NLP基础
NLP基础
1、自然语言处理简介
自然语言处理关注的是自然语言与计算机之间的交互(NLP)。
1.1 自然语言处理简介
自然语言生成恰恰相反,结构化数据中以读取的方式自动生成文本。三个阶段:文本规划(完成结构化数据中的基础内容规划)、语句规划(从结构化数据中组合语句来表达信息流)、实现(产生语法通顺的语句来表达文本)。
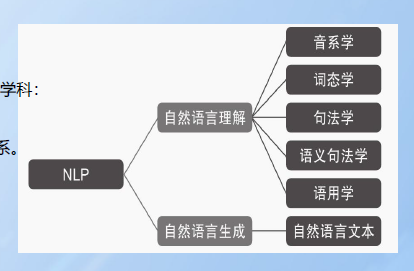
1.2、自然语言处理发展历史
1950图灵发布《机器可以思考吗?》从此促进人类语言学与计算机科学的交融
1957~1970自然语言处理出现两大阵营基于规则和基于统计
1994~1999基于统计取得认可,概率计算引入到NLP领域每个任务中
2000~2008机器学习开始兴起,迅速站领了NLP主流市场
2015年人工智能的到来深刻改变NLP的未来
1.3、自然语言处理方式
分词:基于字典的最长串匹配,据说可以解决85%的问题,但是歧义词很难。
词性标注:在每个词后面标注词性。比如:ns代表名词,v代表动词等
命名实体识别:文本识别具有特定类别的实体。例如:人名、地名、机构名等
句法分析:理清句子的主从关系。
指定消解:中文出现的频率很高,后面指示代词用来表征前文的词。
情感识别:一般用舆论分析领域,情感一般分为正面、负面、中性,在电商行业识别一个东西的好坏。
纠错:用户输入出错的可能性比较大,出错的场景比较多,我们需要一个纠错系统。
问答系统·:需要语音识别、合成、自然语言理解、知识图谱多项技术配合使用实现比较好。比如微软小冰。
主要技术: 词法分析(词性标注)、句法分析、语义分析
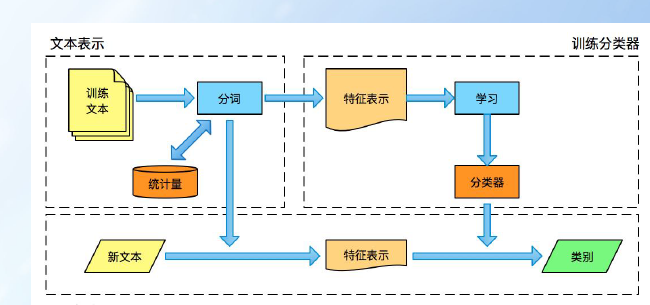
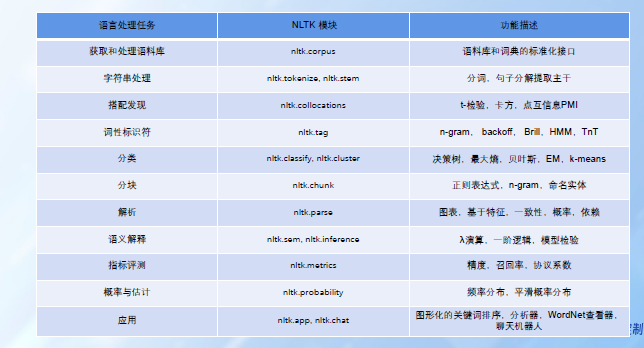
2、词法分析
2.1、中文分词的概念与分类
文本语料在送进模型前需要进行一系列的预处理工作,才能符合模型的输入要求。如:把文本转化为模型需要的张量。
处理中文分词前需要进行分词处理,中文分词需要进行切词,而英文分词以空格隔开。
统计词出现的词频
2.2、分词技术
基于规则分词是一种机械的分词方法,主要为了维护词典。
词匹配切分的方法,主要有正向最大匹配法,逆向最大匹配法以及双向最大匹配法
正向最大匹配法:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功。
逆向最大匹配法:逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(i为词典中最长词数)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。
双向最大匹配法:双向最大匹配法(Bi-directction Matching method)是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。
使用jieba分词器 Jieba(结巴)是一个开源库,在GitHub上很受欢迎,使用频率很高。
GitHub链接:https://github.com/fxsjy/jieba
pip install jieba
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
精确模式:把文本最精确分开,适合文本分析。
全模式:把句子中全部可以成词的词语扫描出来,速度快,但不能解决歧义
搜索引擎模式:在精确的基础对词进一步切分,提高召回率,适合用于搜索引擎分词。
高频词提取其实就是自然语言处理中的TF策略。
2.3、词性标注
词性标准以文本分词为基础,是对文本语言的另外一种理解,常作为AI解决NLP领域高阶任务。比如:n名词 v动词 a形容词等
命名实体识别(Named Entity Recognition,简称NER)就是识别出一段文本中可能存在的命名实体。

