神经网络基础
3、神经网络基础
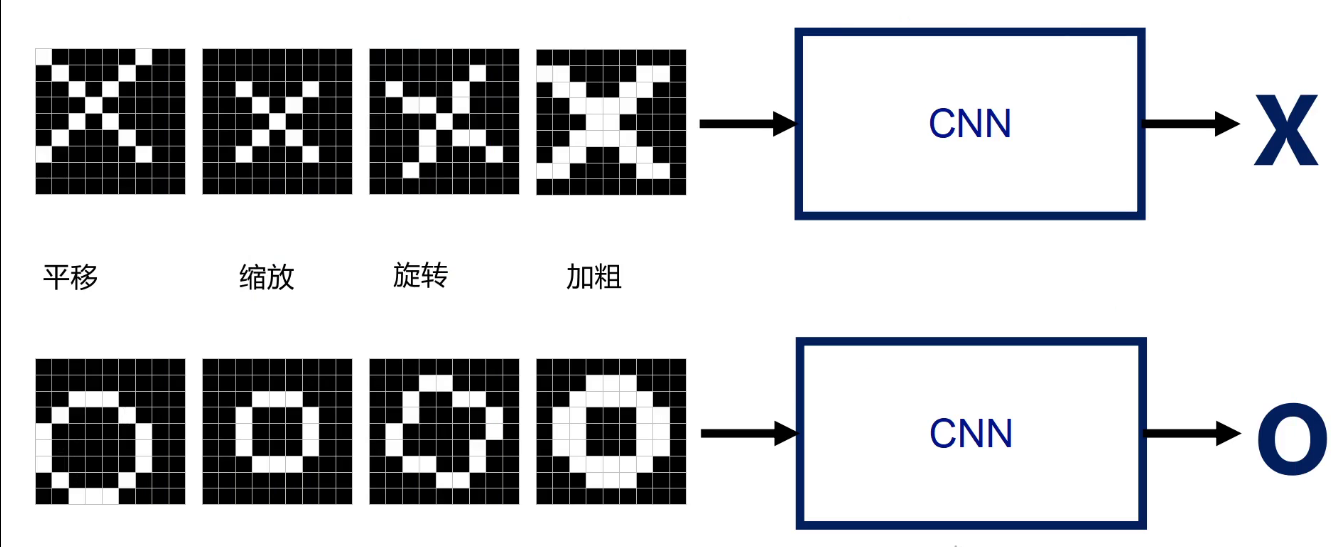
一、计算机视觉
计算机图像是多维的 而文本是二维的具有强相关性 比如:明明请我吃饭 我请明明吃饭 完全意思就不一样。
二、图像分类
给不同的图像给予不同的标签来识别图像。 像素图==>特征图==>特征融合==>输出
9格像素中每个格向量相乘求平均,值越高图像相识度越高 接近1表示匹配度越好。 CNN卷积层进行运算识别得出的分数越高越相识。
四宫格卷积层运算后取最大池化数值。
分类:输出图片的类别 比如:识别乳腺癌图像
回归:预测一个数值。比如:预测股票
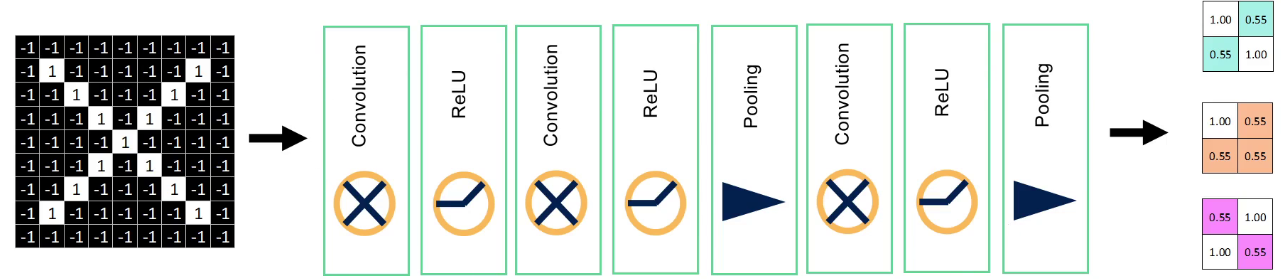
三、CNN
卷积层->激活函数层->池化 卷积神经网络经过卷积操作以后图像会越来越小。 图生文 文生图
xxxxxxxxxx 算力资源消耗巨大:需要大量的CPU和显卡资源以及消耗用电量。算力资源分配不均:美国对技术垄断、闭源,国内大公司对商业先进模型闭源。数据获取难度高:涉及到数据隐私问题,隐私数据一般不公开。比如过去股市、股民数据。模型幻觉问题:对敏感问题回答存在伦理问题,敏感词识别。比如:台湾是否是中国的?架构局限性:架构计算复杂度越来越高,数据处理能力有瓶颈。实时性要求:计算复杂度高导致响应延迟、串行解码(编码解码)、资源消耗大等技术限制,同时与应用场景的高实时性需求存在显著差距。应用经验不足:AI与公司业务结合刚刚起步,存在行业融合实战经验不足。行业认知障碍:每个行业的专业知识不同,模型对专业性问题回答存在歧义或不够专业。学习方法:为什么? 是什么? 怎么做? 什么时候做?txt
共8层:5层卷积层和2层全连接隐藏层以及1个全连接输出层。
第一层卷积核形状11X11 第二层缩小到5X5 第三层全采用3X3 所有池化窗口大小为3X3 步幅为2最大池化。
将sigmoid激活函数改成成ReLU激活函数 使计算更简单 网络更容易训练。
dropout来控制全连接层的模型复杂度 随机清除一些噪声异常神经元 只有一轮不参与。
引入大量的图像增强 翻转 裁剪 颜色变化 进一步扩大数据集来缓解过拟合。
AlexNet上下两支是为了方便同时使用两片GPU并行训练 在第三层卷积核全连接层处 上下两支信息可交互 两支网络完全一致

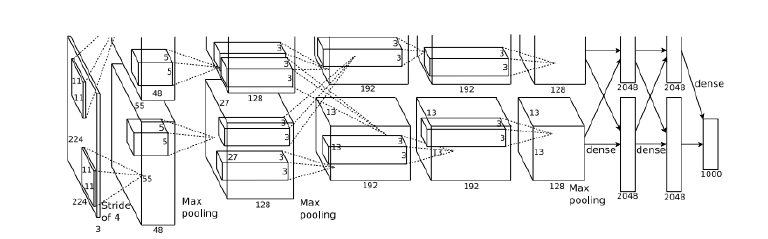
五、ALexNet案例分析
import tensorflow as tf
# 创建一个网络序列
net = tf.keras.models.Sequential([
# 创建卷积层 输出96个卷积核 使用11*11卷积核 卷积步数为4 使用relu激活函数
tf.keras.layers.Conv2D(filters=96,kernel_size=11,strides=4,activation='relu'),
# 对特征图进行 池化:3*3像素取最大值 步数为2
tf.keras.layers.MaxPool2D(pool_size=3,strides=2),
# 卷积 256 3*3 输入和输出一致 使用relu激活函数
tf.keras.layers.Conv2D(filters=256,kernel_size=5,padding='same'
,strides=2,activation='relu'),
# 池化 3*3 2
tf.keras.layers.MaxPool2D(pool_size=3,strides=2) ,
