高可用Hadoop平台-Hue In Hadoop
1.概述
前面一篇博客《高可用Hadoop平台-Ganglia安装部署》,为大家介绍了Ganglia在Hadoop中的集成,今天为大家介绍另一款工具——Hue,该工具功能比较丰富,下面是今天为大家分享的内容目录:
- Hue简述
- Hue In Hadoop
- 截图预览
本文所使用的环境是Apache Hadoop-2.6版本,下面开始今天的内容分享。
2.Hue简述
Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览HBase数据库等等。
Hue在数据库方面,默认使用的是SQLite数据库来管理自身的数据,包括用户认证和授权,另外,可以自定义为MySQL数据库、Postgresql数据库、以及Oracle数据库。其自身的功能包含有:
- 对HDFS的访问,通过浏览器来查阅HDFS的数据。
- Hive编辑器:可以编写HQL和运行HQL脚本,以及查看运行结果等相关Hive功能。
- 提供Solr搜索应用,并对应相应的可视化数据视图以及DashBoard。
- 提供Impala的应用进行数据交互查询。
- 最新的版本集成了Spark编辑器和DashBoard
- 支持Pig编辑器,并能够运行编写的脚本任务。
- Oozie调度器,可以通过DashBoard来提交和监控Workflow、Coordinator以及Bundle。
- 支持HBase对数据的查询修改以及可视化。
- 支持对Metastore的浏览,可以访问Hive的元数据以及对应的HCatalog。
- 另外,还有对Job的支持,Sqoop,ZooKeeper以及DB(MySQL,SQLite,Oracle等)的支持。
下面就通过集成部署,来预览相关功能。
3.Hue In Hadoop
本文所使用的Hadoop环境是基于Apache社区版的Hadoop2.6,在集成到Hadoop上,Hue的部署过程是有点复杂的。Hue在CDH上是可以轻松的集成的,我们在使用CDH的那套管理系统是,可以非常容易的添加Hue的相关服务。然而,在实际业务场景中,往往Hadoop集群使用的并非都是CDH版的,在Cloudera公司使用将其贡献给Apache基金会后,在Hadoop的集成也有了较好的改善,下面就为大家介绍如何去集成到Apache的社区版Hadoop上。
3.1基础软件
在集成Hue工具时,我们需要去下载对应的源码,该系统是开源免费的,可以在GitHub上下载到对应的源码,下载地址如下所示:
git@github.com:cloudera/hue.git
我们使用Git命令将其克隆下来,命令如下所示:
git clone git@github.com:cloudera/hue.git
然后,我们在Hadoop账号下安装Hue需要的依赖环境,命令如下所示:
sudo yum install krb5-devel cyrus-sasl-gssapi cyrus-sasl-deve libxml2-devel libxslt-devel mysql mysql-devel openldap-devel python-devel python-simplejson sqlite-devel
等待其安装完毕。
3.2编译部署
在基础环境准备完成后,我们开始对Hue的源码进行编译,编译的时候,Python的版本需要是2.6+以上,不然在编译的时候会出现错误,编译命令如下所示:
[hadoop@nna ~]$ cd hue [hadoop@nna ~]$ make apps
