大模型基础
5、大模型基础
一、BERT模型
- 核心概念
BERT是2018年10月由Google AI研究院提出的一种预训练模型.
1、BERT是transformer编码器中的预训练方法(基于Transformer的Encoder部分)
2、双向上下文建模:通过掩码机制同时学习单词两侧的上下文信息
如同把人类语言翻译成"数学语言"。
- BERT预训练任务
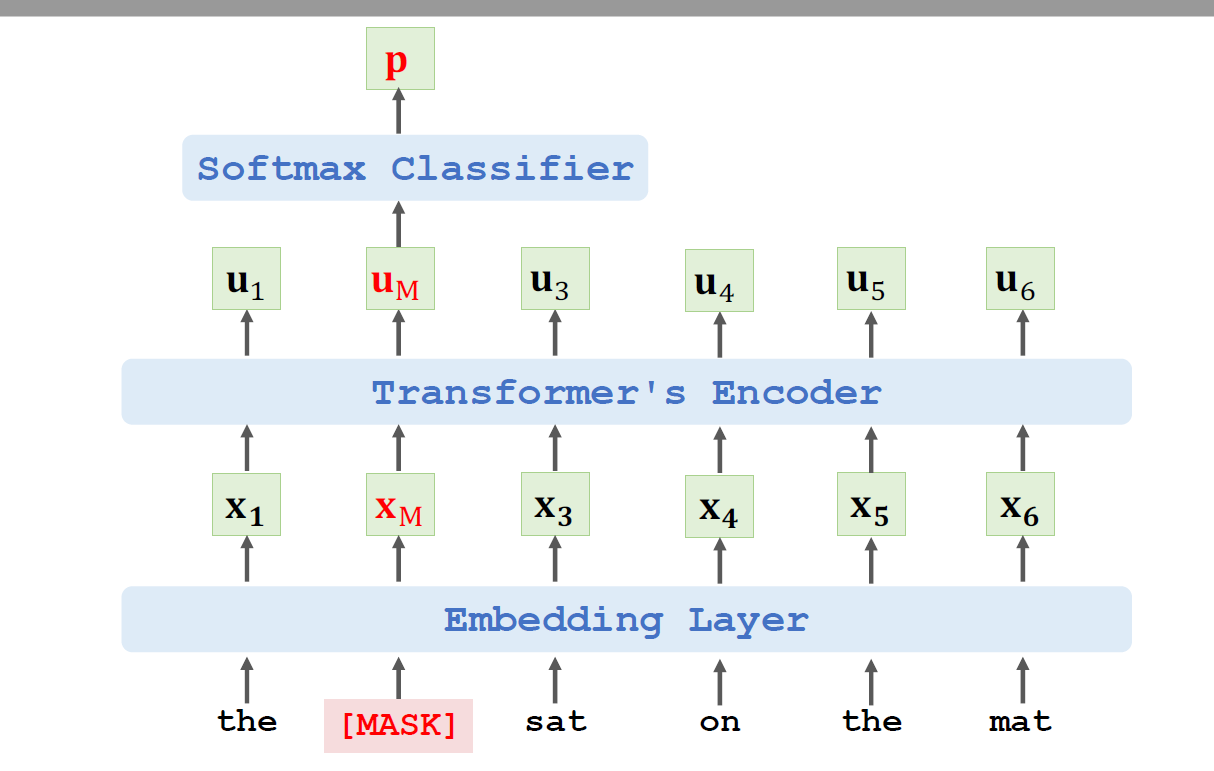
1、掩码语言建模:
随机掩盖输入句子中 15% 的单词(如:"The [MASK] sat on the mat")。
用Transformer编码器输出被掩盖位置的向量表示 Xₘ(Embeding layer)。
通过 Softmax分类器预测被掩盖的单词概率(如 "cat")。
损失函数:交叉熵损失函数
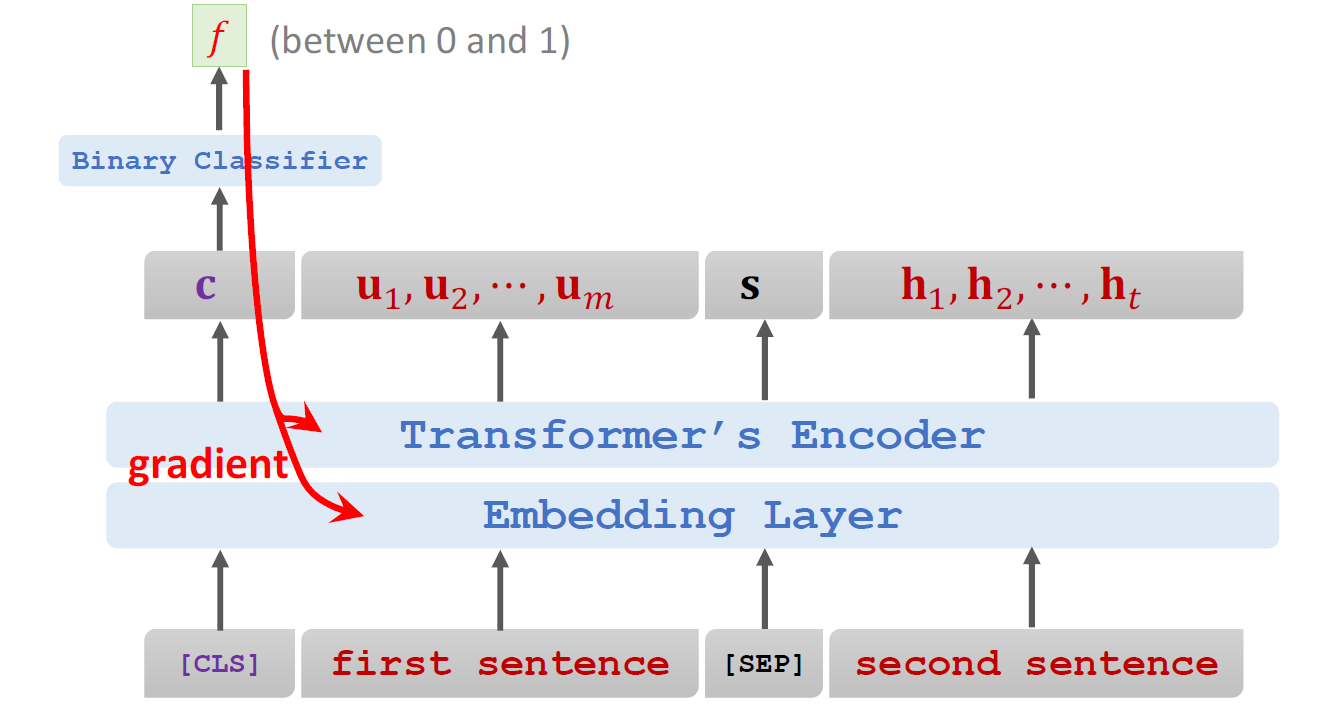
2、下一句预测:
目的:学习句子间关系。
方法:
输入格式:[CLS] 句子A [SEP] 句子B [SEP]
[CLS]:分类标记,输出用于NSP分类。
[SEP]:句子分隔标记。
正样本:句子B是句子A的真实下一句(如:"微积分是数学的分支" → "由牛顿和莱布尼茨发展")。
负样本:句子B为随机句子(如:"微积分是数学的分支" → "熊猫原产于中国中南部")。
用 [CLS] 位置的输出进行 二分类(0/1:是否相关)
梯度反向传播: 更新 NSP分类器参数 和 Encoder中与[CLS]相关的权重;更新 MLM分类器参数 和 Encoder中与被掩盖位置相关的权重;计算各层 、权重矩阵和 FFN参数的梯度;更新词向量矩阵(包括 [MASK]、[CLS]、[SEP] 等特殊标记的嵌入)。核心作用:将预测误差从输出层反向传递至底层,指导模型参数更新。
