python的学习之路day3
大纲
1、汉字编码
2、浅拷贝与深拷贝
3、函数
4、return
5、函数的基本参数
6、format
7、三元运算(三目运算)
8、python的内置函数
abs() all() any() bool() bin() oct() hex()
bytes()
callable()
ord() chr()
compile() exec() eval()
dir() help()
filter()
9、open函数
汉字编码
汉字的字节:
utf-8 一个汉字:三个字节
gbk 一个汉字:二个字节
一个字节等于八位;1byte=8bits
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。关于这个深浅拷贝为了方便自己,所以复制了老师的
浅拷贝与深拷贝
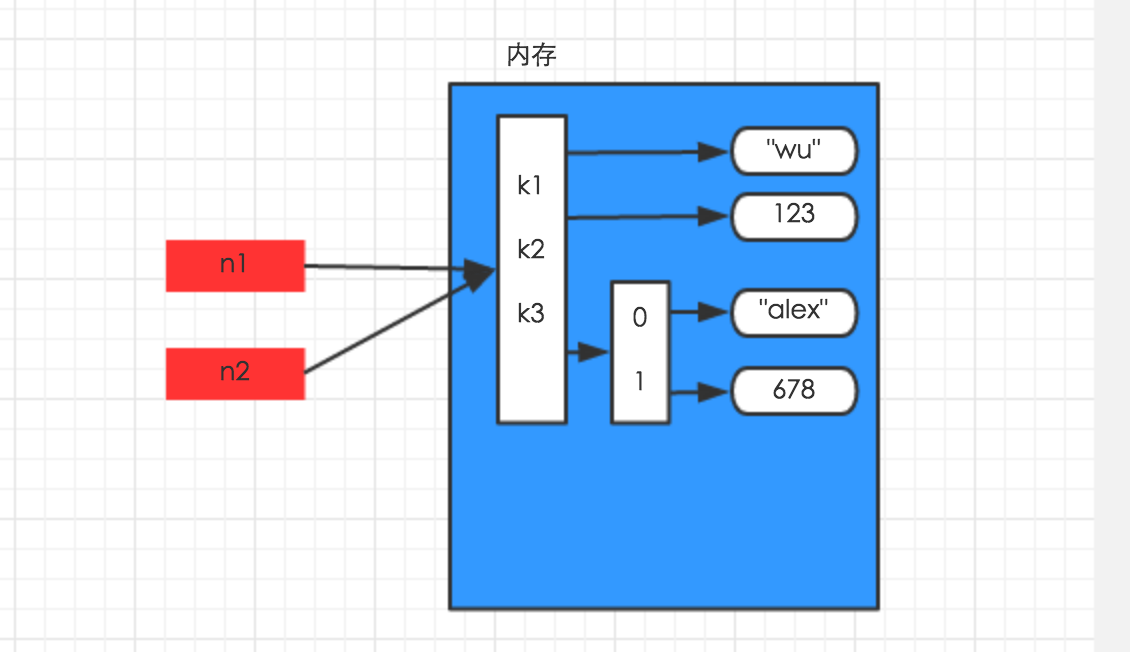
1、赋值
赋值,只是创建一个变量,该变量指向原来内存地址,如:
|
1
2
3
|
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n2 = n1 |
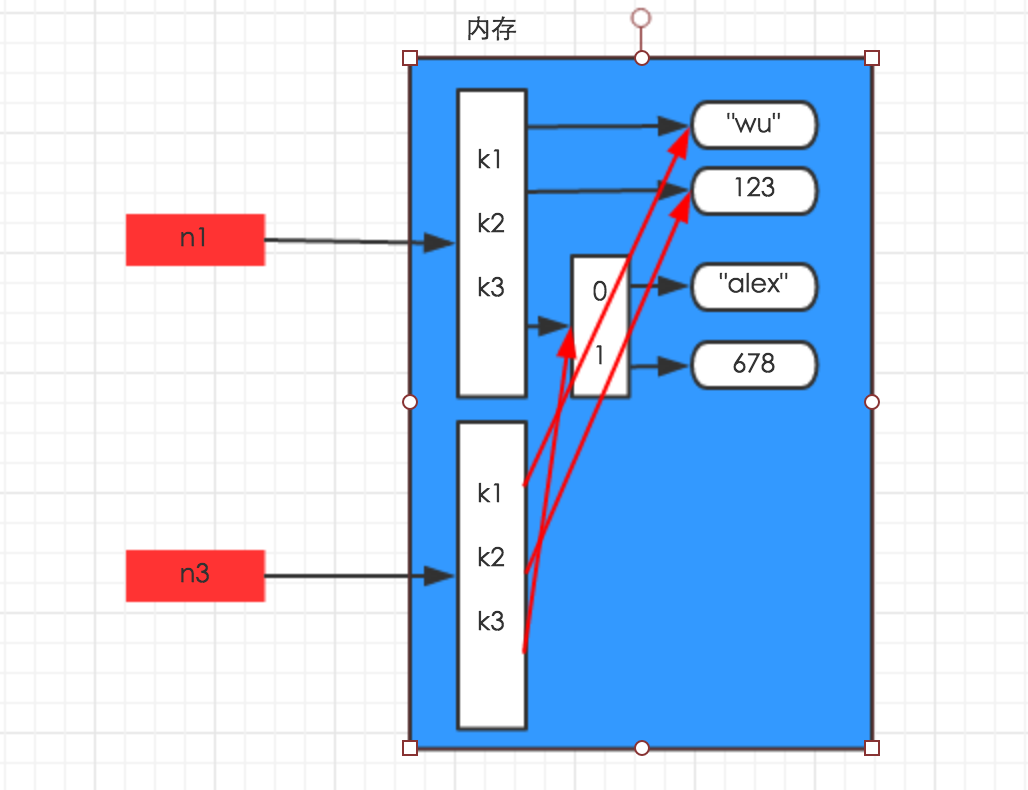
2、浅拷贝
浅拷贝,在内存中只额外创建第一层数据
|
1
2
3
4
5
|
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n3 = copy.copy(n1) |
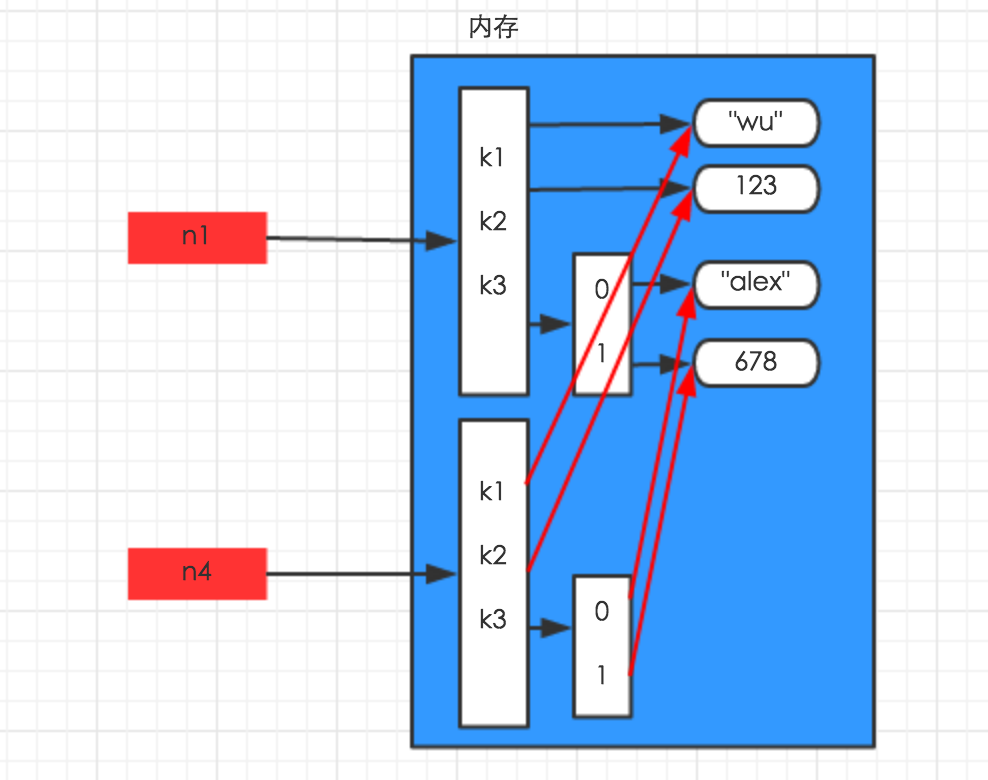
3、深拷贝
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
|
1
2
3
4
5
|
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n4 = copy.deepcopy(n1) |
函数
函数分为自定义函数,和python的内置函数
定义:
函数是指将一组语句的集合通过一个名字(函数名)封装起来,想要执行这个函数,只需要调用其函数名即可
语法定义:
def hello():#hello是函数名,def关键字用于创建函数 print("hello world...") hello()#调用函数
函数的执行过程:
1、def关键字,创建函数
2、函数名
3、()
4、函数体(函数体默认是不执行的,当我调用时执行)
5、返回值
函数的特性:
1、减少重复代码
2、是程序变的可扩展
3、是程序变得已维护
return返回值的使用:
def ret(): print("hello world") return "success"#在函数中,一旦执行了return后,函数执行过程立即终止,返回值将会赋给我们定义的函数 print(123)#123是不会执行的 r = ret() print(r) hello world success
return默认的返回值:
def ret(): print(123) r = ret() print(r) 123 None#python默认的返回值为none
函数的基本参数:
1、基本参数 == 形参、实参
2、默认参数(必须放置参数的最后面)
3、指定参数 == 相当于a="b"、b="a"
4、动态参数:
* == 相当于一个元组