等待其编译完成,在编译的过程中有可能会出现错误,在出现错误时Shell控制台会提示对应的错误信息,大家可以根据错误信息的提示来解决对应的问题,在编译完成后,我们接下来需要对其做对应的配置,Hue的默认配置是启动本地的Web服务,这个我们需要对其修改,供外网或者内网去访问其Web服务地址,我们在Hue的根目录下的desktop/conf文件夹下加pseudo-distributed.ini文件,然后我们对新增的文件添加如下内容:
vi pseudo-distributed.ini
[desktop] http_host=10.211.55.28 http_port=8000 [hadoop] [[hdfs_clusters]] [[[default]]] fs_defaultfs=hdfs://cluster1 logical_name=cluster1 webhdfs_url=http://10.211.55.26:50070/webhdfs/v1 hadoop_conf_dir=/home/hadoop/hadoop-2.6.0/etc/hadoop [beeswax] hive_server_host=10.211.55.17 hive_server_port=10000 # hive_conf_dir=/home/hive/warehouse [hbase] hbase_clusters=(cluster1|10.211.55.26:9090) hbase_conf_dir=/home/hadoop/hbase-1.0.1/conf
关于Hue的详细和更多配置需要,大家可以参考官方给的知道文档,连接地址如下 所示:
http://cloudera.github.io/hue/docs-3.8.0/manual.html
这里,Hue的集成就完成了,下面可以输入启动命令来查看,命令如下所示:
[hadoop@nna ~]$ /root/hue-3.7.1/build/env/bin/supervisor &
启动信息如下所示:
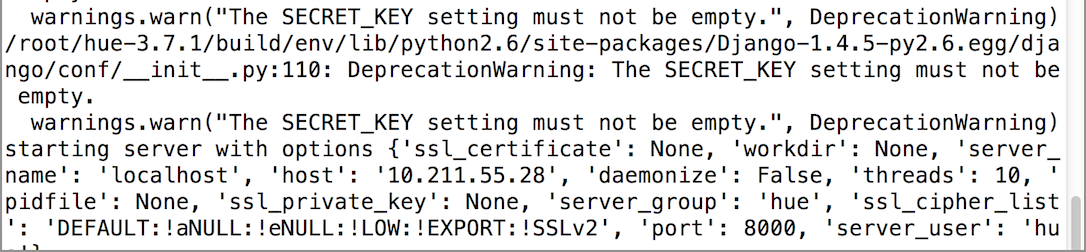
下面,在浏览器中输入对应的访问地址,这里我配置的Port是8000,在第一次访问时,需要输入用户名和密码来创建一个Administrator,这里需要在一步的时候需要注意下。
4.截图预览
下面附上Hue的相应的截图预览,如下图所示:



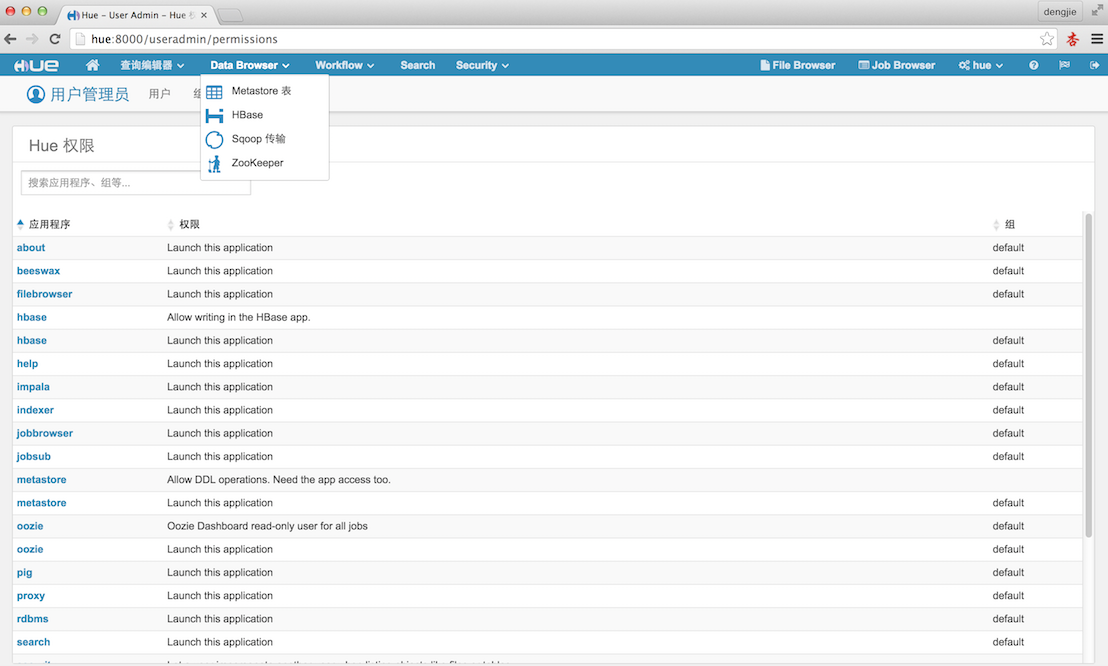

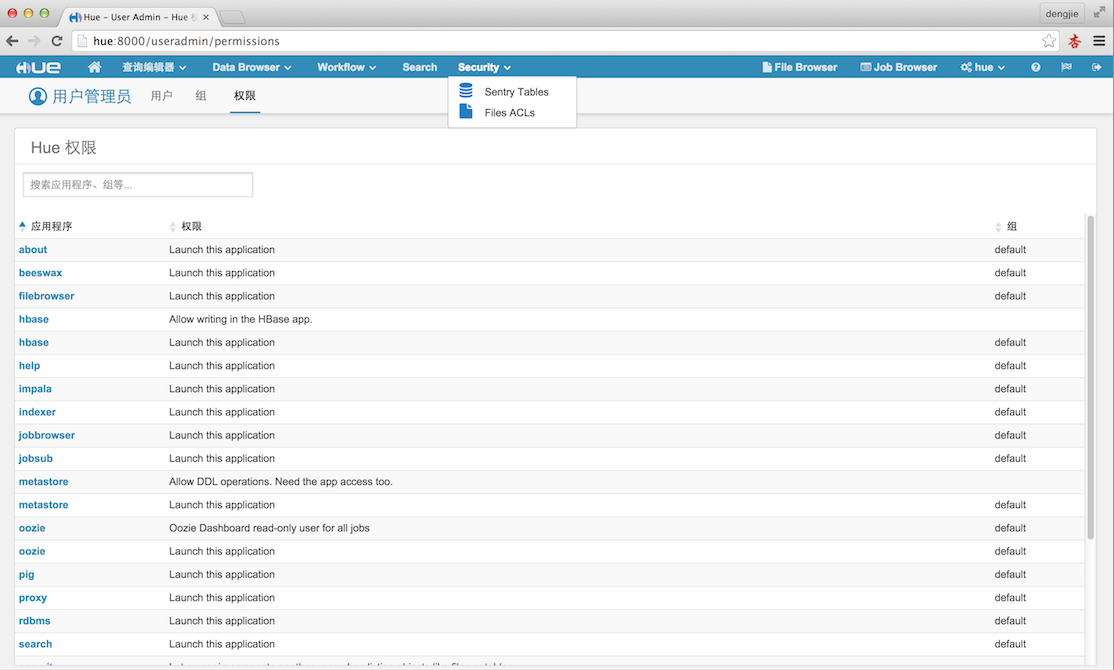
5.总结
在编译的时候,大家需要注意Hue的依赖环境,由于我们的Hadoop集群不是CDH版本的,所以在集成Hue的服务不能像CDH上那么轻松。在Apache的Hadoop社区版上集成部署,会需要对应的环境,若是缺少依赖,在编译的时候是会发生错误的。所以,这里需要特别留心注意,出错后,一般都会有提示信息的,大家可以根据提示检查定位出错误原因。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
邮箱:smartloli.org@gmail.com
QQ群(Hive与AI实战【新群】):935396818
QQ群(Hadoop - 交流社区1):424769183
QQ群(Kafka并不难学):825943084
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号