3、联合训练机制:
同时执行 MLM 和 NSP 任务。
总损失 = MLM损失(多分类) + NSP损失(二分类)。
输入格式示例:
"[CLS] calculus is a [MASK] of math [SEP] it [MASK] developed by newton [SEP]"
目标:NSP=True, "branch", "was"

4、数据来源:
无需人工标注:使用大规模无监督文本(如英文维基百科,25亿词)。
关键策略:
掩码技巧:15%单词被掩盖(其中80%替换为[MASK],10%替换为随机词,10%保留原词)。
NSP采样:50%正样本(真实下一句),50%负样本(随机句子)。
计算成本:
BERT-Base:1.1亿参数,16个TPU训练4天。
BERT-Large:2.35亿参数,64个TPU训练4天。

- 核心优点
1、性能卓越
在11项NLP任务上刷新SOTA(如GLUE、SQuAD),通过预训练+微调范式实现。
2、双向上下文建模
基于Transformer Encoder,同时捕捉左右两侧语境,突破GPT等单向模型的限制。
3、长距离依赖处理
利用Self-Attention机制,解决RNN的长程依赖退化问题,支持并行计算。
4、微调友好性
预训练后的统一结构可直接适配多种下游任务(如分类、QA),仅需添加输出层。
- 缺点
1、计算资源消耗大
参数量庞大(Base:110M,Large:340M),训练/推理成本高,实时场景应用受限。
2、中文处理局限
中文版以字为Token单位,无法利用词向量信息,生僻词被识别为[UNK]。
3、预训练-微调偏差
[MASK]标记仅在预训练出现,微调时消失,导致语义表示不一致。
4、训练效率低
MLM任务中仅15%的Token参与训练(85%不更新),收敛速度慢于自回归模型。
