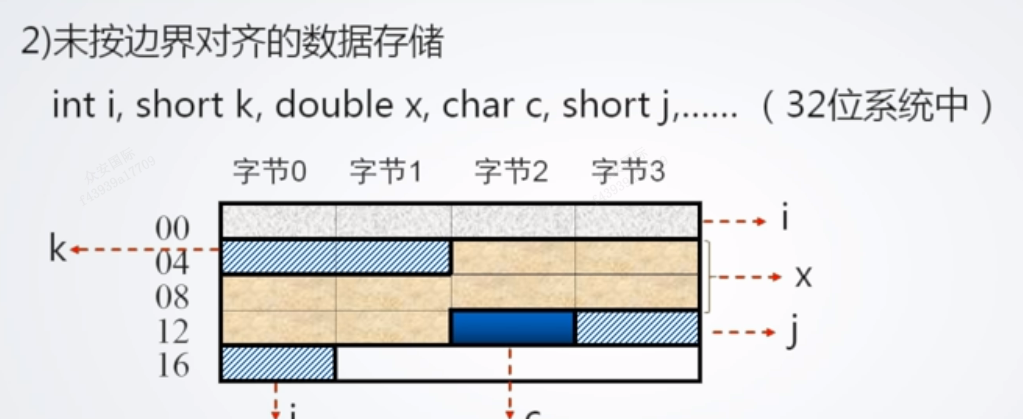
缺点:虽然节省了空间,但增加了访存次数,需要在性能与容量间权衡
比如:访问j就需要方位一次12还需要方位一次16,访问x需要三次(4,8,12)
3. 边界对齐与存储地址的关系(以32位为例)

- 双字节数据边界对齐的起始地址的最末三位为000(8字节的整数倍)
- 单字长边界对齐的起始地址的末二位为00(4字节的整数倍)
- 半字长边界对齐的起始地址的最末一位为0(2字节的整数倍)
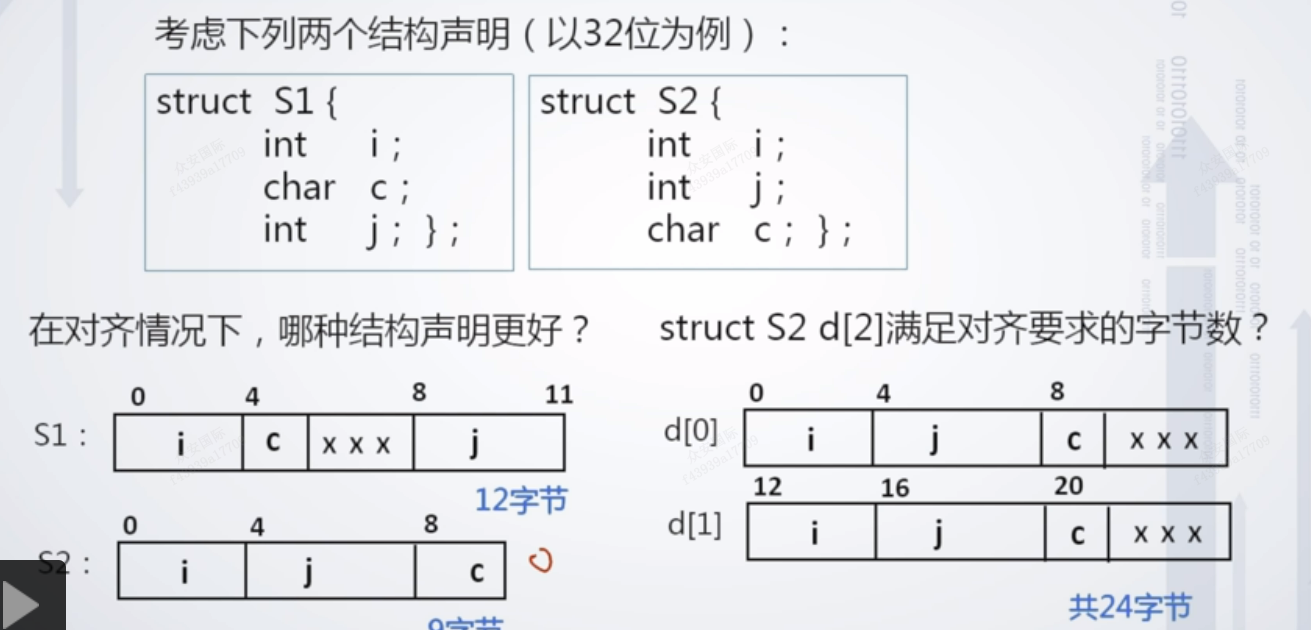
S1和S2两个字节的存储方式实际S1需要12个字节,S2需要9个字节,但是按照对齐要求依然需要12个字节来存储S2,实际上是没有区别的
大端与小端的存储方式
1. Big-endian:最高字节地址(MSB)是数据地址

2. Little-endian:最低字节地址(LSB)是数据地址

但是,如果你的程序要跟别人的程序产生交互呢?在这里我想说说两种语言。C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而JAVA编写的程序则唯一采用big endian方式来存储数据。
试想,如果你用C/C++语言在x86平台下编写的程序跟别人的JAVA程序互通时会产生什么结果?就拿上面的0x12345678来说,你的程序传递给别人的一个数据,将指向0x12345678的指针传给了JAVA程序,由于JAVA采取big endian方式存储数据,很自然的它会将你的数据翻译为0x78563412。什么?竟然变成另外一个数字了?是的,就是这种后果。因此,在你的C程序传给JAVA程序之前有必要进行字节序的转换工作。
例如:

R1=0X100,指的是r1的初始值是100
STR r0, [r1] – 将r0的内容执行r1所在的储存单元上,就是将16进制数11223344存放在100号起始单元
LDRB r2, [r1] -从r1的储存单元取出来一个字节赋值给r2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号