Transformer基础知识
4、Transformer基础知识
一、背景
BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!
论文地址:
https://arxiv.org/pdf/1810.04805.pdf
二、优势
相比于RNN/LSTM/GRU模型
1、transfomer能够利用分布式GPU进行并行训练,提高模型训练效率。
2、在分析预测更长文本时,通过自注意力机制捕捉间隔较长语义关联效果更好。
3、多任务通用性,可以调节输入输出方式,适用于多种任务也就是迁移学习。(如:机器翻译、文本生成、计算机视觉等)
三、总体架构
1、基于seq2seq架构的transformer模型可以完成NLP领域研究,同时可构建预训练语言模型,用于不同任务的迁移学习。(垂直领域训练学习、机器翻译、文本生成等)
2、transformer能将自然语言通过文本嵌入(Embedding)转换成多维词向量。
3、总体架构包含:输入部分、输出部分、编码器部分、解码器部分。其中输入部分含有源文本嵌入层及其位置编码器和目标文本嵌入层及其位置编码器;输出部分包含线性层、softmax激活函数层; transformer模型可以由n个编码器(encoding)和n个解码器(deconding)堆积而成; 编码器由多头自制力子层和规范层以及残差连接子层和前馈全连接层和规范层以及一个残差连接子层构成(两层子层); 解码器由两个多头自制力子层和规范层以及残差连接子层和一个前馈全连接层和规范层以及一个残差连接子层构成(三层子层)。
