
原文地址:http://mp.weixin.qq.com/s?__biz=MzAxOTAzMDEwMA==&mid=2652502581&idx=1&sn=0c26519bcbb48efa44d916a08e2fa046&chksm=8020130eb7579a1880365bda09c1fc0be1059ff69bcc6f8300b40ac4c98b412a1f880b4d97fd&mpshare=1&scene=23&srcid=0410qVBJvXGbJLbLzyuTiWyK#rd
一、OpenStack测试概要
随着,云计算在国内外的迅猛发展,OpenStack业已成为这方面的既定事实标准,而众多企业在基于OpenStack开发云产品时,自然地,对测试方面的需求和质量提出了更高的要求。
目前,OpenStack社区已有近百个项目、数千名开发人员、数千万行代码和数百家公司参与其中。如何确保如此众多且水平不同、目的不同的开发人员,按照某种规则贡献智慧、提交代码,促进OpenStack开源社区有序、稳定健康发展。为此,社区在CI(持续集成)中提出了一种规则,——Gate,即门禁系统之意。凡开发人员提交代码(站在门外),均务必测试成功后(门禁系统验证身份通过),代码才会进入到Git仓库中(站在门内)。
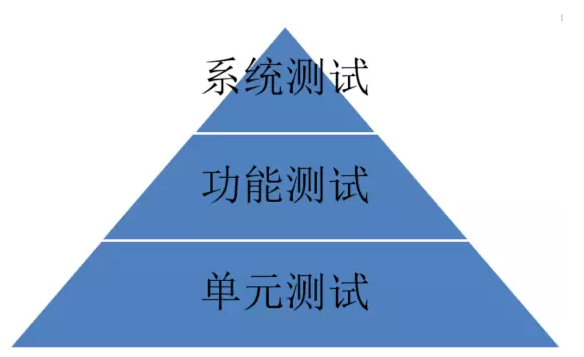
OpenStack测试,是一个涉及层面非常广泛和多技术交叉应用的领域。根据不同层面,即纬度的划分主要有:单元测试——>功能测试(也称为集成测试)——>系统测试(如验收测试、性能测试)等。根据特定的测试对象和目标,又可以分为存储测试、虚拟机网络测试、故障HA测试等。如下图所示。
在测试方面,OpenStack社区做得非常完善,针对不同的测试层面,设计并实现了相应的测试工具或项目。具体如,使用Python PEP8等测试代码编写是否符合规范,Nose等框架用于单元测试、Tempest用于功能/集成测试、Rally用于性能测试、Shaker用于虚拟机网络测试、DevStack用于部署测试等,除此外,还有各种环境兼容性测试,如Python2.7和Python3.4、Centos系和Debian系等环境测试。

二、OpenStack功能测试设计与实现
以上,是对OpenStack测试的概要介绍,是一个面。这里,针对一个点进行详细阐述,即使用Tempest自动化测试OpenStack的功能,具体包括测试Keystone、Glance、Cinder、Nova、Neutron和Swift等项目功能。
由于Tempest大部分功能社区已经开发实现,所以在企业的研发测试环境下,用户可以按照自己的需求进行扩展使用等。目前,Tempest已广泛应用于CI持续集成、OpenStack社区互操作性测试认证等领域。
1.在Docker中运行Tempest
“工欲善其事,必先利其器”。首先,需要安装并配置好Tempest测试环境,由于Docker具有轻量、环境隔离、一次打包处处运行的优秀特性,故此,这里选择将Tempest安装部署在Docker容器中。
举个简单例子,当测试A环境的OpenStack时,需要构建好一个诸如Tempest在内的测试平台;当测试B环境的OpenStack时,又需要构建好一个同样的测试平台;同时,因不同环境的反复配置容易导致测试环境配置错误。综上,选择Docker运行是一种更好的方式。
Tempest测试的实现是基于Python的unittest2和nose框架。通过对Openstack后端发起一系列API请求,并且对后端的响应进行验证。Tempest使用config配置文件来描述整个测试环境,包括Nova 、Keystone、Glance、Neutron等OpenStack相关服务。并同时支持 JSON、XML 两种 REST API 格式类型的测试, 以及 CLI 测试。
Tempest的优点
-
Tempest可以自动寻找,执行测试:自动查找当前目录下所有以[Tt]est开头的Python源文件,并且按此规则递归查找子目录;所有以[Tt]est开头的Python源文件里所有以[Tt]est开头的function和class,以及继承自unittest.TestCase的class(不需要以[Tt]est开头)都会被执行。
-
Tempest可以指定文件、模块、函数进行测试。
-
Tempest可以指定类型进行测试。
-
Tempest可扩展性强,可以方便的在tempest中添加其他测试用例,可以整合其他类型测试例如压力测试、场景测试等。
-
Tempest是通过nose驱动的,python语言编写,使用testtools和testresources等几个测试工具库
-
Tempest.test.BaseTestCase,BaseTestCase声明config属性,读取配置文件
-
Tempest.test.TestCase声明很多工具函数,供调用。每个测试可以分别测试JSON格式和XML格式
当然,它的缺点是需要手动配置tempest.conf环境描述文件,工作量大,容易出错。
Tempest 代码主要结构,如下所示。其中,api和scenario部分的测试用例是我们关注的重点。
tempest/
├── etc/ <--tempest相关配置文件目录
├── tempest/ <--各个组件测试用例
├── api <--OpenStack组件API接口测试用例
├── common <--测试通用类例如Rest Client
├── hacking <--用于代码风格检测,如 pep8等
├── scenario <--根据一些复杂场景进行测试,属于系统测试