- 长文本处理
BERT最大输入长度为512,需截断处理:
1、头部截断(Head-only)
保留前510个Token(预留[CLS]和[SEP]位置)。
2、尾部截断(Tail-only)
保留后510个Token(优先保留结尾关键信息)。
3、首尾组合(Head+Tail)
动态分配:
文本≤800 Token:取前128 + 后382 Token
文本>800 Token:取前256 + 后254 Token

二、文本张量表示方法
- 核心目的
让计算机能处理文字(像人类理解语言),用于翻译、情感分析等任务。
- 基本形式(One-Hot编码)
每个词-->一个数字向量(词向量)
整段文本-->词向量组成的矩阵
示例:
["人生","该","如何"] →
[[1.2, 3.1], [0.5, 4.2], [2.1, 0.3]](每个词用2维向量表示)
- 三种文本表示方法比对
| 方法 | 原理 | 特点 | 示例 |
|---|---|---|---|
| One-Hot | 每个词分配唯一ID(身份证号) | ✅ 简单直接 ❌ 无法表达词义关系 ❌ 维度爆炸 | 猫=[1,0,0] 狗=[0,1,0] 鱼=[0,0,1] |
| Word2Vec | 根据上下文学习词义 | ✅ 词向量有语义(近义词靠近) ✅ 维度低(50-300维) | 国王 - 男人 + 女人 ≈ 女王 |
| Word Embedding | 更广义的词向量表示(含Word2Vec等) | ✅ 灵活适应不同任务 ✅ 现代NLP基础技术 | BERT、GPT等模型的核心技术 |
-
Word2Vec详解:通过上下文猜词
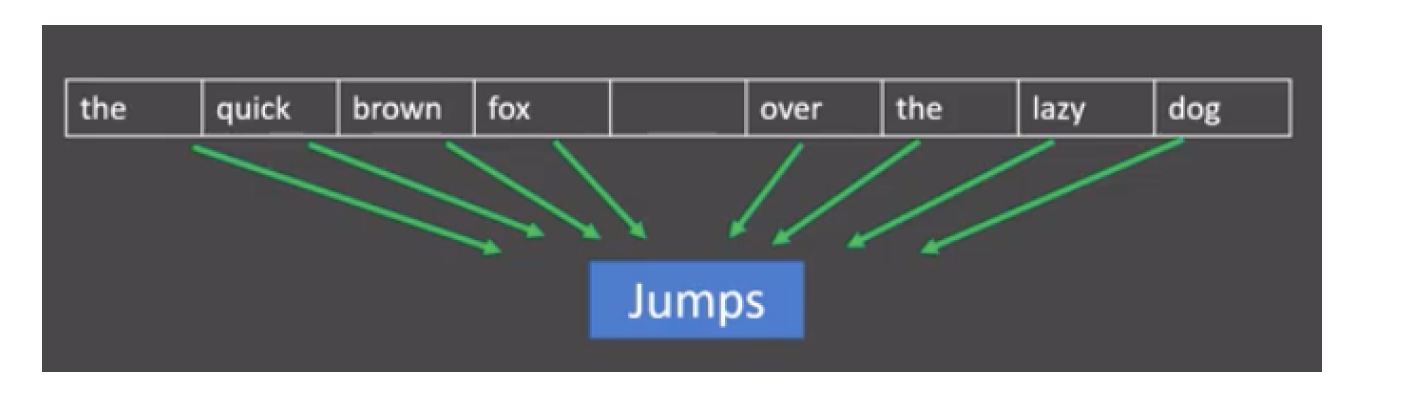
1、CBOW(连续词袋)
目标:用上下文词预测中心词
