1-深入浅出Nodejs
web服务器
| 事件驱动 |
事件驱动是指在持续事务管理过程中,进行决策的一种策略,即跟随当前时间点上出现的事件,调动可用资源,执行相关任务,使不断出现的问题得以解决,防止事务堆积。 从事件角度说事件驱动程序的基本结构:一个事件收集器 + 一个事件发送器 + 一个事件处理器
|
| 非阻塞I/O |
Chrome VS Node

| WebKit |
是一个开源的浏览器引擎,是个非常好的网页解析机制。 包含: WebCore排版引擎 、 JSCore引擎、。。。 浏览器的内核引擎,基本上是四分天下:
Trident: IE 以Trident 作为内核引擎;
Gecko: Firefox 是基于 Gecko 开发;
WebKit: Safari, Google Chrome,傲游3,猎豹浏览器,百度浏览器 opera浏览器 基于 Webkit 开发。
Presto: Opera的内核,但由于市场选择问题,主要应用在手机平台--Opera mini
|
| V8 |
使用c++开发,并在google浏览器中使用 在运行js之前,相比其它的js的引擎转换成字节码或解释执行,V8将其编译成原生机器码(IA-32, x86-64, ARM, or MIPS CPUs),并且使用了如内联缓存(inline caching)等方法来提高性能。有了这些功能,js程序在V8引擎下的运行速度媲美二进制程序。 V8支持众多操作系统,如windows、linux、android等,也支持其他硬件架构,如IA32,X64,ARM等,具有很好的可移植和跨平台特性。 V8可以独立运行,也可以嵌入到任何C++应用程序。项目托管在Google Code上 [1] ,基于BSD协议,任何组织或个人可以将其源码用于自己的项目中。 |
| libuv |
是 Node 的新跨平台抽象层,用于抽象 Windows 的 IOCP 及 Unix 的 libev。作者打算在这个库的包含所有平台的差异性。 是一个跨平台的的基于事件驱动的异步io库。但是他提供的功能不仅仅是I/O,包括进程、线程、信号、定时器、进程间通信等。
|
| 显卡 |
将计算机系统需要的显示信息进行转换驱动显示器,并向显示器提供逐行或隔行扫描信号,控制显示器的正确显示,是连接显示器和个人计算机主板的重要组件,是“人机”的重要设备之一,其内置的并行计算能力现阶段也用于深度学习等运算 承担输出显示图形的任务 |
补充不足:
| 编程语言 | 解释 | 备注 |
| 编译型语言 | 执行之前需要先执行完全编译 | 执行速度快 |
| 解释型语言 | 一边执行,一边编译 |
执行速度慢 js就是一种解释型脚本语言 |
1、渲染引擎及网页渲染
1.1 渲染引擎 :能够将HTML/CSS/JavaScript文本及相应的资源文件转换成图像结果。
webkit大致结构
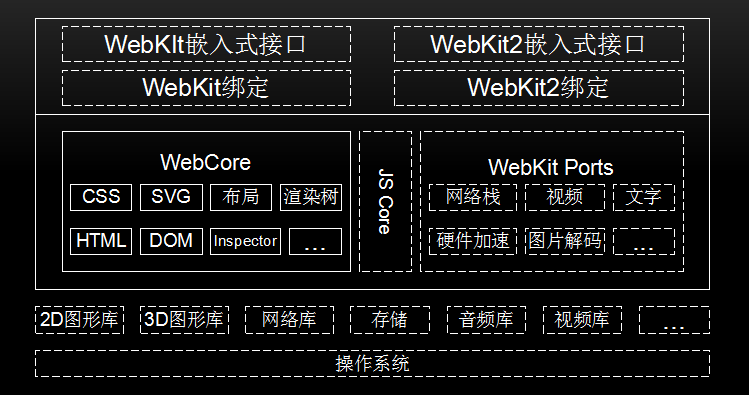
| 操作系统 |
是管理和控制计算机硬件与软件资源的计算机程序,是直接运行在“裸机”上的最基本的系统软件,任何其他软件都必须在操作系统的支持下才能运行。 WebKit也是在操作系统上工作的。 |