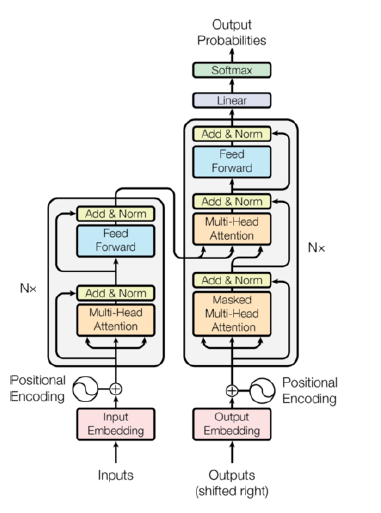
四、基本运行机制
文本从输入层通过文本嵌入转换成词向量进行编码器中,编码器通过自注意力机制把文本进行计算出每个词与其他词的关联性,生产新的表示,规范层把新的表示转换成正态分布防止文本过于疏散,接着输出编码好的文本复制三份到解码层的三个子层并行处理,解码器把编码好的文本通过前馈全连接层提取局部通用特征以及多头自注意力通过查询键值对(kv)获取全局信息,最终通过线性层和softmax生成概率分布(0~1之间)进行循环计算并最终输出所有的文本。
五、适合的场景
长序列任务 如机器翻译、文本摘要、DNA序列分析,需捕捉远距离依赖关系。
高并行性需求 需要快速处理大规模数据(如实时翻译、语音识别)时,Transformer的并行计算优势显著。
多任务通用性 需要模型适应多种下游任务(如问答、情感分析)时,可基于预训练Transformer(如BERT)进行微调。
非结构化数据建模 如自然语言、图像(ViT)、时序数 据(如金融预测),需建模全局上下文关系
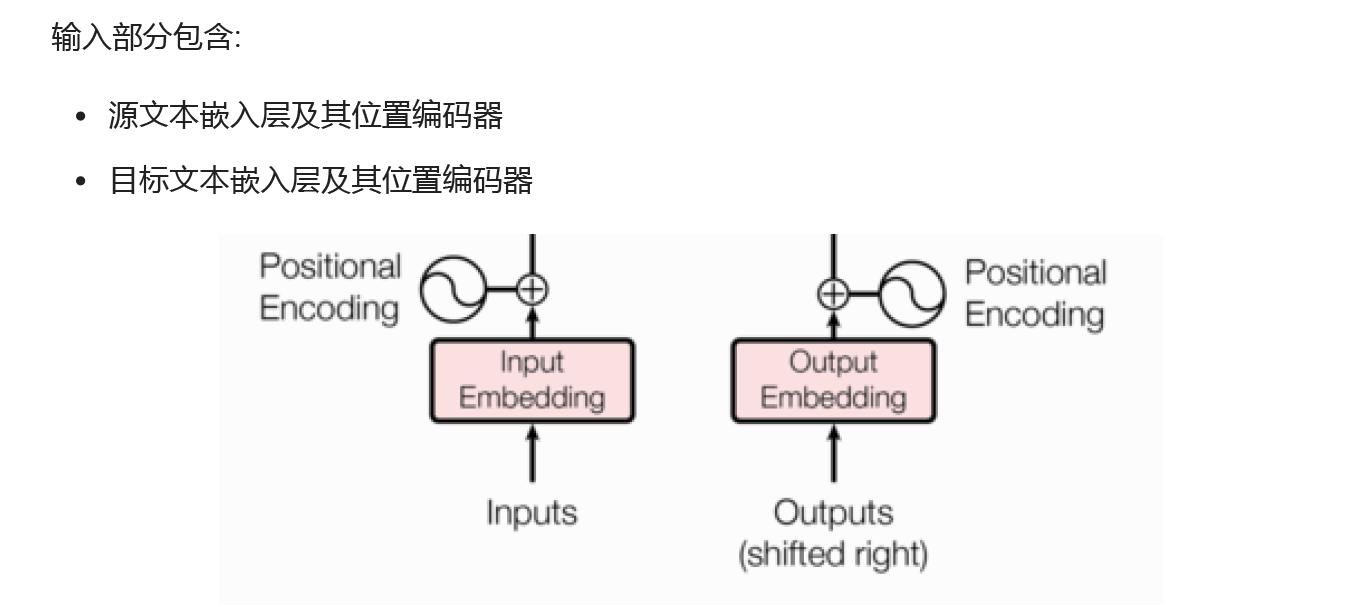
六、输入部分
作用:将文本转化为词向量,希望在高维空间捕捉词汇间的关系,最终输出的是文本嵌入后的结果。
位置解码器的作用:transformer编码器中,没有针对词汇位置的处理,加入位置编码器,将不同位置产生不同语义信息加入词嵌入张量中,弥补位置信息的缺失,最终输出词嵌入张量。
保证同一词汇随着所在位置不同它对应位置嵌入向量会发生变化.
