

1、pom.xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<!-- <version>1.6.0</version>-->
<version>2.3.1</version>
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.17.Final</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<!--<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.1 2.3.1 2.4.5</version>-->
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.1</version>
</dependency>
</dependencies>
********************************************************************************************************************************
***************************************消费者--订阅**************************************************************************
2、RDDtoKafaConsumer3 消费者--订阅
#####spark Streaming订阅的kafka的主题以及连接kafka集群所需要的参数
#####主题:wordProducer2003
################bootstrap.servers localhost:9092
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
object RDDtoKafaConsumer3 {
def main(args: Array[String]): Unit = {
// 1、创建一个StreamingContext上下文对象
val sparkConf = new SparkConf()
.setAppName("object RDDtoKafaConsumer3 {")
.setMaster("local[2]")
// .set("spark.port.maxRetries","128")
// .set("spark.ui.port","4041")//Spark web UI at http://192.168.7.135:4041
val ssc = new StreamingContext(sparkConf,Seconds(10))
// 2、通过Kafka数据源创建DStream--直连Kafka集群的方式
val topics = Array("wordProducer2003")
val kafkaParam = Map(
"bootstrap.servers" -> "localhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
//"zookeeper.connect" -> "localhost:2182",
"group.id" -> "spark",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
/**
* 三个值
* 1、streamingcontext
* 2、类型
* 3、spark Streaming订阅的kafka的主题以及连接kafka集群所需要的参数
*
* 读取回来Kafka数据在在DStream是一个ConsumerRecord类型----代表的是kafka中一条消息
*/
val dStream: DStream[ConsumerRecord[String, String]] =
KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String,
String](topics, kafkaParam))
dStream.foreachRDD((rdd:RDD[ConsumerRecord[String, String]]) => {
rdd.foreach((data:ConsumerRecord[String, String]) => {
println("sparkstreaming读取处理了一条kafka的数据"+data.key()+data.value())
})
})
ssc.start()
ssc.awaitTermination()
}
}
3、RDDtoKafaConsumer4 消费者--订阅
######消费主题wordProducer2003
################bootstrap.servers localhost:9092
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object RDDtoKafaConsumer4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("RDDtoKafaConsumer4")
//刷新时间设置为1秒
val ssc = new StreamingContext(conf, Seconds(1))
//消费者配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092", //kafka集群地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group", //消费者组名
"auto.offset.reset" -> "latest", //latest自动重置偏移量为最新的偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)) //如果是true,则这个消费者的偏移量会在后台自动提交
val topics = Array("wordProducer2003") //消费主题,可以同时消费多个
//创建DStream,返回接收到的输入数据
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams))
//打印获取到的数据,因为1秒刷新一次,所以数据长度大于0时才打印
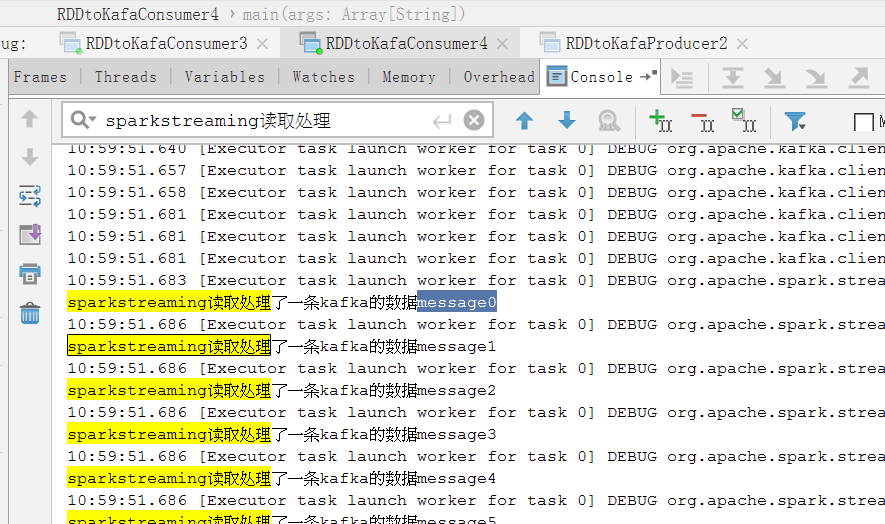
stream.foreachRDD(f => {
if (f.count > 0)