| 第三方库 | 为了WebKit提供支持,如图形库、网络库、视频库等。 |
| WebCore |
是各个浏览器使用的共享部分,包括HTML解析器、CSS解析器、DOM和SVG等。 JSCore是WebKit的默认引擎,在谷歌系列产品中被替换为V8引擎。 WebKit Ports是WebKit中的非共享部分,由于平台差异、第三方库和需求的不同等原因,不同的移植导致了WebKit不同版本行为不一致, 它是不同浏览器性能和功能差异的关键部分。 |
| WebKit嵌入式编程接口 | 供浏览器调用,与移植密切相关,不同的移植有不同的接口规范。 |
| 测试用例 | 包括布局测试用例和性能测试用例,用来验证渲染结果的正确性。 |
1.2 网页渲染流程
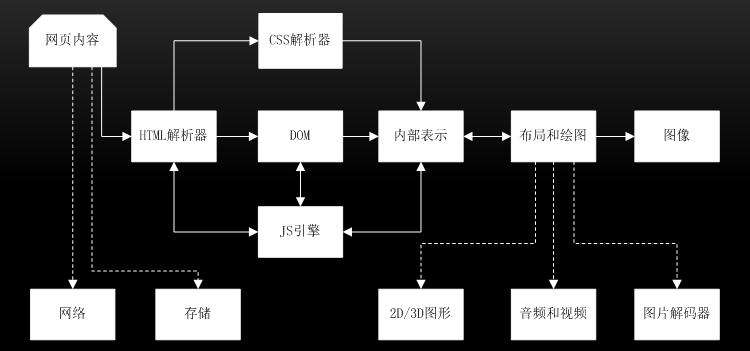
首先是网页内容,输入到HTML解析器,HTML解析器解析,然后构建DOM树,
在这期间如果遇到js代码则交给js引擎处理;
如果来自CSS解析器的样式信息,构建一个内部绘图模型。
该模型由布局模块计算模型内部各个元素的位置和大小信息,最后由绘图模块完成从该模型到图像的绘制。在网页渲染的过程中,大致可分为下面3个阶段 。
1、从输入URL到生成DOM树 |
|
2、从DOM树到构建WebKit绘图上下文 |
|
3、绘图上下文到最终图像呈现 |
|
1.3 JS引擎
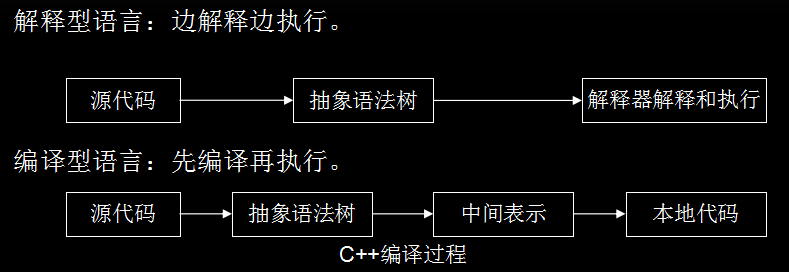
js需要一边执行,一边解析,所以js的解析速度就是当务之急,js引擎和渲染引擎的关系如下:
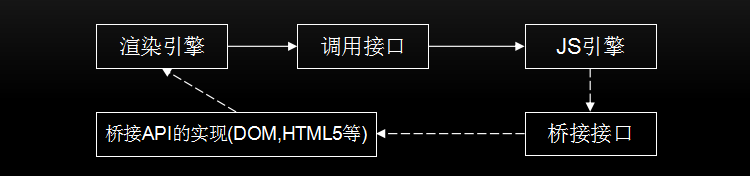
js引擎执行过程:源代码 -> 抽象语法树 -> 字节码 -> JIT --> 本地代码(V8引擎没有中间字节码)
V8更加直接的将抽象语法树通过JIT技术转换成本地代码,放弃了在字节码阶段可以进行的一些性能优化,但保证了执行速度。
在V8生成本地代码后,也会通过Profiler采集一些信息,来优化本地代码。虽然,少了生成字节码这一阶段的性能优化,但极大减少了转换时间。
但是在2017年4月底,v8 的 5.9 版本发布了,新增了一个 Ignition 字节码解释器,将默认启动,从此之后将与JSCore有大致相同的流程。
做出这一改变的原因为:(主要动机)减轻机器码占用的内存空间,即牺牲时间换空间;提高代码的启动速度;
对 v8 的代码进行重构,降低 v8 的代码复杂度(V8 Ignition:JS 引擎与字节码的不解之缘 - CNode技术社区)。
2、V8引擎
V8项目代码结构如下:
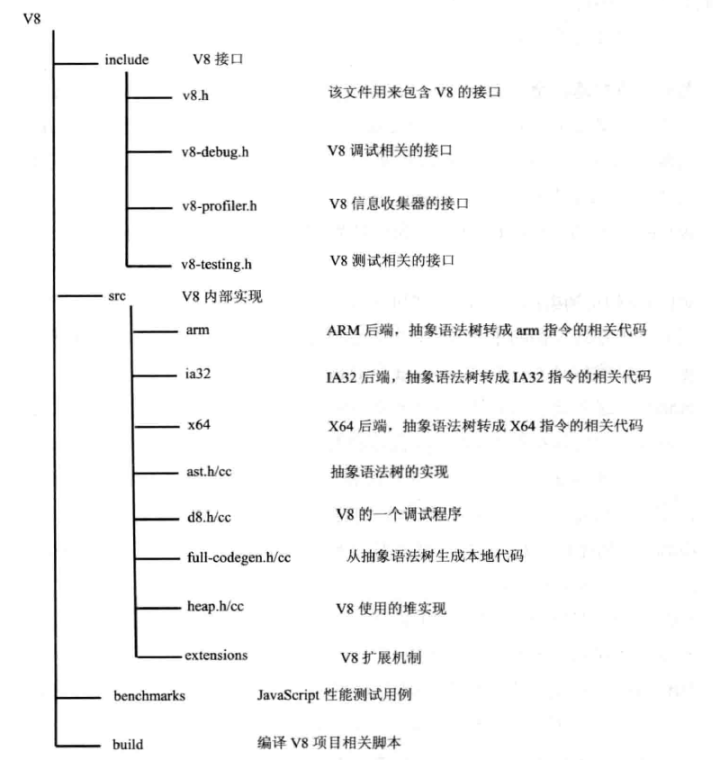
2.1 数据表示 js是动态类型语言,在编译时并不能准确知道变量的类型,只有在运行时确定
js 和 C++ 有几个区别
| c++ | js | |
| 编译确定位置 | 编译阶段确定位置偏移信息,在执行时直接存取 | 执行阶段确定,而且执行期间可以修改对象属性 |