├── services <--给相应的组件提供模块接口
├── stress <--压力测试,目前可以结合rally进行压力测试
├── test_discover <--继承unittest,从api等处查找用例
├── tests <--针对tempest代码本身的单元测试
├── tools/ <--搭建环境的脚本测试用例和REST API交互流程,如下图所示。

1)安装Docker和Tempest
# yum install docker -y编写dockerfile文件,用于构建Tempest镜像,内容如下所示
# cat dockerfile
FROM centos:7
MAINTAINER Xuchao <test@126.com>
# Install dependencies tools
RUN yum -y install epel-release
RUN yum install -y gcc git libxslt-devel openssl-devel
RUN yum install -y libffi-devel python-devel python-pip python-virtualenv
RUN pip install junitxml
# Cloning tempest
RUN git clone https://github.com/openstack/tempest.git
# Installing tempest dependencies
RUN cd tempest && python setup.py install
RUN pip install -r /tempest/requirements.txt
RUN pip install -r /tempest/test-requirements.txt
# Generate configuration files
RUN pip install tox
RUN cd tempest && tox -egenconfig
# Copy sample configuration
RUN cp tempest/etc/{tempest.conf.sample,tempest.conf}
RUN cp tempest/etc/{accounts.yaml.sample,accounts.yaml}
# Running tempest setup
RUN cd tempest && testr init
WORKDIR /tempest执行镜像构建命令
# docker build -t tempest_docker:1.0 .查看构建的镜像
# docker images | grep tempest
tempest_docker 1.0 02970e7ee390 5 hours ago 763.2 MB以后台运行方式启动Tempest镜像
# docker run -d -it tempest_docker:1.0 /bin/bash查看运行中的Tempest容器
# docker ps | grep tempest
0a5cf6c1d4b8 tempest_docker:1.0 "/bin/bash" 49 seconds ago Up 48 seconds silly_kilby8进入到Tempest容器中,进行操作
# docker exec -u root -it 0a5cf6c1d4b8 bash2)配置文件 使用tempest,需要配置tempest.conf和accounts.yaml两个文件。
这里,首先配置accounts.yaml文件。该文件内容包括了Tempest测试OpenStack所需要的认证信息,如租户、用户和密码等信息。示例如下:
# egrep "^[^#]" accounts.yaml
- username: 'demo1'
tenant_name: 'demo1'
password: '123456'
- username: 'demo2'
tenant_name: 'demo2'
password: '123456'
- username: 'demo3'
tenant_name: 'demo3'
password: '123456'
roles:
- 'fun_role'
- username: 'swift _user'
tenant_name: 'swift_tenant'
password: '123456'
types:
- ' SwiftOperator'
- username: 'admin'
tenant_name: 'admin'
password: 'admin'
types:
- 'admin'
resources:
network: ' public_net '
router: 'router'接着,配置tempest.conf文件,这里以配置[identity]部分测试Keystone服务为例。如果需要测试诸如Compute、Network、Volume等服务,根据注释提示配置相关选项即可。示例如下。
# egrep "^[^#]" etc/tempest.conf
[DEFAULT]
[alarming]
[auth]
Tempest_roles = Member//为Tempest设置的角色
admin_username = admin //管理员用户名
admin_tenant_name = admin//管理员租户名
admin_password = admin //管理员用户密码
[baremetal]
[compute]