正弦波和余弦波的值域范围都是1到-1, 这又很好的控制了嵌入数值的大小, 有助于梯度的快速计算.
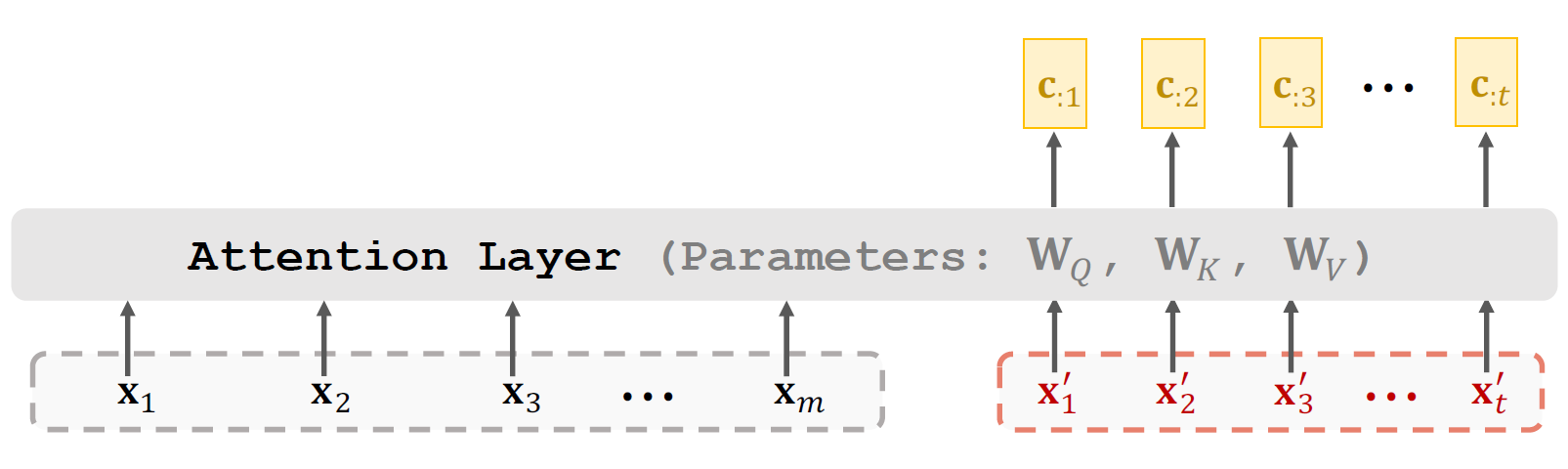
七、注意力机制(编码器)
优势:能够高效捕获序列中任意两个元素之间的依赖关系。
基本原理:每个元素通过生成一个查询向量,去询问序列中所有其他元素的k向量,计算一个相关性分数。然后根据这些分数对所有元素的v向量加权求和,得到新的该元素上下文信息的表示,两个不同序列之间的运算。
Attention(Q, K, V) = softmax((Q * K^T) / √d_k) * V

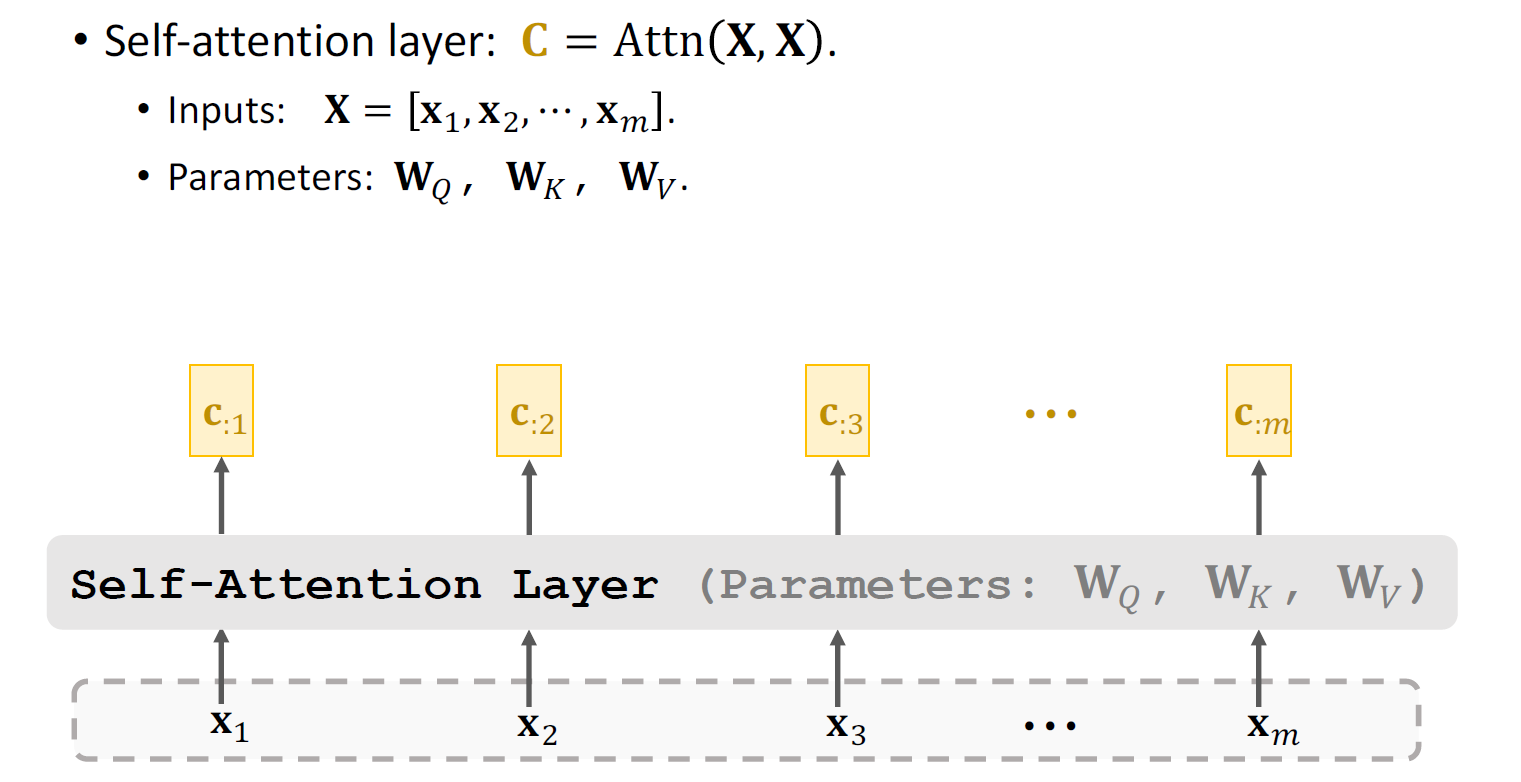
八、自注意力机制(解码器)
自注意力(Self-Attention)机制是 Transformer 模型的核心,它使模型能够动态地捕捉序列内部元素之间的依赖关系(无论距离远近),并为每个元素生成一个融合了全局上下文信息的新表示。其核心原理是通过序列元素自身生成的三组向量(Query, Key, Value)来计算元素间的关联度并加权聚合信息。
多头自注意力:通过多组独立的线性投影将输入序列映射到多个不同的表示子空间,在每个子空间内并行执行自注意力计算以捕获特定类型的依赖关系,然后将所有子空间的结果拼接并用一个最终的线性投影融合,极大地增强了模型捕获序列中多样化、复杂依赖关系的能力。
九、前馈全连接
在Transformer中前馈全连接层就是具有两层线性层的全连接网络.
考虑注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力.
