03_虚拟机栈
数据结构栈
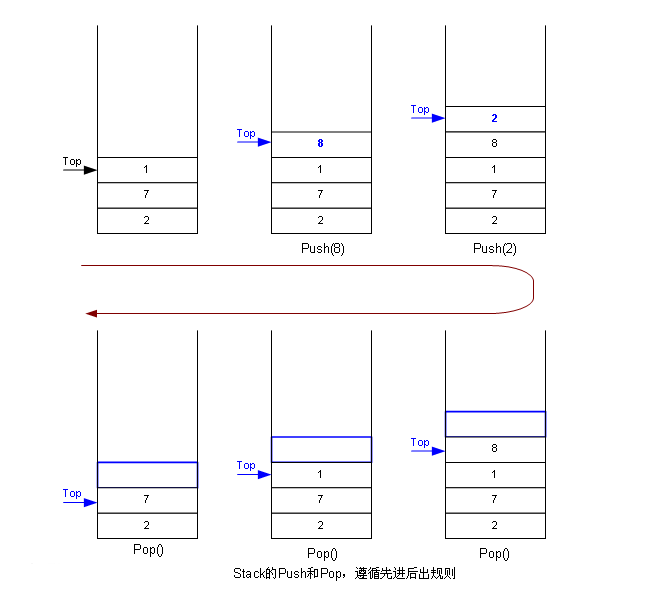
栈作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。
虚拟机栈
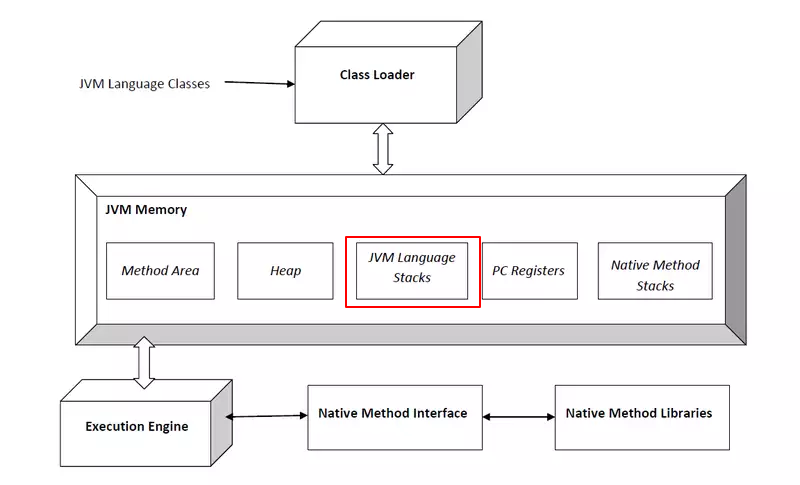
区别于数据结构中的栈,虚拟机中的栈除了结构上遵循栈的数据结构外栈内存放的每个元素叫栈帧,其相关定义如下:
- 每个线程运行需要的内存空间,称谓虚拟机栈
- 每个栈由多个栈帧组成,对应着每次调用方法时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的方法

- 程序开始执行,未调用任何方法,此时虚拟机栈为空
- 调用方法1,此时将方法1对应的栈帧1入栈
- 由于方法1中调用了方法2,此时将方法2对应的栈帧2入栈
- 由于方法2中调用了方法3,此时将方法3对应的栈帧3入栈
- 方法3执行完毕将栈帧3出栈
- 方法2执行完毕将栈帧2出栈
- 方法1执行完毕将栈帧1出栈
栈帧演示
演示代码如下:
package org.slumberjax.jvm.d03;
public class T01 {
public static void main(String[] args) {
method1();
}
private static void method1() {
method2(1, 2);
}
private static int method2(int a, int b) {
int c = a + b;
return c;
}
}
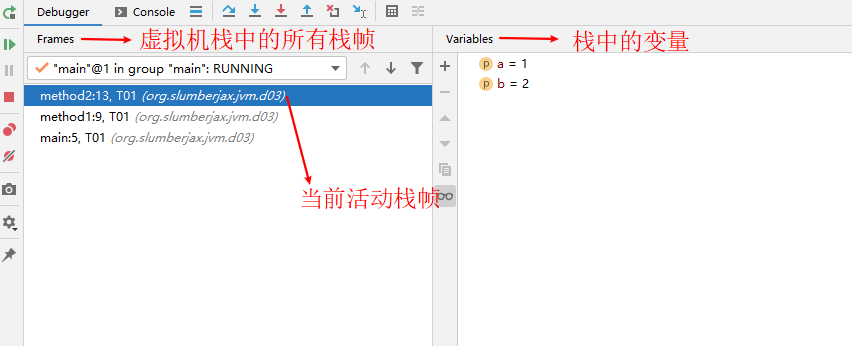
以下为在IDE(idea)中断点调试时的栈帧演示截图:
问题辨析
垃圾回收是否涉及栈内存?