[compute-feature-enabled]
[dashboard]
[data-processing]
[data-processing-feature-enabled]
[database]
[debug]
[identity]
catalog_type = identity //测试的类型
uri = http://10.10.xx.xx:5000/v2.0 //Keystone服务的Endpoint
auth_version = v2 //Keystone服务的版本
region = RegionOne //Keystone服务的Region
v2_admin_endpoint_type = adminURL//Keystone服务的Admin Endpoint
v2_public_endpoint_type = publicURL //Keystone服务的Public Endpoint
username = demo //一个测试用户
tenant_name = demo //一个测试租户
admin_role = admin //一个测试角色
password = 123456 //测试用户的密码
[identity-feature-enabled]
api_v2 = true//指定测试v2版本的Keystone
api_v3 = false//指定不测试v3版本的Keystone
[image]
[image-feature-enabled]
[input-scenario]
[negative]
[network]
[network-feature-enabled]
[object-storage]
[object-storage-feature-enabled]
[orchestration]
[oslo_concurrency]
[scenario]
[service_available]
[stress]
[telemetry]
[telemetry-feature-enabled]
[validation]
[volume]
[volume-feature-enabled]2.查看Tempest测试用例
在实际的测试环境中,QA测试人员会不断地编写各种类型的测试用例。对于我们自己开发的测试用例,自然十分清楚用例执行的类型、名称和内容等。对于Tempest、Rally和Shaker这种社区的自动化测试项目,我们如何了解其测试用例呢?
下面,是一个用于获取Tempest项目tempest/api目录下测试用例的bash脚本。
#!/bin/sh
mkdir -p tempest_result && rm -f tempest_result/*
testcase_number=tempest_result/testcase_number.txt
testcase_list=tempest_result/testcase_list.txt
for openstack_projects in identity image compute network volume
do
projects_dir=tempest/api/$openstack_projects
projects_num=`grep -rn '\<def test_' $projects_dir | wc -l`
echo "$openstack_projects testcase number: "$projects_num >> $testcase_number
echo "Keystone(identity) testcase list: " >> $testcase_list && grep -rn '\<def test_' tempest/api/identity | awk '{print $3,NR}' >> $testcase_list
echo "Glance(image) testcase list: " >> $testcase_list && grep -rn '\<def test_' tempest/api/image | awk '{print $3,NR}' >> $testcase_list
echo "Nova(compute) testcase list: " >> $testcase_list && grep -rn '\<def test_' tempest/api/compute | awk '{print $3,NR}' >> $testcase_list
echo "Neutron(network) testcase list: " >> $testcase_list && grep -rn '\<def test_' tempest/api/network | awk '{print $3,NR}' >> $testcase_list
echo "Cinder(volume) testcase list: " >> $testcase_list && grep -rn '\<def test_' tempest/api/volume | awk '{print $3,NR}' >> $testcase_list
sed -i 's/(self)//g' $testcase_list
done将以上内容写入脚本文件中,并放在Tempest目录下。执行该脚本,会在tempestresult目录下分别输出testcaselist.txt和testcase_total.txt文件,前者用于存放tempest/api目录下各项目服务的测试用例,后者用于存放每个项目服务的测试用例统计数量。
打开testcase_list.txt文件,部分内容如下:
# cat testcase_list.txt
Keystone(identity) testcase list:
test_list_endpoints: 1
test_create_list_delete_endpoint: 2
test_list_roles: 3
test_role_create_delete: 4
test_get_role_by_id: 5
test_assign_user_role: 6
test_remove_user_role: 7
test_list_user_roles: 8
test_list_roles_by_unauthorized_user: 9
test_list_roles_request_without_token: 10
……
……查看testcase_number.txt文件,内容如下:
# cat testcase_number.txt
Identity testcase number: 172
Image testcase number: 63
Compute testcase number: 510
Network testcase number: 162
Volume testcase number: 1543.Tempest代码调试
1.安装ipdb库
# pip install ipdb2.调试测试程序
如果某个用例执行出错,可能需要加入断点单步调试,可以用pdb调试库来完成调试工作,但笔者更建议用ipdb库来调试,这个库更智能易用,它的缺点是非Python系统库,需要手工安装才能使用。
如果要加入断点单步调试,需要使用python -m testtools.run方法来执行被调试的用例,否则可能导致断点无法进入,也就没办法进行单步调试了,调试的第一步是在被调试的用例里面加上断点(下面以tempest.api.compute.servers.testserversnegative.ServersNegativeTestJSON.testrebootnonexistentserver用例为例进行说明,这里使用的是ipdb,pdb也是类似)。
@test.attr(type=['negative'])
@test.idempotent_id('d4c023a0-9c55-4747-9dd5-413b820143c7')
def test_reboot_non_existent_server(self):
import ipdb;ipdb.set_trace()
# Reboot a non existent server
nonexistent_server = data_utils.rand_uuid()
self.assertRaises(lib_exc.NotFound, self.client.reboot_server,
nonexistent_server, type='SOFT')之后,用python -m testtools.run运行这个用例即可进入断点调试模式。命令如下所示。
# python -m testtools.run tempest.api.compute.servers.test_servers_negative.ServersNegativeTestJSON.test_reboot_non_existent_server4.运行Tempest测试
执行Tempest测试,既可以使用testr也可以使用nosetests、ostestr、run_tempest.sh脚本等命令,但社区推荐使用ostestr命令。这里以testr使用为例进行介绍。
这里以测试Keystone v2版本的testlisttenantsreturnsonly authorizedtenants测试用例为例。命令如下:
# testr run tempest.api.identity.v2.test_tenants从下图中可以直接看到测试结果信息,这里显示该测试用例执行成功了,符合预期目的。
如果觉得这样的测试结果不方便浏览、分析或者出于保存用例的需要,也可以直接将该XML格式的结果文件拖放到Excel中浏览。
测试用例分析。
# vim tempest/api/identity/v2/test_tenants.py
from tempest.api.identity import base
from tempest.lib import exceptions as lib_exc
from tempest import test
class IdentityTenantsTest(base.BaseIdentityV2Test):
credentials = ['primary', 'alt']
@test.idempotent_id('ecae2459-243d-4ba1-ad02-65f15dc82b78')
def test_list_tenants_returns_only_authorized_tenants(self):
alt_tenant_name = self.alt_manager.credentials.tenant_name
resp = self.non_admin_tenants_client.list_tenants()
# check that user can see only that tenants that he presents in so user
# can successfully authenticate using his credentials and tenant name
# from received tenants list
for tenant in resp['tenants']:
body = self.non_admin_token_client.auth(
self.os.credentials.username,
self.os.credentials.password,
tenant['name'])
self.assertNotEmpty(body['token']['id'])
self.assertEqual(body['token']['tenant']['id'], tenant['id'])
self.assertEqual(body['token']['tenant']['name'], tenant['name'])
self.assertEqual(body['user']['id'], self.os.credentials.user_id)
# check that user cannot log in to alt user's tenant
self.assertRaises(
lib_exc.Unauthorized,
self.non_admin_token_client.auth,
self.os.credentials.username,
self.os.credentials.password,
alt_tenant_name)该测试用例的主要内容是,检查用户是否只可以看见同租户下的其他用户;验证用户所使用的凭证和租户名;最后检查用户不能登录到名为“alt”用户的租户。主要是调用assertEqual、assertRaises等断言方法来判断程序的执行结果和预期值是否相符。
如下,是一些testr测试的相关命令
1)使用testr,查看命令帮助信息
# testr help执行以下命令前,首先需要加载测试环境
# source .tox/py27/bin/activate直接运行测试
testr run --parallel
testr run --parallel test_name_regex测试结束后,查看失败的用例,并重新运行失败用例
testr failing
testr run --failing批量运行api、scenario两个测试用例集
# ostestr --regex '(?!.*\[.*\bslow\b.*\])(^tempest\.(api|scenario))'或者使用如下方法
# testr run或者,并行运行测试
# testr run --parallel或者,并行运行某一个测试用例集
# /root/tempest/tempest/api testr run --parallel运行单个测试用例
# testr run
tempest.api.compute.servers.test_servers_negative.ServersNegativeTestJSON.test_reboot_non_existent_server根据,OpenStack环境机器的CPU数量多少,设置并发量,比如这里设置为2。
# testr run --parallel -- concurrency=2执行测试分析
# testr run --analyze-isolation列出测试用例
# testr list-tests执行 Tempest的场景测试
# testr run --parallel tempest.scenario或者
# ./run_tempest.sh tempest.scenario只重新运行失败的测试用例
# testr run --failing为了更好的分析和浏览,我们可以将xml文件,直接拖放到Excel文档中。
2)测试结果
Tempest的测试结果有四种:测试错误(Error)、测试失败(Failure)、跳过(Skip)、成功(Success)。其含义分别如下。
-
测试错误:可以理解成测试代码执行时报错。比如测试代码中print a,而a没有进行变量声明。和setUp类似,如果代码在这个阶段出错,也都会被认为是测试错误(Error)。也可能是配置环境有问题。
-
测试失败:可以简单理解成测试代码执行正常,但没有得到预期的测试结果,比如在测试代码中调用功能代码add(1, 2),但返回结果不是3。
-
跳过:可以理解为测试忽略。比如某个用例只在CentOS系统下运行,这样在其他系统下就会被跳过,也就是忽略。还有可能是被测试的服务有bug。
-
成功:测试用例执行成功,即测试程序返回的结果值符合预期的目的。
5.开发测试报告
如何让Tempest API集成/功能测试自动化输出有利于分析和浏览的测试报告,并捕获测试中的失败用例,是QA测试人员工作的内容之一。我们需要尽可能地让看似模糊的测试结果可视化和数据化。
让Tempest测试自动化输出报告,需要使用HTMLTestRunner.py模块文件。其下载地址是:http://tungwaiyip.info/software/HTMLTestRunner.html。
这里假定Tempest源码仓库位于/tempest目录下。则执行如下步骤。
# cd /tempest将HTMLTestRunner.py和自动化测试程序文件(比如,这里提供的用例程序tempest_keystone.py)一并存放在Tempest目录下。代码如下:
#!/usr/bin/env python
#coding=utf-8
import HTMLTestRunner
import unittest,time
import re,os,sys
def createsuite():