f.foreach(f => println("sparkstreaming读取处理了一条kafka的数据"+f.value()))
})
ssc.start();
ssc.awaitTermination();
}
}
4、RDDtoKafaConsumer5 消费者--订阅
######消费主题wordProducer2003
################bootstrap.servers localhost:9092
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
public class RDDtoKafaConsumer5 {
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDDtoKafaConsumer5");
// SparkConf sparkConf = new SparkConf();
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(10));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "localhost:9092");//多个可用ip可用","隔开
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "sparkStreaming");
Collection<String> topics = Arrays.asList("wordProducer2003");//配置topic,可以是数组
JavaInputDStream<ConsumerRecord<String, String>> javaInputDStream = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, kafkaParams));
JavaPairDStream<String, String> javaPairDStream = javaInputDStream.mapToPair(new PairFunction<ConsumerRecord<String, String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(ConsumerRecord<String, String> consumerRecord) throws Exception {
return new Tuple2<>(consumerRecord.key(), consumerRecord.value());
}
});
javaPairDStream.foreachRDD(new VoidFunction<JavaPairRDD<String, String>>() {
@Override
public void call(JavaPairRDD<String, String> javaPairRDD) throws Exception {
javaPairRDD.foreach(new VoidFunction<Tuple2<String, String>>() {
@Override
public void call(Tuple2<String, String> tuple2)
throws Exception {