# 卷积 384 3*3 1 Relu same
tf.keras.layers.Conv2D(filters=384,kernel_size=3,strides=1,padding='same',activation='relu'),
#池化 3*3 2
tf.keras.layers.MaxPool2D(pool_size=2,strides=2),
# 展开
tf.keras.layers.Flatten(),
# 全连接层 输出4096个神经元 relu
tf.keras.layers.Dense(1024,activation='relu'),
# 随机失活 表示在训练阶段,每个神经元被随机丢弃的概率为 50%。 提高泛化能力 0~1范围
tf.keras.layers.Dropout(0.5),
# 输出层 于将输入特征映射到 512 维空间 Softmax 激活函数 能直接输出概率分布。
tf.keras.layers.Dense(512,activation='softmax')
])
# 加载 MNIST 数据集
from tensorflow.keras.datasets import mnist
import numpy as np
# 将数据集拆分为 训练集 和 测试集
(train_images,train_labels),(test_images,test_labels)=mnist.load_data()
# 为灰度图像添加通道维度,使其适配 CNN 的输入格式 模型数 长 宽 灰度:1 彩色:3
train_images= np.reshape(train_images,(train_images.shape[0],train_images.shape[1],train_images.shape[2],1))
# 为测试集图片添加通道维度
test_images=np.reshape(test_images,(test_images.shape[0],test_images.shape[1],test_images.shape[2],1))
print(train_images.shape[0]) # 模型数量
print(train_images.shape[1]) # 长
print(train_images.shape[2]) # 宽
print(train_images.shape[3]) # 渠道 1 表示灰度显示 3 表示彩色显示 RGB
print(test_images.shape[0])
print(test_images.shape[1])
print(test_images.shape[2])
print(test_images.shape[3])
# 对训练数据进行抽样
def get_train(size):
# 随机生成index 从[0,60000)中选取size数量的随机数
index = np.random.randint(0,train_images.shape[0],size)
# 选择图像并进行resize
resize_image = tf.image.resize_with_pad(train_images[index],227,227)
return resize_image.numpy(),train_labels[index]
# 对测试数据进行抽样
def get_test(size):
index = np.random.randint(0,test_images.shape[0],size)
resize_image = tf.image.resize_with_pad(test_images[index],227,227)