| 偏移信息共享 | 有类型定义,执行时不能动态改变,可共享偏移信息 | 每个对象都是自描述,属性和位置偏移信息都包含在自身的结构中 |
| 偏移信息查找 | 查找偏移地址很简单,在编译代码阶段,对使用的某类型成员变量直接设置偏移位置 | 使用一个对象,需要通过属性名匹配才能找到相应的值,需要更多的操作 |
在代码执行过程中,变量的存取是非常普遍和频繁的,通过偏移量来存取,使用少数个汇编指令就能完成,如果通过属性名匹配则需要更多的汇编指令,也需要更多的内存空间。
在JS中,除boolean,number,string,null,undefined这个五个简单变量外,其他的数据都是对象,V8使用一种特殊的方式来表示它们,进而优化JavaScript的内部表示问题。
在V8中,数据的内部表示由数据的实际内容和数据的句柄构成。数据的实际内容是变长的,类型也是不同的;句柄固定大小,包含指向数据的指针。
这种设计可以方便V8进行垃圾回收和移动数据内容,如果直接使用指针的话就会出问题或者需要更大的开销,使用句柄的话,只需修改句柄中的指针即可。
除少数数据(如整型数据)由handle本身存储外,其他内容限于句柄大小和变长等原因,都存储在堆中。整数从value中取值,然后使用一个指针指向它,可以减少内存的占用并提高访问速度。
一个句柄对象的大小是4字节(32位设备)或者8字节(64位设备),而在JSCore中,使用的8个字节表示句柄。
在堆中存放的对象都是4字节对齐的,所以它们指针的后两位是不需要的,V8用这两位表示数据的类型,00为整数,01为其他。
JS对象在V8中的实现包含三个部分:隐藏类指针,这是v8为JS对象创建的隐藏类;属性值表指针,指向该对象包含的属性值;元素表指针,指向该对象包含的属性。
2.2 工作过程
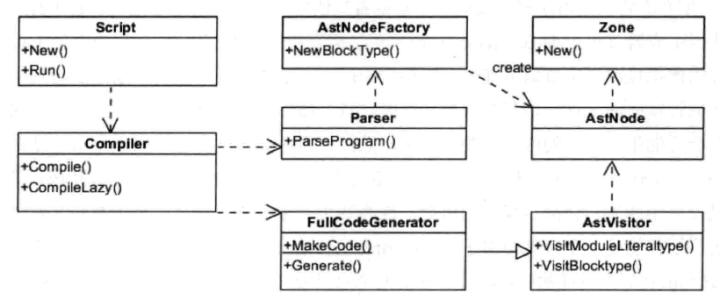
V8引擎编译本地代码时使用的主要类
| 类 | |
| Script | 表示js代码,即包含源代码,又包含编译之后生成的本地代码,即是编译入口,又是运行入口 |
| Compiler | 编译器类,辅组Script类来编译生成代码,调用解释器(Parser)来生成AST,全代码生成器将AST转变为本地代码 |
| AstNode | 抽象语法树节点类,是其他所有节点的基类,包含非常多的子类,后面会针对不同的子类生成不同的本地代码 |
| AstVisitor | 抽象语法树的访问者类,主要用来遍历异构的抽象语法树 |
| FullCodeGenerator | AstVisitor类的子类,通过遍历AST来为js生成本地可执行代码 |
运行阶段使用的主要类:
| 类 | |
| Script | 表示JavaScript代码,即包含源代码,又包含编译之后生成的本地代码,即是编译入口,又是运行入口 |
| Execution | 运行代码的辅组类,包含一些重要函数,如Call函数,它辅助进入和执行Script代码 |
| JSFunction | 需要执行的JS函数表示类 |