例子:
输入:["今天", "天气"] → 预测:"晴朗"
网络结构:输入层(上下文词) → 隐藏层 → 输出层(中心词预测)
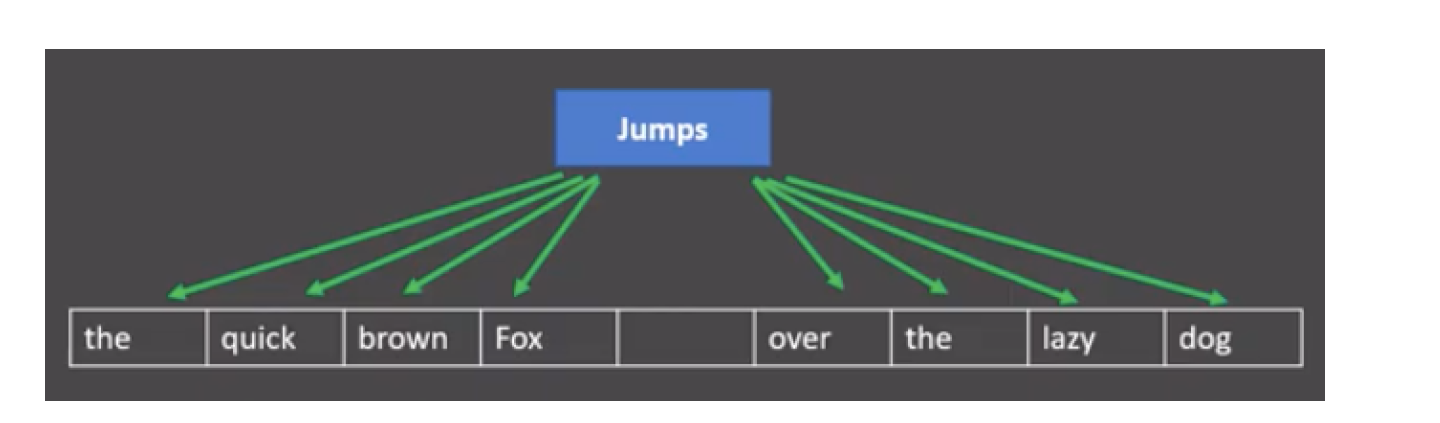
2、Skip-Gram
目标:用中心词预测上下文词
例子:
输入:"晴朗" → 预测:["今天", "天气"]
更擅长处理稀有词
- 模型训练四步曲
1、准备数据:用大规模的数据然后进行清洗。
2、训练模型:自动学习词向量
3、调参技巧:选择Skip-Gram(默认)更适合稀有词
维度:语料越大 维度越高(常用300维)
窗口大小:决定上下文的范围(一般5—10词)
4、模型softmax分布概率展示
- 三种方式的比对
| 方法 | 优势 | 局限 |
|---|---|---|
| One-Hot | 实现简单,5分钟上手 | 无法表达“猫和狗都是动物”这种关系 |
| Word2Vec | 捕获语义关系 节省内存 | 无法区分多义词(如“苹果”公司vs水果) |
| Embedding | 可结合深度学习灵活优化 | 需要大量训练数据和计算资源 |
- 总结(通俗理解)
One-Hot 像班级花名册每个学生有唯一学号(1,0,0...),但看不出谁和谁关系好
Word2Vec 像社交网络分析 经常一起出现的词是"朋友"(如"咖啡"和"奶茶")语义相近的词住得近("医院"-"医生"距离小于"医院"-"超市")
Embedding 像多功能身份证 不仅包含学号(基础信息) 还记录兴趣、能力等多维特征(适合不同任务需求)
三、常见的损失函数
- 1、损失函数的作用
衡量模型预测结果与标准答案的差距
类比理解:
考试评分标准 → 损失函数
学生答卷 → 模型预测
标准答案 → 真实值
损失函数值越低 → 模型越好(差距越小)
- 2、多分类交叉熵(softmax损失)