return resize_image.numpy(),test_labels[index]
# 获取抽样结果
train_images,train_labels = get_train(256)
test_images,test_labels = get_test(128)
import matplotlib.pyplot as plt
for i in range(9):
# 生成前9张 3X3比例的图
plt.subplot(3,3,i+1)
# 以灰度图发布 将(60000,28,28,1)转换为有符号整型并去除值为1的维度==>(60000,28,28) 如果数值为[0,1)的浮点型会转换失败
# interpolation='none' 禁用插值算法,直接显示每个像素 图像保持像素化效果(无模糊或平滑),
# '适合查看原始像素分布
plt.imshow(train_images[i].astype(np.int8).squeeze(),cmap='gray',interpolation='none')
# 设置图片对应的标题 对应的类别
plt.title("number{}".format(train_labels[i]))
# 显示生成的图片
plt.show()
plt.imshow(train_images[4].astype(np.int8).squeeze(),cmap='gray')
plt.show()
# 配置深度学习模型的训练过程
# 使用 随机梯度下降(Stochastic Gradient Descent, SGD)作为优化器,并设置学习率为 0.01。
# SGD:通过计算损失函数的梯度,逐步调整模型参数以最小化损失。
# 学习率(learning_rate):控制参数更新的步长。值过大可能导致模型不稳定,值过小可能导致收敛速度慢。
# 典型值:学习率通常在 [0.001, 0.1] 范围内,0.01 是一个常见的初始选择。
# 使用 稀疏分类交叉熵(Sparse Categorical Crossentropy)作为损失函数
# 在训练和验证过程中,监控 准确率(Accuracy)
net.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),loss=tf.keras.losses.sparse_categorical_crossentropy,metrics=['accuracy'])
# 训练神经网络模型
# epochs:训练次数 太少的 epochs 可能导致欠拟合,太多可能导致过拟合
# 从训练数据中划分出 5% 的数据作为验证集 验证集用于评估模型在训练过程中的泛化性能(防止过拟合)
# 根据 verbose=1 的设置,显示每个 epoch 的训练和验证结果
net.fit(train_images,train_labels,epochs=5,validation_split=0.05,verbose=1)
# 通过 evaluate 方法,可以最终确认模型在真实场景中的性能,是机器学习流程中不可或缺的一步。
net.evaluate(test_images,test_labels,verbose=1)
六、图像增强案例
# 对图像的翻转 左右平移 缩放 色彩调节
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 加载图片
cat = plt.imread('./img/cat.jpg')
# 加载显示图片
plt.imshow(cat)