通过一个高维中间层(d_ff,通常为 d_model 的 4 倍)对自注意力层输出的、已融合上下文的每个位置表示 zᵢ 进行深度非线性变换和特征加工
作用:
1、引入关键的非线性能力,弥补注意力层线性操作的不足。
2、显著提升模型的容量和表达能力(拥有大量参数)。
3、深化对每个位置(已含上下文)信息的理解与转换
4、与注意力层分工协作(注意力负责融合关系,FFN 负责加工特征)。
5、通过“bottleneck”结构高效实现特征变换与维度保持。
十、文本生成(TextGeneration)
核心思想:给定文本序列,预测下一个最可能出现的字符。
迭代生成:将预测出的新字符加入输入序列,重复预测过程,可拓展到任意长度的文本。
关键依赖:通过文本训练统计规律,生产类似风格的新文本。
- 模型架构:(RNN/LSTM)
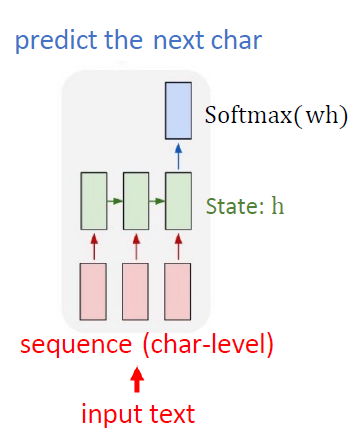
输入一段字符序列,序列通过RNN或LSTM单元逐步处理。每个时间步接收一个字符输入并更新隐藏状态(承载历史信息),在序列末尾最终的隐藏状态通过一个全连接层(Dense)+softmax激活函数,输出一个概率分布,表示所有字符成为下一个字符的概率。
示意图:输入序列 -> RNN/LSTM (更新隐藏状态 h) -> 最终h -> Dense层 -> Softmax -> 概率分布
- 训练流程归纳
- 数据准备:
- 源文本:任意长文本(如莎士比亚著作、Linux源码、婴儿名字列表)。
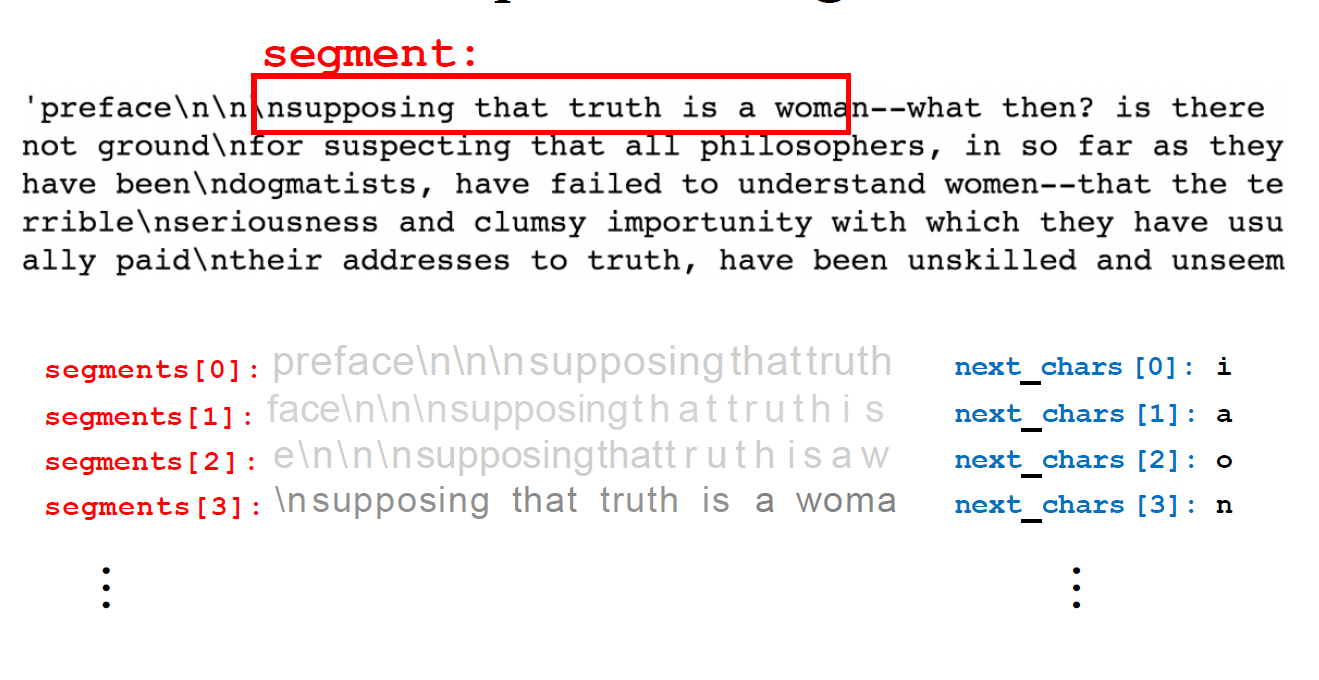