答: 不需要。因为虚拟机栈中是由一个个栈帧组成的,在方法执行完毕后,对应的栈帧就会被弹出栈。所以无需通过垃圾回收机制去回收内存。
栈内存的分配越大越好吗?
答: 不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。比如物理内存为500MB,栈内存分配为1MB,则可以同时运行500个线程,若将栈内存分配为2MB,则可以同时运行250个线程.通过-Xss参数可以制定JVM栈内存大小,下面是oracle官方列出的不同操作系统的默认栈内存大小
-Xss size
Sets the thread stack size (in bytes). Append the letter k or K to indicate KB, m or M to indicate MB, and g or G to indicate GB. The default value depends on the platform:
Linux/x64 (64-bit): 1024 KB
macOS (64-bit): 1024 KB
Oracle Solaris/x64 (64-bit): 1024 KB
Windows: The default value depends on virtual memory
The following examples set the thread stack size to 1024 KB in different units:
-Xss1m
-Xss1024k
-Xss1048576
方法内的局部变量是否线程安全?
我们从几个案例来分析说明这个问题:
代码1如下:
package org.slumberjax.jvm.d03;
public class T02 {
static void method1() {
int x = 0;//定义变量x
/*
循环5000次对x进行自增
*/
for (int i = 0; i < 5000; i++) {
x++;
}
System.out.println(x);
}
}
问: 有多个线程同时执行method1方法,会不会造成x的值混乱?
答: 不会,因为一个线程对应一个虚拟机栈(栈是线程私有的),线程内每次方法调用都会产生一个新的栈帧,多个线程同时执行method1时,各自在各自的虚拟机栈上创建method1的栈帧,互相独立,互不影响.,因此上面的代码中的局部变量x是线程安全的
代码2如下:
package org.slumberjax.jvm.d03;
public class T03 {
public static void method1() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static void method2(StringBuilder sb) {
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static StringBuilder method3() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
return sb;
}
}
问: 上述代码中的三个方法中的变量sb是否线程安全?
答:
method1中的sb是线程安全的,其原因同代码1中的method1
method2中的sb线程不安全,sb对象是作为参数传递到method2中,这意味着其他线程能访问到sb,不再是线程私有的,代码如下:
package org.slumberjax.jvm.d03;
public class T03 {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
sb.append(4);
sb.append(5);
sb.append(6);
new Thread(() -> {
method2(sb);
}).start();
}
public static void method1() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static void method2(StringBuilder sb) {
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static StringBuilder method3() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
return sb;
}
}
在原有的代码上新增了主方法,在主方法中创建sb对象并操作其值,并开启线程调用method2,这样导致主线程和子线程都在对sb对象进行修改,两个线程都在操作sb,不再线程安全
method3中的sb同样也是线程不安全的,其原因为sb作为了返回值,返回后仍可以被其他线程进行修改,因此他是不安全的
通过代码1和代码2的分析,总结出该问题的结论为:
方法内的局部变量是否是线程安全的?