2.4关键词提取法
TF-IDF是一种词频-逆文档提词算法,由TF算法和IDF算法,TF算法统计词在文档中出现的频率,词出现频率越高对文档表达能力越强。 IDF算法统计词在文档集中其他文档出现的次数,用于对文档的区分,在其他文档出现频率越小,对文档的区分越强。
在词袋模型中,我们可以使用TF × IDF作为每个词的权重。

3、句法分析
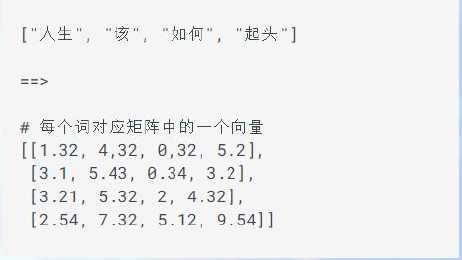
句法分析(Parsing)是从单词串得到句法结构的过程,而实现该过程的工具或程序被称为句法分析器(Parser)。
将一段文本使用张量进行表示,其中一般将词汇表示成向量,按词向量顺序组成矩阵。
文本张量将文本表示张量形式,能够使语言文本可以作为计算机处理程序的输入,进一步解析。
文本张量表示的方法:one-hot编码、word2vec、Word Embedding
3.1、文本特征处理
文本特征处理包括为 语料添加具有普适性的文本特征。
常见的文本特征处理方法:
1,添加n-gram特征
2,文本长度规范
N-Gram模型:是一种语言模型,一种基于概率的判别模型,输入一句话(单词顺序序列)输出是这句话的概率,也是这些单词的联合概率。
N-gram本身也指一个由N个单词组成的集合,各单词具有先后顺序,且不要求单词之间互不相同。
用途:词性标注、垃圾短信分类、分词器、机器翻译、语音识别、


3.2、One-Hot编码

称为独热编码 将每个词表示为n个元素的向量,向量由1和0表示,1和0表示的不同位置表示每个词。
优点:操作简单,容易理解 缺点:割裂了词之间的关系,向量越长占据大量内存。


3.3、词袋
词袋(Bag Of Word)模型是最早的以词语为基本处理单元的文本向量化方法。下面举例说明该方法的原理。 缺点:对文本的情感色彩和意思容易产生歧义。

3.4、word2vec(词向量)
一种流行的将词汇表示成向量的无监督训练方法构建神经网络模型,网络参数作为词的向量。CBOW和skipgram两种训练模式.
利用神经网络从大量无注解的文本中提取有用的信息。通过训练将每个词映射到较短的词向量上来。

3.5 、word Embedding
词嵌入;通过一定方式将词汇映射到指定维度(一般都是更高维度)的空间,神经网络中加入的word Embedding层一般是所有输入词汇向量的矩阵空间。
文本表示的一类方法。
优点:通过低维度来表示,相比One-Hot节省了空间。
通用性很强,可以在不同任务中。
相似的词在向量上会比较接近。

