
满意度调查 - Satisfaction Survey - Indexed Tree
满意度调查
(全部测试用例:40个,1.5秒(C/C++),2秒(JAVA))
用户用餐后会在外卖应用上对食物的满意度进行评价。(满意度分数始终大于0)
研究满意度的专家称,当把满意度分数按照从小到大的顺序排列时,某个(X/Y)位置的满意度非常重要。因此作为管理满意度的负责人丽雅,她想逐个接收分数后进行处理。
每当接收的满意度为Y的倍数时,会调查X/Y位置的满意度并进行记录。(如果X=3,Y=4的情况,满意度有4个时取第三个分数,有八个时取第六个分数。)
然而,有时候用户也会删除他们的满意度分数。这种情况,为了方便会把该满意度分数接收为负数,然后删除该分数。(确定删除只会发生在已存在的分数上。)然而删除后,数据个数重新变成Y的倍数时,也仍然需要调查满意度分数并进行记录。
让我们思考一下 X=3,Y=4,并且按照 7、5、3、1、-1、7、7、5、6、1、-7、1 的顺序接收12个满意度分数的情况。
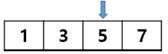
[图1]
首先按照7、5、3、1的顺序输入时,输入的数据个数满足Y的倍数,所以按升序排列时,会成为[图1],X/Y位置的满意度分数是5。

[图2] [图3]
接着输入了-1时,会如上[图2]一样,前面的1会被删除(请注意,负数值本身不是输入值,而是要删除的值), 然后输入7,会成为[图3]。此时,数据个数重新会变成Y的倍数,X/Y位置的满意度值为7。