- 如果方法内局部变量没有逃离方法的作用范围,则是线程安全的
- 如果如果局部变量引用了对象,并逃离了方法的作用范围,则需要考虑线程安全问题
栈内存溢出
Java.lang.stackOverflowError 栈内存溢出
- 虚拟机栈中,栈帧过多(无限递归)
- 每个栈帧所占用过大(实际情况下基本不会出现栈帧过大导致的栈溢出,单个栈帧占用的内存都是很小的)
无限递归导致栈溢出案例1
代码如下:
package org.slumberjax.jvm.d03;
/**
* 演示栈内存溢出 -Xss256k
*/
public class T04 {
private static int count;//定义计数变量存储递归调用次数
public static void main(String[] args) {
try {
method1();
} catch (Throwable e) {
e.printStackTrace();
System.out.println(count);
}
}
/**
* 递归调用method1并记录进行了多少次递归调用
*/
public static void method1() {
count++;
method1();
}
}
我的电脑执行结果如下:
java.lang.StackOverflowError
at org.slumberjax.jvm.d03.T04.method1(T04.java:24)
...
...
at org.slumberjax.jvm.d03.T04.method1(T04.java:24)
24852
Process finished with exit code 0
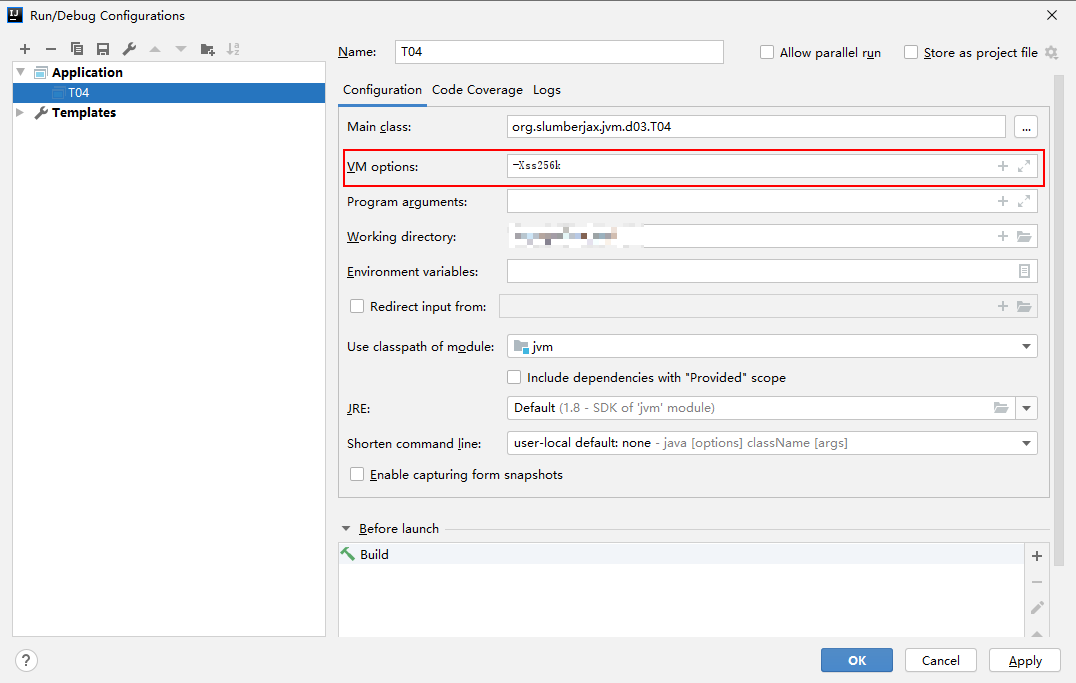
递归了24862次,再修改-Xss参数 减小栈内存,观察递归次数是否减少.intellij idea可以通过Edit Configurations来修改jvm参数,如下图
再次运行结果如下:
java.lang.StackOverflowError
at org.slumberjax.jvm.d03.T04.method1(T04.java:24)
...
