
第一次个人编程作业
https://github.com/smallgrape14/duann
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 480 | 540 |
| · Estimate | · 估计这个任务需要多少时间 | 480 | 540 |
| Development | 开发 | 870 | 1040 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 300 |
| · Design Spec | · 生成设计文档 | 60 | 40 |
| · Design Review | · 设计复审 | 60 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| · Design | · 具体设计 | 120 | 70 |
| · Coding | · 具体编码 | 240 | 300 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 180 |
| Reporting | 报告 | 120 | 105 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 30 |
| · 合计 | 1500 | 1470 | 1685 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
设计整个程序的流程分为两个步骤:-
读取敏感词文件,生成相应的敏感词库,用于检测
-
读取待检测文件,参照着敏感词库,来检测敏感词
一个类:DFAfilter 三个核心函数
ps:考虑到,若是,单单把敏感词文件中的敏感词原原本本的加入敏感词库,而实际上,中文敏感词具有变形的多种形式,放在检测文本函数中去识别的变形,如此一来,形成判断的分支结构会比较复杂。
于是,该类有三个核心函数:
1.transshape() 对文本中的敏感词进行变形,实现ex:法--fa--f--氵去 or 功--gong--g--工力--工(工与功同音)
关键在于把敏感词中的每个汉字的可能形式组合起来,采用了遍历敏感词的每个字。每一次遍历都在前一次循环新形成的字符串后面添加该字的变形,等到最后一层循环结束后,将刚刚组合成功的字符串依次调用add函数,使其进入敏感词库。
由于运行样例时,发现了法轮工没有检测出来的bug。是由于没有考虑到拆分出来的左部首也有可能和原字是谐音,于是增加了相应的判断语句。
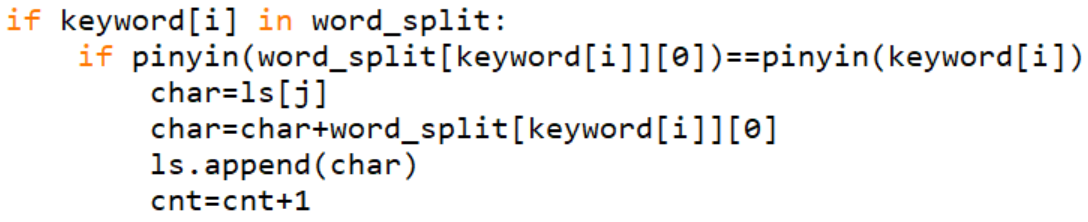
2.add() 将变形组合的敏感词入库
此函数为建立敏感词库,其实是敏感词的字典链,delimit作为敏感词结束的标志,该键对应的值是 敏感词的原型,用于变形过后的敏感词也可以对应出敏感词文本中出现的敏感词。
因为,中文敏感词变形加工后才调用add函数,而且,进入敏感词链的英文也被化作了小写(目的是检测函数可以更好地比较两个英文字符),但是检测的结果需要有原始敏感词,因此,add的参数多了一个real_word,并且把每一个字典链的结尾标志delimit的键值设置为 real_word,用于输出结果。
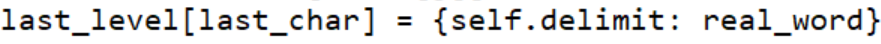
3.detecting() 参照着敏感词库,检测待测文本的敏感词,(代码量最大的函数)
总体思路:通过遍历循环,参照敏感词库来检测敏感词。
一些关键细节:
- (1)falung 遇见 falugong 二者选谁的问题,明显,样例选了后者,所以在原本的代码上加了个小分支,用于解决当前已经是完整敏感词的时候,是否向后遍历其实有更加适合的求解 或是 对敏感词提取可以更加完整的情况。

- (2)中文敏感词插入数字无效,但是英文敏感词插入数字仍旧是有效的,设置了两个标志:flag (是否出现是敏感词的中文) fnum (是否出现数字),于是敏感词中间的数字就暂时算是可容忍的字符。等到循环到了字典链的结尾,又通过delimit的键值发现,该敏感词是中文,在fnum的指示下,若出现数字,则该敏感词无效;未出现数字,则敏感词有效。
4.拆分汉字左右结构:
实现汉字可以被拆分为左右结构的代码,本来以为python中会有相应的库来操作,但是没有找到,换了个思路,找到一个将汉字拆分为左右字结构的文本,自成了一个小词库,虽说并不具有涵盖所有的本领,一般的汉字应该是可以应付,代码如下:

(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
函数总时间降序图: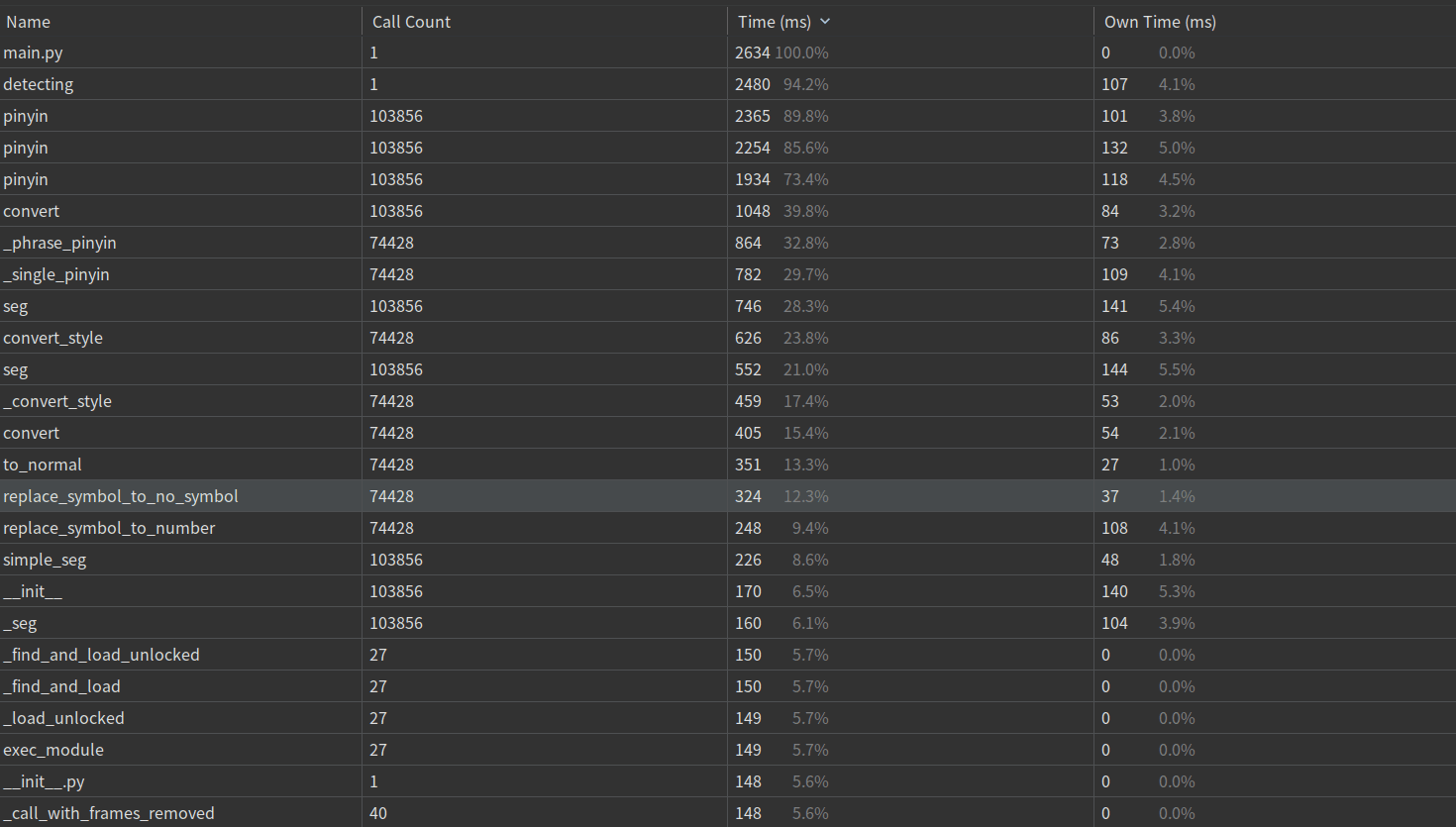
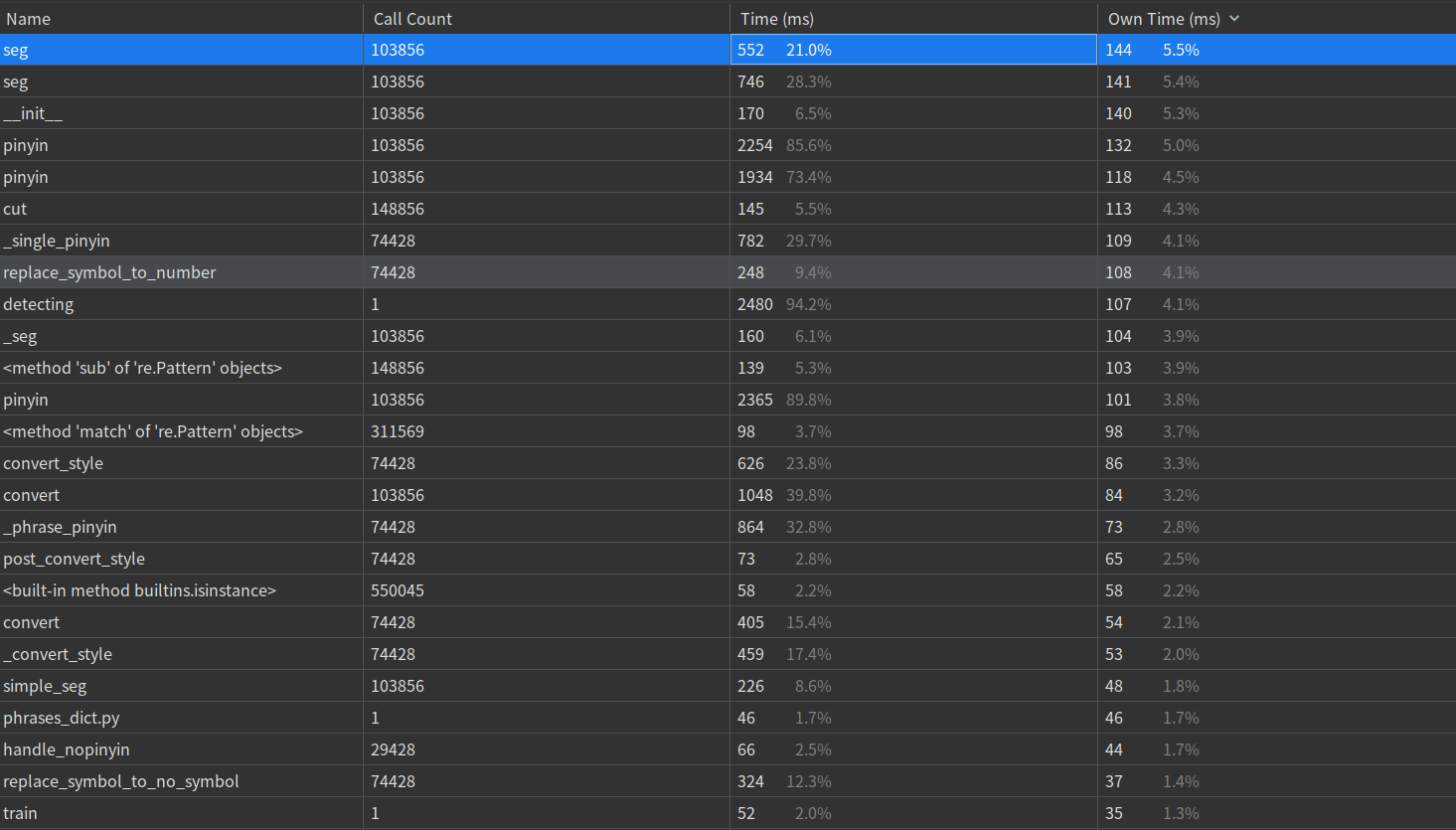
改进设计:在耗时最大的detecting函数进行一些重复模块的提取,减小代码长度,在一些可以简短运行时间的部分进行改造,想办法在代码量集中的第二重for循环减少判断的分支,尽量使实现检测功能的思路更清晰和简单。
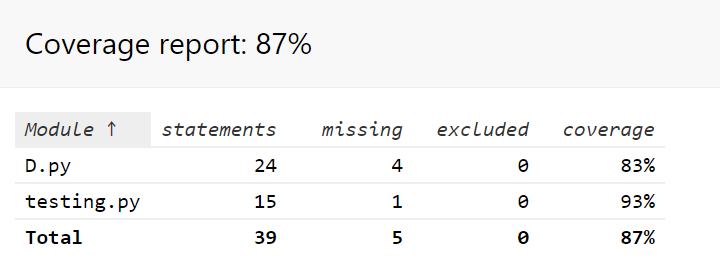
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
思路为:检验正确检测结果,与自己代码检测的结果文本是否一致
单元测试的代码(测试主函数):

单元测试覆盖图:

测试add函数的代码:

单元测试覆盖图:
样例结果对比:

(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
设计了命令行输入的参数个数与要求不一致的异常处理,单元测试样例:
三、心得
(4.1)在完成本次作业过程的心得体会(3')
- 每个函数的实现,其实都不算太难,难的是debug,各种先开始没考虑到的情况,都会在样例和自己单元测试下被发现
- 第一次用python写一段挺长的代码,暴露了python学的并不是很扎实的本质,好多学过的东西,没有经常使用很容易忘记,感觉python的小细节还是挺多的,基础不牢的时候,debug的时候真的会“地动山摇”。
- 有些功能实现的过程真的是非常坎坷,想起来容易,做起来这也出错,那也出错,快点成为行动的巨人吧。
- 虽然实现了题目要求的功能,但是时间够的话,还是希望能拓展下功能,并且把代码的结构更加优化一下,不至于太冗长。
- 一直在跟着百度解决各种“疑难杂症”,好多时候是莫名其妙的解决了,也有的时候是找不到解决的方法,解决问题的能力总的来说,也是提升了那么一丢丢。
- 有收获,有成长,有挫折,有苦恼,更有希望吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号