- 滑动窗口切割:
- 设定窗口长度
seg_len(如40) 和步长stride(如3)。- 将长文本切割成多个重叠的短文本片段 (
segment)。- 示例:
"Machine learning is a subset of artificial intellig" -> "achine learning is a subset of artificial intell" -> ...- 构建训练对:
输入 (X):一个文本片段 (segment)。标签 (y):该片段紧接着的下一个字符 (next_char)。- 结果:得到大量
(segment, next_char)样本对。
2、字符编码:
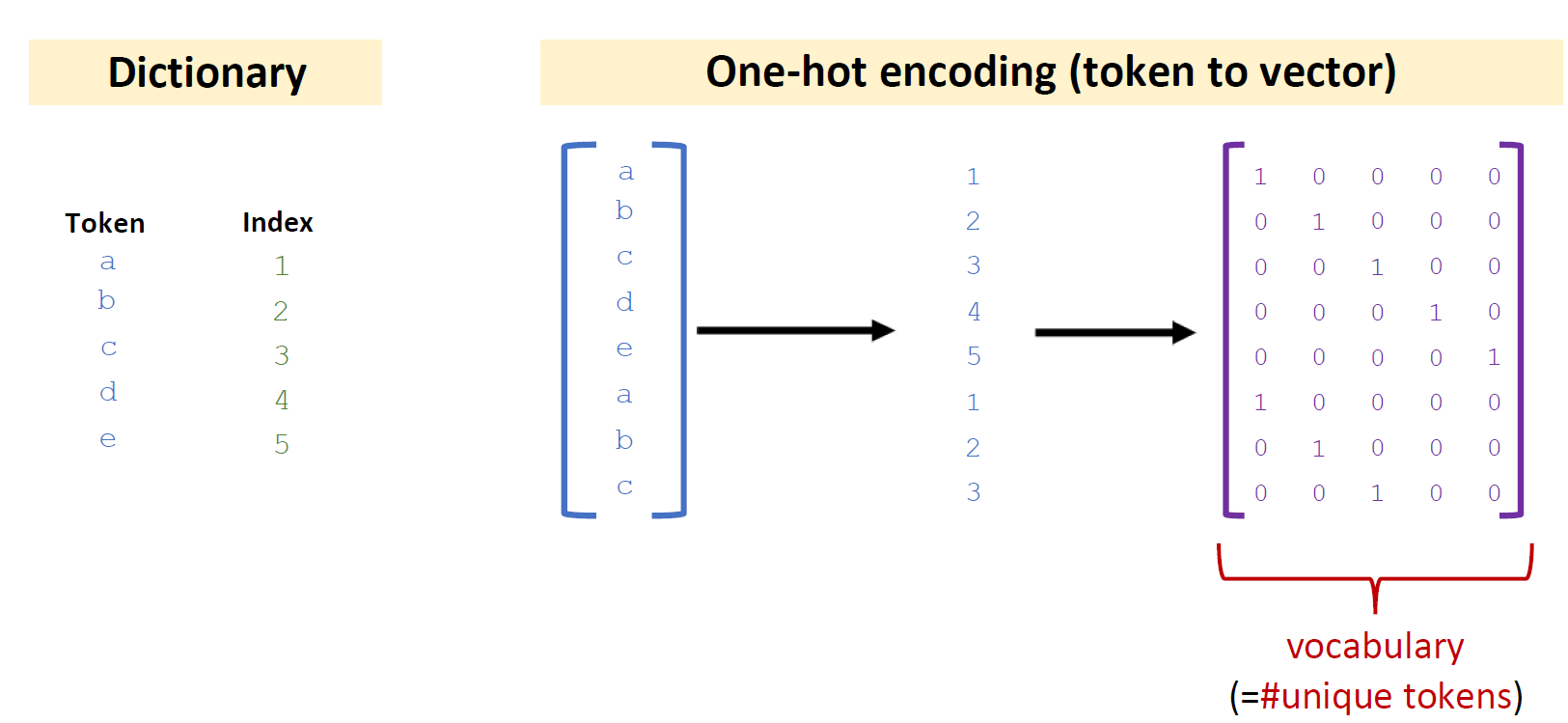
- 构建词典:
- 统计训练文本中所有唯一字符(字母、空格、标点等)。
- 为每个字符分配唯一整数
索引 (Index)。- 示例词典:
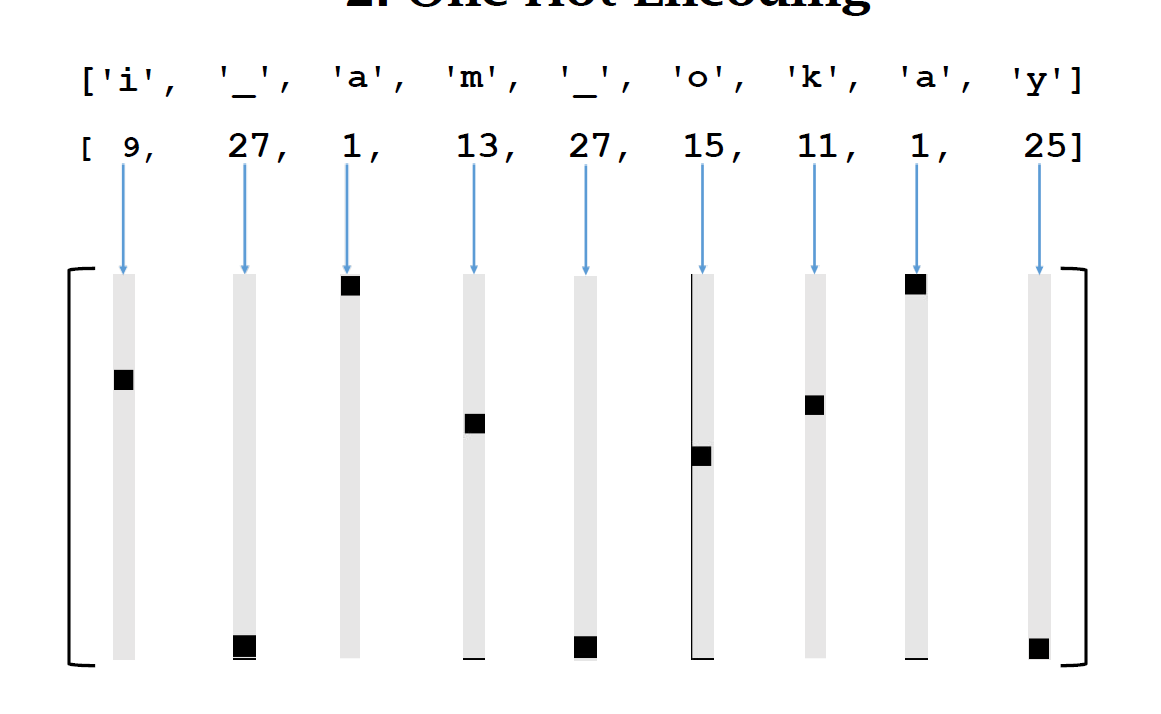
'a'->1, 'b'->2, ..., ' '->27, '\n'->28, ...- 向量化 (One-Hot Encoding):
- 将
segment中的每个字符转换为其对应的 One-Hot 向量(长度=词典大小v,对应索引位置为1,其余为0)。- 将
segment转换为l × v矩阵(l=片段长度)。- 将
next_char转换为其对应的 One-Hot 向量(v × 1)。
3、模型训练:
- 输入:
l × v矩阵(表示一个文本片段)。- 模型:
RNN/LSTM层 -> Dense层 (v个神经元) -> Softmax。- 输出:
v × 1向量(下一个字符的概率分布)。- 损失函数:交叉熵损失 (Cross-Entropy Loss)。比较模型输出的概率分布
p与真实next_char的 One-Hot 向量y。- 优化:通过反向传播和优化算法(如Adam)更新网络权重,最小化损失。这是一个多类分类问题(类别数 = 词典大小
v)。

- 文本推理
- 初始化:提供一个种子文本 (
seed),长度需等于训练时的seg_len(如"the cat sat on the")。- 自回归生成:
- a) 将当前文本片段 (
segment) 进行 One-Hot 编码 (l × v矩阵)。- b) 输入模型,得到下一个字符的概率分布
pred(v × 1向量)。- c) 关键:选择下一个字符 (三种策略):
- Option 1: 贪心搜索 (Greedy):
next_index = np.argmax(pred)。选择概率最高的字符。缺点:生成文本可能过于保守、重复。- Option 2: 原始采样 (Multinomial Sampling):
next_onehot = np.random.multinomial(1, pred, 1); next_index = np.argmax(next_onehot)。完全按概率随机选择。缺点:生成文本可能过于随机、不连贯。- Option 3: 温度采样 (Temperature Sampling - 推荐):
- 调整概率分布:
pred = pred ** (1 / temperature)- 重新归一化:
pred = pred / np.sum(pred)- 按调整后的分布采样:
next_onehot = np.random.multinomial(1, pred, 1); next_index = np.argmax(next_onehot)- 温度
temperature的作用:
temperature → 0:接近贪心搜索 (确定性高)。temperature → 1:接近原始采样 (随机性高)。temperature > 1:使分布更均匀 (更随机)。temperature < 1:使分布更尖锐 (更集中,更确定)。(PPT图示展示了不同temperature的效果)- d) 根据
next_index从词典中找到对应的字符 (next_char)。- e) 将
next_char追加到生成的文本中。- f) 更新
segment:移除原segment的第一个字符,将next_char添加到末尾 (保持长度l不变)。
- 终止:重复步骤 a-f,直到生成所需长度或遇到特定终止符。

- 应用示例
婴儿名字生成:在8000个婴儿名字上训练,模型生成类似风格的新名字 (如"Rudi Levette Berice Lussa ...")。
C代码生成:在Linux内核源码上训练,模型生成具有C代码语法结构的文本。
学术论文生成 (LaTeX):在LaTeX格式的学术文章上训练,模型生成包含章节、公式等结构的伪论文文本。
十一、语言翻译(示例)
任务:将英语文本序列转换为德语文本序列