#定义一个单元测试容器
testunit=unittest.TestSuite()
#定义测试文件查找的目录
#此处,测试identity项目中v2目录下的以test开头的测试用例
test_dir='tempest/api/identity/v2'
#定义discover方法的参数
discover=unittest.defaultTestLoader.discover(test_dir,pattern='test*.py', top_level_dir=None)
#将discover方法筛选出来的测试用例,循环添加到测试套件中
for test_case in discover:
print test_case
testunit.addTests(test_case)
return testunit
now = time.strftime("%Y-%m-%d")
#测试报告存放路径
filename = '/home/'+now+'_keystone.html'
fp = file(filename,'wb')
runner = HTMLTestRunner.HTMLTestRunner(
stream=fp,title=u'OpenStack Keystone API功能测试',description=u'用例执行情况:')
if __name__ == '__main__':
alltestnames = createsuite()
#运行所有测试
runner.run(alltestnames)
fp.close()代码说明如下:
unittest模块中的TestLoader类有一个discover方法。通过使用该方法,如discover(start dir, pattern='test*.py',topleveldir=None),递归查找指定目录(startdir)及其子目录下的全部测试模块,然后将这些测试模块放入TestSuite对象中并返回。只有匹配pattern的测试文件才会被加载到TestSuite中。
如果一个测试文件的名称符合pattern,将检查该文件是否包含 loadtests() 函数,如果loadtests()函数存在,则由该函数负责加载本文件中的测试用例;如果不存在,就会执行loadTestsFromModule(),查找该文件中派生自TestCase类的以test开头的方法。
执行测试命令:
# python tempest_keystone.py执行测试命令后,会在/home目录下生成一份HTML格式的测试报告,使用浏览器打开该文件,如下图所示。
需要说明的是,这里是针对Tempest中的identity项目(Keystone认证服务)v2版本目录下的用例进行测试。如若运行其他项目测试,可参考此方法。
测试报告查看
对于测试结果报告,可以通过邮件和浏览器等多种方式查看。比如,我们可以开发程序,自动将测试报告发送到相关人员的邮件中,或者自动发送到Web服务器中,这样当我们使用浏览器访问某个URL地址,就可方便的看到测试结果。围绕这一内容,还可以将其应用到日常的QA测试、CI/CD等研发测试环节,起到以点带面的效果。
三、人工智能AI对软件测试的影响
自从,阿尔法狗(AlphaGo)在人机大战中,以3:0的绝对优势战胜李世石之后,AI便火得一塌糊涂,仿佛一夜之间不谈AI,便已感觉是来自外星球。那么AI对软件测试的影响如何呢。
软件测试技术发展至今,可以说基于页面对象的模型测试(POM)是一种更接近于人工智能的测试方法。但人工智能AI明显还要更进一步,要求可以实现自动的构造测试场景和测试用例。它要求测试人员首先基于软件功能构造出各种模型(或者叫做行为),然后制定行为和行为之间的关系以及行为和系统整体的关系,之后自动测试系统就可以智能的根据当前的被测系统的状态(场景)以及预设的规则,选择下一步要执行的行为。
理论上这种测试方法可以尽可能的遍历被测试系统中各种可能经历的行为链,从而极大的提高测试覆盖率。由于它每次执行的路径并非固定不变,所以可以构造出完全不同的测试用例,我们也可以称之为智能的软件测试。
基于模型的人工智能测试,首先就是要把各种OpenStack操作定义成模型。这里我们拿虚拟机的各种操作举例。通常,虚拟机具有多种状态,如运行、暂停、重启、迁移、快照等等,此时,我们可以在状态和状态之间定义一些标准的操作。当把这些状态和操作画出来后,我们就可以得到虚拟机的状态迁移图(或者说是虚拟机场景)。如下图所示。
可以看到,上图中Running和Stopped的状态之间可以通过stop和start操作做成状态环。那么智能测试就可以根据预先设定的规则,让虚拟机在这个环里做有限的测试。这一个看起来好像很简单,但是要知道OpenStack里面还有很多其他资源的状态迁移图,而且很多资源之间是有相互依赖关系的,例如在其他服务正常运行可用的前提下,虚拟机各种操作才会顺利执行。而且用户在操作OpenStack的时候,也不会只做虚拟机状态的改变,通常还会和其他资源的行为混合操作。所以,当把所有资源的迁移图画完,就会发现整个OpenStack的场景和可选的行为之间的关系是非常复杂的。
最后,关于Tempest还有很多故事点和内容可以进行研究,如测试用例和tempest.conf配置文件之间的关系、如何按照自身需求扩展Tempest测试用例等。本次分享内容整理自《OpenStack最佳实践 —测试与CI/CD》一书5.5.1小节,现已发售。
提问环节
比如说创一个虚拟机,有bug,也就是host os上可能留有脏数据,DB中也可能,这些东西怎么清理?或者说如何保证环境是干净的。尤其是hostos上的干净?