| Runtime | 运行这些本地代码的辅组类,主要提供运行时所需的辅组函数,如:属性访问、类型转换、编译、算术、位操作、比较、正则表达式等 |
| Heap | 运行本地代码需要使用的内存堆类 |
| MarkCompactCollector | 垃圾回收机制的主要实现类,用来标记、清除和整理等基本的垃圾回收过程 |
| SweeperThread | 负责垃圾回收的线程 |

2.3 优化回滚
在2010年,V8引入了新的编译器-Crankshaft,它主要针对热点函数进行优化,基于js源代码开始分析而非本地代码,同时构建Hydroger图并基于此来进行优化分析
Crankshaft编译器为了性能考虑,通常会做出比较乐观和大胆的预测—代码稳定且变量类型不变,所以可以生成高效的本地代码。但是,鉴于JavaScript的一个弱类型的语言,变量类型也可能在执行的过程中进行改变,鉴于这种情况,V8会将该编译器做的想当然的优化进行回滚,称为优化回滚。
在最近发布的 V8 5.9 版本中,新增了一个 Ignition 字节码解释器,TurboFan 和 Ignition 结合起来共同完成JavaScript的编译。这个版本中消除 Cranshaft 这个旧的编译器,并让新的 Turbofan 直接从字节码来优化代码,并当需要进行反优化的时候直接反优化到字节码,而不需要再考虑 JS 源代码
2.4 隐藏类与内嵌缓存
隐藏类
在执行C++代码时,仅凭几个指令即可根据偏移信息获取变量信息,
而JavaScript里需要通过字符串匹配来查找属性值的,这就需要更多的操作才能访问到变量信息,而代码量变量存取是十分频繁的,这也就制约了JavaScript的性能。
V8借用了类和偏移位置的思想,将本来通过属性名匹配来访问属性值的方法进行了改进,使用类似C++编译器的偏移位置机制来实现,这就是隐藏类。

内嵌缓存
正常访问对象属性的过程是:首先获取隐藏类的地址,然后根据属性名查找偏移值,然后计算该属性的地址。
虽然相比以往在整个执行环境中查找减小了很大的工作量,但依然比较耗时。能不能将之前查询的结果缓存起来,供再次访问呢?当然是可行的,这就是内嵌缓存。
内嵌缓存的大致思路就是将初次查找的隐藏类和偏移值保存起来,当下次查找的时候,先比较当前对象是否是之前的隐藏类,如果是的话,直接使用之前的缓存结果,减少再次查找表的时间。当然,如果一个对象有多个属性,那么缓存失误的概率就会提高,因为某个属性的类型变化之后,对象的隐藏类也会变化,就与之前的缓存不一致,需要重新使用以前的方式查找哈希表。
2.5 内存管理
Node中通过JavaScript使用内存时就会发现只能使用部分内存(64位系统下约为1.4 GB,32位系统下约为0.7 GB),
其深层原因是 V8 垃圾回收机制的限制所致(如果可使用内存太大,V8在进行垃圾回收时需耗费更多的资源和时间,严重影响JS的执行效率)
内存的管理组要由分配和回收两个部分构成。V8的内存划分如下
| 1、Zone |
管理小块内存 其先自己申请一块内存,然后管理和分配一些小内存,当一块小内存被分配之后,不能被Zone回收,只能一次性回收Zone分配的所有小内存。 当一个过程需要很多内存,Zone将需要分配大量的内存,却又不能及时回收,会导致内存不足情况 |