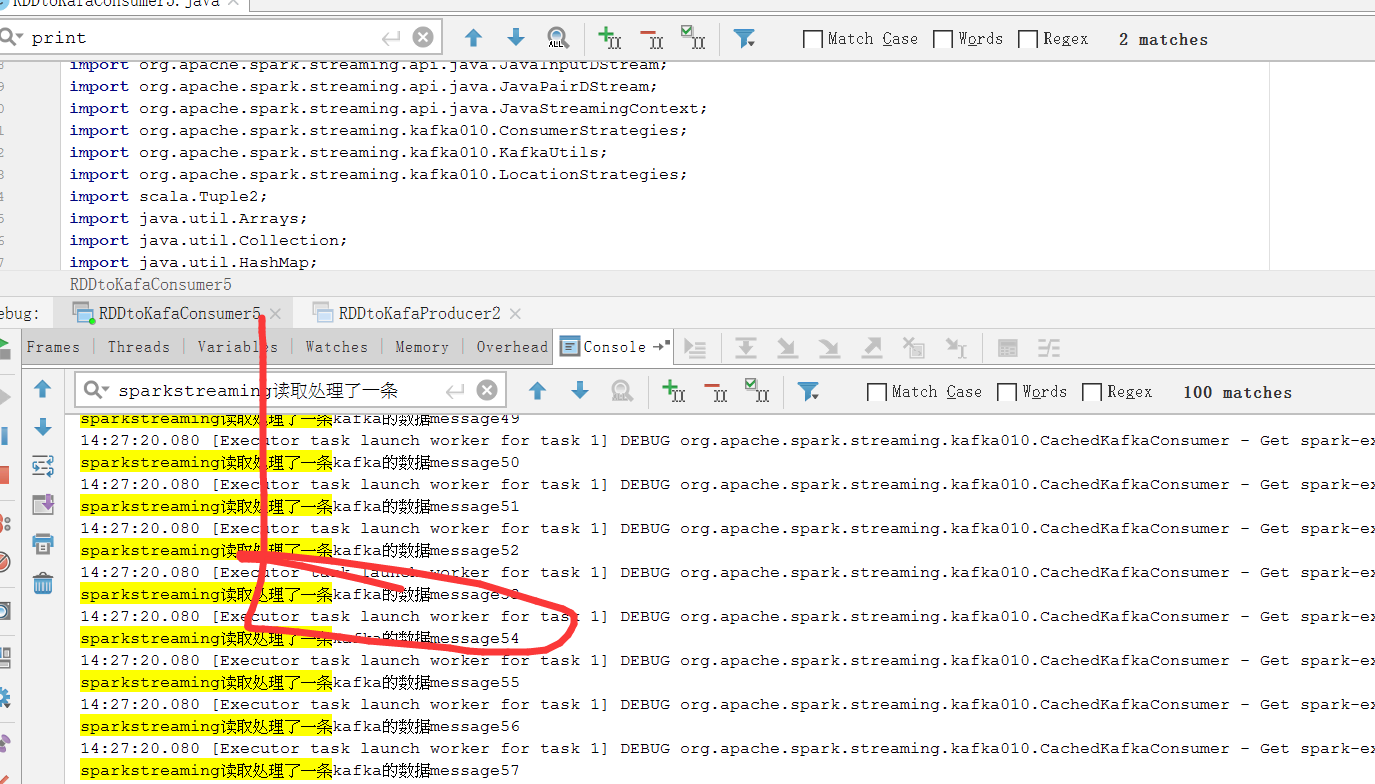
System.out.println("sparkstreaming读取处理了一条kafka的数据"+tuple2._2);
}
});
}
});
streamingContext.start();
streamingContext.awaitTermination();
System.out.println("spark启动成功!");
}
}
********************************************************************************************************************************
***************************************生产者**************************************************************************
5、RDDtoKafaProducer 生产者
######生产主题wordProducer2003
################bootstrap.servers localhost:9092
import java.util
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
/**
* kafka生产者
*/
object RDDtoKafaProducer {
def main(args: Array[String]): Unit = {
var brokers="localhost:9092"
var topic="wordProducer2003"//主题
var messagePerSec=5 //行数
var wordsPerMessage=7 //列数
//配置Zookeeper
val props= new util.HashMap[String,Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
var producer=new KafkaProducer[String,String](props)
//生成数据str
while (true){
(1 to messagePerSec).foreach({x=>
var str=(1 to wordsPerMessage).map(x=>scala.util.Random.nextInt(10).toString).mkString(" ")
println(str+"==》")
var message=new ProducerRecord[String,String](topic,null,str+"==》")
//str往kafka写入数据
producer.send(message)
})
Thread.sleep(1000)
}
}
}
6、RDDtoKafaProducer2 生产者
######生产主题wordProducer2003
################bootstrap.servers localhost:9092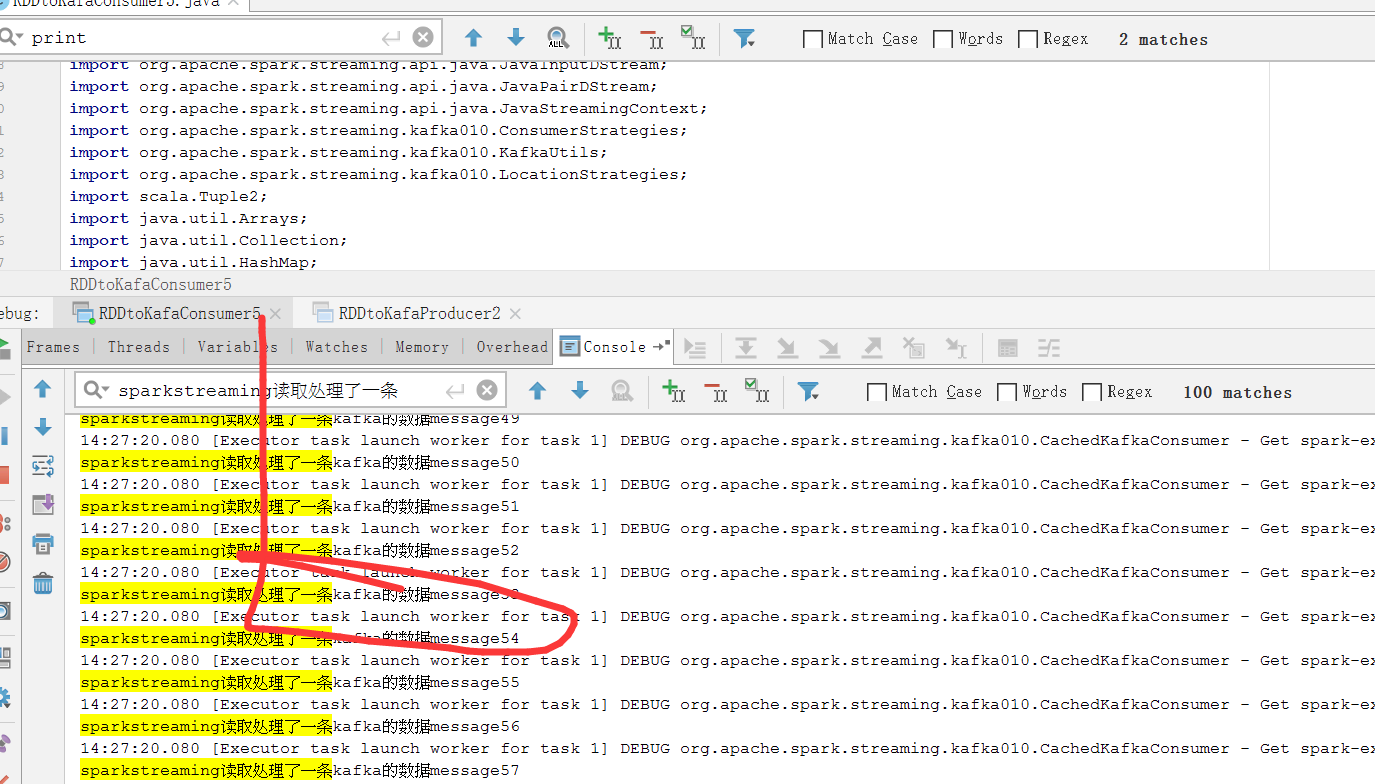
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
