如何无缝地将人工智能扩展到分布式大数据
作者:Jason Dai,最初发表于LinkedIn Pulse。
6 月初,在今年的虚拟 CVPR 2020 上,我在半天的 教程课中 介绍 了如何构建面向大数据的深度学习应用程序。这是一个非常独特的体验,在本文中,我想分享本教程的一些重点内容。
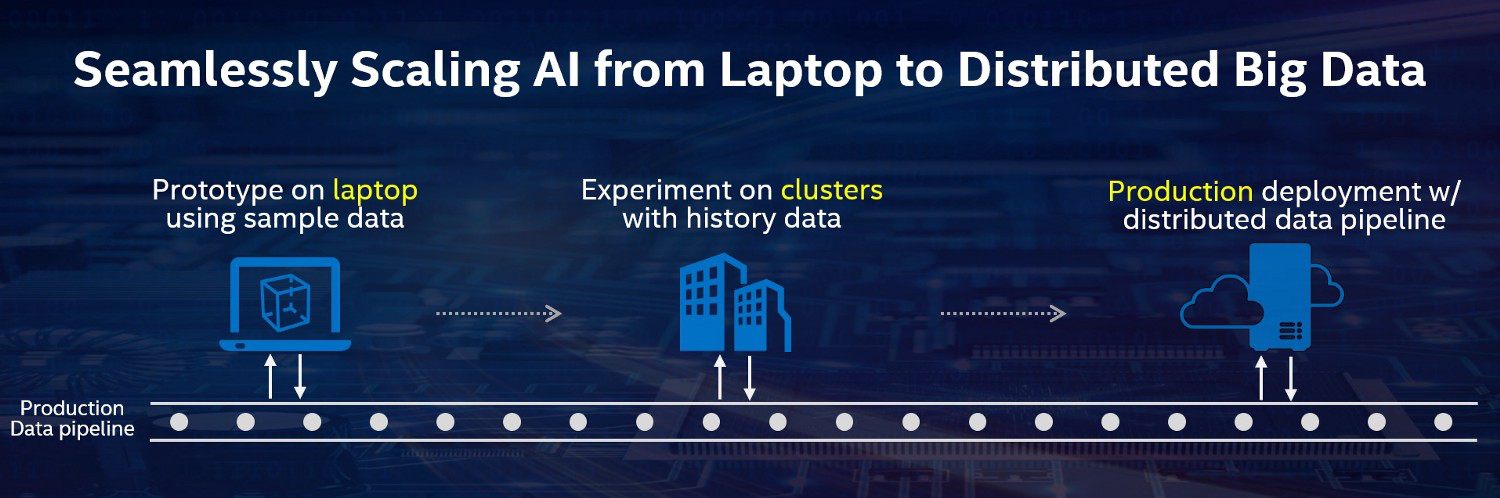
关键问题:大数据上的人工智能
本教程的重点是AI 从实验阶段进入生产应用这个过程中出现的一个关键问题,即 如何无缝地将人工智能扩展到分布式大数据 。如今,人工智能研究人员和数据科学家要将人工智能模型应用到存储在分布式大数据集群中的生产数据集上,都需要经历巨大的痛苦。
通常,传统的方法是配置两个独立的集群,一个用于大数据处理,另一个用于深度学习(例如GPU 集群),中间部署“连接器”(或胶水代码)。遗憾的是,这种“连接器方法”不仅带来了大量的开销(例如,数据复制、额外的集群维护、碎片化的工作流等),而且还会因为跨异构组件而导致语义不匹配(下一节将对此进行详细介绍)。
为了应对这些挑战,我们开发了开源技术,直接在大数据平台上支持新的人工智能算法。如下图所示,这包括 BigDL (面向 Apache Spark 的分布式深度学习框架)和 Analytics Zoo (Apache Spark/Flink&Ray 上的分布式 Tensorflow、Keras 和 PyTorch)。