...
at org.slumberjax.jvm.d03.T04.method1(T04.java:24)
4498
Process finished with exit code 0
由于栈内存减少,导致了可入栈的栈帧数减少,递归次数降低到4498次
无限递归导致栈溢出案例2
有的时候并不是自己写的代码导致方法的无限递归造成的栈溢出,第三方库的代码也有可能造成栈溢出,代码如下:
package org.slumberjax.jvm.d03;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.util.Arrays;
import java.util.List;
class Employee {
private String name;
private Department department;//所属部门
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
class Department {
private String name;
private List<Employee> Employees;//部门下的所有员工
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Employee> getEmployees() {
return Employees;
}
public void setEmployees(List<Employee> employees) {
Employees = employees;
}
}
public class T05 {
public static void main(String[] args) throws JsonProcessingException {
Department d = new Department();
d.setName("Market");
Employee e1 = new Employee();
e1.setName("Sawyer");
e1.setDepartment(d);
Employee e2 = new Employee();
e2.setName("Anna");
e2.setDepartment(d);
d.setEmployees(Arrays.asList(e1, e2));
ObjectMapper mapper = new ObjectMapper();//jackson
System.out.println(mapper.writeValueAsString(d));//jackson将对象转换为json字符串
}
}
运行结果如下:
Exception in thread "main" com.fasterxml.jackson.databind.JsonMappingException: Infinite recursion (StackOverflowError) (through reference chain: org.slumberjax.jvm.d03.Employee["department"]->org.slumberjax.jvm.d03.Department["employees"]->java.util.Arrays$ArrayList[0]->org.slumberjax.jvm.d03.Employee["department"]->org.slumberjax.jvm.d03.Department["employees"]->java.util.Arrays$ArrayList[0]->org.slumberjax.jvm.d03.Employee["department"]->org.slumberjax.jvm.d03.Department["employees"]->java.util.Arrays$ArrayList[0]->org.slumberjax.jvm.d03.Employee["department"]->org.slumberjax.jvm.d03.Department["employees"]->java.util.Arrays$ArrayList[0]->org.slumberjax.jvm.d03.Employee["department"]->org.slumberjax.jvm.d03.Department["employees"]-
Process finished with exit code 1
造成这个的原因是,在解析Department对象为json字符串时,无限递归解析造成,解析Department内部的Employee时,发现Employee中有Department,又开始解析Department,解析Department时又去解析Employee,而Employee中又有Department........
解决方案:
- 在类设计时避免这样的双向引用
- 通过jackson的注解忽略解析某些属性,打破json解析时的这种循环引用
方案2代码如下:
class Employee {
private String name;
@JsonIgnore
private Department department;//所属部门
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
修改后代码正常运行输出如下:
{"name":"Market","employees":[{"name":"Sawyer"},{"name":"Anna"}]}
线程运行诊断
下面两个案例均是模拟实际生产环境,复现具体场景和响应的解决方案
程序运行环境如下:
操作系统: Centos-7-x86_64-2003
JDK:jdk-8u261-linux-x64.rpm
案例1之CPU占用过多
已知有一台运行Java程序的服务器CPU占用很高,该服务器上的程序运行都很缓慢,如何解决?
解决步骤如下:
- 使用
top命令定位是哪个java进程占用CPU过高 - 使用
ps命令定位到是该进程(第1步定位出的进程)的哪个线程占用过高 - 使用
jstack分析java进程详细情况
具体步骤如下
-
top定位占用CPU过高的进程,结果如下图:
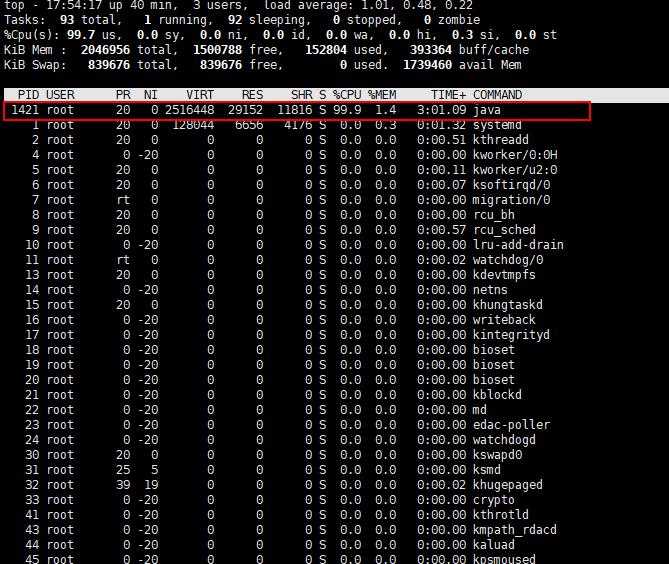