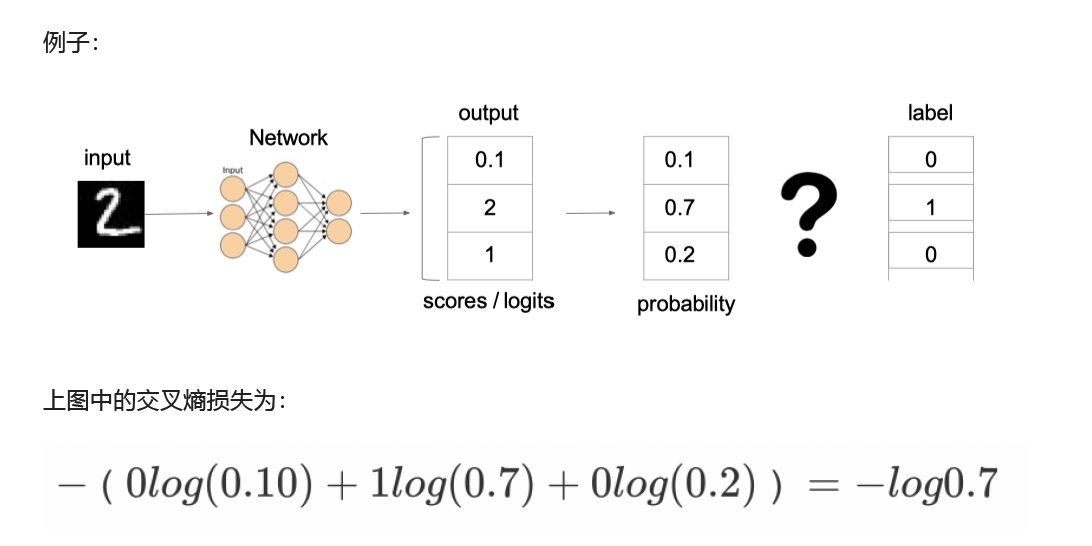
- 3、二分类交叉熵(sigmoid损失)

- 4、回归任务损失函数(预测数值)

- 实际生活应用
电商推荐系统 → 交叉熵
(预测用户点击「是/否」)
天气预报 → MSE
(严惩“暴雨报成晴天”的大错)
医学检测 → MAE
(避免单个异常样本影响模型)
自动驾驶 → Smooth L1
(平衡小幅抖动和严重偏离)
四、深度学习及大模型演进

- 传统深度学习模型演进:AlexNet-->VGG-->ResNet差异以及优化过程
AlexNet(2012)
核心改进:首次使用ReLU激活函数,解决梯度消失问题,加速训练。 Dropout正则化随机丢弃神经元,减少过于拟合。
局部响应归一化(LRN):增强局部特征对比度。首次利用双GPU大模型训练。
结构:5个卷积层+3个全连接层 重叠最大池化(3X3池化窗口,步长2)
VGGNet(2014)
深度是性能关键,统一使用3X3小卷积核堆叠
结构优化:所有卷积层均为3X3核(减少参数量,增加非线性) 2个3X3卷积层约等于1个5X5卷积的感受野,但参数更低。 VGG16/VGG19,层数显著着增加(16~19层)
结构简洁规整,易于迁移学习。
验证了深度对特征提取的重要性。
ResNet(2015)
核心创新:残差连接
解决深层网络梯度消失或者梯度爆炸问题
结构:残差块跨层连通道。支持极深网络(ResNet-152达152层)
训练1000层网络仍能收敛 ImageNet错误率低至3.57% 突破限制成为现代CNN基础结构
五、GPT模型
GPT是OpenAI公司提出的一种语言预训练模型.
OpenAI在论文<< Improving Language Understanding by Generative Pre-Training >>