一个启发性的示例: JD.com
在深入讲解 BigDL 和 Analytics Zoo 的技术细节之前,我在教程中分享了一个启发性的示例。京东是中国最大的网购网站之一;他们在 HBase 中存储了数以亿计的商品图片,并构建了一个端到端的对象特征提取应用程序来处理这些图片(用于图像相似性搜索、图片去重等)。虽然对象检测和特征提取是标准的计算机视觉算法,但如果扩展到生产环境中的数亿张图片,这将是一个相当复杂的数据分析流水线,如下面的幻灯片所示。
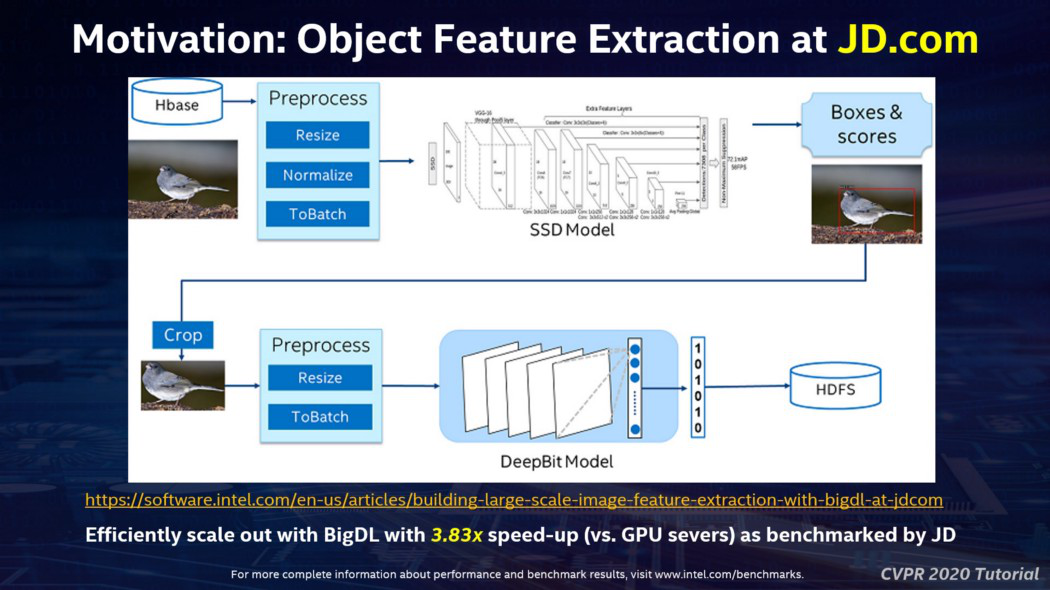
之前,京东的工程师在 5 节点的 GPU 集群上构建了解决方案,采用的是“连接器方法”:从 HBase 读取数据,跨集群对数据进行分区和处理,然后在 Caffe 上运行深度学习模型。这个过程非常复杂且容易出错(因为数据分区、负载平衡、容错等都需要手动管理)。此外,“连接器”还出现了语义不匹配的情况(在这里是 HBase+Caffe)——从 HBase 读取数据大约需要花费一半的时间(因为任务并行性与系统中 GPU 卡的数量相关,与 HBase 交互读取数据的速度太慢了)。
为了克服这些问题,京东的工程师使用 BigDL 实现了端到端的解决方案(包括数据加载、分区、预处理、DL 模型推断等),作为一个统一的管道,以分布式方式运行在单个 Spark 集群上。这不仅极大地提高了开发效率,而且速度比 GPU 解决方案提高了大约 3.83 倍。要了解这个应用程序的更多细节,可以参考 [1] 和 [2] 。
关键技术:BigDL框架
在过去的几年里,我们一直在推动开源技术,力争无缝地将人工智能扩展到分布式大数据。2016 年,我们开源了 BigDL ,一个面向 Apache Spark 的分布式深度学习框架。它被实现为 Spark 上的一个标准库,并提供了一个富有表现力的、“数据分析集成”深度学习编程模型。因此,用户可以将新的深度学习应用程序作为标准的 Spark 程序构建,无需进行任何更改,就可以在现有的大数据集群上运行,如下面的幻灯片所示。

与机器学习社区的一般常识(细粒度的数据访问和就地更新对于高效的分布式训练至关重要)相反,BigDL 直接在 Spark 的函数式计算模型(具有写时复制和粗粒度操作特性)上提供可扩展的分布式训练。它使用 Spark 中现有的原语(比如 shuffle、broadcast、内存缓存等)实现了一个高效的类 AllReduce 操作,与 Ring AllReduce 具有相似的性能特征。详情请参阅我们的 SoCC 2019 论文。
关键技术:Analytics Zoo平台
BigDL 提供了 Spark 原生框架让用户建立深度学习应用程序, Analytics Zoo 则试图解决一个更普遍的问题:如何以分布式、可扩展的方式无缝地将任意人工智能模型(可以使用 TensroFlow、PyTorch、PyTorch、Keras、Caffe 等等)应用到存储在大数据集群上的生产数据。

如上面的幻灯片所示,Analytics Zoo 是在 DL 框架和分布式数据分析系统之上实现的一个更高层次的平台。特别是,它提供了一个“端到端 流水线 层”,可以无缝地将 TensorFlow、Keras、PyTorch、Spark 和 Ray 程序集成到一个集成 流水线 中,后者可以透明地扩展到大型(大数据或 K8s)集群,用于分布式训练和推理。
作为一个具体的例子,下面的幻灯片展示了 Analytics Zoo 用户如何在 Spark 程序中直接编写 TensorFlow 或 PyToch 代码;这样,程序就可以先使用 Spark 处理大数据(存储在 Hive、HBase、Kafka、Parquet 中),然后将内存中的 Spark RDD 或 Dataframes 直接提供给 TensorFlow/PyToch 模型用于分布式训练或推理。在底层,Analytics Zoo 会自动处理数据分区、模型复制、数据格式转换、分布式参数同步等,这使得 TensorFlow/PyToch 模型可以无缝地应用于分布式大数据。

总结
在本教程中,我还分享了更多关于如何使用 Analytics Zoo 构建可扩展大数据 AI 流水线 的细节,包括高级功能(比如 RayOnSpark、用于时序数据的 AutoML 等)和 实际的应 用案例(比如 Mastercard、Azure、CERN、SK Telecom 等)。感兴趣的读者,可以查阅以下资料:
- 我的 CVPR 2020 教程网站 (https://jason-dai.github.io/cvpr2020/)
- Analytics Zoo Github 网址 (https://github.com/intel-analytics/analytics-zoo)
- Analytics Zoo 用例页 (https://analytics-zoo.github.io/master/#powered-by/)
参考
- “Building Large-Scale Image Feature Extraction with BigDL at JD.com”, https://software.intel.com/en-us/articles/building-large-scale-image-feature-extraction-with-bigdl-at-jdcom
- “BigDL: A Distributed Deep Learning Framework for Big Data”, ACM Symposium of Cloud Computing conference (SoCC) 2019, https://arxiv.org/abs/1804.05839

 浙公网安备 33010602011771号
浙公网安备 33010602011771号