得到占用CPU过高的进程号为PID 1421
-
ps H -eo pid,tid,%cpu | grep 1421查看进程1421下的所有线程占用CPU详情,得到如下结果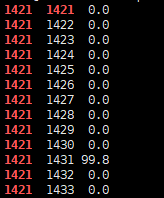
得到占用CPU过高的线程为1431
-
jstack 1421分析java进程1421下的java线程详情(由于ps命令查看的线程号为10进制,jstack输出的线程号为16进制,先将1431转为16进制得到597),得到如下结果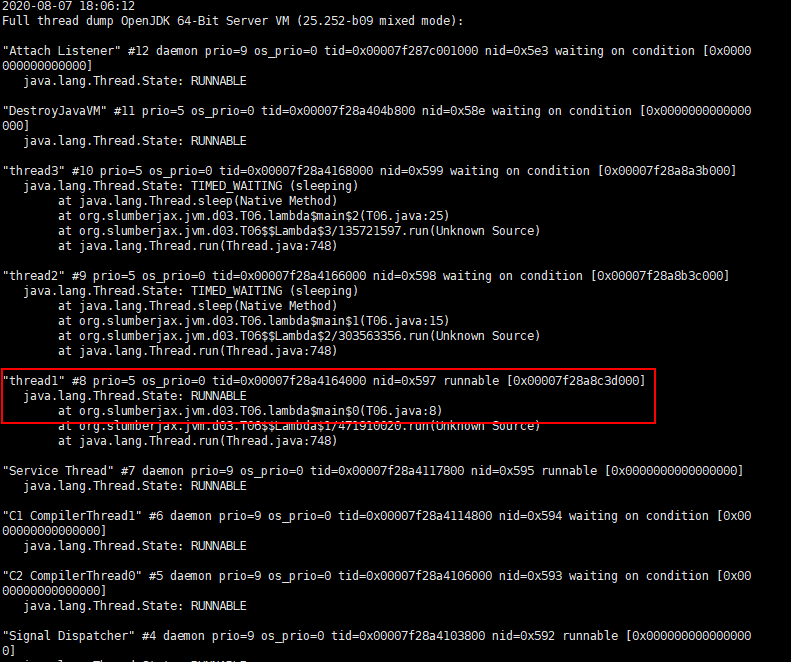
最终定位到1431对应的0x597名为thread1的线程,该线程处于运行状态,代码执行位置在T06的第8行,此时再去追溯源码查找原因
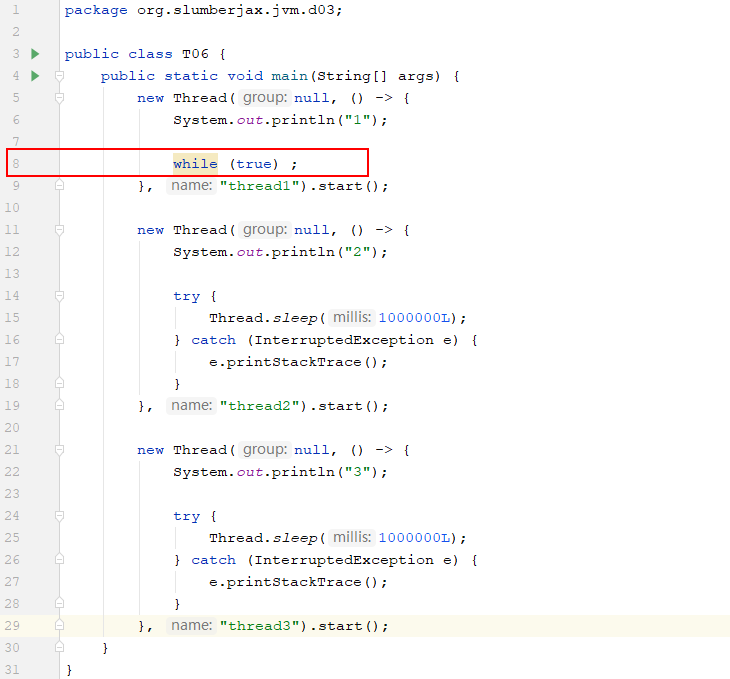
果然第8行的代码有问题,死循环导致CPU占用过高
案例2之程序运行很长时间没有结果
在服务器上运行如下程序(假设代码非本人编写,未查看源码),本应有输出结果,但运行后一直卡住,得不到结果,如图所示:

使用jstack工具来分析这个进程,得到如下结果:
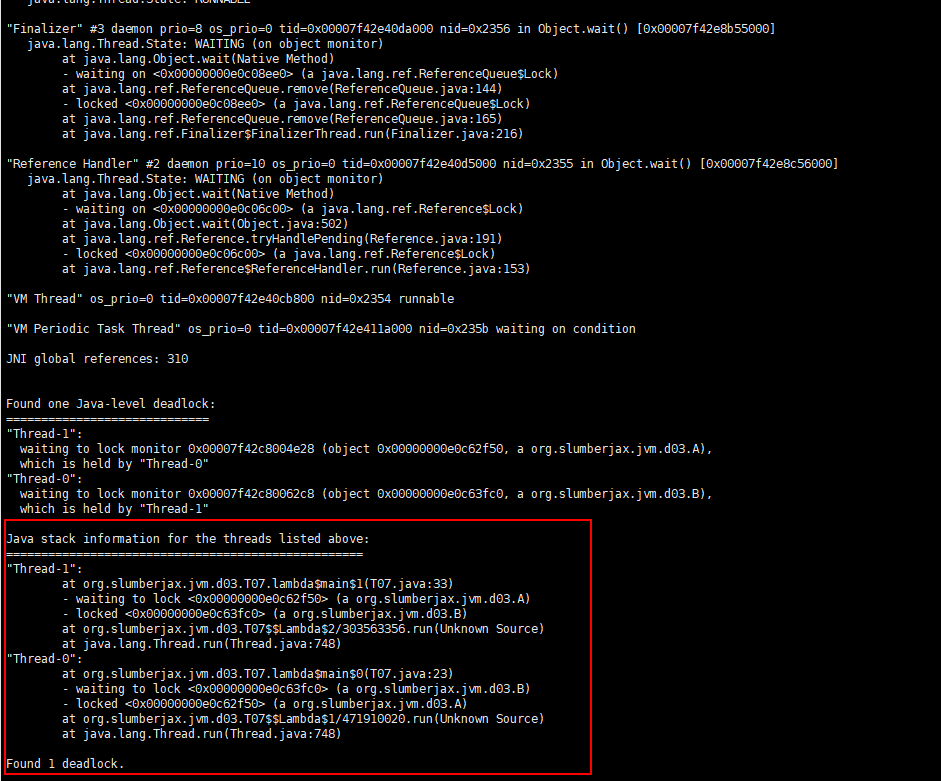
发现了红框框出来部分的死锁,此时去找到开发这个程序的小伙伴找出源码,如下,果然
package org.slumberjax.jvm.d03;
class A {
}
class B {
}
public class T07 {
static A a = new A();
static B b = new B();
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
synchronized (a) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (b) {
System.out.println("我获得了a 和 b");
}
}
}).start();
Thread.sleep(1000);
new Thread(() -> {
synchronized (b) {
synchronized (a) {
System.out.println("我获得了 a 和 b");
}
}
}).start();
}
}
-
线程0在运行时锁住了对象a,再休眠两秒后,尝试锁住对象b
-
在线程0休眠的期间,主线程休眠1秒后开始执行线程1,线程1尝试锁住对象b,再尝试锁住对象a
-
但线程0早已锁住了对象a,线程1此时等待线程0释放对象a的锁,因此整个程序执行1秒后,线程1处于等待状态
-
时间继续流逝,过了2秒,线程0睡眠完毕并尝试获得对象b的锁,但b对象在一秒前已被线程1锁住,线程0此时陷入等待状态
-
最后线程0和线程1处于互相等待状态,形成死锁
以上是对一个因死锁造成的长时间没有运行结果的程序分析,案例虽然简单,但已够用,实际生产环境大同小异,排查步骤通用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号