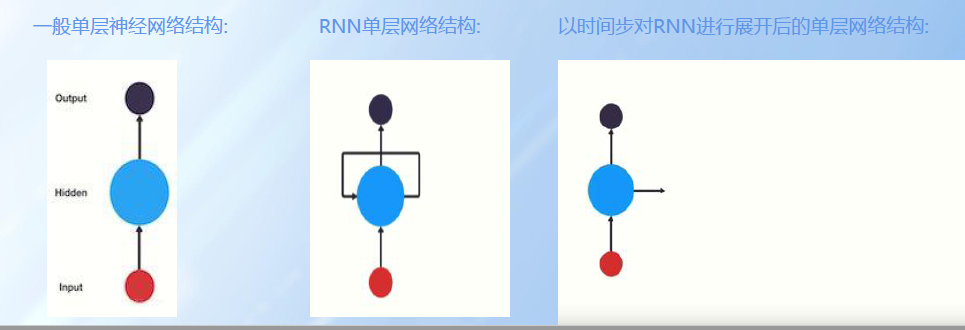
4、RNN
- 概念
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络。当前运算处理依赖上一轮结果,依次类推。当文本足够长的时候容易出现梯度爆炸或者梯度消失,也就是记忆丢失。
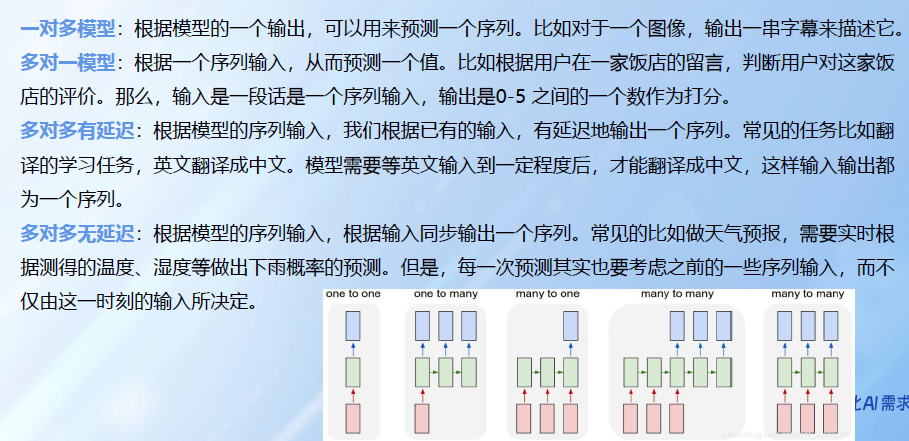
应用:如文本分类, 情感分析, 意图识别, 机器翻译等
Pytorch中传统RNN工具的使用:
位置: 在torch.nn工具包之中, 通过torch.nn.RNN可调
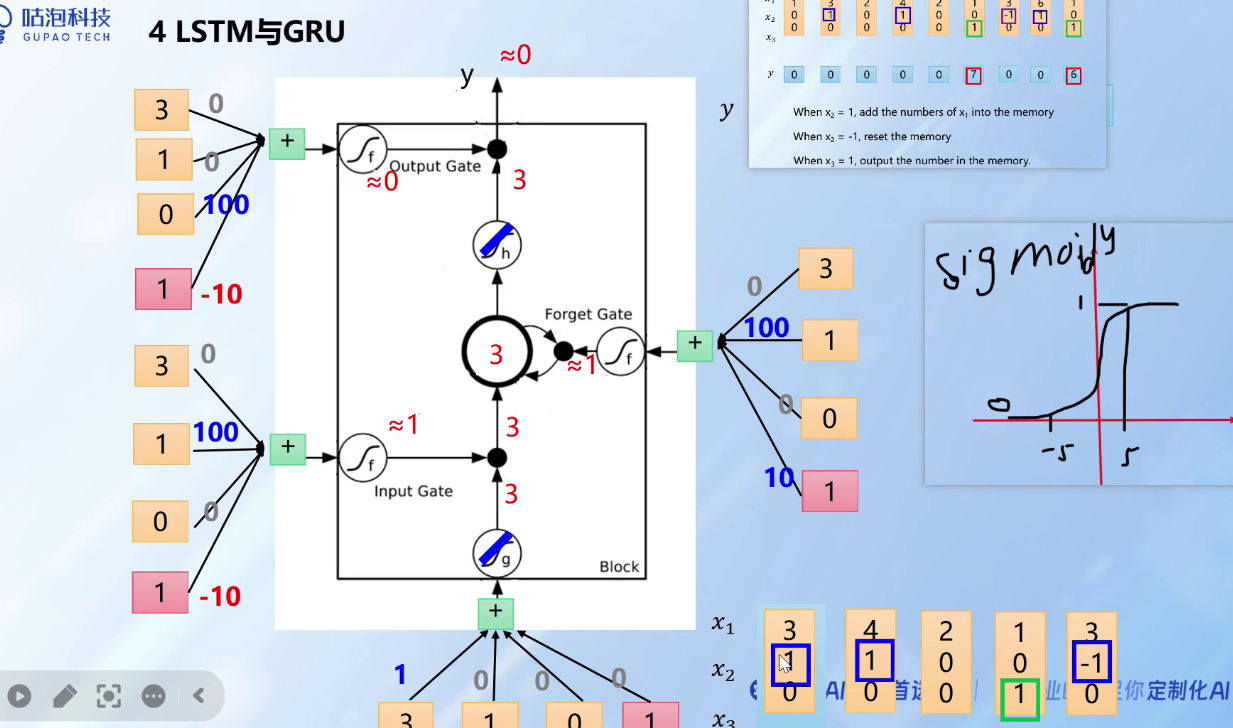
5、LSTM
长短时记忆结构,传统RNN的变形体,与经典的RNN相比,能缓解梯度爆炸和梯度消失,结构更复杂处理效率会下降。
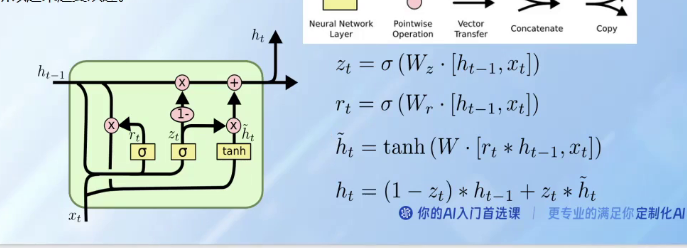
6、GRU
是LSTM的变形版本 将遗忘门和输入门合并成一个更新门 合并了单元状态和隐藏状态 还更新了其他 结构比LSTM简单。
7、RNN经典案例 构建人名分类器
以一个人名为输入, 使用模型帮助我们判断它最有可能是来自哪一个国家的人名, 这在某些国际化公司的业务中具有重要意义, 在用户注册过程中, 会根据用户填写的名字直接给他分配可能的国家或地区选项, 以及该国家或地区的国旗, 限制手机号码位数等等
五步骤:
1、导入工具包
python版本使用3.6.x, pytorch版本使用1.3.1
2、对data文件中的数据进行处理,满足训练要求
定义数据集路径并获取常用的字符数量.