中提出GPT模型.OpenAI后续又在论文
<< Language Models are Unsupervised Multitask Learners >>中提出GPT2模型.
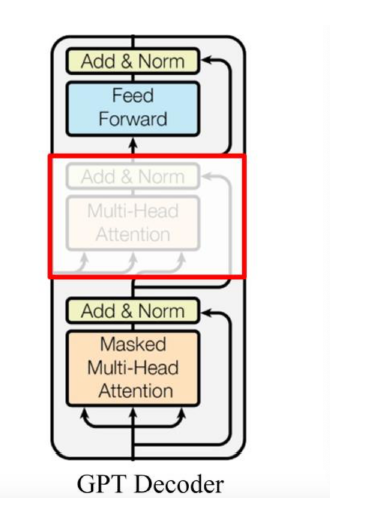
Transformer Decoder Block包含3个子层, 分别是Masked Multi-HeadAttention层, encoder-decoder attention层, 以及Feed Forward层. 但是在GPT中取消了第二个encoder-decoder attention子层, 只保留Masked Multi-Head Attention层, 和FeedForward层. 只能从左往右单向预测下一个文本。
对比于经典的Transformer架构, 解码器模块采用了6个Decoder Block; GPT的架构中采用了12个Decoder Block.
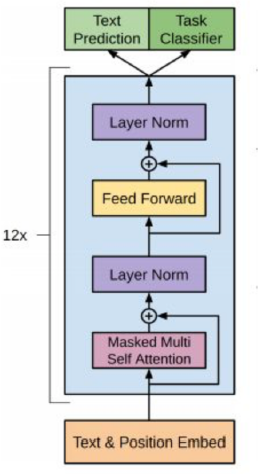
GPT1 (2018)
12层Transformer解码器(仅使用Masked Self-Attention) 训练约5GB文本有1.17亿参数量 无监督预训练 + 有监督微调:先预训练语言模型,再针对下游任务微调。
首次验证Transformer在生成任务的潜力。
GPT2 (2019)
核心突破:零样本学习能力 层数增进48层 隐藏层维度1600 训练数据约40GB 有15亿参数量
"所有任务都是文本生成":无需任务特定微调,通过提示(Prompt)直接生成结果。
强调规模化(Scaling Law):模型能力随数据/参数增长而提升。
GPT2模型是一个只包含了Transformer Decoder模块的模型.