模型:Seq2Seq模型=>编码器:将输入的文本序列压缩成一个固定维度的上下文向量 解码器:接收上下文向量逐步生成目标序列。
- 处理流程
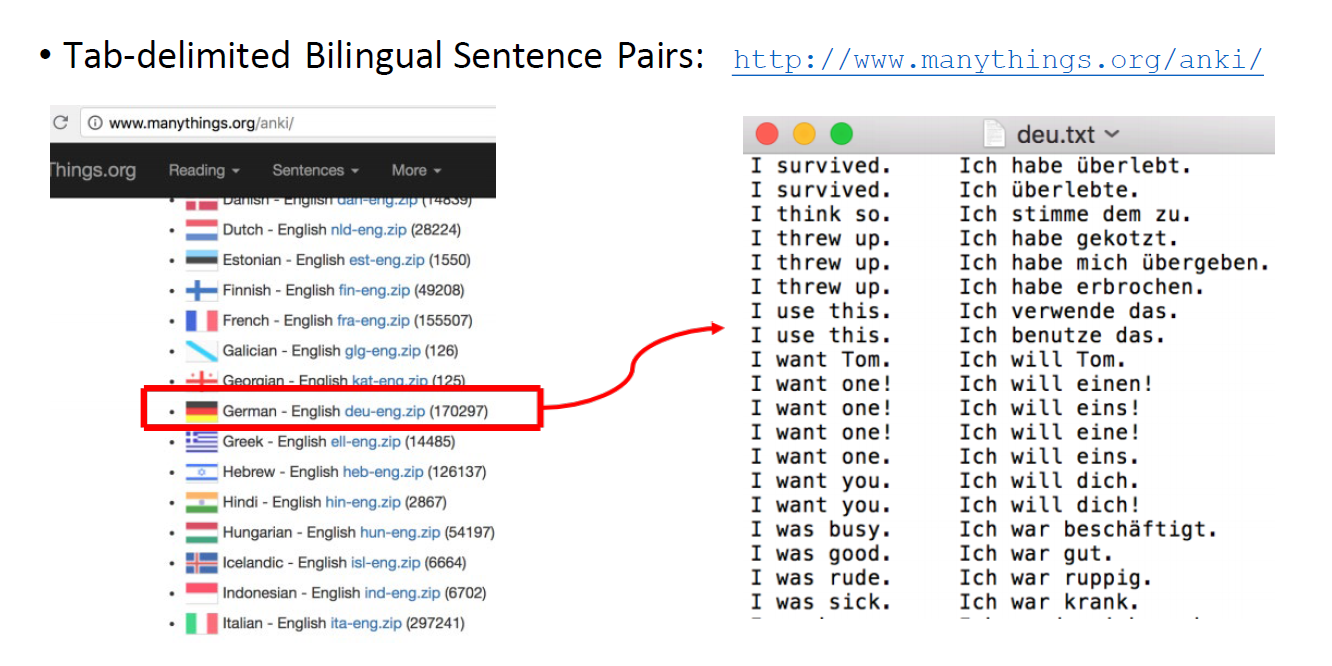
1、数据获取:使用tab分割的双语句对数据集
2、预处理:数据获取 统一大小写 去除标点符号
3、分词语词典构建:将句子拆成单个字符或者将句子拆分为单词,为每种语言的每个唯一token分配一个整数ID
4、向量化:将分词后的序列中的每个ID转换为一个One-Hot向量
- 模型训练
将编码器处理后的序列输入解码器中进行处理,在时间t解码器接收上一个时间步的状态和上一个时间步的真实目标token,最终输出下一个目标token的概率分布。
使用交叉熵损失函数,将模型分布p与当前时间步的2真实目标token的One-Hot向量y进行比较。
重复生成token概率分布以及预测概率分布与时间同步的真实目标token One-Hot向量y比较,直到预测结束符停止。
- 编写代码思想
使用基于GRU的seq2seq模型架构实现翻译的过程
1、下载和准备训练数据集
2、对数据进行预处理并处理一个数据集
3、构建模型并选择优化器和损失函数
4、构建训练函数并进行训练
5、构建评估函数进行预测分析
本文来自博客园,作者:戴莫先生Study平台,转载请注明原文链接:https://www.cnblogs.com/smallzengstudy/p/18943533

 浙公网安备 33010602011771号
浙公网安备 33010602011771号