字符规范化之unicode转Ascii函数unicodeToAscii.
构建一个从持久化文件中读取内容到内存的函数readLines.
构建人名类别(所属的语言)列表与人名对应关系字典
将人名转化为对应onehot张量表示函数lineToTensor
3、构建RNN模型(RNN/LSTM/GRU)
构建传统的RNN模型的类class RNN.
构建LSTM模型的类class LSTM.
构建GRU模型的类class GRU.
4、构建训练函数并进行训练
从输出结果中获得指定类别函数categoryFromOutput.
随机生成训练数据函数randomTrainingExample.
构建传统RNN训练函数trainRNN.
构建LSTM训练函数trainLSTM.
构建GRU训练函数trainGRU.
构建时间计算函数timeSince.
构建训练过程的日志打印函数train.得到损失对比曲线和训练耗时对比图.
5、构建评估函数并进行预测
构建传统RNN评估函数evaluateRNN.
构建LSTM评估函数evaluateLSTM.
构建GRU评估函数evaluateGRU.
构建预测函数predict.
结论:模型选用一般应通过实验对比, 并非越复杂或越先进的模型表现越好, 而是需要结合自己的特定任务, 从对数据的分析和实验结果中获得最佳答案
本文来自博客园,作者:戴莫先生Study平台,转载请注明原文链接:https://www.cnblogs.com/smallzengstudy/p/18943531

 浙公网安备 33010602011771号
浙公网安备 33010602011771号