GPT2的解码器在self-attention层上有一个关键的差异: 它将后面的单词(token)遮掩掉, 而BERT是按照一定规则将单词替换成[MASK].
GPT2可以处理最长1024个单词的序列.
GPT2本质上也是自回归模型.
输入张量要经历词嵌入矩阵和位置编码矩阵的加和后, 才能输入进transformer模块中.
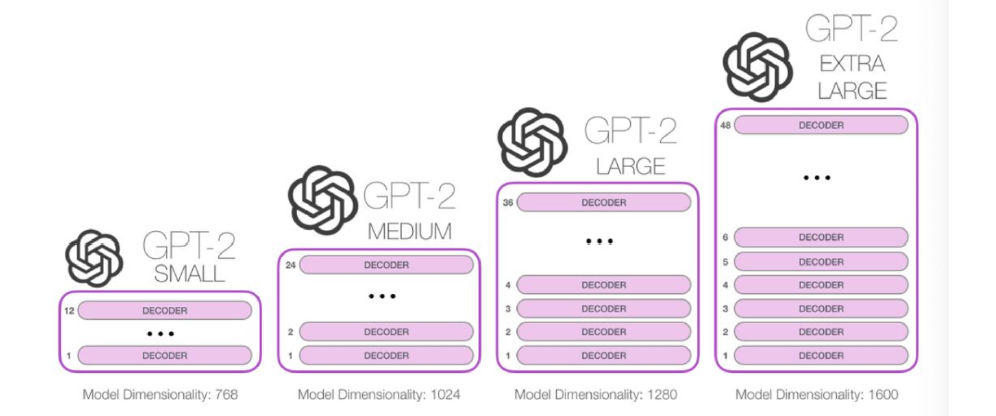
GPT3(2010)
核心革新:少样本上下文学习
架构: 96层Transformer,隐藏层维度12288 使用稀疏注意力降低计算量 训练混合数据集45TB 参数量1750亿
优化重点:上下文学习输入中给少量示范,模型直接推理。无需微调即可完成翻译、问答、编程等任务。
关键演进总结
| 维度 | GPT-1 | GPT-2 | GPT-3 |
|---|---|---|---|
| 参数量 | 1.17亿 | 15亿 | 1750亿 |
| 训练数据 | 5GB | 40GB | 45TB |
| 核心能力 | 任务微调 | 零样本学习 | 少样本上下文学习 |
| 结构改进 | 基础Transformer | 层数/维度增加 | 稀疏注意力 + 巨型规模 |
| 训练目标 | 语言模型预训练 | 多任务统一生成 | 通用任务泛化 |
六、VIT模型
1、ViT的核心思想**
-
图像分块处理
- 将图像分割为固定尺寸的非重叠/重叠区块(如16×16像素)。
- 用户指定参数:
patch_size(区块大小)、stride(步长,决定是否重叠)。
-
向量化表示
- 每个区块展平为向量:若区块尺寸为 d1×d2×d3d1×d2×d3(宽×高×通道),则向量维度为 d1d2d3d1d2d3。
- 示例:RGB图像(3通道)的16×16区块 → 16×16×3=76816×16×3=768 维向量。
2. Transformer编码器
- 核心模块:多头自注意力机制(Multi-Head Self-Attention)。
- 参数共享:所有区块共享相同的线性投影权重(降低参数量)。
- 层级结构:输入 → 位置编码 → Transformer Encoder × N层 → [CLS]输出 → Softmax分类器