** == 相当于一个字典
形参、实参定义方法:
def parameter(p1, p2): # 在定义时被称为形参,相当于他是一个变量 print("name:", p1, "age:", p2) return "..." parameter("smelond", 16) # 在调用时我输入的参数被称为实参,大概就是他是一个实际的值,反正我是这样理解的 name: smelond age: 16
默认参数:
def parameter(p1, p2="16"): # 默认参数必须放置在形参列表的最后面 print("name:", p1, "age:", p2) return "..." parameter("smelond") #在调用过程中,如果我不传参进去他就会输出默认的值 name: smelond age: 16
指定参数:
def parameter(p1, p2): # 形参的常规写法 print("name:", p1, "age:", p2) return "..." parameter(p2 = "smelond", p1 = 16) #在调用过程时,我们只需要指定形参名即可 name: 16 age: smelond
动态参数
* 接收N个实际参数(元组):
def n_p(*args):#只要在前面加上一个*,他可以接受N个实际参数 print(args, type(args)) n_p(11, 22, 33) (11, 22, 33) <class 'tuple'>#输出时会把他们转换为元组
def n_p(*args): print(args, type(args)) li = [11, 22, 33, "smelond"] # 给了一个列表 n_p(li, "44") ([11, 22, 33, 'smelond'], '44') <class 'tuple'>#就算是列表他也只当了一个元素,可以看到输出时在元组里面有一个列表
def n_p(*args): print(args, type(args)) li = [11, 22, 33, "smelond"] # 给了一个列表 n_p(*li) # 如果在实参前面加上*,在输出时他会像for循环一样,把每一个列表循环到元组里面,从而有了多个元素 li = "smelond" # 字符串也一样 n_p(*li) (11, 22, 33, 'smelond') <class 'tuple'> ('s', 'm', 'e', 'l', 'o', 'n', 'd') <class 'tuple'>
**接收N个实际参数(字典):
def d_p(**kwargs): # **他接收的是一个字典 print(kwargs) d_p(k1="v1", k2="v2")#以key value的方式传参 {'k1': 'v1', 'k2': 'v2'}
def d_p(**kwargs): # **他接收的是一个字典 print(kwargs) dic = {"k1": "v1", "k2": "v2"}#定义一个字典 d_p(k1=dic) # 因为在这个地方v为一个字典,所以输出时会嵌套一个字典 {'k1': {'k1': 'v1', 'k2': 'v2'}}
万能参数:
def d_p(*args, **kwargs): # 接收一个元组和一个字典 print(args) print(kwargs) d_p(11, 22, 33, k1="v1", k2="v2") # 将他俩同时传入 (11, 22, 33) {'k1': 'v1', 'k2': 'v2'}
