django(五)
模板语法之过滤器(类似于内置函数)
使用的时候可以看看源码,了解内部的原理
1.语法结构
{{ 数据对象|过滤器名称:参数 }} 过滤器最多只能额外传输一个参数
2.常见过滤器(django模板语法提供了60+过滤器 我们了解几个即可)
<p>统计数据的长度:{{ s1|length }}</p>
<p>算术加法或者字符串加法:{{ n1|add:111 }}、{{ s1|add:'big baby' }}</p>
<p>将数字转成合适的文件计量单位(kb、mb、...):{{ file_size|filesizeformat }}、{{ file_size1|filesizeformat }}</p>
<p>判断当前数据对象对应的布尔值是否是False:{{ b|default:'前面的值对应的布尔值是False' }}、{{ s1|default:'前面的值对应的布尔值是False' }}</p>
<p>时间格式化:{{ ctime|date:'Y-m-d' }}</p>
<p>索引切片:{{ s1|slice:'0:8' }}</p>
<p>以空格作为分隔符截取指定个数的文本,多的内容用3个点表示:{{ s2|truncatewords:5 }} 截取5个文本、{{ s1|truncatewords:1 }} 截取1个文本</p>
<p>按照字符个数截取文本(包含三个点):{{ s2|truncatechars:5 }} 一共2个显示的字符和3个点、{{ s1|truncatechars:10 }} 一共7个显示的字符和3个点</p>
<p>移除指定的字符:{{ info|cut:'|' }}</p>
<p>是否取消转换:{{ tag1 }}、{{ tag1|safe }}、{{ scripts1|safe }}、{{ res }}</p>
ttt = '<a href="https://www.baidu.com">点我</a>'
from django.utils.safestring import mark_safe
res = mark_safe(ttt)
上诉代码可以让过滤器safe的作用在后端编写的时候就启用,到模板层只要直接用res就可以做到效果了
最后一个|safe启发了我们以后用django开发全栈项目前端页面代码(主要指HTML代码)也可以在后端编写

模板语法之标签
在django模板语法中写标签的时候 只需要写关键字然后tab键就会自动补全
1.语法结构
{% 名字 ...%}
{% end名字 %}
2.if判断
{% if 条件1 %}
<p>你好啊</p>
{% elif 条件2 %}
<p>他好呀</p>
{% else %}
<p>大家好</p>
{% endif %}
3.for循环
提供了forloop关键字
{'parentloop': { }, 'counter0': 0, 'counter': 1, 'revcounter': 4, 'revcounter0': 3, 'first': True, 'last': False}
parentloop forloop.parentloop引用父级循环的 forloop 对象。
counter0 从头开始索引位置
counter 从头开始第几个数字
revcounter 从尾开始第几个数字
revcounter0 从尾开始索引位置
first 是否是第一个
last 是否是最后一个
{% for i in l1 %}
<p>{{ i }}</p>
{% endfor %}
for+if其他使用
{% for i in l1 %}
{% if forloop.first %}
<p>这是第一次循环</p>
{% elif forloop.last %}
<p>这是最后一次循环</p>
{% else %}
<p>中间循环</p>
{% endif %}
{% empty %} # 对象是空的的时候执行
<p>for循环对象为空 自动执行</p>
{% endfor %}
针对字典同样提供了keys、values、items方法
自定义过滤器、标签、inclusion_tag
1.在应用下需要创建一个名为templatetags的文件夹
2.在该文件夹内创建一个任意名称的py文件
3.在该py文件内需要先提前编写两行固定的代码
from django import template
register = template.Library()
# 自定义过滤器:只能接收两个参数
# templatetagsw文件夹中的py文件中写自定义内容
@register.filter(is_safe=True)
def index(a, b):
return a + b
# 写在模板中
{% load mytag %} # 加载自定义内容所在的py文件
{{ n1|index:666 }}
# 自定义简单标签:可以接收任意的参数
@register.simple_tag(name='my_tag')
def func1(a, b, c, d):
return a + b + c + d
{% my_tag 1 2 3 4 %} # 参数之间空格隔开即可
# 自定义inclusion_tag
@register.inclusion_tag('left.html')
def func2(n): # 可以不加参数也可以加多个,多个在使用时就用空格分隔
l1 = []
for i in range(1, n + 1):
l1.append(f'第{i}页')
return locals()
{% func2 10 %}
###left.html###
<ul>
{% for foo in l1 %}
<li>{{ foo }}</li> # {{}}千万别忘记加了不然显示的只是foo这个字符串
{% endfor %}
</ul>
该方法需要先作用于一个局部html页面,之后将渲染的结果放到调用的位置
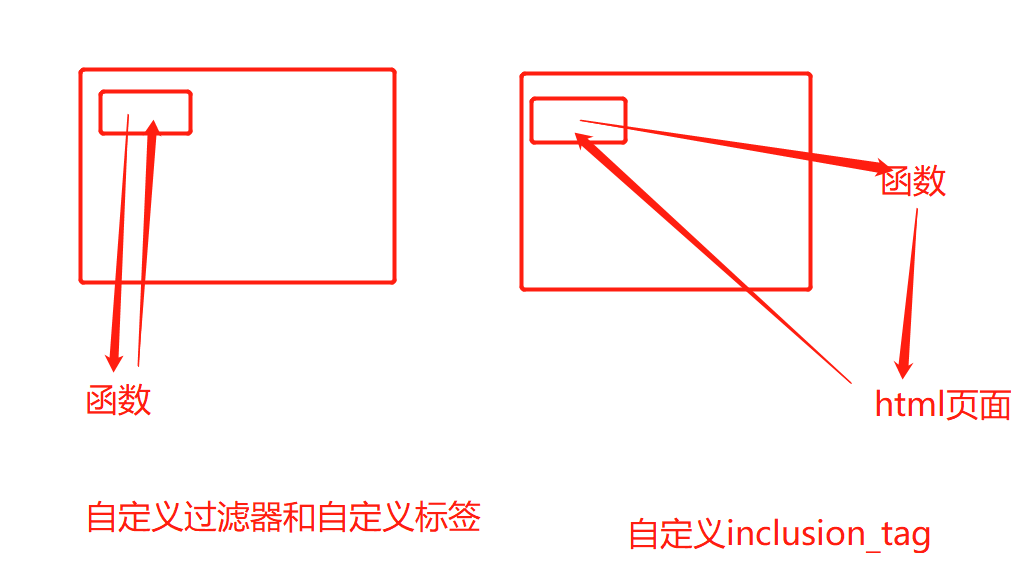
自定义过滤器和自定义标签是让函数直接作用于页面上的 ,inclusion_tag是先让函数作用于html页面在让html页面作用在要进行操作的页面上。
模板的导入(了解)
类似于将html页面上的局部页面做成模块的形式 哪个地方想要直接导入即可展示
eg:有一个非常好看的获取用户数据的页面 需要在网站的多个页面上使用
策略1:拷贝多份即可
策略2:模板的导入