就拿Tempest来说吧,当它创建一个VM后,如果没有异常或错误(也有可能是程序bug)发生,tempest会自动删除掉vm及其相关的资源
请问现在你们开发是用什么工具?调试又是如何做的?刚才只看到测试部分,谢谢!
每个开发人员使用的工具不同,比如说我吧,看代码一般会用eclipse+pydev,调试一般用ipdb等等。
请问你们修改的代码都会提交到社区吗?如果有部分提交不了社区,请问你们是怎么维护的?再下次OpenStack版本发布是怎么合并的?谢谢!版本怎么做的控制?
针对软件项目,我们一般使用持续集成Jenkins来统一管理,对于DB数据字段更新多的业务,可能还需要其他来完善。
安全性测试如何做的呢?
对于安全性测试,每个人或者每个团队对它的侧重点不一样,比如会有常见的SQL注入、渗透、前端页面的漏洞扫描
很想知道针对openstack存储性能方面有什么比较好的测试方法吗?
针对openstack存储性能方面的测试,可以参见《OpenStack最佳实践-测试与CI/CD》第5.6小节,比如在openstack+ceph集成的情况下,从下往上,有服务器本身的,也有Ceph集群、RBD块存储、虚拟机等
测试各个组件的用例应该是涵盖了 各个组件的大部分功能吧?这些功能是必须在组件的配置文件中先全部配置的吧?
tempest支持主流项目的API功能测试,需要事先在tempest.conf文件中配置,目前来说,比较琐碎。
请问你们修改的代码都会提交到社区吗?如果有部分提交不了社区,请问你们是怎么维护的?再下次OpenStack版本发布是怎么合并的?谢谢!版本怎么做的控制?
如果,我们有fix的bug,由于各方面原因,无法进入到社区,但是在我们的产品中经验证通过,我们会打进产品中,对于版本的控制,内部使用gitlab
测试报告是否可以基于测试数据做智能分析和给出优化建议?
一个良好的测试报告,应该基于测试数据做出智能的分析和给出优化建议,测试的目的在于发现缺陷,并进行管控
我有200台不同厂家,不同型号的老旧pc服务器,如果用os来搞成一个大的集群,供测试或业务使用,是否可行?谈谈大体方案?
我有200台不同厂家,不同型号的老旧pc服务器,用于搭建OpenStack测试环境应该够了(没有特殊要求),但不太建议上生产系统。开发、测试、使用不用的OS环境即可,具体看自身对资源环境的隔离要求
OpenStack对硬件的最低配置要求?
OpenStack对硬件的最低配置要求,可以说下,我在大二时,在自己笔记本上的虚拟机(2Core、4GB内存)上搭建了一个all-in-one的OpenStack,也能部署成功,但基本没法用
作者生产上是如何容灾的?现在上云关注点对容灾和云安全有多点顾虑
对于生产环境上的云容灾,这是一个老生常谈的话题,不同的需求,可能有不同具体实现方案。比如ceph存储的,就会有多MON、多OSD。OpenStack服务的HA,可能有Haproxy、keepalived等。但我个人觉得,有效及时的监控和运维、预警,可能更为重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号