# 显示
# 随机猫图像左右位置转换
cat1 = tf.image.random_flip_left_right(cat)
plt.imshow(cat1)
# 随机猫图像上下位置转换
cat2 = tf.image.random_flip_up_down(cat)
plt.imshow(cat2)
# 图像裁剪 200*200 彩色发布 3
cat3 = tf.image.random_crop(cat,(200,200,3))
plt.imshow(cat3)
# 图像随机曝光度 0表示原图显示 数值越大图像越模糊 1表示黑色显示
cat4 = tf.image.random_brightness(cat,0.5)
plt.imshow(cat4)
# 随机变化图像的色调 最大值不能超过[0,0.5] 值越大色调越强
cat5 = tf.image.random_hue(cat,0.3)
plt.imshow(cat5)
# plt.show()
# 导入mnist数据集 使用图像增强类进行图像增强
from tensorflow.keras.datasets import mnist
# 获取数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 将训练数据集和测试数据 图像数据集合(x轴)转为4维度
x_train = np.reshape(x_train,(x_train.shape[0],28,28,1))
x_test = np.reshape(x_test,(x_test.shape[0],28,28,1))
# tf.keras.preprocessing.image.ImageDataGenerator() 是一个用于图像数据增强的类,它可以在训练深度学习模型时自动生成批次的图像数据。这个类有很多参数,下面是一些常用的参数及其解释:
#
# rescale: 缩放因子,用于将图像像素值缩放到0-1之间。默认值为None,表示不进行缩放。
#
# validation_split: 验证集的比例。例如,设置为0.2表示从训练集中抽取20%的数据作为验证集。默认值为0.0。
#
# horizontal_flip: 是否随机水平翻转图像。默认值为False。
#
# vertical_flip: 是否随机垂直翻转图像。默认值为False。
#
# width_shift_range: 水平方向上随机平移的范围(相对于总宽度的比例)。默认值为0.0。
#
# height_shift_range: 垂直方向上随机平移的范围(相对于总高度的比例)。默认值为0.0。
#
# rotation_range: 随机旋转的角度范围(以度为单位)。默认值为0。
#
# zoom_range: 随机缩放的范围。例如,设置为0.1表示图像可以在原始尺寸的基础上缩小到90%或放大到110%。默认值为0.0。
#
# channel_shift_range: 随机通道偏移的范围。默认值为0.0。
#
# fill_mode: 当进行变换时超出边界的填充方式。可选值有'nearest'(最近邻插值)、'constant'(常数填充)、'reflect'(反射填充)和'wrap'(环绕填充)。默认值为'nearest'。
#
# cval: 当fill_mode为'constant'时,用于填充超出边界的常数值。默认值为0。
#
# horizontal_flip: 是否随机水平翻转图像。默认值为False。
#
# dtype: 输出图像的数据类型。默认值为None,表示使用输入图像的数据类型。