利用动态参数实现format功能:
# 一个*的使用方法(列表)
s1 = "i am {0}, age {1}".format("smelond", 16) # format会将smelond副歌0,16赋给1,
print(s1)
li = ["smelond", 16]
s2 = "i am {0}, age {1}".format(*li) # 因为是列表,所以加上*号输出效果是一样的
print(s2)
# 两个*的使用方法(字典)
s3 = "i am {name}, age {age}".format(name="smelond", age=16) # 如果前面括号里面为什么,我们的key值就得为什么
print(s3)
dic = {"name": "smelond", "age": 16}
s4 = "i am {name}, age {age}".format(**dic) # 在这个地方得加上**因为他是一个字典
print(s4)
i am smelond, age 16
i am smelond, age 16
i am smelond, age 16
i am smelond, age 16
三元运算(三目运算)表达式:
# 以下是if_else的常规写法
if 1 == 1:
name = "smelond"
else:
print("age")
# 三元运算就可以写简单的if_else
name = "smelond" if 1 == 1 else "age" # 意思是说,如果1 == 1,那么将"smelond"赋给变量name,否者将age赋给name
print(name)
smelond
lambda表达式:
# lambda 写一些简单的函数可以用lambda表达式
def f1(a1):
return a1 + 100
r1 = f1(10)
print(r1) # def的简单常规写法
# 如果用lambda表达式:
f2 = lambda a1, a2=10: a1 + a2 + 100 # 最前面的f2代表函数名,冒号前面的是形参,可以看到在这个里面也可以个形参加默认值,冒号后面的就是简单的运算
r2 = f2(10)
print(r2)
110
120
python的一些内置函数:


# 内置函数一 # abs() 返回绝对值 n = abs(-1) print(n) # 1 # all() # any() # 0,None,"",[],{},() == 全部都为False # all()所有为真,才为真 n = all([1, 2, 3, 4, None]) print(n) # # any()只要有一个为真,就为真 n = any([1, [], []]) print(n) # bool值,返回真假 print(bool(0)) print(bool(True)) # ascii() #自动执行对象的__repr__方法 # bin() 接收一个十进制,会把十进制转换为二进制(0b) print(bin(5)) # oct() 接收一个十进制,会把十进制转换为八进制(0o) print(oct(9)) # hex() 接收一个十进制,会把十进制转换为十六进制(0x) print(hex(15)) 1 False True