public class RDDtoKafaProducer2 {
public static void main(String[] args) {
// 1、定义生产者连接Kafka集群的配置项 key-value格式的
Properties prop = new Properties();
prop.put("bootstrap.servers", "localhost:9092");
// key序列化
prop.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
// value序列化
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者
KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(prop);
// 3. 使用生产者向某个主题发送一个数据
for (int i = 0; i < 100; i++) {
// 生产者需要发送的消息
ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>("wordProducer2003", i, "message" + i);
producer.send(record, new Callback() {
/**
* 方法就是kafka生产者消息发送完成之后,触发的一个回调函数
* @param recordMetadata 包含当前这个消息在Topic主题中的分区和offset
* @param e
*/
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println("当前这个数据的分区为:"+recordMetadata.partition() + "---offset:" + recordMetadata.offset());
System.out.println("当前的主题为"+recordMetadata.topic());
System.out.println("key为:" + recordMetadata.serializedKeySize() + "---value为:" + recordMetadata.serializedValueSize());
}
});
}
// 4. 代表将生产者生产的数据刷新到topic中
producer.flush();
}
}
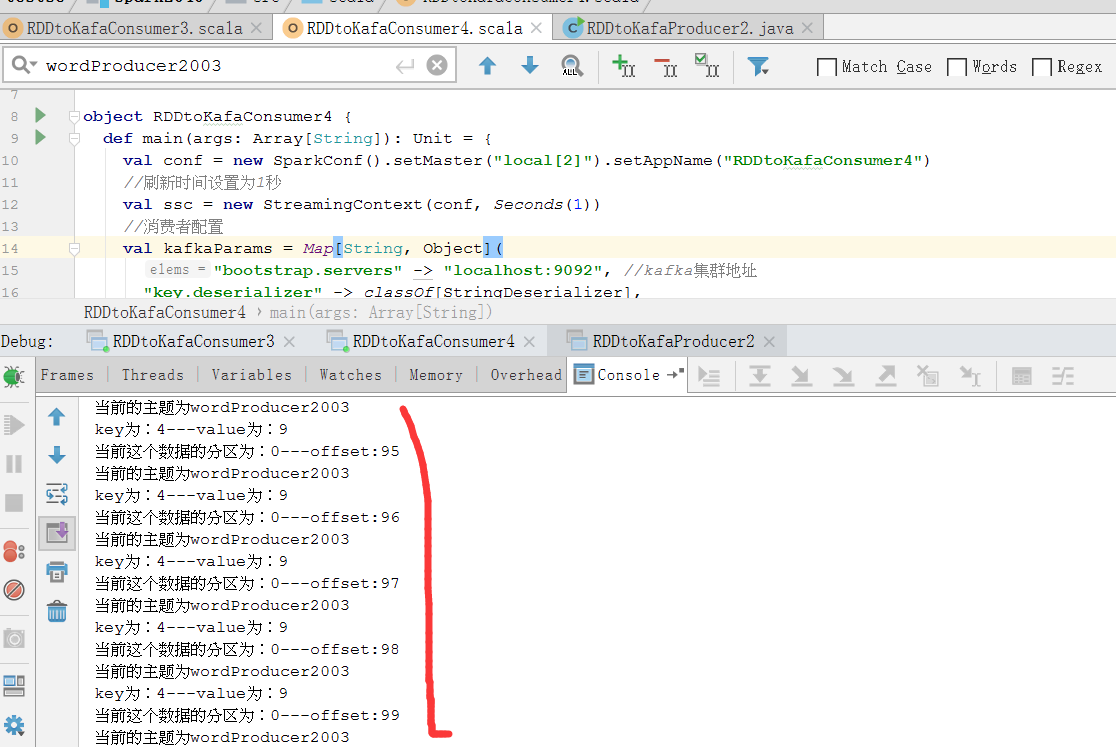
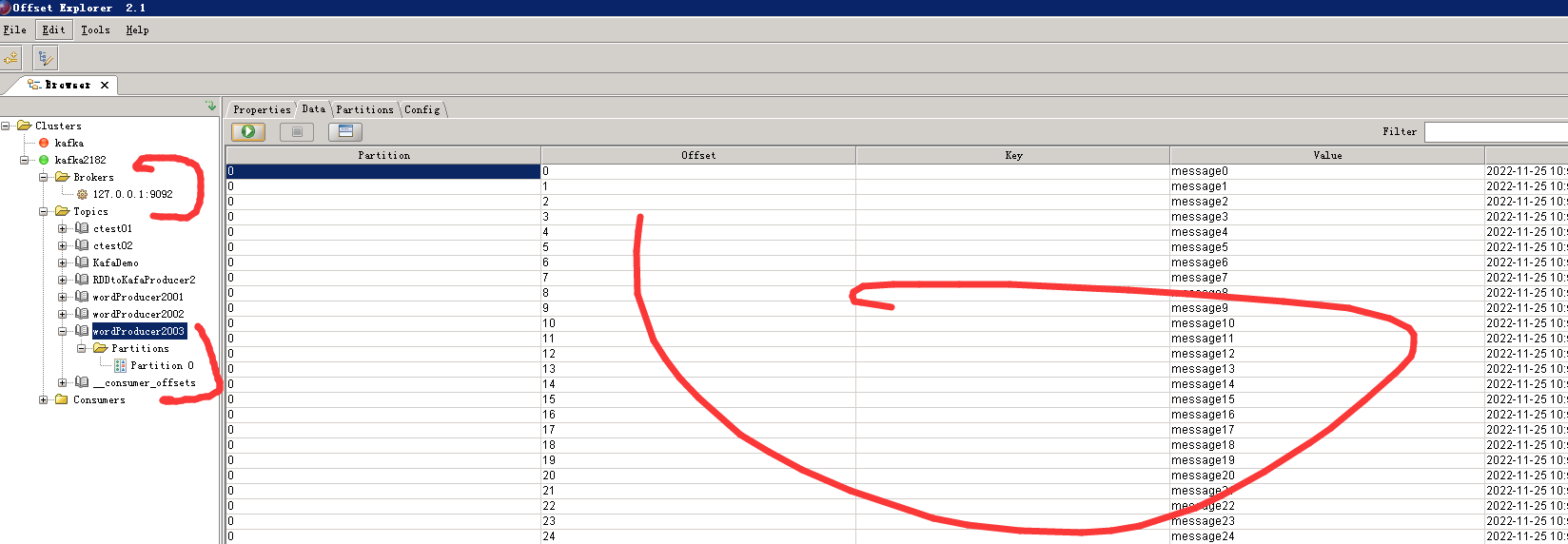
7、查看kafka信息
8、kafka 出现问题
1)、
Group coordinator lookup failed: The coordinator is not available.问题
把kafka、zookeeper 缓存先清一下
2)、启动kafka
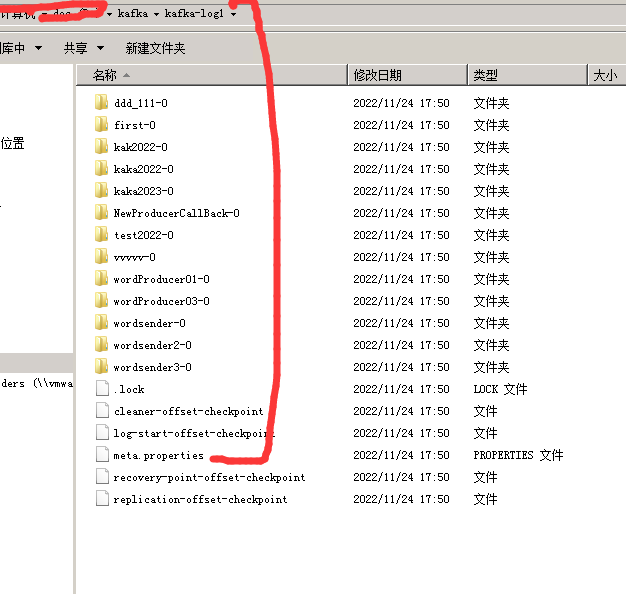
Kafka启动报错:The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
删除这里面的meta.properties文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号