#
# data_format: 图像数据的格式,可以是'channels_first'或'channels_last'。默认值为None,表示使用Keras后端的默认数据格式。
#
# validation_split: 验证集的比例。例如,设置为0.2表示从训练集中抽取20%的数据作为验证集。默认值为0.0。
#
# subset: 如果提供了数据集,可以选择从数据集中抽取一部分数据进行预处理。可选值有'training'、'validation'和None。默认值为None。
#
# 这些参数可以根据具体需求进行调整,以便在训练过程中实现更好的图像数据增强效果。
#mageDataGenerator()是keras.preprocessing.image模块中的图片生成器,可以在batch中对数据进行增强,扩充数据集大小,增强模型的泛化能力。比如旋转,变形等,如下所示:
datagen = tf.keras.preprocessing.image.ImageDataGenerator(shear_range=10,horizontal_flip=True,zoom_range=0.4,
width_shift_range=0.2,height_shift_range=0.1,
vertical_flip=True,rescale=0.8)
for x,y in datagen.flow(x_train,y_train,batch_size=9):
plt.figure(figsize=(8,8))
for i in range(0,9):
plt.subplot(330+1+i)
plt.imshow(x[i].reshape(28,28),cmap='gray')
plt.title(y[i])
plt.show()
break
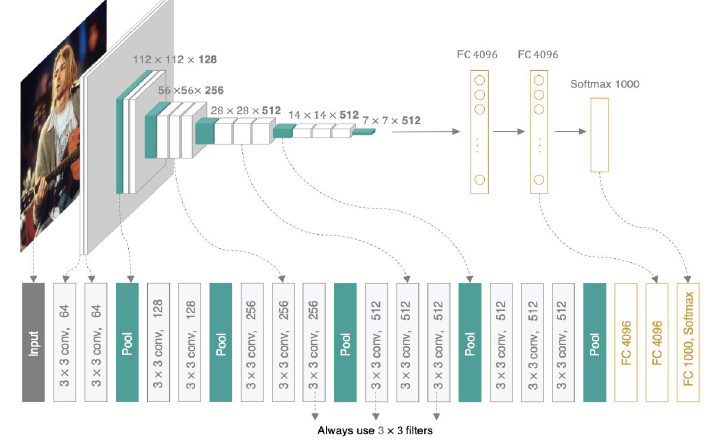
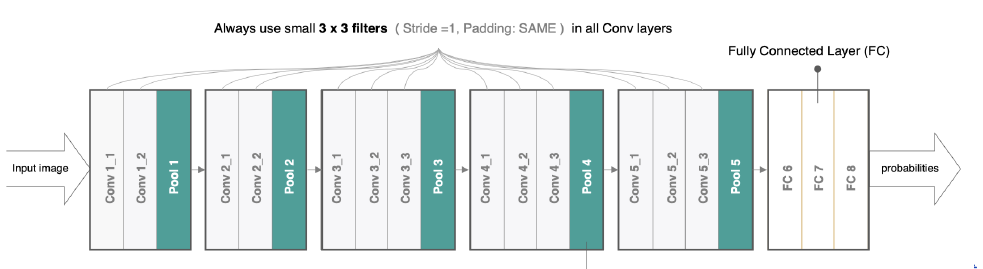
七、VGGNet
1、为什么使用VGGNet?
结构简洁且规律:2全部使用3X3卷积核和2X2的最大池化层,堆积多个小卷积核构建深度网络;卷积块为单位(多个卷积层接一个池化层)
特征提取能力强:两次3X3的卷积相当于一次5X5卷积,参数量更少,增加非线性变换次数(每个卷积层后接ReLU激活函数),提升特征学习能力。
深层网络提升性能:首次超过16层的CNN 加深网络深度提升分辨准确率
良好的泛化能力:所有输入图都为224X224,归一化处理 提升模型在不同数据集上的泛化能力
参数量可控:参数量非常大 但大部分参数集中在最后的三个全连接层(全连接隐藏层和全连接输出层)
2、VGGNet定义
AlexNet的加深版本,整个网络由卷积层和全连接层叠加而成,不同的是VGGNET全部使用的是3X3卷积层和2X2池化层,加深了网络的层数,对训练数据集识别更精确。
3、VGGNet运行?
输入图统一为224X224X3进行归一化 通过3X3卷积核提取局部特征 每层后接ReLU激活函数 通过2X2最大池化降低特征图尺寸 最后将特征图展平后输入全连接层 输出1000个类别的概率(softmax激活函数)
4、VGGNet应用?
图像分类:VggNet在ImageNet等大规模分类任务中表现优异。
特征提取:卷积层常被用作特征提取器。
研究教学:结构简单 常用用于模型设计的对比实验和教学示范。
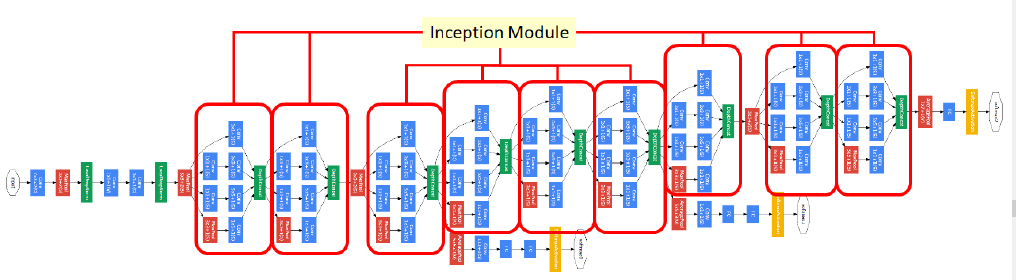
八、GoogleNet
1、为什么使用GoogleNet?
