# 导入库
import seaborn as sns # 绘图
import numpy as np # 数值运算
# 机器学习: sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegressionCV # 逻辑回归
1 数据处理
# 使用 Seaborn 库加载经典的鸢尾花(Iris)数据集,并将其存储在变量 iris 中
iris = sns.load_dataset('iris')

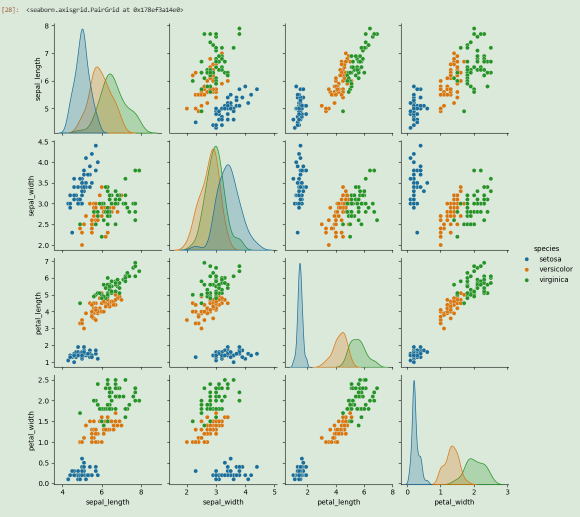
# 矩阵式的散点图(Pair Plot),这是探索数据特征间关系和类别分布的高效工具
# 花瓣(petal)的尺寸
# 花萼(sepal)的尺寸
sns.pairplot(iris,hue="species")
# iras数据集中的三个物种:setosa, versicolor, virginica
# 通过这个图表,你可以快速发现:花瓣(petal)的尺寸是区分鸢尾花种类的关键特征,而花萼(sepal)的特征需要结合其他信息才能有效分类。
# 特征值 和 目标值
x = iris.values[:,:4]
y = iris.values[:,4]
# 数据集划分: 训练数据和测试数据
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.5,random_state=0)
2 机器学习 sklearn 训练鸢尾花
# 估计器
lr = LogisticRegressionCV()
# 模型训练
lr.fit(train_x, train_y)
# 模型评估
lr.score(test_x, test_y)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号