| 2、堆 | 管理js使用的数据、生成的代码、哈希表等。为方便实现垃圾回收,堆被分为三个部分: |
| 2.1、年轻分代 |
为新创建的对象分配内存空间,经常需要进行垃圾回收。 为方便年轻分代中的内容回收,可再将年轻分代分为两半,一半用来分配,另一半在回收时负责将之前还需要保留的对象复制过来 |
| 2.2、年老分代 | 根据需要将年老的对象、指针、代码等数据保存起来,较少地进行垃圾回收 |
| 2.3、大对象 | 为那些需要使用较多内存对象分配内存,当然同样可能包含数据和代码等分配的内存,一个页面只分配一个对象 |

垃圾回收
V8 使用了分代和大数据的内存分配,在回收内存时使用精简整理的算法标记未引用的对象,然后消除没有标记的对象,最后整理和压缩那些还未保存的对象,即可完成垃圾回收。
在V8中,使用较多的是年轻分代和年老分代。
年轻分代中的对象垃圾回收主要通过Scavenge算法进行垃圾回收。在Scavenge的具体实现中,主要采用了Cheney算法:通过复制的方式实现的垃圾回收算法。它将堆内存分为两个 semispace,一个处于使用中(From空间),另一个处于闲置状态(To空间)。当分配对象时,先是在From空间中进行分配。当开始进行垃圾回收时,会检查From空间中的存活对象,这些存活对象将被复制到To空间中,而非存活对象占用的空间将会被释放。完成复制后,From空间和To空间的角色发生对换。在垃圾回收的过程中,就是通过将存活对象在两个 semispace 空间之间进行复制。年轻分代中的对象有机会晋升为年老分代,条件主要有两个:一个是对象是否经历过Scavenge回收,一个是To空间的内存占用比超过限制。
对于年老分代中的对象,由于存活对象占较大比重,再采用上面的方式会有两个问题:一个是存活对象较多,复制存活对象的效率将会很低;另一个问题依然是浪费一半空间的问题。为此,V8在年老分代中主要采用了Mark-Sweep(标记清除)标记清除和Mark-Compact(标记整理)相结合的方式进行垃圾回收。
2.6.快照
在V8引擎启动时,需要构建JS运行环境,需要加载很多内置对象,同时也需要建立内置的函数,如Array,String,Math等。
为了使V8更加整洁,加载对象和建立函数等任务都是使用JS文件来实现的,V8引擎负责提供机制来支持,就是在编译和执行JS前先加载这些文件。
V8引擎需要编译和执行这些内置的JS代码,同时使用堆等来保存执行过程中创建的对象、代码等,这些都需要时间。为此,V8引入了快照机制。
将这些内置的对象和函数加载之后的内存保存并序列化。序列化之后的结果很容易反序列化,经过快照机制的启动时间可以缩减几毫秒。
快照机制也可以将一些开发者认为需要的JS文件序列化,以减少处理时间。不过快照机制的加载的代码不能被CrankShaft这样的编译器优化,可能会存在性能问题。
参考文章:https://zhuanlan.zhihu.com/p/27628685

 浙公网安备 33010602011771号
浙公网安备 33010602011771号