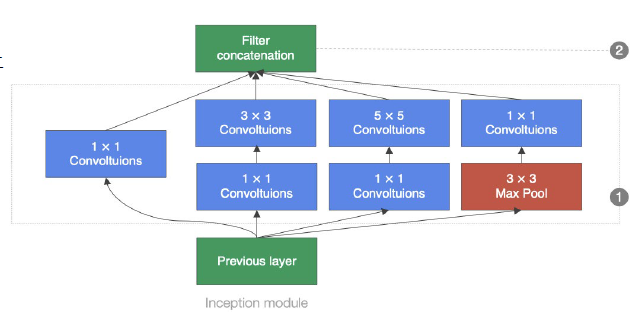
参数效率高:1X1卷积降低了特征图额的通道数 显著减少了计算量和参数量。全局平均池化:直接将特征图的每个通道取平均值 输出类别概率 相比连接池 几乎不增加参数
性能优越:inception模块并行卷积核和池化层 提取局部和全局特征 增强模型的表达能力。 网络层数更深避免计算冗余。
结果灵活易于拓展:堆叠inception模块,可灵活拓展深度适应不同的需求。
多路径学习与梯度优化:中间层添加辅助分类器 提供额外的梯度信号 缓解深层网络梯度消失问题,inception并行路径适应不同尺度特征,增强模型的健壮性。
GooleNet在ImageNet分类比赛上的Top-5错误率降低到6.7% 图像识别更准确。
2、什么是GooleNet?
GooleNet在加深网络结构上的同时,引入了Inception结构来代替之前的卷积加激活函数的经典组件。
整个网络架构我们分为五个模块,每个模块之间使用步幅为2的3×3最大池化层来减小输出高宽。
B1模块:第一模块使用一个64通道的7×7卷积层
B2模块:第二模块使用2个卷积层:首先是64通道的1×1卷积层,然后是将通道增大3倍的3×3卷积层。
B3模块:第三模块串联2个完整的Inception块。第一个Inception块的输出通道数为64+128+32+32=256。
第二个Inception块输出通道数增至128+192+96+64=480。
3、 如何运行?
输入224X224X3尺寸的图像,减去ImageNet的均值 训练时可以随机裁剪 翻转等图像增强手段 通过卷积层提取局部特征 通过最大池化降低特征图尺寸 并行执行四条路径输出特征拼接 在中间层输出分类结果 全局平均池化将特征图压缩到1X1X1000 最终输出1000个概率分布
4、何时使用?
图像分类 目标检测 迁移学习 研究与教学
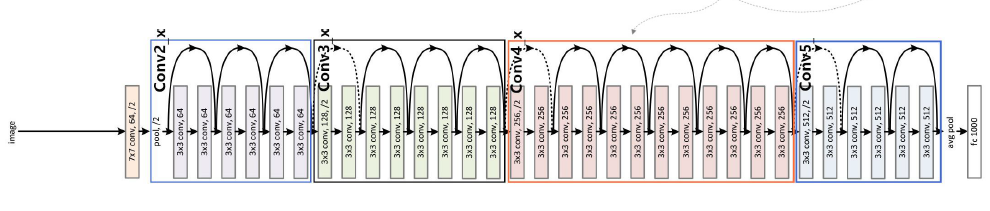
九、ResNet
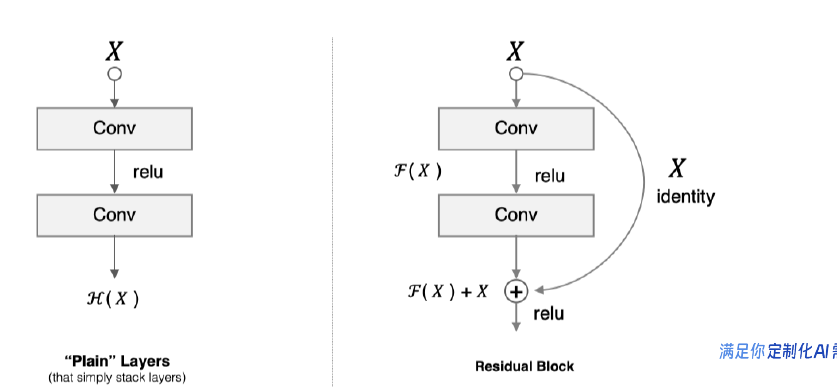
网络越深,获取的信息就越多,特征也越丰富。但是在实践中,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了,这叫网络退化。
1、为什么使用ResNet模型?