使用方式
{% include 'menu.html' %} # 注意导入的模板不要用一个完整的html,不然排版会乱掉的
注释语法补充
是HTML的注释语法{##} 是django模板语法的注释
HTML的注释可以在前端浏览器页面上直接查看到
模板语法的注释只能在后端查看 前端浏览器查看不了
模板的继承
类似于面向对象的继承:继承了某个页面就可以使用该页面上所有的资源
有很多网站的很多页面 其实都是差不多的 只是局部有所变化 模板的继承可以很好的实现该需求
1.先在模板中通过block划定将来可以被修改的区域
{% block content %}
<h1>主页内容</h1>
{% endblock %}
2.子板继承模板
{% extends 'home.html' %}
3.修改划定的区域
{% block content %}
<h1>登录内容</h1>
{% endblock %}
4.子页面还可以重复使用父页面的内容
{{ block.super }}
模板上最少应该有三个区域
css区域、内容区域、js区域
子页面就可以有自己独立的css、js、内容
前期数据准备
django自带的sqlite3数据库,功能很少,并且针对日期类型不精确
1.数据库正向迁移命令(将类操作映射到表中)
python3 manage.py makemigrations
python3 manage.py migrate
2.数据库反向迁移命令(将表映射成类)
python3 manage.py inspectdb
需求
我们只想操作orm 不想使用网络请求
需要有专门的测试环境
1.自己搭建
import os
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day54.settings")
import django
django.setup()
2.pycharm提供
python console
3.orm操作
models.user.objects.create(name='king', age=18, hobby='篮球')
models.user.objects.create(name='jack', age=38, hobby='吃火锅')
models.user.objects.create(name='tom', age=28, hobby='足球')
models.user.objects.create(name='jom', age=18, hobby='编程')
models.user.objects.create(name='lisa', age=28, hobby='音乐')
res = models.user.objects.all()
res = models.user.objects.filter(name='king')
res = models.user.objects.filter() # 不写条件类似于all()只是语义上不同罢了
res = models.user.objects.filter(pk=2) # 如果不知道主键的字段名可以直接用pk来表示
res = models.user.objects.filter().first() # 其实和filter()[0]效果一样,但是推荐写first,虽然first底层就是用的[0]
res = models.user.objects.filter(pk=1, name='kevin').first() # 括号内支持填写多个筛选条件 默认是and关系
res = models.user.objects.filter().filter().filter().filter().filter() # 只要是QuerySet对象就可以继续点对象方法(类似于jQuery链式操作)
res = models.user.objects.all().values('name', 'age') # 可以看成是列表内套字典,用这个方法是筛选出括号内写明的字段
res = models.user.objects.values('name', 'age') # 不写all()也是从所有的内容中拿
res = models.user.objects.filter(pk=2).values('name') # 可以看成从结果集里再进行筛选
res = models.user.objects.all().values_list('name', 'age') # 可以看成列表套元组,用起来不方便故用的不多
res = models.user.objects.values_list('name', 'age') # 和values用法差不多
res = models.user.objects.all().distinct() # 有主键的表不好进行去重,去重是要完全相同才行
res = models.user.objects.values('name').distinct() # 可以筛选
res = models.user.objects.order_by('age') # 升序
res = models.user.objects.order_by('-age') # 降序
res = models.user.objects.order_by('age', 'pk') # 先比较第一个参数,再比较第二个参数
res = models.user.objects.exclude(name='king') # 取反,取不满足条件
res = models.user.objects.order_by('age').reverse() # 反转,与order_by配合使用
res = models.user.objects.count() # 看有几条记录
res = models.user.objects.exists() # 看结果集中是否有数据
res = models.user.objects.filter(name='kingnb').exists()
res = models.user.objects.get(pk=1) # 直接获取对象,不推荐使用
res = models.user.objects.get(pk=100) # 没有该数据对象就报错,还是推荐使用filter来查找数据对象
print(res)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号