3、训练策略与性能
两阶段训练**
| 阶段 | 数据规模 | 目标 |
|---|---|---|
| 预训练 | 超大规模数据集 | 学习通用视觉特征 |
| 微调 | 任务特定数据集 | 适配下游任务(如ImageNet分类) |
数据集规模对性能的影响**
| 预训练数据集 | 图像数量 | ViT vs ResNet性能 |
|---|---|---|
| ImageNet-1K | 130万 | ViT略差于ResNet |
| ImageNet-21K | 1400万 | 两者相当 |
| JFT-300M | 3亿 | ViT优于ResNet |
关键结论:ViT需大规模预训练(≥1亿图像)才能超越CNN。
- 小数据场景:CNN(如ResNet)仍占优。
- 大数据场景:ViT凭借全局注意力机制实现更高精度。
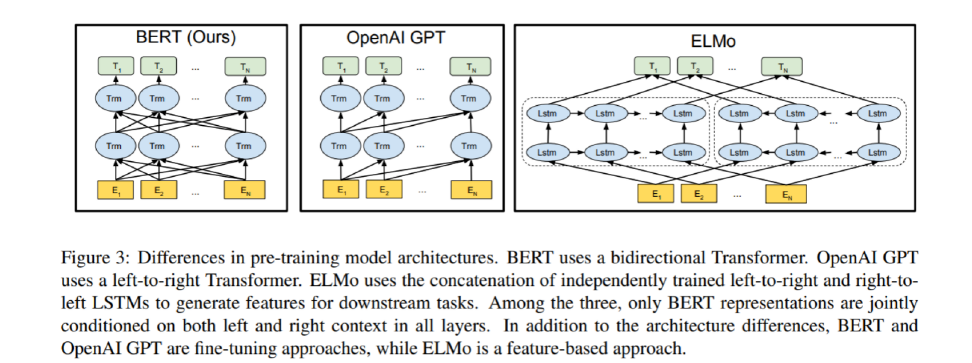
七、ELMo模型
- 简介
ELMo是2018年3月由华盛顿大学提出的一种预训练模型.
ELMo的全称是Embeddings from Language Models.
架构:最底层黄色标记的Embedding模块. 中间层蓝色标记的两部分双层LSTM模块. 最上层绿色标记的词向量表征模块.
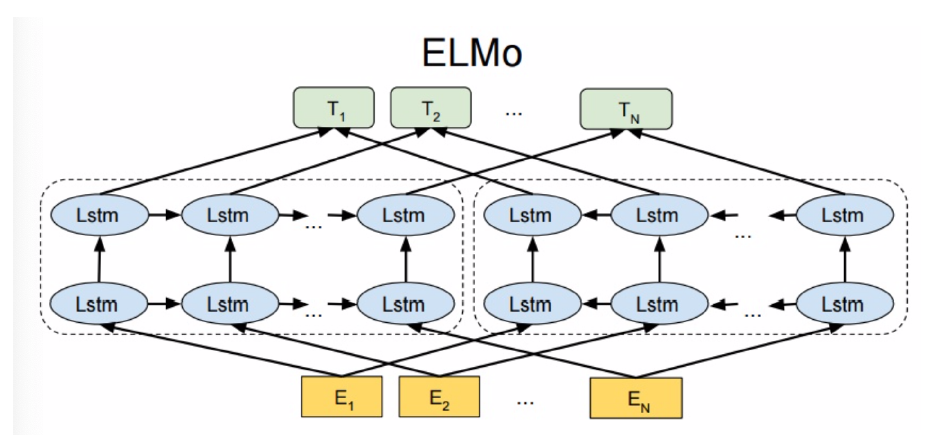
- 预训练
ELMo的本质思想就是根据当前上下文对word embedding进行动态调整的语言模型.
ELMo的预训练是一个明显的两阶段过程.
第一阶段: 利用语言模型进行预训练, 得到基础静态词向量和双向双层LSTM网络.
第二阶段: 在拥有上下文的环境中, 将上下文输入双向双层LSTM中, 得到动态调整后的word embedding, 等于将单词融合进了上下文的语义, 可以更准确的表达单词的真实含义.
本文来自博客园,作者:戴莫先生Study平台,转载请注明原文链接:https://www.cnblogs.com/smallzengstudy/p/18945486

 浙公网安备 33010602011771号
浙公网安备 33010602011771号