解决了深度网络退化问题 参数效率与计算的优化 残差块结构大幅度减少计算量 堆积残差块多尺度特征提取 通过堆积浅层网络和深层网络 灵活拓展18层到152层
2、什么是ResNet?
按照残缺块的通道分为不同的模块,第一个模块使用了步伐为2的最大池化层,之后每个模块在第一个残缺块里将上一个模块的通道数 翻倍,并将高和宽减半。 在每个卷积层后在增加了BN层接着是所有的残差模块和跳跃连接允许梯度直接反向传播到浅层,缓解梯度消失。
3、运行模式?
输入224X224X3尺寸的图像,减去ImageNet的均值 训练时可以随机裁剪 翻转等图像增强手段 通过卷积层提取局部特征 通过最大池化降低特征图尺寸 并行执行四条路径输出特征拼接 在中间层输出分类结果 全局平均池化将特征图压缩到1X1X1000 最终输出1000个概率分布。
4、应用?
语义分割 图像分类 目标检测 医学影像分析 视频分析
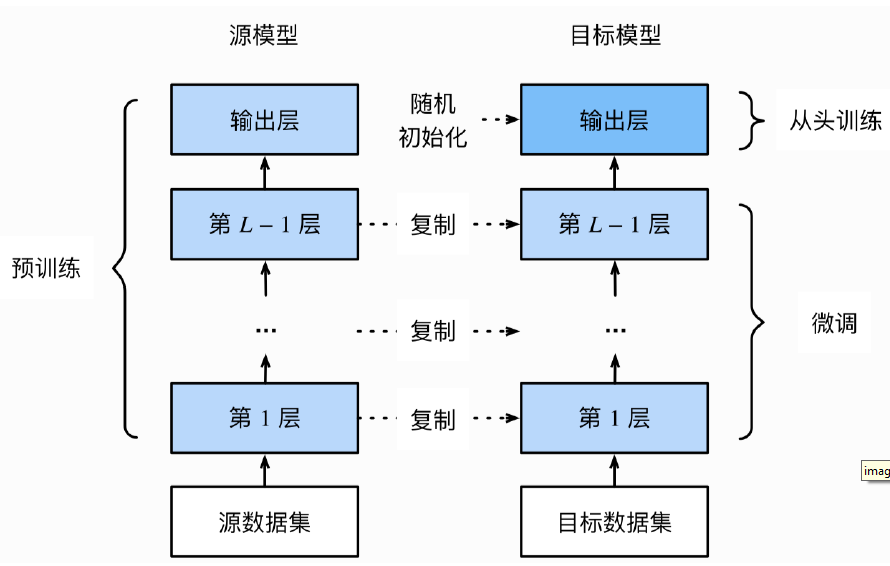
十、微调

1、为什么要微调?
前面的模型一步步演进会出现一些训练数据不准确的现象,微调可以提升训练数据的准确性同时效率更高,训练成本低能实现同样的效果,适用于很多中小企业。如果调用API会涉及数据隐私问 题,需要微调训练适配企业的垂直业务。
2、什么是微调?
在开源的预训练模型基础上(GPT-2、qianwen-2等)基础上把除去输出层以外的所有底层参数属性复制到新的模型,只需要对输出层进行随机初始化并从头训练使其适应具体任务或领域,当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
3、应用场景?