[图4]
然后输入7、5、6、1时,数据会成为Y的倍数,会有8个值按从小到大排序,此时跟[图4]一样,这时X/Y位置的值为7。

[图 5]
最后输入-7、1时,跟上述的条件一样,会删除一个跟-7的绝对值相同的7,然后添加1后,数据个数又会变成Y的倍数,成为[图 5]。此时的X/Y位置的值为6,所以符合条件的位置上所在的满意度分数之和为25(5+7+7+6)。
请编写一个程序,求出丽雅记录的满意度之和。
[限制条件]
1.输入的满意度分数的个数N为介于4到300,000之间的整数。
2.满意度分数为介于-1,000,000,000 到 1,000,000,000 之间的整数,分数为整数时,表示用户输入的满意度,分数为负数时,表示用户删除的满意度。不会给出0。
3.删除时,存在多个相同的满意度绝对值时,只删除其中一个满意度。
4.不会删除不存在的满意度。
5.X和Y是介于1到N的整数,且必须为互质数。
6.X小于Y。
[输入]
首先给出测试用例数量T,接着给出T种测试用例。每个测试用例的第一行给出数据个数N,以及空格区分给出表示比率的X,Y。第二行空格区分给出N个数字。
[输出]
每个测试用例输出一行。各测试用例输出#x(x是测试用例的编号,从1开始),加一个空格,输出丽雅调查的满意度之和。
[输入输出 示例]
(输入)
3
12 3 4
7 5 3 1 -1 7 7 5 6 1 -7 1
6 2 3
3 -3 2 4 4 1
9 2 3
7 2 6 2 7 7 3 3 7
(输出)
#1 25
#2 4
#3 20
思路:排序并散列化
1.按照原数据顺序读取数据,逐个去排序后的数组中去找对应的index,在tree中,将offset+index的位置上+1;
2.tree的update是求和,如果tree[1]%Y==0,即放入的数的个数是Y的的倍数时,求个数(即tree[1])*X/Y的值,此值就是要统计的值,计为idx;
3.tree中的下标,本来就是按顺序的,所以,要求tree的叶子节点上,有效值的index=idx时,对应的原数组中的元素;
步骤:
1.散列化 : map中的val对应原数组散列化后的结果
2.当读取的数据个数%Y==0时,记录第X个数,因此需要记录读取的数的数个,即求个数之和,定义tree,第读取一个数,在对应的散列化的节点上+1
3.记录第X个数时,从排序后的节点中取,我们将数据的散列化结果放到tree上时,从左到右,就是按顺序的,因此,只需要从叶子节点中,取第X个数对应的原数组的数字即可
4.当读取的数据个数%Y==0时,取第X个数的方法: 从根节点遍历,如果子节点1<X,则去子节点2找,此时val=X-子节点1,用val去子节点2的子节点找,重复此步骤, 直到找到叶子节点上的对应位置
5.找到第X个叶子节点后,此叶子节点-offset=map中散列化后的val,通val找到map的key,即为原数组中的数
6.如果读取到的数是负数,则找到它对应的正数的位置:取反,去map中找,找到后,在tree上对应的位置-1
package tree;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.HashMap;
import java.util.StringTokenizer;
import java.util.TreeSet;
/**
*
* 思路:排序并散列化
* 1.按照原数据顺序读取数据,逐个去排序后的数组中去找对应的index,在tree中,将offset+index的位置上+1;
* 2.tree的update是求和,如果tree[1]%Y==0,即放入的数的个数是Y的的倍数时,求个数(即tree[1])*X/Y的值,此值就是要统计的值,计为idx;
* 3.tree中的下标,本来就是按顺序的,所以,要求tree的叶子节点上,有效值的index=idx时,对应的原数组中的元素;
*
* 步骤:
* 1.散列化 : map中的val对应原数组散列化后的结果
* 2.当读取的数据个数%Y==0时,记录第X个数,因此需要记录读取的数的数个,即求个数之和,定义tree,第读取一个数,在对应的散列化的节点上+1
* 3.记录第X个数时,从排序后的节点中取,我们将数据的散列化结果放到tree上时,从左到右,就是按顺序的,因此,只需要从叶子节点中,取第X个数对应的原数组的数字即可
* 4.当读取的数据个数%Y==0时,取第X个数的方法: 从根节点遍历,如果子节点1<X,则去子节点2找,此时val=X-子节点1,用val去子节点2的子节点找,重复此步骤, 直到找到叶子节点上的对应位置
* 5.找到第X个叶子节点后,此叶子节点-offset=map中散列化后的val,通val找到map的key,即为原数组中的数
* 6.如果读取到的数是负数,则找到它对应的正数的位置:取反,去map中找,找到后,在tree上对应的位置-1
*
* @author XA-GDD
*
*/
public class SatisfactionSurvey_0524 {
static int T,N,X,Y;
static int _Max_N = 300000;
static int [] srcArr = new int[_Max_N];
static int [] idxTree = new int[_Max_N*4];
static int offset;
static TreeSet<Integer> ts = new TreeSet<Integer>();
static HashMap<Integer, Integer> hash = new HashMap<Integer, Integer>();
static HashMap<Integer, Integer> map = new HashMap<Integer, Integer>();
static long ans;
public static void main(String[] args) throws IOException {
System.setIn(new FileInputStream("D:\\workspace\\eclipse-workspace\\sw_pro\\test_case\\sample_input_0524.txt"));
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
T = Integer.parseInt(st.nextToken());
for(int testCase = 1; testCase<=T;testCase++) {
init();
st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
X = Integer.parseInt(st.nextToken());
Y = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
for(int i=0;i<N;i++) {
srcArr[i] = Integer.parseInt(st.nextToken());
if(srcArr[i]>=0) {
ts.add(srcArr[i]);
}
}
int index=0;
for(int val : ts) {
hash.put(val, index); //散列化
map.put(index,val); //找到index后,通过index找原始的数据
index++;
}
//初始化tree
int k=0;
while((1<<k)<index) {
k++;
}
offset = 1<<k;
for(int i=0;i<N;i++) {
if(srcArr[i]>=0) {
update(offset+hash.get(srcArr[i]),1);
}else {
//负数时,需要将对应的正数位置的个数-1
update(offset+hash.get(-srcArr[i]),-1);
}
if(idxTree[1]>0 && idxTree[1]%Y==0) { //节点个数是Y的倍数时,统计第X个值
int mult = idxTree[1]/Y;
int xIdx = findIndex(mult);
ans += (long)map.get(xIdx-offset);
}
}
System.out.println("#"+testCase+" "+ans);
}
}
static void update(int index,int val) {
idxTree[index] += val;
index = index>>1;
while(index>0) {
idxTree[index] = idxTree[index*2] + idxTree[index*2+1];
index = index>>1;
}
}
//找tree中第X个有效数的下标
static int findIndex(int mult) {
int index = 1;
int val = mult*X;
int leftIdx ;
int rightIdx ;
while(index < offset) {
leftIdx = index<<1;
rightIdx = leftIdx+1;
if(idxTree[leftIdx]>=val) { //左子节点的值<X时,要找的节点以右子节点下
index = leftIdx;
}else {
val -= idxTree[leftIdx];
index = rightIdx;
}
}
return index;
}
static void init() {
ans=0;
Arrays.fill(srcArr,0);
Arrays.fill(idxTree,0);
ts.clear();
hash.clear();
map.clear();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号