False True 0b101 0o11 0xf
# 内置函数二 # 字符串转换为字节类型 # bytes(只要转换为字符串,按照什么编码),字符串只要想转换字节,就要用bytes n = bytes("编码", encoding="utf-8") print(n) n = bytes("编码", encoding="gbk") print(n) # 将字节转换为字符串 st = str(b'\xe7\xbc\x96\xe7\xa0\x81', encoding="utf-8") # 这段字节是有上面的字符串转换的 print(st) b'\xe7\xbc\x96\xe7\xa0\x81' b'\xb1\xe0\xc2\xeb' 编码
三
# callable()#检查函数是否能被调用,返回True、False def f1(): pass # f1()#能被调用 f2 = 123 # f2()# 这个不能被调用 print(callable(f1)) # 能被调用 print(callable(f2)) # 不能被调用 # 查看对应的ascii码 # ord()把ASCII转换成数字 # chr()则相反,把数字转换成ASCII r = chr(65) print(r) # A n = ord("a") print(n) # 97
# compile()#可以将字符串编译为python的代码 # 编译:single,eval,exec s = "print(123)" r = compile(s, "<string>", "exec") # 将字符串编译成python代码 print(r) # 执行 # exec()# 执行python代码,接收:代码或者字符串 ,只执行,没有返回值 exec(r) # 执行 # eval()#执行表达式,并且获取结果(有返回值) s = "8*8" ret = eval(s) print(ret)
# dir()#快速的查看一个对象为你提供了哪些功能 print(dir(list)) # help()#查看帮助信息 # help(list) # 共:97条数据,每页显示10条,需要多少页 r = divmod(100, 10) print(r) n1, n2 = divmod(100, 10) # 同时赋给两个变量 print(n1, n2) # 对象是类的实例 s = [11, 22, 33] # 用于判断,对象是否是某个类的实例 r = isinstance(s, list) # 前面是对象,后面是类 print(r)
# filter(函数,可迭代的对象)#返回True或False,用于过滤 def f2(a): if a > 22: return True li = [11, 22, 33, 44, 55] # filter内部,循环第二个参数 # result = [] # for item in 第二个参数: # r = 第一个参数(item) # if r : # result(item) # return result # filter,循环循环第二个参数,让每一个循环元素执行 函数,如果函数的返回值是True,表示元素合法 ret = filter(f2, li) print(list(ret)) # lambda版本的filter li = [11, 22, 33, 44, 55] ret = filter(lambda a: a > 33, li)#直接在放函数的位置进行筛选 print(list(ret))
open函数:
# 1、打开文件 # f = open("db", "r") # 只读 # f = open("db", "w") # 只写,写之前会把文件清空 # f = open("db", "x") # 文件存在,报错;不存在,创建并写内容 # f = open("db", "a") # 追加 # # f = open("db", "rb") # 以字节类型读,只要加上b,都是二进制,二进制表现在代码里面就是字节类型 # date = f.read() # print(date, type(date)) # # f = open("db", "ab") # f.write(bytes("test", encoding="utf-8")) # ab以字节方式写入文件,记得加上bytes以utf-8转换 # f.close() # r+ 用的最多 f = open("db", "r+", encoding="utf-8") # 如果打开模式无b,则read,按照字符读取 date = f.read(12) print(date) print(f.tell()) # tell获取当前指针的位置(永远是字节) f.seek(1) # r+既可读,又可写,如果这里面加入一个seek()方法,调整当前指针的位置(字节) f.write("777") # 写的时候,当前指针位置开始向后覆盖 f.close() # 2、操作文件 # read() #无参数,读全部;有参数, # b,按字节 # 无b,按字符 # tell() 获取当前指针位置(字节) # seek() 指针跳转到指定位置(字节) # write() 写数据,有b:写字节;无b:写字符; # close() 关闭文件,如果打卡了必须调用此方法 # fileno() 文件描述符 # flush() 强制刷新 # readable() 判断是否可读,返回True或False # readline() 仅读取一行 # truncate() 截断,指针位后的清空 # for循环文件对象 f = open(xxx) # for line in f: # print(line) # 通过源码查看功能 # 2、关闭文件 # f.close() with open("xb") as f: # with打开文件操作完成之后,会自动关闭文件 pass with open("db1") as f1, open("db2") as f2: # 可以同时打开多个文件 pass # 在代码块里面两个文件都打开,代码块执行完毕之后,两个文件都关闭
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。 打开文件的模式有: r ,只读模式【默认】 w,只写模式【不可读;不存在则创建;存在则清空内容;】 x, 只写模式【不可读;不存在则创建,存在则报错】 a, 追加模式【可读; 不存在则创建;存在则只追加内容;】 "+" 表示可以同时读写某个文件 r+, 读写【可读,可写】 w+,写读【可读,可写】 x+ ,写读【可读,可写】 a+, 写读【可读,可写】 "b"表示以字节的方式操作 rb 或 r+b wb 或 w+b xb 或 w+b ab 或 a+b 注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号