领域适配:涉及医学 法律 金融专业领域。
企业定制:将模型适配到企业内部业务逻辑。如:客服对话等
任务定制:使用标注的垃圾邮件数据微调模型,提高分类准确率。
十一、模型优化微调案例
- 热狗识别
基于一个小的数据集对ImageNet数据集上训练好ResNet模型进行微调。该数据集包含数千张热狗或者其他事物的图像。
- 代码分解
# 导入包依赖
import tensorflow as tf
import pathlib
import matplotlib.pyplot as plt
# 获取数据集
traindir = 'hotdog/train'
testdir ='hotdog/test'
# 输入图像的所有像素值按比例缩放到0到1之间。通常情况下,原始图像的像素值范围是0到255(图像增强)
image_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255.)
# 获取训练集数据 traindir:训练数据集的地址
# batch_size:每次从生成器中返回的图像
# target_size 输入图像的尺寸 符合卷积神经网络模型输入要求相匹配
# shuffle:打乱图像的顺序 从而提高模型的泛化能力
train_data_gen = image_gen.flow_from_directory(traindir,batch_size=32,target_size=(224,224),shuffle=True)
# 获取测试集数据
test_data_gen = image_gen.flow_from_directory(testdir,batch_size=32,target_size=(224,224),shuffle=True)
# 获取下一个批次的图像和标签
image,label = next(train_data_gen)
# 显示5X5图片格 显示加载的图片
plt.figure(figsize=(10,10))
for n in range(15):
ax = plt.subplot(5,5,n+1)
plt.imshow(image[n])
plt.axis('off')
# 导入和加载预训练的ResNet50模型
# weights='imagenet': 指定使用在ImageNet数据集上预训练的权重。
# input_shape=(224, 224, 3): 指定输入图像的形状为224x224像素的RGB(channel=3)图像。
ResNet50 = tf.keras.applications.ResNet50(weights='imagenet',input_shape=(224,224,3))
# 遍历ResNet50模型的所有层,并将它们设置为不可训练(trainable=False)。这意味着在后续的训练过程中,这些# 层的权重不会被更新,从而保留了预训练的特征提取能力。
for layer in ResNet50.layers:
layer.trainable = False
# 创建一个新的顺序模型 线性堆层叠方式构建模型
net = tf.keras.models.Sequential()
# 将之前加载并冻结的ResNet50模型作为一个整体添加到新的顺序模型中。
net.add(ResNet50)
# 展平ResNet50模型的输出,使其从三维张量变为一维向量。这对于后续的全连接层是必要的 扁平化操作
net.add(tf.keras.layers.Flatten())
# Dense(2, activation="sigmoid"): 添加一个包含2个神经元的全连接层,并使用Sigmoid激活函数。这里的2表示输出类别数为2,适用于二分类问题 表示是热狗或者不是热狗。
# net.add(tf.keras.layers.Dense(256, activation="sigmoid")) 包含256个神经元的中间层
net.add(tf.keras.layers.Dense(2, activation="sigmoid"))
# 使用了Adam优化器 二元交叉熵作为损失函数。
#binary_crossentropy 使用二元交叉熵作为损失函数 二元交叉熵适用于二分类问题
# metrics=["accuracy"]: 指定在训练过程中监控的评估指标为准确率
# 模型编译
net.compile(optimizer='adam',loss=tf.keras.losses.binary_crossentropy,metrics=["accuracy"])
# 训练模型
# steps_per_epoch=10: 指定每个epoch中从train_data_gen获取的批次数量
# epochs=3: 指定训练的总轮数(epoch) 训练3轮
# batch_size=32: 指定每个批次中的样本数量
# validation_data=test_data_gen: 验证数据生成器,负责从验证数据目录中加载和预处理图像数据。
# validation_steps=10: 指定每个epoch中从test_data_gen获取的批次数量。在这个例子中,每个epoch将使用# 10个批次的数据进行验证。
net.fit(train_data_gen,steps_per_epoch=10,epochs=3,batch_size=32,validation_data=test_data_gen,validation_steps=10)
- 总结:
1、加载图像并打印输出图像
2、导入和加载预训练的ResNet50模型
3、创建一个新的顺序模型 线性堆层叠方式构建模型
4、将预训练模型加载进新的顺序模型中
5、模型编译和训练 查看准确率
本文来自博客园,作者:戴莫先生Study平台,转载请注明原文链接:https://www.cnblogs.com/smallzengstudy/p/18943532

 浙公网安备 33010602011771号
浙公网安备 33010602011771号